はじめまして、ますみです!
株式会社Galirage(ガリレージ)という「生成AIに特化して、システム開発・アドバイザリー支援・研修支援をしているIT企業」で、代表をしております^^

この記事では、「文字数制限のないChatGPTを実装するためのアルゴリズム」を解説します!
ChatGPTやLangChainやについてまだ詳しくない方は、こちらを先にご覧ください◎
1. 背景
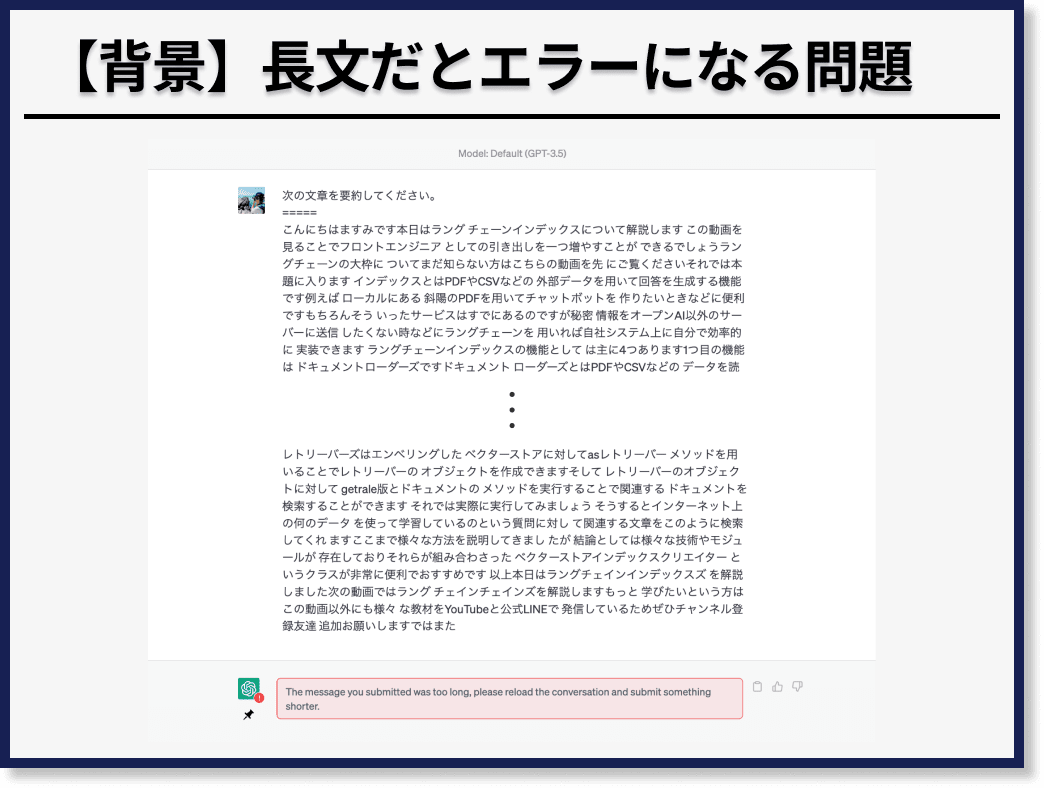
まず背景として、ChatGPTのウェブサービスでは、長文の文章を送信すると、エラーになってしまいます。
たとえば、次のように「次の文章を要約してください」という指示のもと、長文を入力すると、エラーになります。
現在(2023年5月)、GPT-3.5が扱えるテキストの長さは、最大4097トークンで、日本語1文字が2トークンと仮定した場合、約8000文字が限界の文字数になります。
GPT-4では、約2倍と約8倍のトークン数に対応したバージョンがありますが、いずれにせよ上限は決まっています。
ここで、先ほど例示したような「次の文章を要約してください」という「指示文の文字列」と「要約をしたい対象の文章」である「使用データの文字列」に分けることができます。
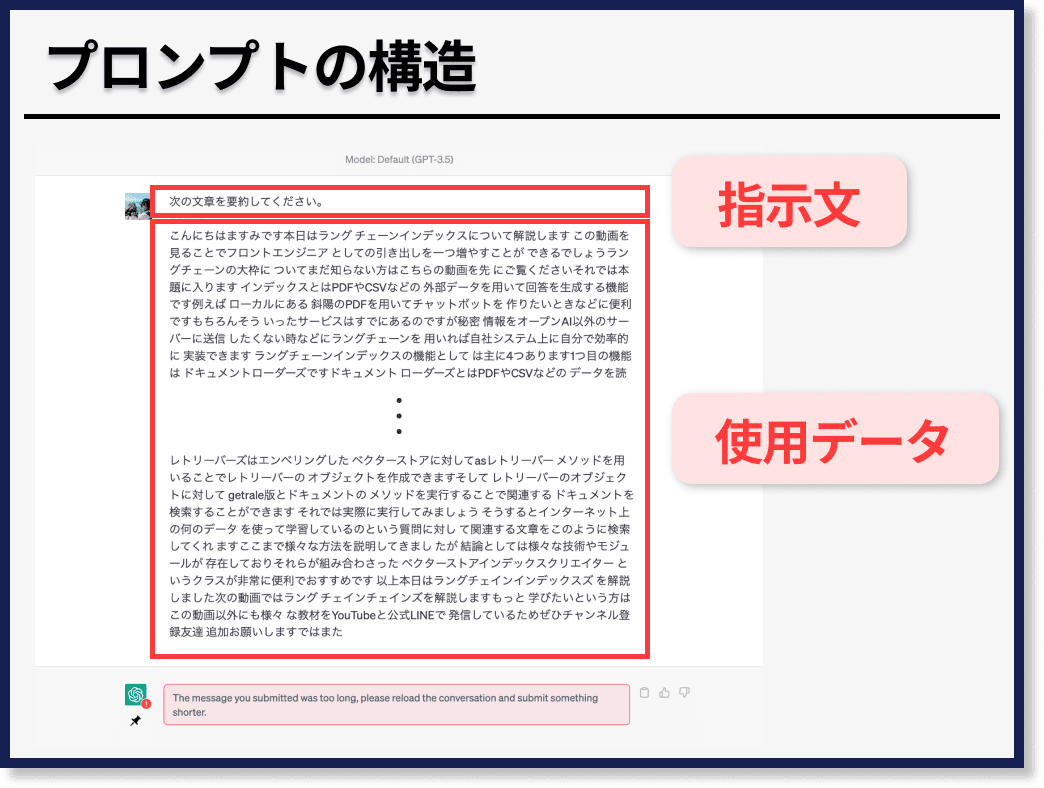
