はじめまして、ますみです!
株式会社Galirage(ガリレージ)という「生成AIに特化して、システム開発・アドバイザリー支援・研修支援をしているIT企業」で、代表をしております^^

本日は、Galirageの「CRO(Chief Research Officer)である越原さん」の現地レポートを紹介します!
越原さんは、かなり抽選確率の低い「OpenAI DevDay 2024」へのチケットを獲得し、現地参加してきました!(彼は本当に何かを持っています笑)
それでは、越原さんが執筆してくださった貴重なレポートは、下記の通りです^^
執筆者の紹介
株式会社GalirageのCRO(Chief Research Officer)の「越原 崚」です。
普段は、大手企業への生成AIコンサルティングや、最新の生成AI研究を行っています(これまで20以上の生成AIプロジェクトに参画)。
さらに、直近では「Galirage Research」という研究部門を立ち上げ、約22名の仲間と共に、最新のLLMのR&Dを行っています。
私自身、2023年の春にGPT-4がリリースされた時は、寝食を忘れて研究していたほど、LLMの技術が大好きです。
今回、OpenAI DevDay 2024のサンフランシスコの会場に参加したので、現地でのディスカッション内容も交えながら、新機能について解説していきます!

OpenAI DevDay 2024とは?
OpenAI DevDay 2024とは、「OpenAI社が開催する開発者向けのカンファレンス」です。
今年は、サンフランシスコ、ロンドン、シンガポールの3都市で開催されています。
現地の会場では、新しくリリースされた機能の発表だけでなく、「OpenAIのエンジニアの方々との交流の機会」もありました。
OpenAI DevDay 2024で発表された新機能
- Realtime API
- Prompt Caching
- Model Distillation
- Vision Fine-tuning
現地で特に盛り上がったのは、Realtime APIの発表でした!
1. Realtime API
Realtime APIとは、「リアルタイムでのSpeech-to-SpeechができるAPI」です。
