本稿は Ubie Engineering Advent Calendar 2023 の 9 日目の記事です。
はじめに
ユビーでソフトウェアエンジニアをやっている syu_cream です。最近は社内で Enabling SRE っぽい動きやデータの信頼性に向き合っています。
さて、みなさんは Sentry やそれに類するエラートラッキングツールを使っていますか?使っている場合、「有効に」使えているでしょうか?有効に使う工夫をしない限り、エラーが山積するのが可視化されるだけの混沌とした状況になることもあるかと思います。筆者も模索中ではありますが、 Sentry と向き合った足跡を参考情報として残してみようと思います。
まず Sentry とは何でどう使うか
改めての説明はあまり要らないと思いますが、 Sentry は以下で確認できる通りエラー監視をはじめとしたシステム運用に役立つ監視ツールです。
ちなみに、現在は以下のような多数の機能があるようです。(筆者としても使ったことのない機能も多い…)
- パフォーマンスモニタリング
- セッションリプレイ
- カバレッジの可視化
- …
ここでは主たる用途であると思われるエラー監視について触れていきます。エラー監視というだけならエラーログを収集・監視するのと領域が被りそうですが、 Sentry のようなツールを使うことで以下のメリットを享受できます。
- 導入の敷居を下げられる。 SDK を入れてセットアップするだけでそこそこ得られるものがある
- エラーに至る直前の動作やスタックトレース、実行環境のコンテキストが取れる
- 柔軟な条件を指定して Slack などに連携できる
ここまでをあまり手をかけずとりあえずエラー監視を開始することが出来るのは便利だと言えるでしょう。
エラー監視のペインと対処
実運用上の課題
導入しやすい Sentry でお手軽にエラー監視を開始すると、実際の運用上いくつかの問題に遭遇すると思います。筆者の経験や世の中のいくつかの資料から、以下は典型的にあるのではないでしょうか。
- エラーに対応する人が限定的、もしくは誰も対応していない
- 大量のエラーが通知されておりどう対処したらいいか分からない
- エラーのバリエーションが多くどう対処したらいいか分からない
- サービスへの影響がわかりにくい
