Claude MCPとVertex AIで遊戯王のルールを生成AIに理解させる
LLM・LLM活用 Advent Calendar 2024 7日
ヤプリ #1 Advent Calendar 2024 9日
の記事です。
はじめにお断り
タイトルや本文で生成AIが「文脈を理解する」や「文脈を捉える」という表現を使っていますが、厳密には実行環境では行列計算で次の単語の出現確率を計算して予測しているのでAIが理解することはないです。ただ話として伝わりやすいようにそういう表現を使っています。
概要
遊戯王デュエルモンスターズというカードゲーム(以下遊戯王とする)があります。
そしてこのカードゲームのルールは非常に複雑です。
複雑さを増している要素として、日本語の意味、文法だけでは捉えられない遊戯王特有の文脈が存在するからです。
今回はこの遊戯王特有に文脈を生成AIに捉えさせることを試みました。
また、11月に発表されたModel Context Protocol(MCP)が話題になっていますが、
local sqliteファイルへのアクセスやgithubアクセスなどデフォルトで用意されているMCP Serverの設定の情報が中心で、cloud上のリソースへのアクセスを含んだCustom MCP Serverの実装例はあまりみません。
そこで、よくあるbigqueryで管理するデータ(テーブルやベクトル埋め込み)に対してアクセスする構成も試みました。
具体的な課題
日本語の意味、文法だけでは捉えられない遊戯王特有の文脈が存在するという話を冒頭で出しました。
具体例を示します。
『王の棺』『ティアラメンツ・シェイレーン』の2つのカードについてです。
『王の棺』の以下の効果
②:手札を1枚墓地へ送って発動できる。デッキから「ホルス」モンスター1体を墓地へ送る。
で手札の『ティアラメンツ・シェイレーン』を墓地に送った場合に、『ティアラメンツ・シェイレーン』の以下の効果
②:このカードが効果で墓地へ送られた場合に発動できる。(中略) 融合召喚する。
が発動するかどうかという問いを考えます。
日本語の意味や文法から判断すると、墓地に送られたのだから発動できそうに見えますが、これは遊戯王のルールでは発動しないというのが答えです。
遊戯王のルール上では、コストと効果という概念がありこれが日本語の文脈と異なります。
今回の場面だと、『ティアラメンツ・シェイレーン』はコストとして墓地送りされているので発動条件を満たせないということです。(これが結構初心者にとって難しい)。
当然何も情報を与えないclaude3.5 sonnetに以下のように投げると、発動するという答え(不正解)になります。
日本語の文脈だけを捉えればそれがむしろ自然に見えます。
生成AI(今回はclaude3.5 sonnet)にこの日本語とカードゲームのルールの文脈の違いを捉えさせて、正解を返すようにしていきます。
全体設計
以下の設計にしています。
前提知識としてMCPがどう動くかは以下で確認してください。
解説記事は他にたくさんあるのでここでは解説しません。
平たくいうと、Claudeに与えられたpromptに対してClaudeがどのMCP Serverにアクセスすれば良いのかを勝手に判断して対応するMCP ClientからMCP Serverに情報をとりにいくということを内部的にやってくれます。そのため、Claudeのユーザーは色々なところに情報アクセスをして頑張ってpromptを作成して生成AIに尋ねる、というプロセスが不要になります。