Speech-to-Speechとは、GPT-4oなどのマルチモーダルAIが、音声を入力として受け取り、音声を出力するEnd-to-Endのモデルです。

Realtime APIでは、Speech-to-Speechの処理を一つのモデルの中で完結させることができる(いわゆるEnd-to-Endのモデルである)ため、応答速度が大幅に改善されました。
また、Realtime APIの特徴の一つとして、音声データに含まれる「感情」「アクセント」「トーン」などの情報を生成AIが直接処理できる点が挙げられます。
これにより、テキストデータでは伝わりにくい音声特有のニュアンスを反映した、より自然な対話が可能になります。
その他の機能としては、合成音声の話者を選択できたり、Function callingを用いて外部ツールと連携させることが可能です。

Realtime APIの内部処理について
内部の処理については、Websocketを使用して、リアルタイムでの音声データの送受信を行っています。
Websocketとは、「クライアントとサーバー間で双方向のリアルタイム通信」を可能にするプロトコルです。これにより、音声データの送受信をリアルタイムで行うことができます。

既存の技術との違い
既存の技術では、まず入力された音声(audio)をWhisperなどの音声認識モデルでテキストに変換します。その後、GPT-4oなどの言語モデルで応答を生成し、最後にText-to-Speechモデルで音声を合成するという手順を踏んでいました。
このような手法を採用していたツールとして、ChatGPTの「Voice Model」があります。
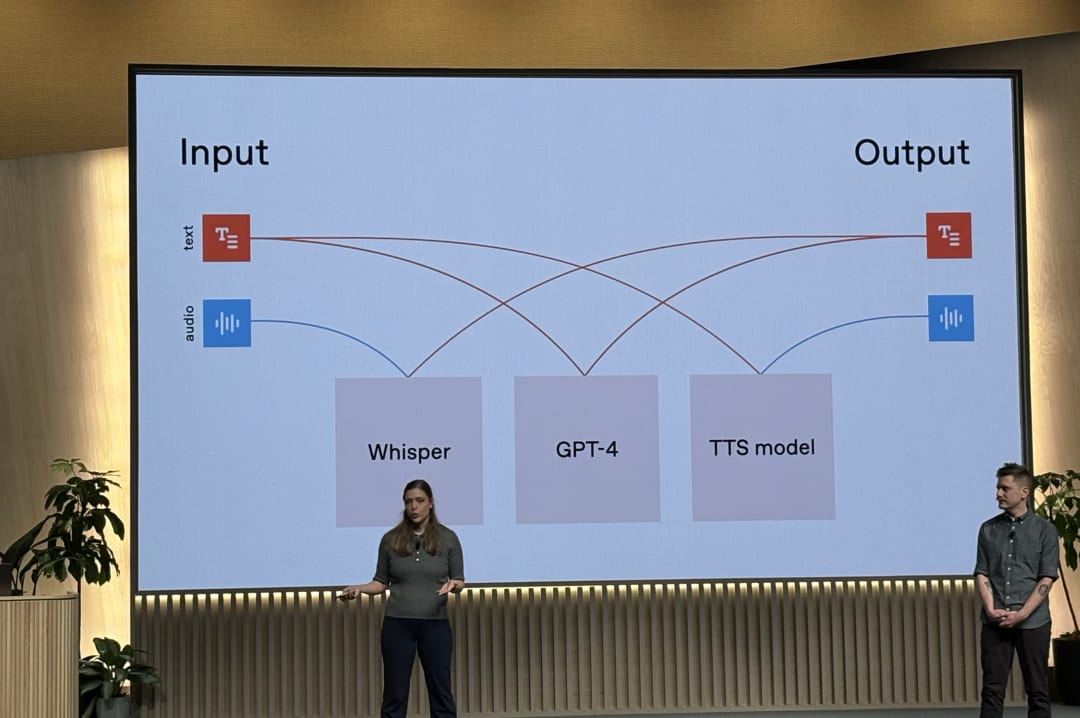
このような実装方法では、回答を読み上げるまでの応答速度が遅く、「ユーザーの待ち時間が長くなる」という課題がありました。
また、生成AIは、回答を生成している間は、ユーザーの新たな質問を処理することができないので、ユーザーはAIの回答を最後まで待つ必要がありました。
私自身、生成AIの「電話応対システム(ユーザーが電話をかけたら、音声の指示に対して、生成AIで回答文を生成して、機械音声で読み上げるシステム)」を案件でに参画したことがあるため、実際に全く同じ課題に直面したことがあります。