ここから、この「指示文の文字列」と「使用データの文字列」がそれぞれ長文になってしまう場合の対処法を解説します。
2. 「指示文の文字列」が長文の時の対処法
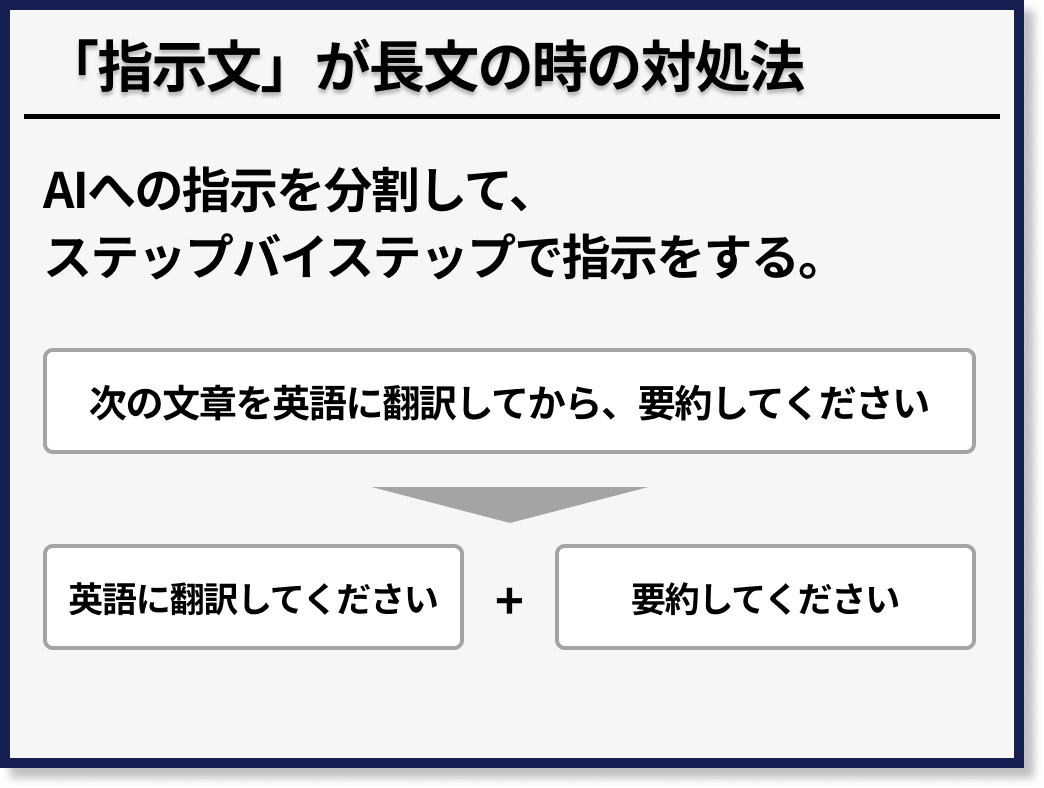
「指示文の文字列」が長すぎる場合は、AIへの指示を分割して、ステップバイステップで指示をすることで問題を解決することができます。
たとえば、「次の文章を英語に翻訳してから、要約してください」という指示の場合、「英語に翻訳する」という指示と「要約をする」という指示に分割することができます。
実際に、このような指示の分割をプログラミングで実装したい場合は、LangChain Chainsというモジュールがかなり役に立ちます。
3. 「使用データの文字列」が長文の時の対処法
「使用データの文字列」が長すぎる場合は、使用データの中から「指示文と関連する文章を抽出する方法」とデータを分割して「分割されたデータの塊に対してそれぞれ処理する方法」があります。
- 指示文と関連する文章を抽出する方法(RAG: Retrieval-Augmented Generation)
- 分割されたデータの塊に対してそれぞれ処理する方法
3-1. 指示文と関連する文章を抽出する方法(RAG: Retrieval-Augmented Generation)
