BigQuery で Vertex AI の LLM を使用して SQL のみで RAG を構築する
はじめに
こんにちは、Google Cloud Partner Top Engineer 2024 を受賞いたしました、クラウドエース データソリューション部の松本です。
クラウドエース データソリューション部 について
クラウドエースのITエンジニアリングを担う システム開発統括部 の中で、特にデータ基盤構築・分析基盤構築からデータ分析までを含む一貫したデータ課題の解決を専門とするのが データソリューション部 です。
弊社では、新たに仲間に加わってくださる方を募集しています。もし、ご興味があれば エントリー をお待ちしております!
今回は、BigQuery で Vertex AI の LLM を使用して SQL のみで RAG を構築する方法についてご紹介します。
この記事はこんな人にオススメ
- BigQuery の SQL のみで LLM を使った問合せシステムを構築したい
- BigQuery ML にて SQL で Vertex AI の LLM を使用できるリモートモデルについて知りたい
- BigQuery ML にて SQL でテキストの Embedding(ベクトル化)とベクトル検索する方法を知りたい
RAG とは

RAG (Retrieval-augmented Generation) とは、質問やプロンプトに対する回答を生成する際に、既存情報を含む外部データベースから関連する情報を取得(Retrieval)し、それを基に回答を生成(Generation)する手法のことです。
この手法を利用することで、ハルシネーション と呼ばれる事実に基づかない回答の生成を避けることができます。
尚、このように根拠のある情報に基づいて、LLM に回答させることを グラウンディング (Grounding) と呼びます。
また、外部データベースから情報を取得する際、事前に既存情報のテキストを Embedding (ベクトル化) しておき、ベクトル検索により情報を取得することで、質問文との類似性が高いテキストを取得することができます。
BigQuery ML のリモートモデルとは
BigQuery ML とは、SQL のみで簡単に機械学習モデルを構築することができるサービスです。
BigQuery ML では リモートモデル を作成でき、これを使用することで BigQuery から Vertex AI エンドポイント や リモートサービスタイプ(Vertex AI が提供する LLM や Cloud Natural Language API)を呼び出すことができます。
そのため、BigQuery 上から SQL で LLM を利用したい場合は、このリモートモデルを使用することになります。
実装
今回は、とあるヘルプデスクへの問合せシステムを想定し、BigQuery の SQL のみで RAG を構築します。システム構成図は、以下の通りになります。

実装する内容は大きく分けて以下の2つになります。
-
既存情報のベクトル化:
既存情報であるヘルプデスクに関するFAQデータを Embedding(ベクトル化)し、ベクトルデータのテーブルに格納します。 -
ベクトル検索とグラウンディング:
質問文を Embedding(ベクトル化)した後、FAQに関するベクトルデータのテーブルに対してベクトル検索し、参考情報を取得します。その後、取得した参考情報に基づいて、質問に対する回答を LLM を用いて生成します。
事前準備
BigQuery Connection API の有効化
こちら を参考に BigQuery Connection API を有効化します。

外部接続の作成
BigQuery コンソールのエクスプローラの [追加] を押下します。
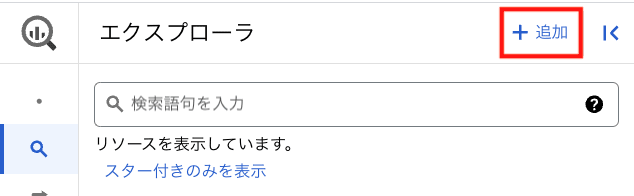
表示された画面にて [一般的なソース] > [外部データソースへの接続] を選択します。

外部データソースとして以下項目を設定し [接続を作成] を押下します。
- 接続タイプ:BigLake とリモート関数(クラウドリソース)
- 接続ID:任意(例:llm_connection)
- ロケーション:BigQuery を実行するロケーション(例:マルチリージョン > US)