一方で、Realtime APIでは、先述した通り、Speech-to-Speechの処理を一つのモデルの中で完結させることができる(いわゆるEnd-to-Endのモデルである)ため、応答速度がかなり速い上、回答生成中であっても、処理を中断させて、指示を入り込ませることができる機能を実装可能です。
ここで、既存技術との違いをまとめると以下の通りです。
| 既存技術 | Realtime API | |
|---|---|---|
| 応答速度 | △ 遅い | ◎ 速い |
| 「感情・アクセント・トーン」の直接処理 | × 不可 | ◎ 可能 |
| 回答生成中での指示の入り込み | × 不可 | ◎ 可能 |
Realtime APIの実行方法
OpenAI DevDayの会場で紹介されていたようなデモができるソースコードが公開されていたので、ぜひ皆さんも試してみてください!
2. Prompt Caching
Prompt Cachingとは、「GPT-4oなどの言語モデルにおいてプロンプトをキャッシュする機能(過去に指示された生成結果を再利用する機能)」です。
Prompt Cachingでは、過去に使用されたプロンプトであれば、回答結果を再利用することができ、「API利用料金の割引」や「リクエストの処理時間の短縮」につながります。
この機能では、1024トークン以上のプロンプトに自動的に適用され、キャッシュされた部分に対して50%の割引が適用されます。
この時、出力トークンには割引は効かず、入力トークンのみが割引対象となります。
現時点で対応しているモデルは、次の通りで、自動的に適応されるそうです(もしかしたらパッケージのアップデートなどが必要かもしれないため、念のため有効になっているか確認することを推奨します)。
- gpt-4o
- gpt-4o-mini
- o1-preview
- o1-mini

Prompt Cachingの内部処理について
内部の処理については、主に3つのステップで構成されています。
- キャッシュの検索:入力されたプロンプトの冒頭部分(プレフィックス)がキャッシュに保存されているかを確認
- キャッシの一致:一致するプレフィックスが見つかった場合、キャッシュされた結果を使用
