UniRec: 拡張Sequential Recommendationの論文を読む
UniRec: A Dual Enhancement of Uniformity and Frequency in Sequential Recommendations 概要
- UniRecは、ユーザーの行動パターンをより正確にモデル化するために、シーケンスの一様性とアイテムの頻度を活用した新しい双方向強化シーケンシャル推薦手法
- 非一様なシーケンスや頻度の低いアイテムの表現を改善し、相互に強化し合うことで、複雑なシーケンシャル推薦シナリオにおけるパフォーマンス最適化
- 4つのデータセットにおいて11の先進モデルと比較して顕著な性能向上を示した
なお内容に間違いもあるかもしれませんが、Sequential Recommendationの初学者なのでお手柔らかにお願いします🙇
本文に入る前にsequential recommendationのざっくり振り返り
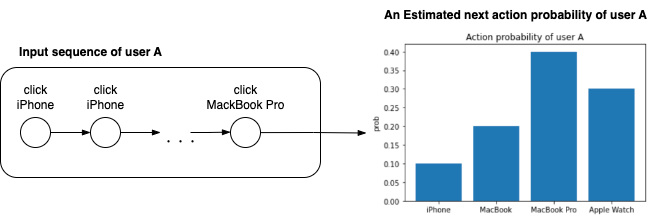
順次推薦システムは、ユーザーの行動パターンを特定し、未来の行動を予測するシステムです。例えば、あるユーザの商品に対するアクション(クリックした、カートに入れた、購入したなど)の時系列を入力として、次にユーザがアクションする商品を推測するモデルが挙げられます。
論文読解: GRU4Recの改良 - 負例のサンプリングと損失関数の改良より抜粋
歴史的には、マルコフモデルがシークエンシャルな状態間の遷移を分析するための重要な役割を果たし、その後、長期的依存関係を捕捉するRNNモデル(例:GRU4Rec)が登場しました ([Session-based Recommendations with Recurrent Neural Networks]
(https://ar5iv.labs.arxiv.org/html/1511.06939))
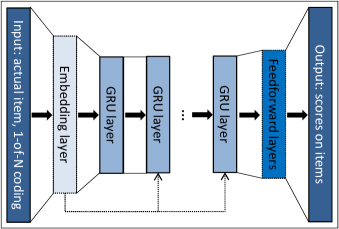
このモデルを含めて初期の時系列推薦モデルは、入力シーケンスから出力の埋め込み表現を獲得し、全結合層を全商品のスコアを計算するため、商品数が多くなってくる(〜1M)と全結合層の重みと計算コストが膨大になるという問題がありました。先ほど例に出したGRU4Recも同様で、論文中にある以下のアーキテクチャ図を見るとよりわかりやすいと思います
また、直近T個のインタラクションのみが次の推薦に影響を与えると仮定したモデルも研究が進められており、CNNの枠組みで学習するモデル(例:Caser)が提案されています。このモデルはユーザーの好みが頻繁に変化し、直近のデータのみを用いる方が有用なケースで採択されるようですが、一般的には一貫した嗜好のもとで部分的に好みが変化(飽きや季節性などの影響)する場合が多いと考えられていて、研究事例・性能の両面で後ほど紹介するアテンションベースの手法に押されている印象です。