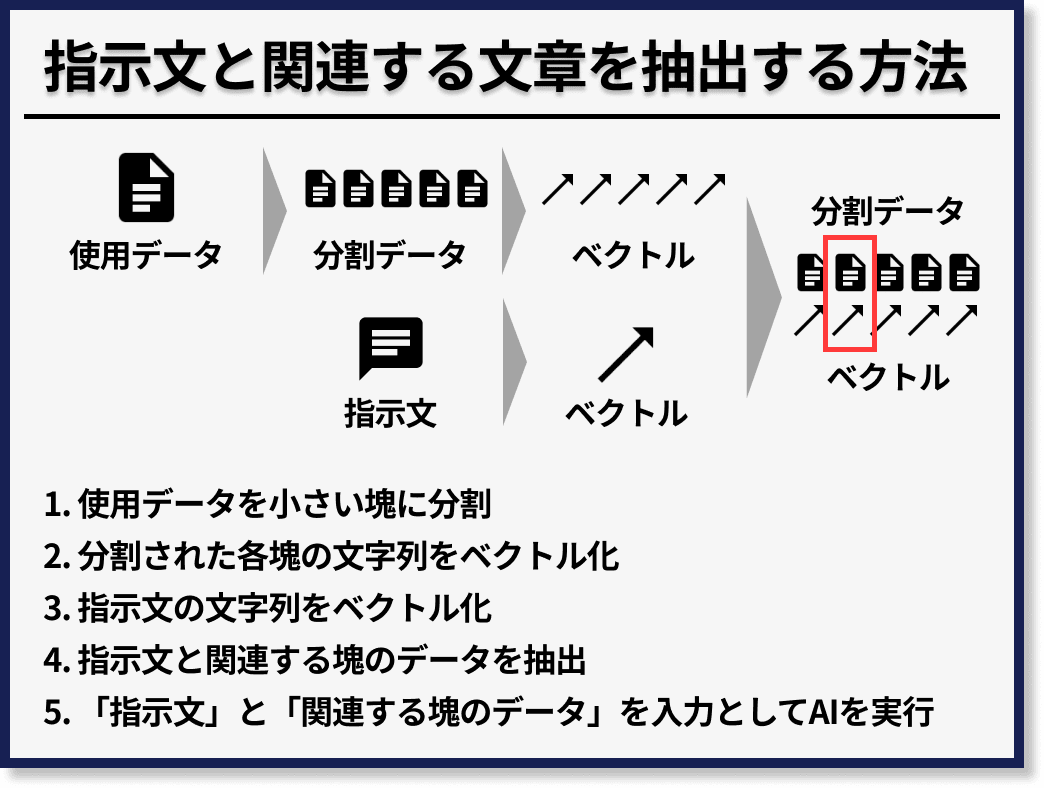
一つ目の「指示文と関連する文章を抽出する方法」では、まず使用データの文字列をプロンプトに入力可能な長さの文の塊(日本語であれば1000文字程度 | 8000文字だと指示文と合計して4097トークンを超える可能性があるため、余裕を持って設定する)に分割します。
次に、分割された各塊の文字列をベクトル化(すなわちEmbedding)します。
そして、指示文の文字列もベクトル化して、指示文と関連する文字列を分割された使用データの塊たちの中から抽出します。
最後に、指示文の文字列と、抽出された関連度の高い使用データの文字列を入力として、ChatGPTなどのAIを実行します。
結果的に、使用データの文字列が短くなるため、実行が可能になります。
まとめると次の手順で実装することができます。
- 使用データを分割
- 分割された各塊の文字列をベクトル化
- 指示文の文字列をベクトル化
- 指示文と関連する塊のデータを抽出
- 指示文と関連する塊のデータを入力としてAIを実行
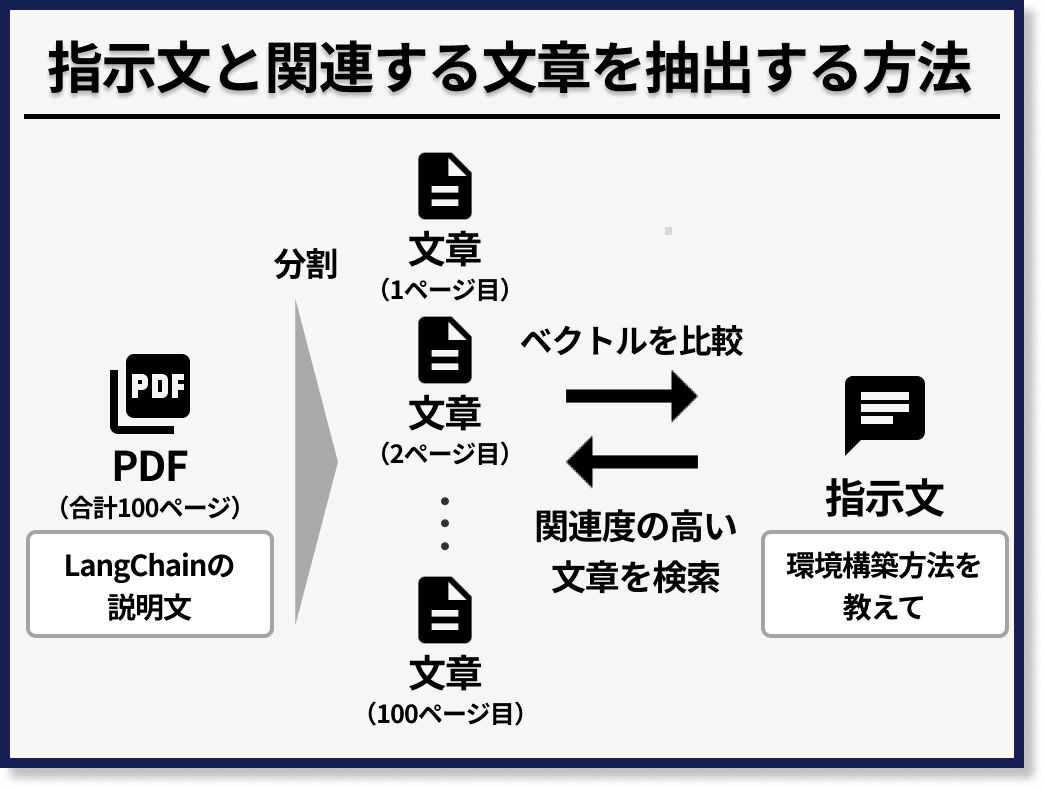
たとえば、LangChainについて説明した100ページのPDFがあったとします。このとき、このPDFの中の文章を1ページごとに分割して、各ページの文章をベクトル化します。