- キャッシュの不一致:一致するプレフィックスが見つからない場合、プロンプト全体を処理
- キャッシュの追加:キャッシュされていない1024トークン以上のプロンプトは、キャッシュに追加
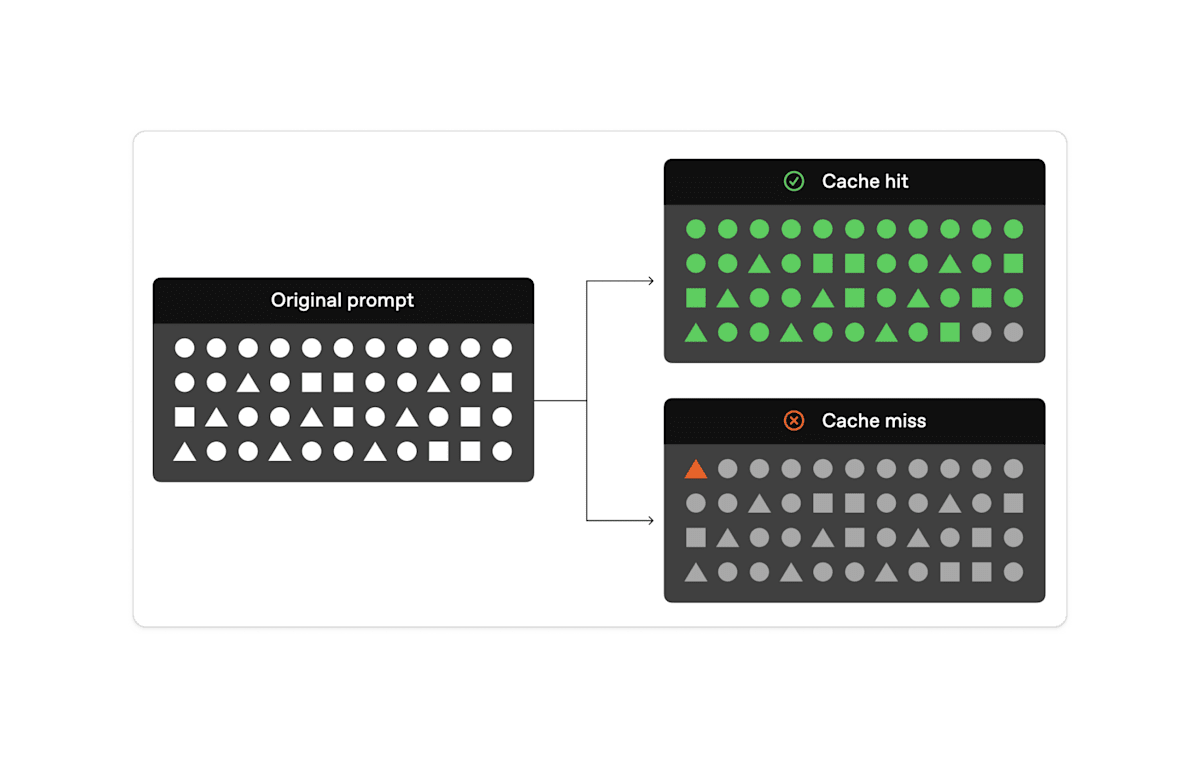
キャッシュの保持期間は、使用頻度と最後の使用時間に基づいて管理されています。キャッシュは5分から10分間使用されない状態が続くと自動的にクリアされます。
また、頻繁に使用されているキャッシュであっても、最後の使用から、1時間が経過すると必ず削除されます。
3. Model Distillation
Model Distillation(モデル蒸留)とは、「OpenAIのGPT-4oなどの高精度なモデルの出力を使って、GPT-4o-miniなどの小型のモデルをファインチューニングするプロセスを簡素化した機能」です。
この機能により、開発者はOpenAIプラットフォーム上でモデルの蒸留(Distillation)が可能になり、デプロイしたモデルを利用することができます。

Model Distillationの主要機能
Model Distillationの主な機能は、次の3つです。
3-1. Stored Completions
APIを通じて生成されたモデルの入出力ペアを自動的にキャプチャして、保存する機能です。
小型モデルの学習データに使用したい場合、Chat Completionsの、storeフラグをtrueに設定することで、Stored Completionsにデータを保存できます。
import OpenAI from "openai";
const openai = new OpenAI();
const response = await openai.chat.completions.create({
model: "gpt-4o",
messages: [
{ role: "system", content: "You are a corporate IT support expert." },
{ role: "user", content: "How can I hide the dock on my Mac?"},
],
+ store: true,