まず、カード情報については高々13000種類程度しかないため、あらかじめBigQueryに入れてあります。ベクトル検索を可能にするため、ベクトル埋め込みをしています。手順は後述します。
また、BigQueryにアクセスするためのMCP Serverを用意してあります。
これは自前で作る必要があります。手順は後述します。
もう一つのMCP Serverでbrave search APIと接続し、Web検索をして関連するルールの情報を取得します。
全体の処理の流れとしては
ユーザーがClaude Desktop App上にルールに関する質問を入力
-> Claudeがカード情報をMCP Serverに問い合わせる
-> MCP Serverの処理の内部でBigQueryに関連カード情報を問い合わせる
-> BigQueryは内部的にVertex AIと接続して、ベクトル検索をし、関連情報をMCP Serverに返す
-> MCP ServerからClaudeにそのまま返す
-> Claudeは続いて、カード情報をもとにWeb検索するワードを決定する
-> MCP Serverを通じてbraveでWeb検索し、ルールに関係する情報を見つける
-> その情報がMCP ServerからClaudeに返される
-> Claudeが取得された情報をもとにユーザーから渡されたpromptに対する回答を生成
-> 出力
となります。
具体的な手順
BigQueryとVetex AIの接続
BigQueryのクエリからVertex AIを使ってベクトル埋め込みを利用するために、下準備をします。
以下の記事が非常に参考になったので、詳細は譲ります。
結果的に以下を実施しました。
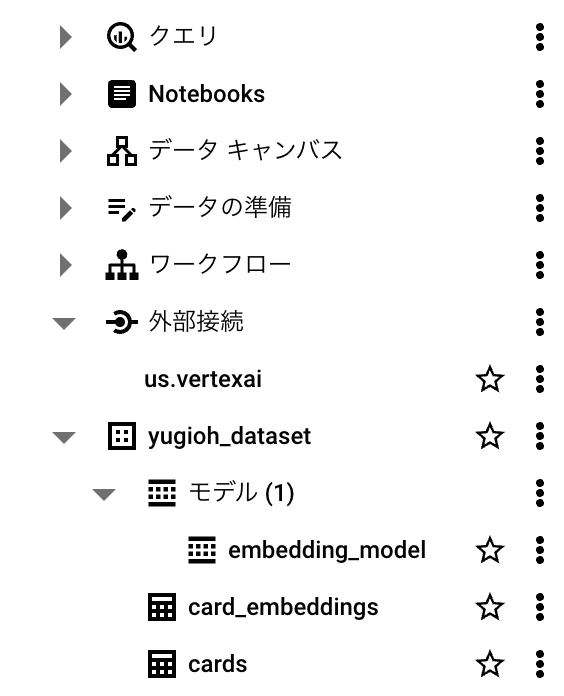
- 最初に外部接続を作成、bigqueryからvertexAIへの接続を作る。(これはコンソールから)
- us.vertexaiというconnectionを作った。
- datasetに属する以下を作成
- cardsテーブル
- card_embedding_model(embeddingするためのモデル)
- card_embeddingsテーブル(カードデータのベクトル化したもの)
このときembedding model作る前にconnectionにattachされているservice accountにVertex AI userを付与する必要があるという注意がありました。このときembedding model作る前にconnectionにattachされているservice accountにVertex AI userを付与する必要があるという注意がありました。
基本的に貼った記事の通りでいけます。
最終的にこのような状態になりました。
正確なカード情報をBigQueryにためる
ここはあまり本質的でないので、概要だけ示します。
まず、公式のカード情報のページからスクレイピングして、13000種類のカードをjsonファイルとしてローカルに作成します。Denoで書きました。
その後、jsonファイルから以下のようにBigQueryのテーブルに入れていきました。
from google.cloud import bigquery
(中略)
self.client = bigquery.Client(project=project_id)
(中略)
errors = self.client.insert_rows_json(
self.table_ref,
batch,
row_ids=[str(row['card_id']) for row in batch]
)
...