外部接続が作成されていることを確認します。


権限設定
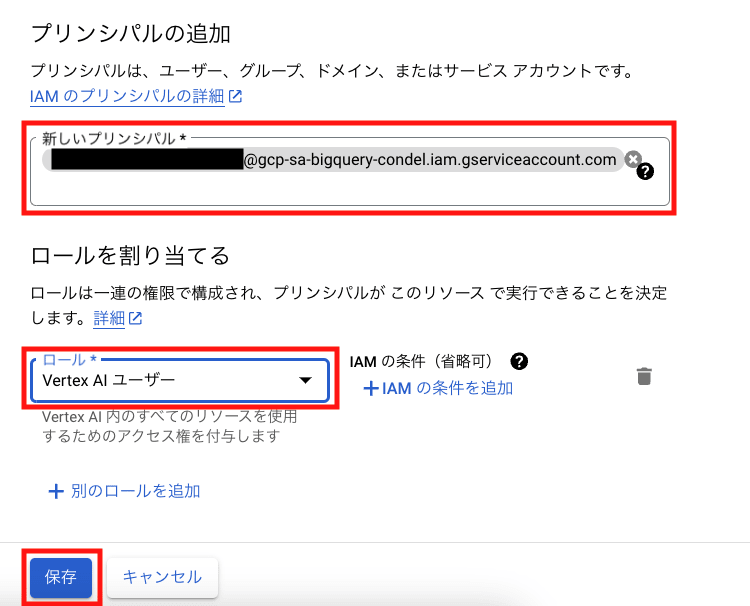
外部接続の作成時に、サービス アカウント(上図の [接続情報] > [サービス アカウント ID])が作成されています。
IAM コンソールから [アクセス権を付与] にて、このサービス アカウントに対して [Vertex AI ユーザー] を付与して保存します。
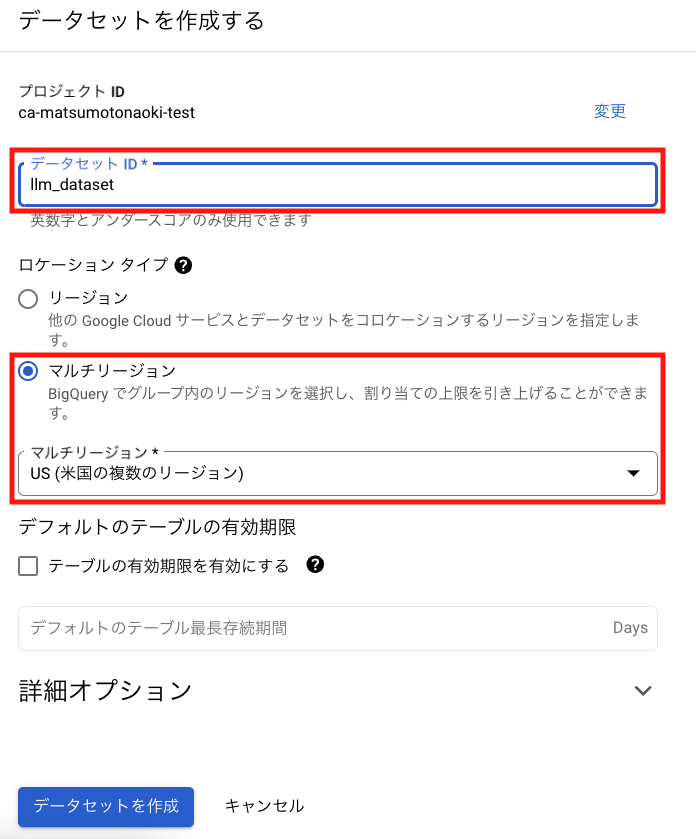
データセットの作成
以下のように BigQuery データセットを作成します。
- データセットID:任意(例:llm_dataset)
- ロケーション:BigQuery を実行するロケーション(例:マルチリージョン > US)
モデルの作成
BigQuery のリモートモデル を作成することで、Vertex AI の LLM を使用することができるようになります。今回は、回答の作成に使用する LLM と テキストのベクトル化に使用する Embedding のリモートモデルを作成します。
LLM のリモートモデル作成
以下のクエリを実行することで、LLM として text-bison のリモートモデルを作成します。
(REMOTE_SERVICE_TYPE:CLOUD_AI_LARGE_LANGUAGE_MODEL_V1 の指定では、text-bison モデルが利用されます)
CREATE OR REPLACE MODEL `project_id.llm_dataset.remote_llm`
REMOTE WITH CONNECTION `us.llm_connection`
OPTIONS (REMOTE_SERVICE_TYPE = 'CLOUD_AI_LARGE_LANGUAGE_MODEL_V1');
Embedding のリモートモデル作成
以下のクエリを実行することで、LLM エンドポイントとして textembedding-gecko-multilingual のリモートモデルを作成します。
CREATE OR REPLACE MODEL `project_id.llm_dataset.embedding`
REMOTE WITH CONNECTION `us.llm_connection`
OPTIONS (ENDPOINT = 'textembedding-gecko-multilingual');
テキストデータのベクトル化
今回は以下のようなヘルプデスクの FAQ に関するサンプルデータを用意し、RAG の外部データソースとして使用します。