metadata: {
role: "manager",
department: "accounting",
source: "homepage"
}
});
console.log(response.choices[0]);
これにより、開発者は本番データを使用してデータセットを簡単に構築し、モデルの評価やファインチューニングに利用できます。
3-2. Evals(ベータ版)
プラットフォーム上でカスタム評価を作成・実行し、特定のタスクにおけるモデルのパフォーマンスを測定する機能です。
Stored Completionsのデータや既存のデータセットを使用して評価が可能です。
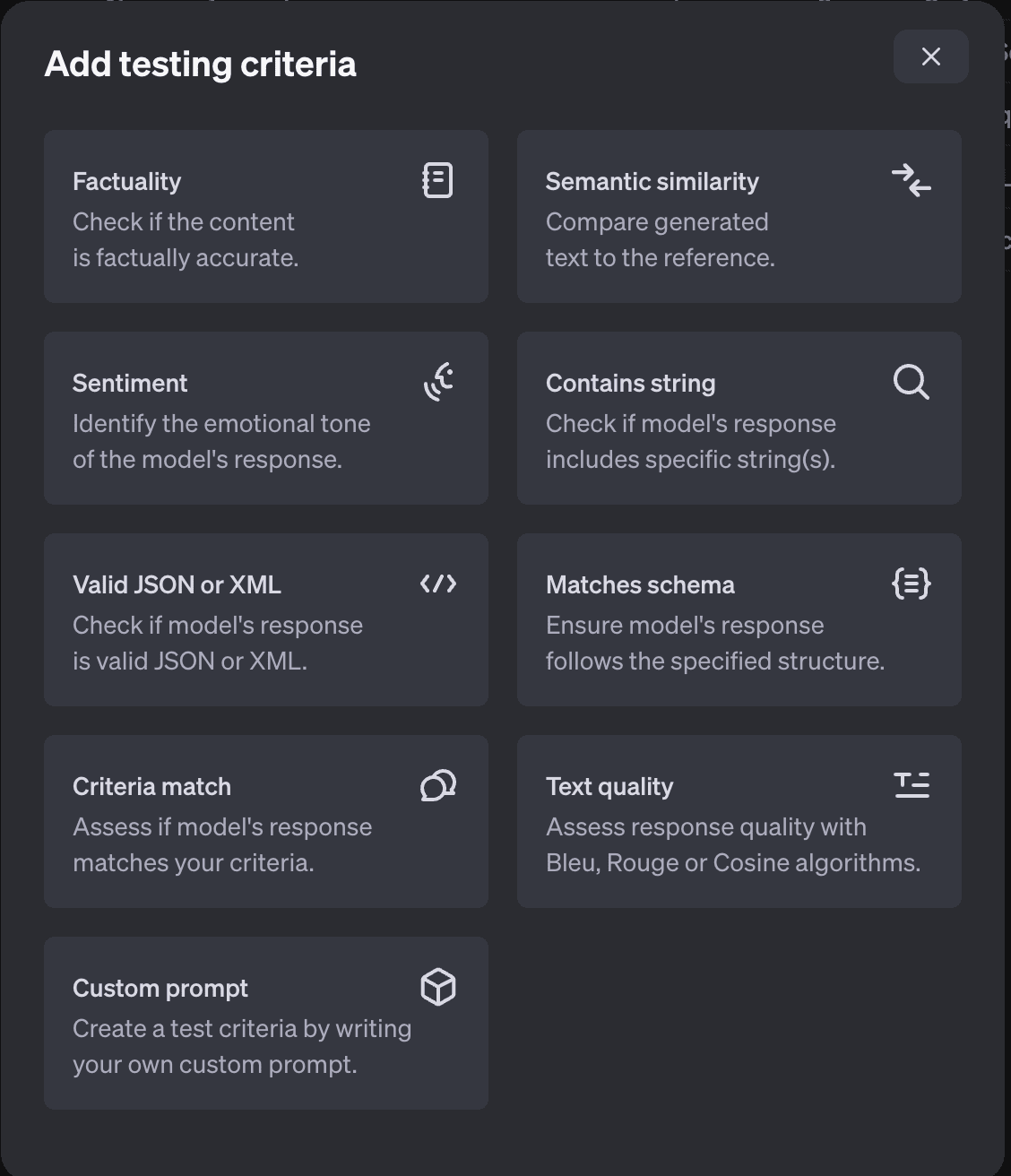
評価メトリクスは、次の9つの評価指標から選択可能になります。
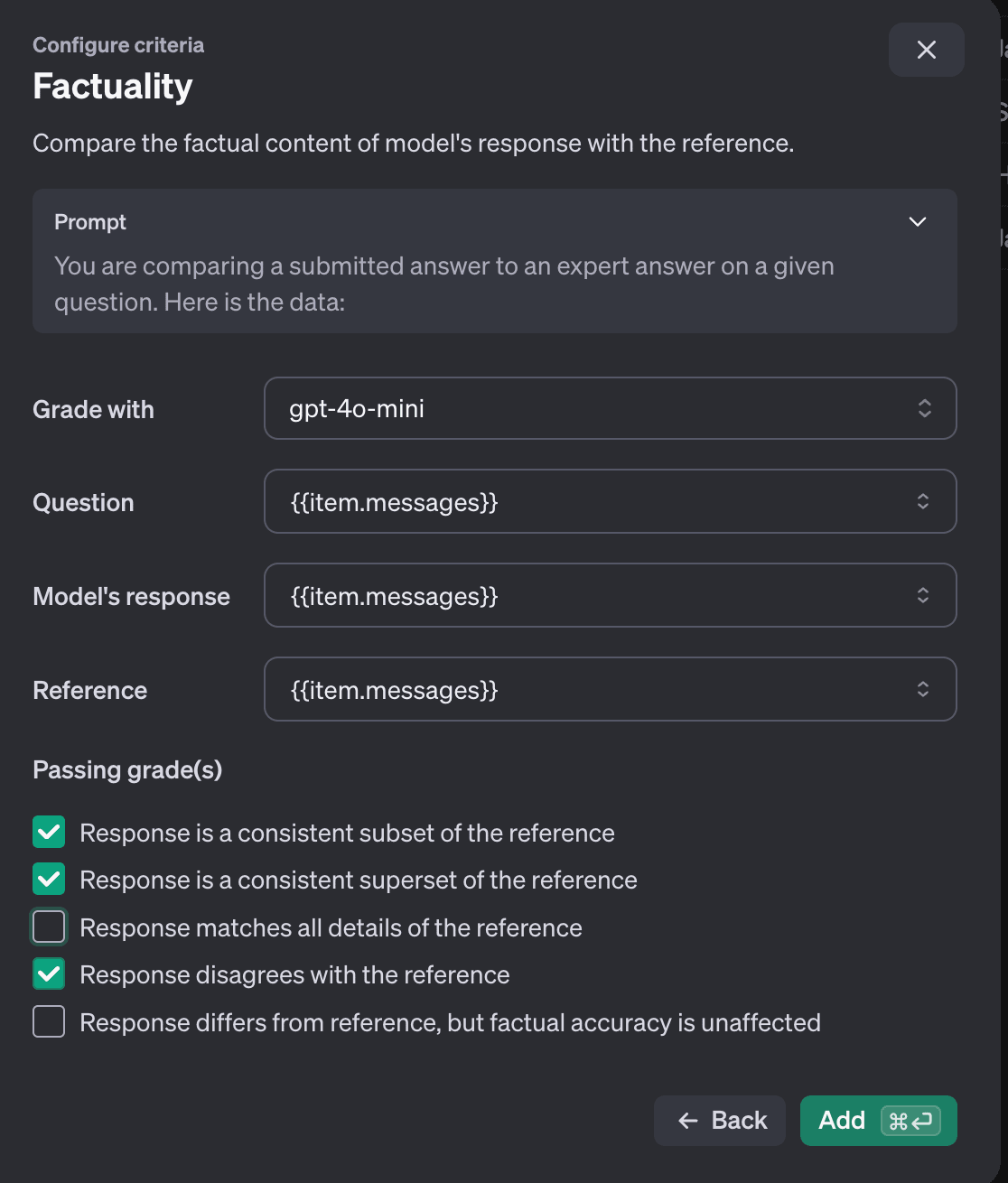
- Factuality:モデルの出力を専門家の回答と比較し、事実に基づいた正確さを評価する指標です。
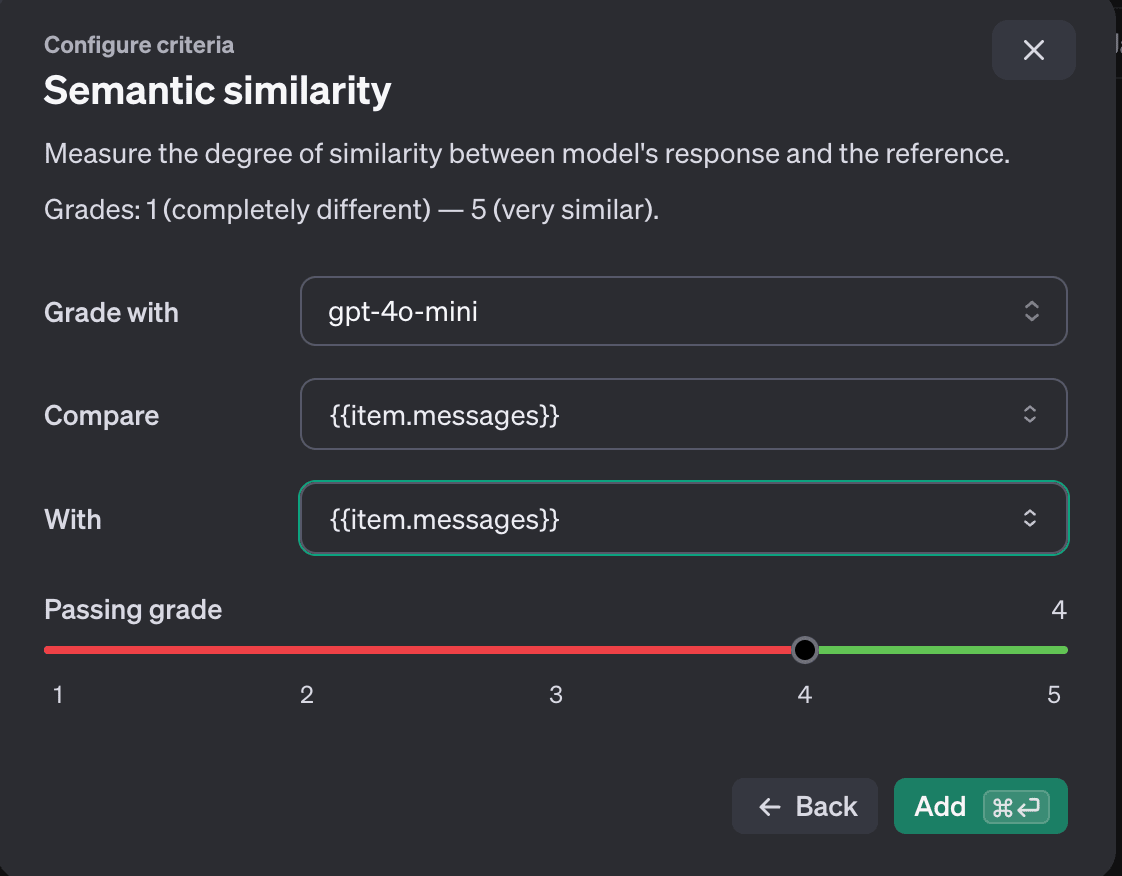
- Semantic similarity:モデルの出力と参照回答の意味的な類似度を測定する指標です。文章の表現や構造が異なっていても、内容の類似性を1(全く異なる)から5(非常に似ている)のスケールで評価します。
- Sentiment:モデルの出力に含まれる感情的なトーンを識別し評価する指標です。回答の感情を「ネガティブ」「中立」「ポジティブ」の3段階で分類します。
- Contains string:モデルの出力に特定の文字列が含まれているかを確認する指標です。
- Valid JSON or XML:モデルの出力が有効なJSONまたはXML形式であるかを検証する指標です。
- Matches schema:モデルの出力が指定されたJSONスキーマに準拠しているかを確認する指標です。
- Criteria match:モデルの出力が設定された基準に合致しているかを評価する指標です。会話の履歴と回答を考慮し、指定された基準に基づいて出力を判断します。