そこに「LangChainの環境構築方法を教えて」と指示したとします。
そしたら、この指示文をベクトル化して、PDFの各ページのベクトルと比較して、ベクトルが近いページを特定します。
すると、LangChainの環境構築に関して説明したページがヒットするため、その「LangChainの環境構築」について説明したページの文字列と「LangChainの環境構築方法を教えて」という文字列を一緒にChatGPTに入力することで、回答を得ることができます。
このエンべディングを使ったアルゴリズムのメリットとしては、ChatGPTなどのLLMの実行回数が1回で済むことがあげられます。
デメリットとしては、使用データのすべての情報を加味できない点があげらえます。
また、補足をすると、この手法はエンべディングを行う際にOpenAIのAPIを使用する場合は、ChatGPTなどのLLMのAPI料金と別に、API料金が発生します。
最後に、この手法を実装したい場合は、以前解説したLangChain Indexesという手法をご参照ください。
ここまで、「指示文と関連する文章を抽出する方法」を説明してきました。
3-2. 分割されたデータの塊に対してそれぞれ処理する方法
次に、「分割されたデータの塊に対してそれぞれ処理する方法」を説明します。
この手法には、現在3種類のアルゴリズムが存在します。
- Map Reduce
- Map Rerank
- Refine
それでは、「次の文章を要約してください」という指示を「長文の文字列」に対して実行したい例をもとに、順番に説明していきます。
Map Reduce
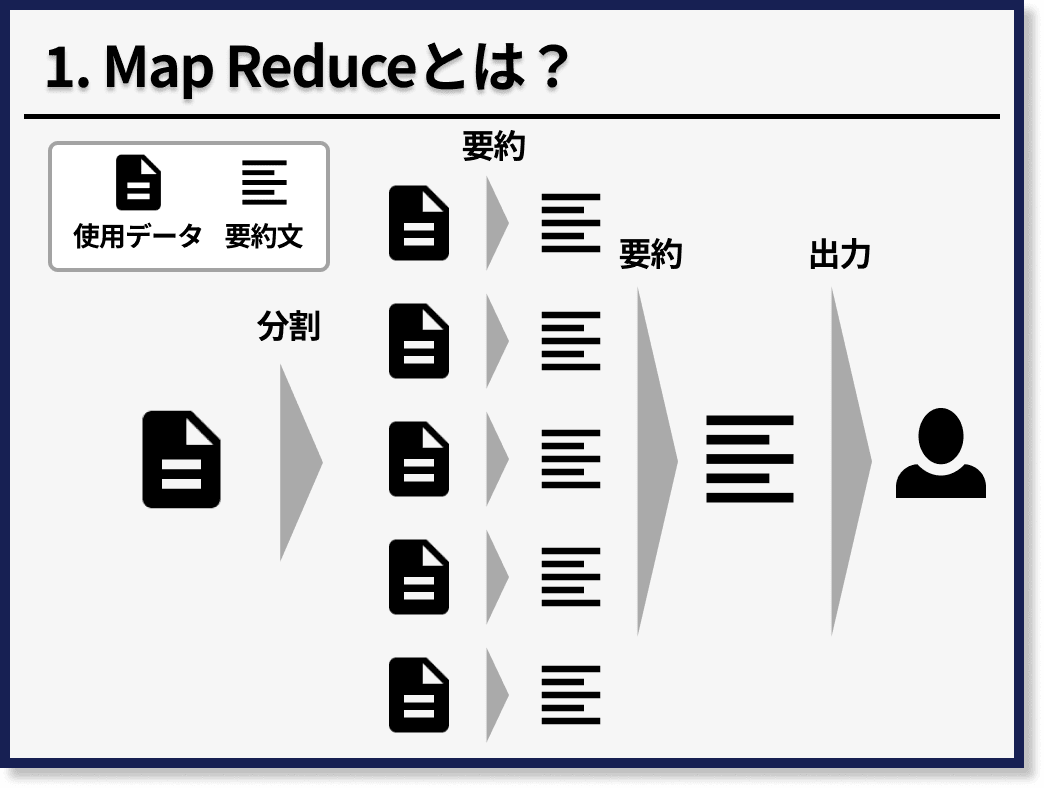
まずMap Reduceとは、長文の文章を分割して、それぞれの塊に対して、指示文を実行して、最後にその結果を統合して、再度指示文を実行する方法です。
たとえば、10,000文字の文章に対して要約をかけたい場合、まず5分割して2,000文字ずつの塊にします。
次に、2,000文字の各塊に対して、要約をかけて400文字になるとします。最後に、5つの400文字の要約文を統合して、再度要約をかけます。
Map Reduceのメリットとしては、後述するRefineの手法と比べて、分割された各文章に対して、並列処理が実行可能なため、高速で処理ができる点があげられます。
一方で、デメリットとしては、先述した「Embeddingをして、関連文章を検索する方法」に比べて、ChatGPTなどのLLMの実行回数が多くなってしまう点があげられます。
Map Rerank
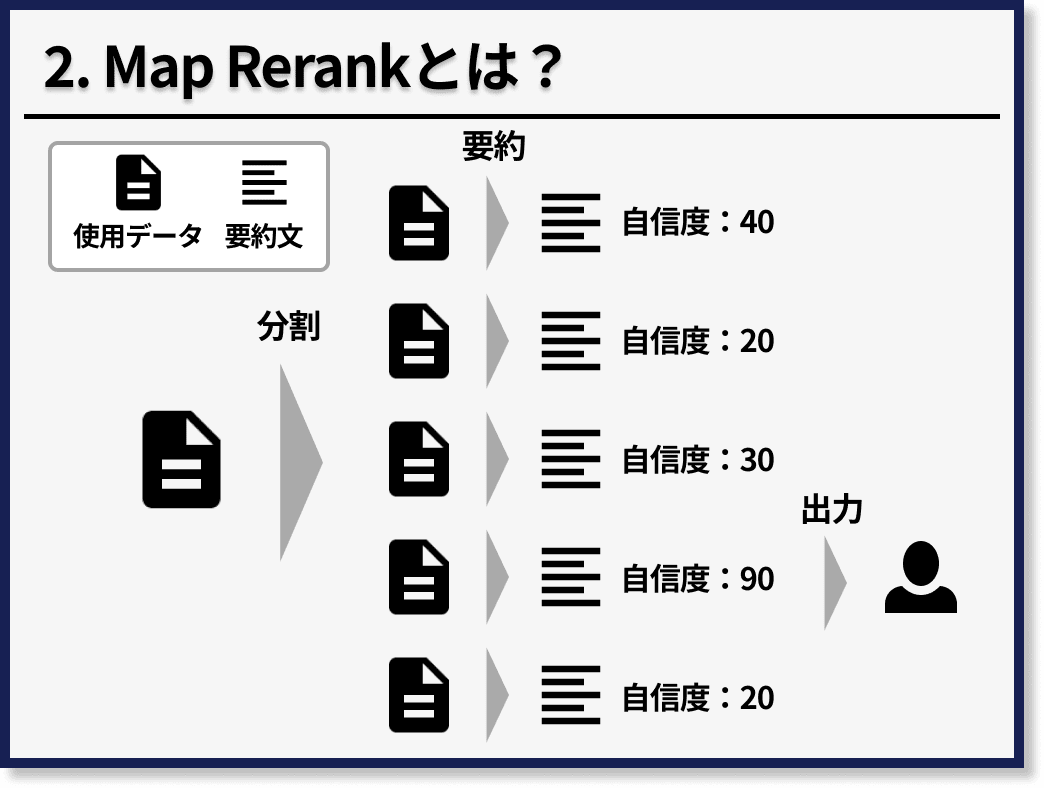