最近主流のアテンションメカニズムやTransformerベースのモデル(例:SASRec、Bert4Rec)は複雑なシーケンス依存性を理解するためにself-attentionを活用しています。Bert4Recでは、これまでのuni-directionalなモデルは逐次推薦タスクに適したuser preference表現を学習するには不十分であると主張していて以下の制限があると述べています
- 制限1: uni-directionalなモデルでは、各interactionがそれよりも過去のinteractionsからの情報しか考慮できないため、hidden representationの品質が制限される。
- 制限2: uni-directionalなモデルは、**rigid order assumption (厳密な順序の仮定??)**を満たすテキストデータや時系列データ等には有効。しかし、実アプリケーション上のユーザ行動は必ずしもその仮定を満たさない。
従って、uni-directionalではなくbi-directionalなモデル(BERTのような bi-directional self-attention model)を採用したBERT4Recを提案していて、Sequential推薦タスクにより適したuser preference 表現の学習を目指しています。
また最近の研究は、クロスドメイン、解釈可能性、グラフニューラルネットワーク、対照学習アプローチなどに拡張されています
クロスドメイン
- メインの概念について、研究者たちは定義を試みてきたが、依然として混乱が多い。例えば、映画や本を異なるドメインと見なす研究者がいる一方で、教科書と小説といった異なるサブカテゴリのアイテムも異なるドメインとされることがあります。
- これらの定義は主にアイテムの違いに焦点を当てており、ユーザーの違いは無視されていて、ドメインを次の3つの視点から定義する:コンテンツレベルの関連性、ユーザーレベルの関連性、アイテムレベルの関連性が挙げられます。
- コンテンツレベルの関連性: デュアルやマルチドメインには、ユーザーの嗜好やアイテムの詳細から同じコンテンツやメタデータの特徴(キーワードやタグ)が存在する。しかし、これらのドメインには共通のユーザーやアイテムは存在しません(例: Amazon MusicとNetflix)。