- Text-quality:モデルの出力を参照テキストと比較し、テキストの品質を評価する指標です。Bleu(翻訳の質)、Rouge(要約や翻訳の質)、Cosine(ベクトル空間での類似度)などのアルゴリズムを使用して測定します。
- Custom prompt:ユーザーが独自のテスト基準を作成できる柔軟な評価指標です。
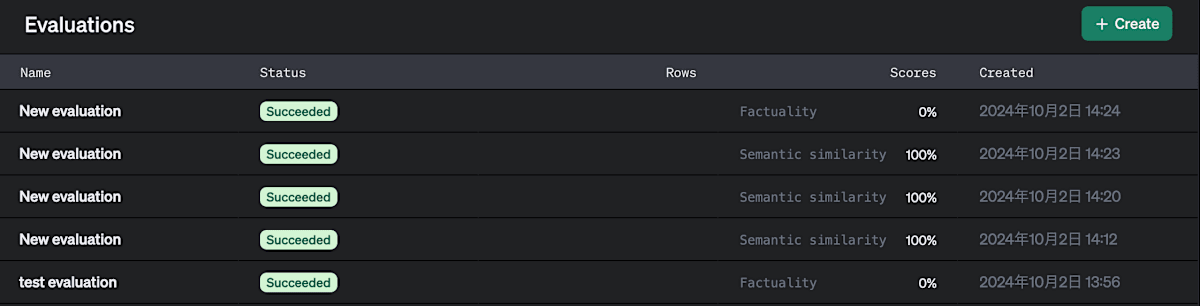
実際にサンプルの会話データを作成し、Evalsを使用してgpt-4o-miniの性能を評価してみました。
「Factuality」「Semantic similarity」を使用して、モデルの性能を評価しました。今回は、Factualityを使用すると、Scoreが0%になり、Semantic similarityを使用すると、Scoreが100%になりました。
今回の結果では、適切に評価するために評価指標を調整する必要はありそうですが、Evalsを使用することで、モデルの性能評価が簡単に行えることがわかりました。
3-3. Fine-tuning
Stored Completionsで作成したデータセットをファインチューニングジョブで使用し、Evalsを使用してファインチューンされたモデルの評価を行うことができます。
ファインチューニングのコストについては、GPT-4oとGPT-4o miniモデルは、2024年10月31日までの期間限定で、毎日一定量のトークンまでファインチューニングを無料で行えます。
具体的には、GPT-4oで1日100万トークン、GPT-4o miniで1日200万トークンまでが無料です。この上限を超えた場合、GPT-4oでは100万トークンあたり25ドル、GPT-4o miniでは100万トークンあたり3ドルの通常料金が適用されます。
詳細については、OpenAIの公式の料金ページをご確認ください。
Model Distillationの利用方法は以下の通りです。
- 蒸留したいモデル(例:GPT-4o mini)のパフォーマンスを測定するための評価メトリクスを設定します。
- Stored Completionsを使用して、より高性能なモデル(例:GPT-4o)の出力を含むデータからなる蒸留したデータセットを作成します。
- このデータセットを使用して、小規模モデル(GPT-4o mini)をファインチューニングします。