以下に一応動かしたコードは貼ります。
Claude3.5sonnetに生成してもらったもので、一部見せたくない情報は隠しています。
雰囲気だけ見てもらえればと思います。
スクレイピングでカード情報を取得してjsonとしてアウトプット
import { DOMParser } from "https://deno.land/x/deno_dom/deno-dom-wasm.ts";
import { ensureDir } from "https://deno.land/std/fs/mod.ts";
import { join } from "https://deno.land/std/path/mod.ts";
import { delay } from "https://deno.land/std/async/delay.ts";
class YugiohScraper {
private baseUrl = "https://www.db.yugioh-card.com/yugiohdb/card_search.action";
private outputDir = "card_data";
private batchSize = 100; // 同時実行数
constructor() {
this.initializeOutputDir();
}
private async initializeOutputDir() {
await ensureDir(this.outputDir);
}
private async fetchWithRetry(url: string, retries = 3): Promise<Response> {
for (let i = 0; i < retries; i++) {
try {
const response = await fetch(url, {
headers: {
"User-Agent": "",
},
});
if (response.ok) return response;
} catch (error) {
console.error(`Attempt ${i + 1} failed:`, error);
if (i === retries - 1) throw error;
}
await delay(1000 * (i + 1));
}
throw new Error("Max retries reached");
}
private getCardSetText(doc: Document): string {
const cardSetElement = doc.getElementById('CardSet');
if (!cardSetElement) return "";
return cardSetElement.textContent?.trim()
.replace(/\s+/g, ' ')
.replace(/\n+/g, ' ')
.trim() ?? "";
}
private async getCardData(cid: number) {
const url = `${this.baseUrl}?ope=2&cid=${cid}&request_locale=ja`;
try {
const response = await this.fetchWithRetry(url);
const html = await response.text();
const parser = new DOMParser();
const doc = parser.parseFromString(html, "text/html");
if (!doc) {
throw new Error("Failed to parse HTML");
}
return {
card_id: cid,
card_info: this.getCardSetText(doc),
timestamp: new Date().toISOString(),
url: url,
};
} catch (error) {
console.error(`Error fetching card ${cid}:`, error);
return null;
}
}
private async saveCardData(cardData: any) {
if (!cardData) return;
const cid = cardData.card_id;
const filename = join(this.outputDir, `card_${cid}.json`);
const jsonString = JSON.stringify(cardData, null, 2);
try {
await Deno.writeTextFile(filename, jsonString);
// console.log(`Successfully saved card ${cid}`);
} catch (error) {
console.error(`Error saving card ${cid}:`, error);
}
}
private async processBatch(cardIds: number[]) {
const promises = cardIds.map(async (cid) => {
try {
console.log(`Processing card ID: ${cid}`);
const cardData = await this.getCardData(cid);
if (cardData) {
if (cardData.card_info === "") {
console.log(`No data found for card ${cid}`);
return;
}
await this.saveCardData(cardData);
} else {
console.log(`No data found for card ${cid}`);
}
} catch (error) {
console.error(`Error processing card ${cid}:`, error);
}
});
await Promise.all(promises);
}
public async scrapeRange(startId: number, endId: number) {
console.log(`Starting parallel scraping from ID ${startId} to ${endId}`);
// カードIDの配列を生成
const cardIds = Array.from(
{ length: endId - startId + 1 },
(_, i) => startId + i
);
// バッチに分割して処理
for (let i = 0; i < cardIds.length; i += this.batchSize) {
const batch = cardIds.slice(i, i + this.batchSize);
await this.processBatch(batch);
}
}
// バッチサイズを設定するメソッド
public setBatchSize(size: number) {
this.batchSize = size;
}
}
async function main() {
try {
const scraper = new YugiohScraper();
// バッチサイズを設定(同時に処理するリクエスト数)
scraper.setBatchSize(1000);
const startId = 1000;
const endId = 20000;
await scraper.scrapeRange(startId, endId);
} catch (error) {