- ユーザーレベルの関連性: デュアルやマルチドメインでは、共通のユーザーと異なるアイテムレベルが存在していて、たとえば属性レベル(同じタイプのアイテム(例: 本)で異なる属性値を持つ教科書と小説)や、テキストタイプレベル(異なるタイプのアイテム(例: 映画と本))が挙げられます
- アイテムレベルの関連性: デュアルやマルチドメインでは、共通のアイテム(例: 映画)と異なるユーザーが存在します(例: MovieLensとNetflixのユーザー)。これらのユーザーは全く異なるか、異なる推薦システム間で重複するユーザーを区別するのが難しく、このタイプのクロスドメイン推薦は文献で「クロスシステム推薦」とも呼ばれています
解釈可能性
- 主に、識グラフ(KG)を活用して効果的で説明可能なシーケンシャルレコメンダーを構築する新しい説明可能なインタラクション駆動ユーザーモデリング(EIUM)アルゴリズムを提案しています。
- 特定のユーザー−アイテムペア間の適格なセマンティックパスをKGから抽出し、それらをエンコードして各パスの重要度スコアを学習することで、推薦システムのパス単位の説明を提供しています。
グラフニューラルネットワーク
- https://arxiv.org/pdf/2305.04619
- 必要な前提知識が多く自分には理解が難しかったです…😢
提案手法
振り返りが少し長くなってしまいましたが、本論文の提案手法をみていきましょう。
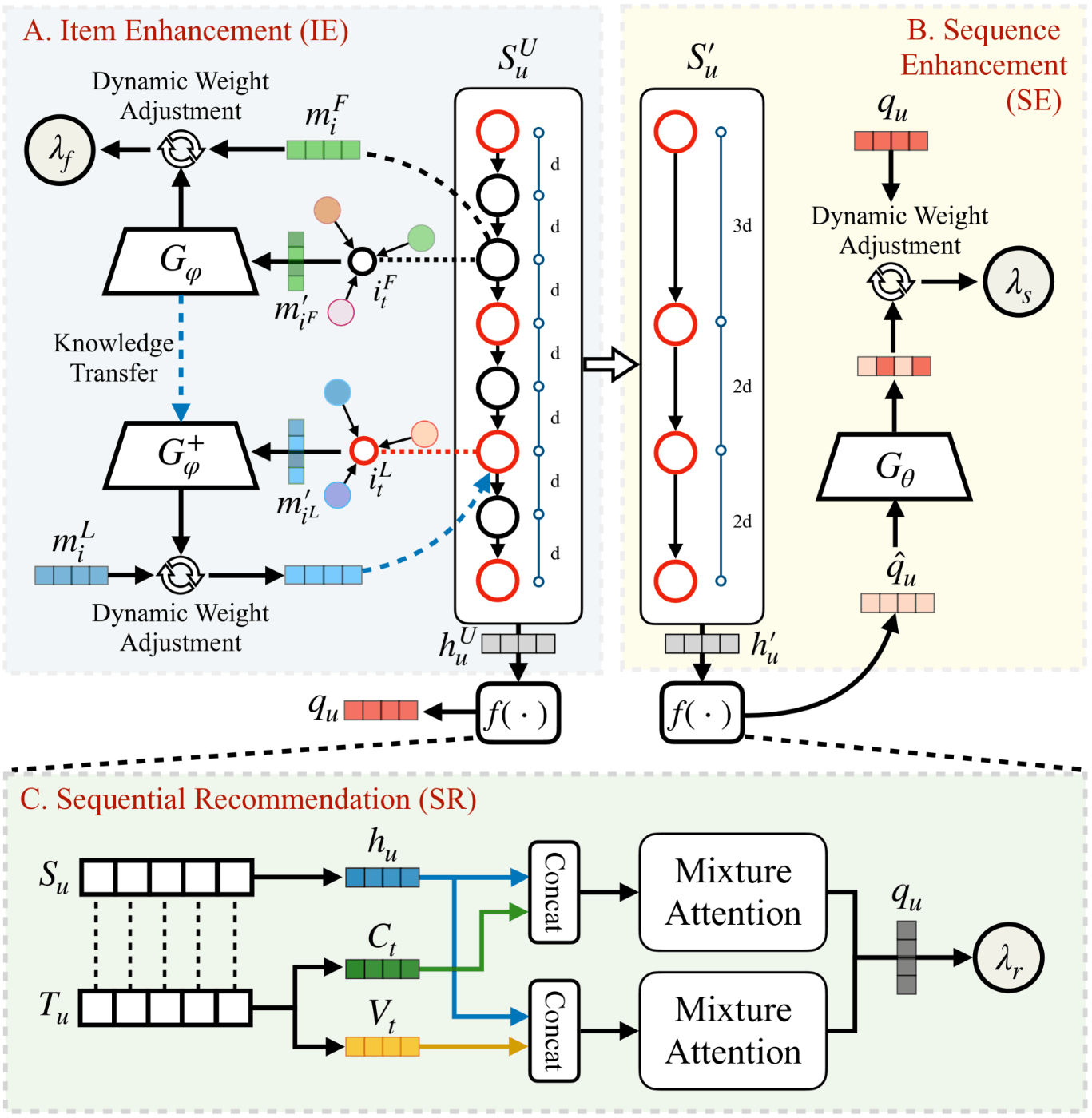
提案手法は3つの要素で構成されていて、A.Item Enhancement(IE), B.Sequence Enhancement(SE), C.Sequential Recommendation(SR)としてそれぞれ整理していきます。
問題の定式化は本論文の(3.1.Problem Formulation)の章を参照してください。
Sequence enhancement
-
S_u S_u’ q_u G_θ G_θ - 学習初期はuniformなseqが多くなるように(後期はnon-uniが多くなる)、学習weight
W_s - このタスクはシーケンシャルレコメンデーションの主要タスクと並行して行われる補助タスクとして機能し、特に
S'_u’ S_n
Item Enhancement
- このモジュールでは隣接アイテムの情報利用と
i_𝑡^F i_𝑡^L - 近隣アイテムは時間間隔
T j H i_c j S s(i_c,j) K - knowledge transferは
i_𝑡^F i_𝑡^L
Multidimensional Time Modeling (SR)
- それぞれの
S_u 𝒯_u 𝒯_intv v_k - 時間的文脈モデリング年、月、日などの時間情報を別々にモデル化して
C_t - 各S𝑢に対して、アイテムシーケンス埋め込み