- ファインチューニングされたモデルが性能基準を満たしているかどうかを、Evalsを使用して再度テストします。
4. Vision Fine-tuning
Vision Fine-tuningとは、「OpenAIのビジョンモデルを特定のタスクやデータセットに適応させるためのファインチューニング機能」です。
これにより、画像データに対するモデルの性能を向上させ、より高度な画像認識や解析が可能になります。

従来、画像処理タスクでは大量のデータと時間を要するモデルのトレーニングが必要でした。
しかし、Vision Fine-tuningを使用することで、既存の強力なビジョンモデルをベースに、自社のデータセットに合わせて効率的にモデルを微調整することができます。
開発者は、画像とテキストを組み合わせたデータセットを指定されたフォーマットで準備します。
わずか100枚程度の画像でもモデルの性能を向上させることができ、より大規模なデータセットを使用すればさらなる性能向上が期待できます。
内部的には、モデルが画像データをトークン化し、テキストデータと一緒に処理することで、画像の内容を理解し、テキストと組み合わせた高度なタスクを実行することが可能になります。
OpenAI DevDayでは、Grab社がVision Fine-tuningを活用して道路標識や車線情報の認識精度を向上させ、車線数の認識精度が20%、速度制限標識の認識が13%向上した事例が印象的でした。
最後に
最後まで読んでくださり、ありがとうございました!
この記事を通して、少しでもあなたの学びに役立てば幸いです!
宣伝:もしもよかったらご覧ください^^
『AIとコミュニケーションする技術(インプレス出版)』という書籍を出版しました🎉
これからの未来において「変わらない知識」を見極めて、生成AIの業界において、読まれ続ける「バイブル」となる本をまとめ上げました。
かなり自信のある一冊なため、もしもよろしければ、ご一読いただけますと幸いです^^
参考文献

株式会社Galirageのテックブログです! Galirageでは、生成AIのシステム開発・コンサルティング・研修を行なっております。 ▼ 問い合わせ先 ▼ info@galirage.com
Discussion