console.error("Error in main:", error);
}
}
main();main();
deno run fetch_cards.ts
jsonファイルからBigQueryのcardsテーブルにデータ投入
import os
from typing import List, Dict, Any
from langchain_community.document_loaders import DirectoryLoader
from langchain_community.document_loaders import JSONLoader
from google.cloud import bigquery
from google.api_core import retry
import json
from datetime import datetime
class CardLoader:
def __init__(self, project_id: str, dataset_id: str, table_id: str):
self.project_id = project_id
self.dataset_id = dataset_id
self.table_id = table_id
self.client = bigquery.Client(project=project_id)
self.schema = [
bigquery.SchemaField("card_id", "INTEGER", mode="REQUIRED"),
bigquery.SchemaField("card_info", "STRING", mode="NULLABLE"),
bigquery.SchemaField("timestamp", "TIMESTAMP", mode="REQUIRED"),
bigquery.SchemaField("url", "STRING", mode="NULLABLE"),
]
self.table_ref = f"{project_id}.{dataset_id}.{table_id}"
self._ensure_table_exists()
def _ensure_table_exists(self):
try:
self.client.get_table(self.table_ref)
except Exception:
table = bigquery.Table(self.table_ref, schema=self.schema)
self.client.create_table(table)
print(f"Created table {self.table_ref}")
def load_json_files(self, directory_path: str) -> List[Dict[str, Any]]:
"""
ディレクトリ内のJSONファイルを読み込む
Args:
directory_path: JSONファイルが格納されているディレクトリパス
Returns:
List[Dict]: カードデータのリスト
"""
all_data = []
for filename in os.listdir(directory_path):
if filename.endswith('.json'):
file_path = os.path.join(directory_path, filename)
try:
with open(file_path, 'r', encoding='utf-8') as f:
data = json.load(f)
all_data.append(data)
except Exception as e:
print(f"Error loading {filename}: {e}")
return all_data
@retry.Retry()
def insert_to_bigquery(self, card_data: List[Dict[str, Any]], batch_size: int = 1000):
"""
BigQueryにデータを挿入
Args:
card_data: カードデータのリスト
batch_size: 一度に挿入するレコード数
"""
for i in range(0, len(card_data), batch_size):
batch = card_data[i:i + batch_size]
errors = self.client.insert_rows_json(
self.table_ref,
batch,
row_ids=[str(row['card_id']) for row in batch]
)
if errors:
print(f"Errors occurred while inserting batch {i//batch_size + 1}:")
for error in errors:
print(error)
else:
print(f"Successfully inserted batch {i//batch_size + 1}")
def process_directory(self, directory_path: str, batch_size: int = 1000):
"""
ディレクトリ内のすべてのJSONファイルを処理してBigQueryに挿入
Args:
directory_path: JSONファイルが格納されているディレクトリパス
batch_size: 一度に挿入するレコード数
"""
print(f"Loading files from {directory_path}")
card_data = self.load_json_files(directory_path)
print(f"Loaded {len(card_data)} card records")
print("Inserting data into BigQuery")
self.insert_to_bigquery(card_data, batch_size)
print("Data insertion completed")
def main():
# 設定
project_id = "" # GCPプロジェクトID
dataset_id = "yugioh_dataset" # 作成するデータセット名
table_id = "cards" # 作成するテーブル名
directory_path = "card_data" # JSONファイルが格納されているディレクトリ
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "xxx.json"
# ローダーの初期化と実行
loader = CardLoader(project_id, dataset_id, table_id)
loader.process_directory(directory_path)
if __name__ == "__main__":
main()
ベクトル埋め込みする
BigQuery上のcardsテーブルからベクトル埋め込みします。
調べればたくさん情報は出てきます。
これも色々やり方がありますが、以下のClaudeが生成してくれたスクリプトで実施しました。
cardsテーブルからcard_embeddingへベクトル埋め込みを実施
from langchain_google_vertexai.embeddings import VertexAIEmbeddings
from typing import List, Dict, Any, Generator
from google.cloud import bigquery
import datetime
import os
class CardEmbedding:
def __init__(self, project_id: str, dataset_id: str, location: str = "us-central1"):
"""
初期化
Args:
project_id: GCPプロジェクトID
dataset_id: BigQueryデータセットID
location: VertexAI APIのロケーション
"""
self.project_id = project_id
self.dataset_id = dataset_id
self.client = bigquery.Client(project=project_id)
# VertexAI Embeddings の初期化
self.embeddings = VertexAIEmbeddings(
project=project_id,
location=location,
model_name="text-multilingual-embedding-preview-0409"
)
self.embedding_schema = [
bigquery.SchemaField("card_id", "INTEGER", mode="REQUIRED"),
bigquery.SchemaField("card_info", "STRING", mode="NULLABLE"),
bigquery.SchemaField("embedding", "FLOAT64", mode="REPEATED"),
bigquery.SchemaField("embedding_timestamp", "TIMESTAMP", mode="REQUIRED"),
bigquery.SchemaField("model_name", "STRING", mode="REQUIRED"),
]
def create_embedding_table(self, table_id: str):
"""埋め込みベクトル保存用のテーブルを作成"""
table_ref = f"{self.project_id}.{self.dataset_id}.{table_id}"
try:
self.client.get_table(table_ref)
print(f"Table {table_ref} already exists")
except Exception:
table = bigquery.Table(table_ref, schema=self.embedding_schema)
self.client.create_table(table)
print(f"Created table {table_ref}")
return table_ref
def stream_card_info(self, source_table: str, batch_size: int = 1000) -> Generator[List[Dict[str, Any]], None, None]:
"""BigQueryからカード情報をストリーミングで取得"""
query = f"""
SELECT card_id, card_info
FROM `{self.project_id}.{self.dataset_id}.{source_table}`
ORDER BY card_id
"""
query_job = self.client.query(query)
current_batch = []
for row in query_job:
if row.card_info: # card_infoが存在する場合のみ処理
current_batch.append({
"card_id": row.card_id,
"card_info": row.card_info
})
if len(current_batch) >= batch_size:
yield current_batch
current_batch = []
if current_batch: # 残りのデータを処理
yield current_batch
def generate_embeddings(self, cards: List[Dict[str, Any]], embedding_batch_size: int = 10) -> List[Dict[str, Any]]:
"""カード情報のテキストから埋め込みベクトルを生成"""
embeddings_data = []
for i in range(0, len(cards), embedding_batch_size):
batch = cards[i:i + embedding_batch_size]
texts = [card["card_info"] for card in batch]
try:
# VertexAI で埋め込みベクトルを生成
vectors = self.embeddings.embed_documents(texts)
for card, vector in zip(batch, vectors):
embeddings_data.append({
"card_id": card["card_id"],
"card_info": card["card_info"],
"embedding": vector,
"embedding_timestamp": datetime.datetime.now().isoformat(),
"model_name": self.embeddings.model_name
})
print(f"Generated embeddings for cards {i} to {i + len(batch)}")
except Exception as e:
print(f"Error generating embeddings for batch starting at {i}: {e}")
return embeddings_data
def save_embeddings(self, embeddings_data: List[Dict[str, Any]], table_ref: str):
"""生成した埋め込みベクトルをBigQueryに保存"""
if not embeddings_data:
return True
errors = self.client.insert_rows_json(
table_ref,
embeddings_data,
row_ids=[str(row['card_id']) for row in embeddings_data]
)
if errors:
print("Errors occurred while inserting embeddings:")
for error in errors:
print(error)
return False
return True
def process_cards(self,
source_table: str,
destination_table: str,
streaming_batch_size: int = 1000,
embedding_batch_size: int = 10):
"""カード情報の処理を実行(ストリーミング処理)"""
print(f"Starting card processing with {self.embeddings.model_name}")
table_ref = self.create_embedding_table(destination_table)
total_processed = 0
total_success = 0
try:
for batch in self.stream_card_info(source_table, streaming_batch_size):
print(f"Processing batch of {len(batch)} cards...")