ML.GENERATE_TEXT_EMBEDDING 関数 を使用することで、Embedding のリモートモデルを利用して、このテキストデータをベクトル化します。
尚 STRUCT(TRUE AS flatten_json_output) の指定により、JSON データを展開して出力します。
クエリは以下の通りです。
CREATE OR REPLACE TABLE
`project_id.llm_dataset.embedded_data` AS (
SELECT
*
FROM
ML.GENERATE_TEXT_EMBEDDING( MODEL `project_id.llm_dataset.embedding`,
(
SELECT
content
FROM
`project_id.llm_dataset.faq_data` ),
STRUCT(TRUE AS flatten_json_output) ) );
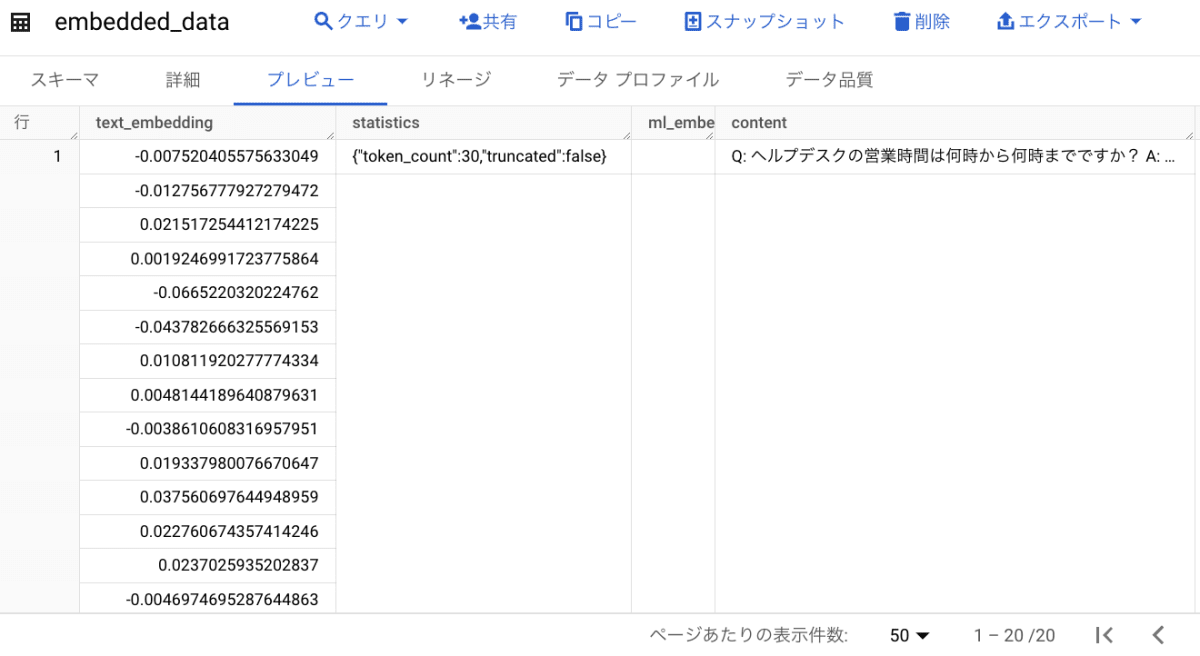
クエリ結果として Embedding されたデータ(text_embedding)が出力されます。
ベクトル検索の結果を用いて LLM から回答を得る
以下の質問文をベクトル化して FAQ データとのベクトル距離(関連度合い)を算出します。
ヘルプデスクへの問い合わせについて、一次回答は何時間以内に得られますか?
ベクトル距離は ML.DISTANCE 関数 によって算出することが可能です。
算出方法として以下のタイプを指定することができますが、今回は一般的によく用いられるコサイン類似度を指定します。
- EUCLIDEAN:ユークリッド距離
- MANHATTAN:マンハッタン距離
- COSINE:コサイン類似度
クエリは以下の通りです。
DECLARE question_text STRING
DEFAULT "ヘルプデスクへの問い合わせについて、一次回答は何時間以内に得られますか?";
WITH
-- 質問文をベクトル化する
embedded_question AS (
SELECT
*
FROM
ML.GENERATE_TEXT_EMBEDDING( MODEL `project_id.llm_dataset.embedding`,
(SELECT question_text AS content),
STRUCT(TRUE AS flatten_json_output))),
-- ベクトル化された FAQ データを取得する
embedded_faq AS (
SELECT
*
FROM
`project_id.llm_dataset.embedded_data` )
-- ベクトル距離(コサイン類似度)を算出する
SELECT
q.content as question,
f.content as reference,
ML.DISTANCE(q.text_embedding, f.text_embedding, 'COSINE') AS vector_distance
FROM
embedded_question AS q,
embedded_faq AS f
ORDER BY
vector_distance
クエリ結果として、ベクトル距離(vector_distance)が 約0.0503 となっている FAQ データのテキスト(reference)が、質問文に対してもっとも関連性が高いデータであると分かります。