次に、Map Rerankとは、長文の文章を分割して、それぞれの塊に対して、指示文を実行して、最後にその結果の中で、AIが最も自信のある回答を採用する方法です。
先ほど、のMap Reduceとの違いとしては、最後に再度指示文を実行するのではなく、自信度が高い結果を採用する点です。
たとえば、先度と同様に、10,000文字の文章に対して要約をかけたい場合、まず5分割して2,000文字ずつの塊にします。次に、2,000文字の各塊に対して、要約をかけて400文字になるとします。この時、AIに対して、その要約に対する自信度も出力するようにします。最後に、5つの400文字の要約文の中で最も自信度の高い要約を採用します。
Map Rerankのメリットとしては、もしも元の使用データの文字列の中で、欲しい情報が一箇所に特異的に存在する場合、他の文章におけるノイズが混入しないため、「Map Reduce」に比べて、精度が高くなる可能性がある点が挙げられます。
また、Map Reduceと同様に並列処理が実行可能なため、高速で処理ができるという点もメリットになります。
一方で、デメリットとしては、もしも元の使用データの文字列の中で、欲しい情報が散らばっている場合、「Map Reduce」に比べて、精度が低くなる可能性がある点が挙げられます。
Refine
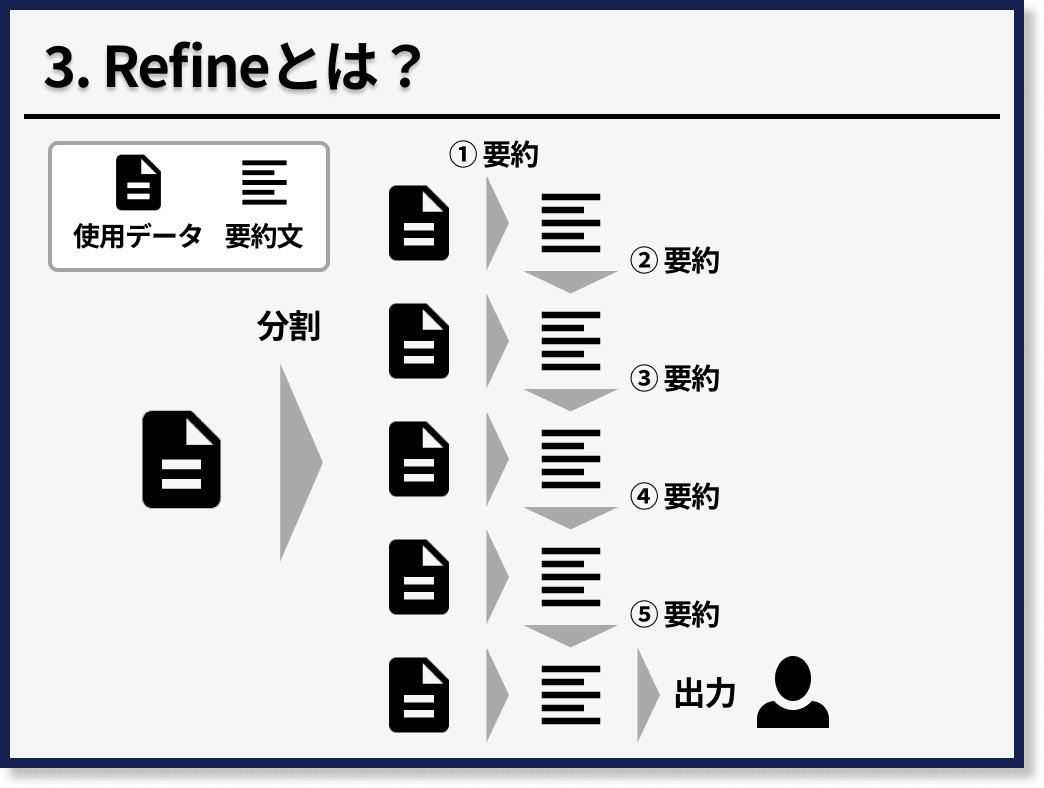