embeddings_data = self.generate_embeddings(batch, embedding_batch_size)
if embeddings_data:
if self.save_embeddings(embeddings_data, table_ref):
total_success += len(embeddings_data)
total_processed += len(batch)
print(f"Progress: {total_processed} cards processed, {total_success} successfully embedded")
except Exception as e:
print(f"Error during processing: {e}")
finally:
print(f"Processing completed. Total: {total_processed}, Success: {total_success}")
return total_processed, total_success
def main():
# 環境設定
project_id = ""
dataset_id = "yugioh_dataset"
source_table = "cards"
embedding_table = "card_embeddings"
location = "us-central1" # VertexAI APIのロケーション
# 認証設定
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "xxx.json"
embedder = CardEmbedding(
project_id=project_id,
dataset_id=dataset_id,
location=location
)
total, success = embedder.process_cards(
source_table=source_table,
destination_table=embedding_table,
streaming_batch_size=10,
embedding_batch_size=10
)
print(f"Final results - Total processed: {total}, Successfully embedded: {success}")
if __name__ == "__main__":
main()

こんな感じでベクトルにしてくれます。
ちなみに今回embeddinに使ったモデルはtext-multilingual-embedding-preview-0409です。
これには特にこだわりがあるわけではなく、適宜最適なモデルを選ぶ必要があります。
MCP Serverのbaseを用意する
以下の公式documentとReadmeに従って作成しました。
documentの通り
uvx create-mcp-server
で大体の使われるmethodは勝手に作ってくれます。
BigQueryに通信するMCP Serverを作る
ざっくりいうと、ボイラーテンプレートで用意しているhandle_call_tool関数が実際にプロンプトを処理するときに動く処理なので、ここにBigQueryのベクトル埋め込みをしたテーブルからベクトル検索して取得してくる処理を追加しました。
# server.py
(中略)
from .bigquery_client import BigqueryClient
server = Server("card_server")
project_id = "xxx"
dataset_id = "yugioh_dataset"
embedding_table = "card_embeddings"
location = "us-central1"
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "/path/to/credential.json"
inquirer = BigqueryClient(
project_id=project_id,
dataset_id=dataset_id,
location=location
)
(中略)
# ↓はボイラーテンプレートで作成される部分をname:get-cards, word:検索文字列で受けられるようにしている
@server.call_tool()
async def handle_call_tool(
name: str, arguments: dict | None
) -> list[types.TextContent | types.ImageContent | types.EmbeddedResource]:
if name != "get-cards":
raise ValueError(f"Unknown tool: {name}")
if not arguments:
raise ValueError("Missing arguments")
word = arguments.get("word")
if not word:
raise ValueError("Missing word")
data = await fetch_relative_cards(word)
return [
types.TextContent(
type="text",
text=json.dumps(data, indent=2),
)
]
@server.list_tools()
async def handle_list_tools() -> list[types.Tool]:
"""
List available tools.
Each tool specifies its arguments using JSON Schema validation.
"""
return [
types.Tool(
name="get-cards",
description="Get relative cards",
inputSchema={
"type": "object",
"properties": {
"word": {"type": "string"},
},
"required": ["word"],
},
)
]
# 新規追加
async def fetch_relative_cards(word: str) -> dict[str, any]:
# inquirerを使ってカード情報を取得
similar_cards = inquirer.get_similar_cards(word, embedding_table)
# レスポンス形式に変換
res = {"cards": []}
for card in similar_cards:
res["cards"].append({
"name": f"card_{card.card_id}",
"content": card.card_info,
"similarity": card.similarity
})
return res
この設定でget-cardsというtoolをClaudeの方で認識してくれ、呼べる選択肢になります。
この場合、wordというベクトル検索文字列を受け取るようにしています。
実際にBigQueryにクエリを投げる部分は以下です。
実質的には質問文をそのままベクトル検索にかけ、コサイン距離が近いもの10個のカード情報を取得してきます。この処理自体は今までもよくやる手法でお馴染みだと思います。
最終的にはその10個のカードの情報をMCP接続を通してClaudeに渡します。
from dataclasses import dataclass