h_u C_t V_t q_U - 推薦タスクに対する損失関数は、埋め込みの出力と次に予測されるアイテムの埋め込みを使用して定義することで、学習をすすめていきます
実験結果
dataset
学習難度からカテゴリー事にitemやuserに閾値を設定してそれ以上の頻度のデータに限って使用しています
評価指標
全体結果

全体的に、時間認識モデルさまざまなデータセットにおいて非時間認識シーケンシャル推薦モデルを上回っていて、UniRecはすべてのデータセットと評価指標において他の比較モデルを大幅に上回っています。UniRecが採用するシーケンスとアイテムの双方向強化戦略と多次元時間モデル化は、ユーザーの興味とアイテムの特性を精密にモデル化する精度を大幅に向上させています。
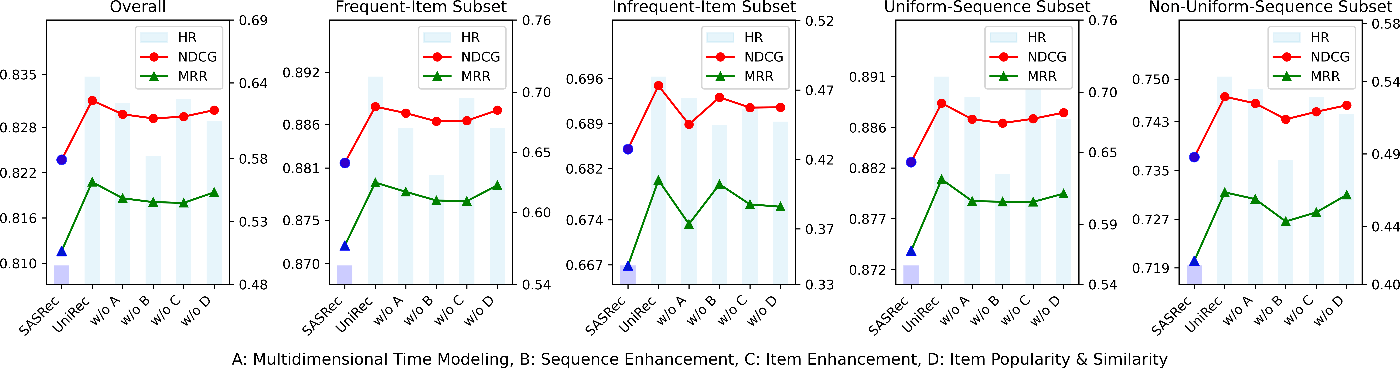
個人的に面白かったのはこの図で、モデル内のさまざまなモジュールの影響を理解するために、アブレーションスタディを行っていて、評価のためにモデルを以下の部分に分けています。
- 多次元時間モデリング(A)、シーケンス強化(B)、アイテム強化(C)、そしてアイテムの人気と類似性(D)。
- w/o Aは多次元時間モデリングを単一次元の時間モデリング構造に置き換え、時間間隔のモデリングのみを利用しコンテキスト時間情報を無視することを指します。
- w/o Bはシーケンス強化タスクを削除しています
- w/o Cはアイテム強化タスクを削除
- w/o Dはアイテム強化コンポーネントにおいてアイテムの人気と類似性を考慮せず、プロジェクトの時間間隔のみに基づいて候補となる近隣候補を選定することを指します
UniRecはすべての戦略においてSASRecを大幅に上回り、特に少頻出アイテムと非均一シーケンスのサブセットで顕著で、w/o Bは最も大きなパフォーマンス低下を引き起こし、HRメトリックで特に顕著であり、シーケンス強化モジュールの効果性を強調しています。このモジュールは、非均一シーケンスの均一性を改善するだけでなく、少頻出アイテムの頻度も増加させ、ユーザーの興味のモデリング精度に大きく貢献していることを示しています。非常に面白いですね。
メモ
- sequential recommendationの歴史的にも、ItemやUserの情報をリッチにしていく今回の手法のような方向性は筋が良さそうでした
- 複数の手法(モジュール)を提案する論文では、アブレーションスタディを行って各手法の効果を示すとよりわかりやすいです。(自分が論文書く機会があれば是非採用指定ですね)
- sequential recommendationのテーマに関して完全に初心者だったので勉強になりました
Discussion