この結果の内、もっともベクトル距離が近いテキストをプロンプトに含めて質問文に対する LLM の回答を生成するよう、以下のようにクエリを修正します。
尚、ML.GENERATE_TEXT 関数 により、リモート モデルの LLM を使用して、回答を生成することができます。今回、ML.GENERATE_TEXT 関数の引数として以下を設定します。その他引数に関しては こちら をご参照ください。
- temperature :レスポンスのランダム性を制御するプロンプト パラメータであり、この値が小さいほど関連度が高くなる
- max_output_tokens:レスポンスに含める単語数
DECLARE question_text STRING
DEFAULT "ヘルプデスクへの問い合わせについて、一次回答は何時間以内に得られますか?";
WITH
-- 質問文をベクトル化する
embedded_question AS (
SELECT
*
FROM
ML.GENERATE_TEXT_EMBEDDING( MODEL `project_id.llm_dataset.embedding`,
(SELECT question_text AS content),
STRUCT(TRUE AS flatten_json_output))),
-- ベクトル化された FAQ データを取得する
embedded_faq AS (
SELECT
*
FROM
`project_id.llm_dataset.embedded_data` ),
-- ベクトル距離(コサイン類似度)がもっとも近い FAQ データを取得する
search_result AS (
SELECT
q.content as question,
f.content as reference,
ML.DISTANCE(q.text_embedding, f.text_embedding, 'COSINE') AS vector_distance
FROM
embedded_question AS q,
embedded_faq AS f
ORDER BY
vector_distance
LIMIT 1),
-- プロンプトを作成する
prompt_text AS (
SELECT
CONCAT(
'以下の参考情報を踏まえて、質問文に対して回答してください。',
' 質問文:', question,
' 参考情報:', reference
) AS prompt
FROM
search_result
)
-- LLM の回答を得る
SELECT
STRING(ml_generate_text_result.predictions[0].content) AS answer
FROM
ML.GENERATE_TEXT( MODEL `project_id.llm_dataset.llm`,
(SELECT * FROM prompt_text),
STRUCT(
0.2 AS temperature,
1000 AS max_output_tokens));
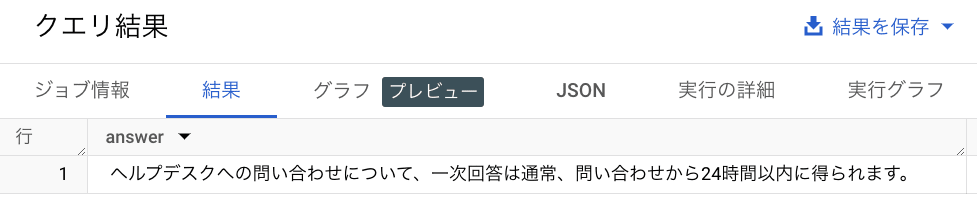
このクエリを実行すると、FAQ データの情報を参考にした回答を得ることができます。
Appendix
機密データの保護について
LLM を使用する際は、機密データの扱いについて気を付けておく必要があります。
今回のように BigQuery にて LLM を使用した場合も例外ではありません。

出典:機密データの保護による生成 AI ワークロードの安全確保
既存情報となる外部データベースや質問文・回答文に対して、機密データの保護を行う必要がありますが、Sensitive Data Protection(旧 Cloud Data Loss Prevention) を使用することで機密データを保護することが可能です。
参考
まとめ
今回は、BigQuery で Vertex AI の LLM を使用して SQL のみで RAG を構築する方法についてご紹介しました。一般的に RAG 構築する際は、LangChain や LlamaIndex と呼ばれる LLM の機能拡張ライブラリを活用することが多いですが、複雑な構成でなければ、今回ご紹介した BigQuery の SQL での実装方法が簡単でオススメですので、ぜひお試しください。
Discussion