from typing import List
import os
from pathlib import Path
from langchain_google_vertexai import ChatVertexAI
from google.cloud import bigquery
@dataclass
class CardInfo:
card_id: int
card_info: str
similarity: float
class BigqueryClient:
def __init__(self, project_id: str, dataset_id: str, location: str = "us-central1"):
"""
GeminiRAGInquirer初期化
Args:
project_id: GCPプロジェクトID
dataset_id: BigQueryデータセットID
location: VertexAI APIのロケーション
"""
self.project_id = project_id
self.dataset_id = dataset_id
self.client = bigquery.Client(project=project_id)
self.embedding_model = "embedding_model"
def escape_string_for_sql(self, s: str) -> str:
"""SQLクエリ用に文字列をエスケープする"""
# 文字列内の改行を空白に置換
s = s.replace('\n', ' ')
# バックスラッシュをエスケープ
s = s.replace('\\', '\\\\')
# シングルクォートをエスケープ
s = s.replace("'", "\\'")
# ダブルクォートをエスケープ
s = s.replace('"', '\\"')
return s
def get_similar_cards(self, question: str, embedding_table: str, top_k: int = 10) -> List[CardInfo]:
escaped_question = self.escape_string_for_sql(question)
job_config = bigquery.QueryJobConfig(
query_parameters=[
bigquery.ScalarQueryParameter("question", "STRING", escaped_question),
]
)
query = f"""
WITH
-- 質問文をベクトル化
question_embedding AS (
SELECT *
FROM ML.GENERATE_TEXT_EMBEDDING(
MODEL `{self.project_id}.{self.dataset_id}.{self.embedding_model}`,
(SELECT @question AS content),
STRUCT(TRUE AS flatten_json_output)
)
),
-- カード情報との類似度計算
similarity AS (
SELECT
card_id,
card_info,
ML.DISTANCE(q.text_embedding, c.embedding, 'COSINE') as vector_distance
FROM question_embedding q
CROSS JOIN `{self.project_id}.{self.dataset_id}.{embedding_table}` c
)
SELECT
card_id,
card_info,
ROUND(1 - vector_distance, 4) as similarity_score
FROM similarity
WHERE vector_distance < 1
ORDER BY vector_distance
LIMIT {top_k}
"""
similar_cards = [
CardInfo(
card_id=row.card_id,
card_info=row.card_info,
similarity=row.similarity_score
)
for row in self.client.query(query, job_config=job_config)
]
return similar_cards
(省略可能)inspectorからMCP Serverの動きを確認
MCP Serverの挙動を確認するためのinspectorが用意されています。
これを使わないと、いちいちコード変更時にClaude Desktop Appを再起動する必要があり面倒です。
また、仮にruntime error等をコンソール上で簡単に確認できるので挙動確認にはほぼ必須です。
http通信のPostmanみたいなものだと思います。
もし、本当に業務上で使うとなると、しっかり関数に対してテストコードを書いて担保するようになると思います。ここは今までと変わらないです。

実際こんな感じで、定義したget-cardsというtoolを確認でき、シェイレーンという文字列から目当ての『ティアラメンツ・シェイレーン』が一番コサイン距離の近い(内積最大)のレコードとして取得できました。(17415がKONAMIのサイトのcidに対応)。
これで、MCP ClientからMCP Serverへの疎通が正しくできるようになったことが確認できます。
Claude Desktop Appから呼び出せるように設定する
最後に、ClaudeからどのMCP Serverを使うかを設定して完了です。
{
"mcpServers": {
"brave-search": {
"command": "/Users/username/.anyenv/envs/nodenv/shims/npx",
"args": [
"-y",
"@modelcontextprotocol/server-brave-search"
],
"env": {
"BRAVE_API_KEY": "xxx"
}
},
"card_server": {
"command": "uv",
"args": [
"--directory",
"/Users/username/projects/mcp-playground/mcp-server-python",
"run",
"card-server"
]
}
}
}
のような設定をしています。
brave検索用のMCP Serverとcard情報取得用のMCP Serverへの接続を定義しています。
braveはAPI_KEYを取得する必要があります。
結果
肝心の結果です。
遊戯王デュエルモンスターズというカードゲームのルールに関する以下の質問に回答してください。
質問の中にはカード名が含まれる可能性が高いです。
カード名だと思われる言葉があれば、関連度の高いカード情報を取得してください。
その情報はカードの詳細情報が含まれているので参考にしてください。
また、日本語の文脈と異なる遊戯王独自の文脈があることに注意してください。
braveで遊戯王wikiの間違えやすいルールを検索して、ルールを詳細に把握してください。
また、回答する情報については根拠と理由を示してください。
質問: 『王の棺』の以下の効果
②:手札を1枚墓地へ送って発動できる。デッキから「ホルス」モンスター1体を墓地へ送る。
で手札の『ティアラメンツ・シェイレーン』を墓地に送った場合に、『ティアラメンツ・シェイレーン』の以下の効果
②:このカードが効果で墓地へ送られた場合に発動できる。(中略) 融合召喚する。
が発動するか?