最後に、Refineとは、長文の文章を分割して、最初の塊に対して、指示文を実行し、その結果と次の塊を統合して、指示文を実行することを繰り返していくリレー形式の方法です。
たとえば、先度と同様に、10,000文字の文章に対して要約をかけたい場合、まず5分割して2,000文字ずつの塊にします。
次に、最初の2,000文字の塊に対して、要約をかけて400文字にします。
そして、この400文字の要約文と2つ目の2,000文字の塊を統合して、要約をします。
これを5つ目の塊まで繰り返していきます。
Refineのメリットとしては、Map ReduceやMap Rerankに比べて、精度が高くなる傾向がある点があげられます。
一方で、デメリットとしては、「Map ReduceやMap Rerank」のように、並列処理ができないため、処理速度が遅いという点が挙げられます。
これらの3種類のアルゴリズムを実装したい場合は、LangChain Chainsを用いることをオススメします。
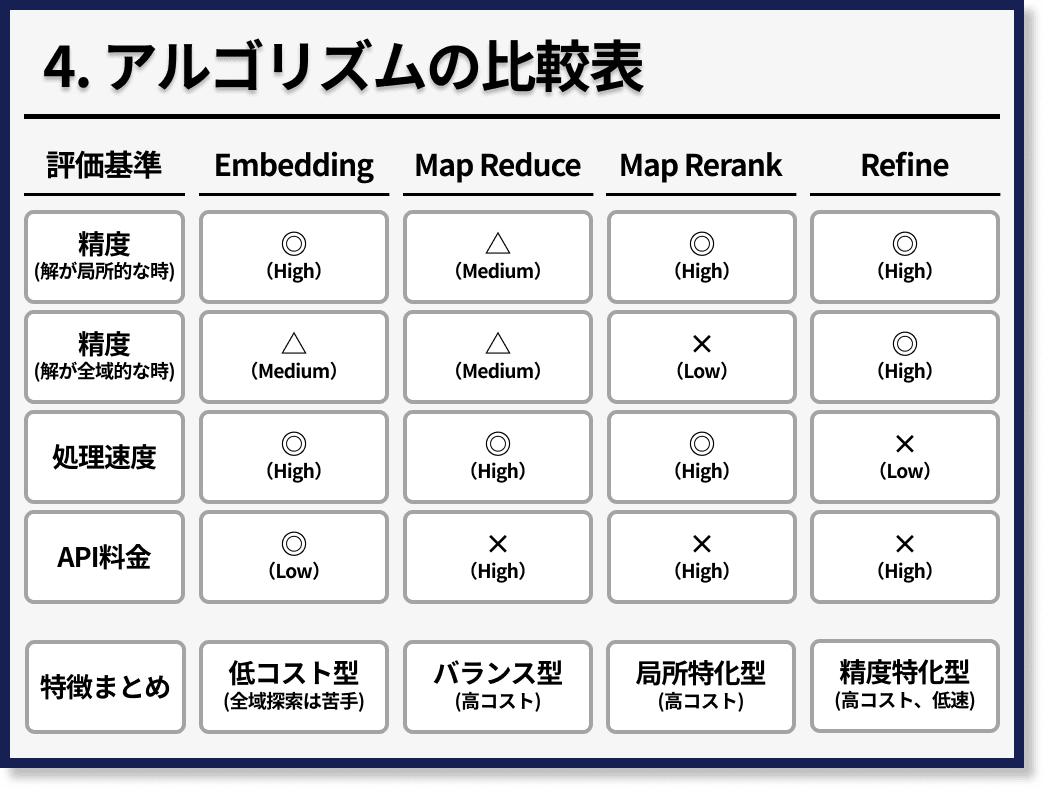
最後に、これらのアルゴリズムの特徴の比較表は、次のとおりです。
必ずしもすべての場合において、これらの特徴が適応されませんが、私の見解をまとめました。
使用データが長文のケースにおいて、もしもコストを抑えたい場合は、最初のエンべディングの方法がオススメです。
また、精度を最優先したい場合は、Refineがおすすめです。
精度を追求したいが、処理速度も優先したい場合は、Map ReduceかMap Rerankがオススメです。
さらに、欲しい情報が使用データの中で散らばっている場合はMap Reduceを、一箇所に固まっている可能性が高い場合はMap Rerankを使用することをオススメします。
LangChainによる実装方法
「LangChain」というPythonのライブラリを用いて、FAQチャットボット」と「要約チャットボット」を実装したい方は、下記をご参照ください◎
最後に
最後まで読んでくださり、ありがとうございました!
この記事を通して、少しでもあなたの学びに役立てば幸いです!
宣伝:もしもよかったらご覧ください^^
『AIとコミュニケーションする技術(インプレス出版)』という書籍を出版しました🎉
これからの未来において「変わらない知識」を見極めて、生成AIの業界において、読まれ続ける「バイブル」となる本をまとめ上げました。
かなり自信のある一冊なため、もしもよろしければ、ご一読いただけますと幸いです^^
参考文献

株式会社Galirageのテックブログです! Galirageでは、生成AIのシステム開発・コンサルティング・研修を行なっております。 ▼ 問い合わせ先 ▼ info@galirage.com
Discussion