というpromptを投げてみます。
すると、

のように、get-cards MCP Serverに繋いでベクトル検索した結果を取得できていることを確認できます。

そして、続いて結果をもとにbrave APIに繋いでいるMCP ServerにリクエストしてWeb検索をしていることを確認できます。
最終的に以下の回答を返します。
カードテキストとルール検索の結果から、この質問に対する回答を整理します。
重要な点は以下の通りです:
『王の棺』の効果
手札を1枚墓地へ送るのはコストとして発動する効果です
デッキから「ホルス」モンスターを墓地へ送るのが効果の処理です
『ティアラメンツ・シェイレーン』の効果
「このカードが効果で墓地へ送られた場合に発動できる」というのが発動条件です
遊戯王における「コスト」と「効果」の区別
コストは効果の発動のために必要な代価であり、効果処理の一部ではありません
コストで墓地へ送られた場合は「効果で墓地へ送られた」とはみなされません
結論:
『王の棺』の②の効果で手札の『ティアラメンツ・シェイレーン』を墓地へ送った場合、これはコストとして送られているため、『シェイレーン』の②の効果は発動できません。
理由:
『王の棺』の効果文で「手札を1枚墓地へ送って発動できる」という部分はコストを示しています
コストで墓地へ送られたカードは「効果で墓地へ送られた」とはみなされないというのが遊戯王のルールです
『シェイレーン』の発動条件である「効果で墓地へ送られた場合」を満たしていないため、効果を発動することはできません
このような判断は、遊戯王OCGにおける「コスト」と「効果」の区別に関する基本的なルールに基づいています。カードを墓地へ送る処理が効果なのかコストなのかを正確に判断することは、適切なカードプレイのために重要です。
おおー!ちゃんとコストと効果の区別を理解し、遊戯王のルールの文脈を把握できていることが確認できます。やりたいことを達成できました。
他にもいくつかルールに関係するpromptを試してみると筋の良い回答もありつつ、カード名の正確さや、考える対象の効果のテキストを明確にpromptで示すことなど、やはりpromptの書き方によって回答の質は大きく変わりそうでした。この点は今までと同じです。
まとめ
今回は日本語の文脈理解だけでは把握できないカードゲームのルールを題材にClaudeで正しい回答が買えるような仕組みをModel Context Protocol (MCP) + Vertex AI ベクトル検索 + BigQueryで実現しました。
この構成は実は社内の問い合わせのようなユースケースに有効です。
publicな情報はWeb検索しながら、社内でしか扱われないデータや社内独自の言葉、文脈を生成AIにinputすることができるからです。
これを実現するためには今まではベクトル検索した結果から手動or何かしらのプログラム処理等でpromptを自前で作成する必要がありました。
それを勝手にやってくれるClaudeのMCPは可能性を感じます。
現状主なHostはClaude Desktop Appと一部のツールですが、この先広がっていくとMCP Serverを実装できることがソフトウェアエンジニアのスキルの一部になる可能性も感じるのでこの辺りは追っていこうと思います。
Discussion