これらの問題を通して、エラー監視しているとは名ばかりのエラー情報を貯めるだけの箱と誰も見ていない通知が溢れる Slack チャンネルがあるだけの状態になりうると思います。
対処法
万能な対処法は存在せず、その組織やチームに合わせた地道な改善が必要かと思います。筆者も模索中ではありますが、現在は以下に取り組んでいます。
まず、エラーに対応する人が限定的、もしくは誰も対応していない状態について。様々な要因があるとは思いますが、まずは当事者意識の欠如はあるのではないかと考えます。「誰かがやってくれる」「自分が対処することでは無い」と各メンバーが思っているような状態です。エラーに敏感に気づき対処する「職人」が居る環境なら余計に当事者意識を育むのは難しいかも知れません。またエラーが対処するべきものか分からない、細かいところだと対処方法を知らないケースもあるかも知れません。これらに対しては筆者は
- エラーを深くトリアージすることなく「ヤバそう」な状態に気付けるようにする
- 人を巻き込み、当事者となり得ることを意識づける
- 当事者意識が生まれやすい組織やソフトウェアの構造にする
に取り組んでいます。
特に直近は 3 点目の要素に力を入れています。当事者意識を持ちにくい組織・ソフトウェア構造というのはあり、適切な摂理面で分割することで一定の改善が見られると考えます。これを考慮して主要な巨大モノリスとなったバックエンドサービスをモジュラーモノリスとして分割するリアーキテクチャプロジェクトが進行中です。これと合わせて、あるモジュールはあるチームの持ち主でありその人たちが Sentry のエラーの管理まで行うような整理を検討しています。
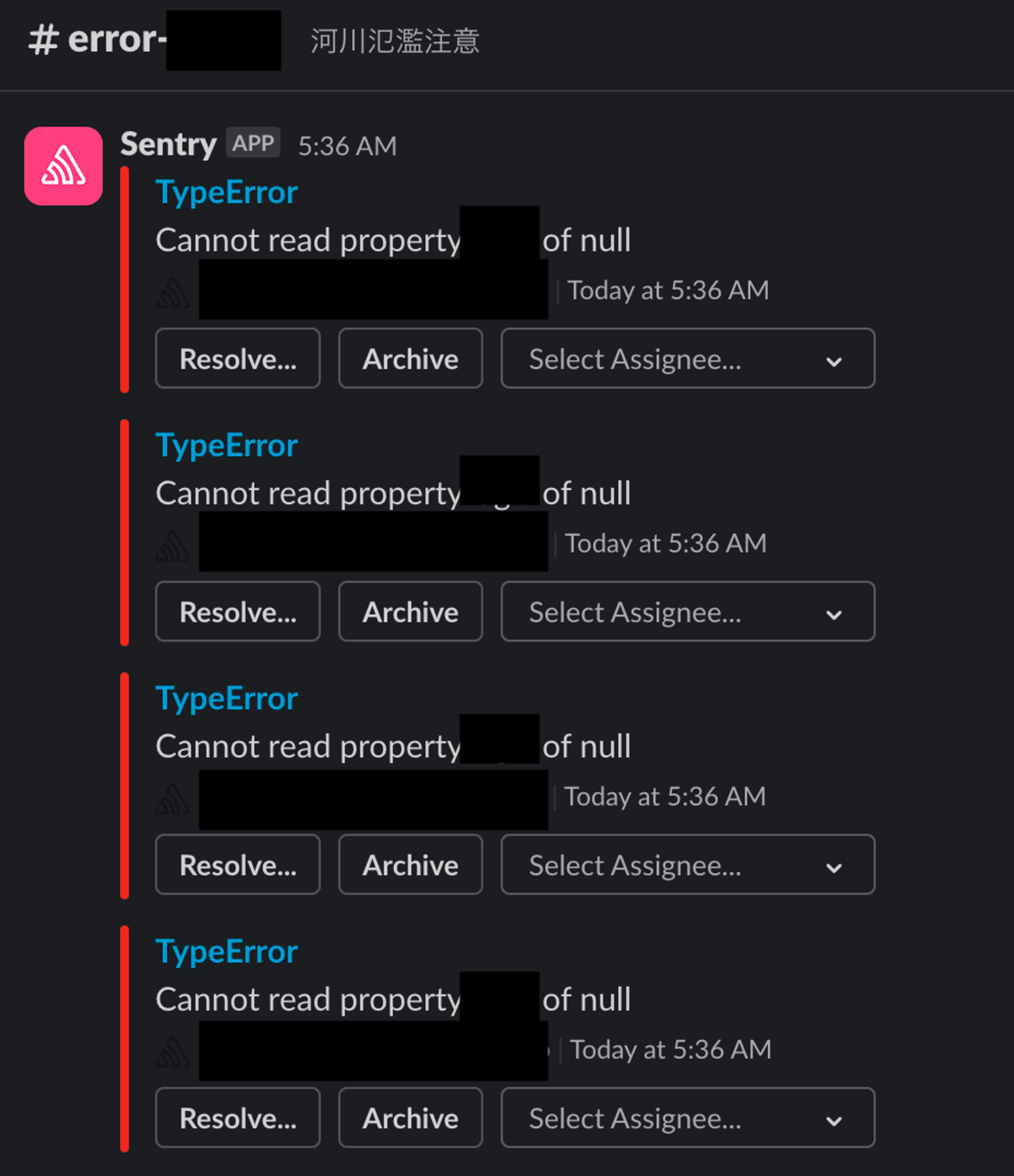
次の大量のエラーが通知されておりどう対処したらいいか分からない、はエラー監視に向き合わずなんとなくで運用し続けた期間が一定の長さあれば起こりうることでしょう。筆者の現場でも一部存在します。これは一つの例ですが、あるフロントエンドのサービスのエラー通知先は Cannot read property xxx of null みたいな初歩的そうなエラーの通知が大量に流れる Slack チャンネルが存在します。(同僚がそのさまを見てトピックに「河川氾濫注意」書き殴っています)個々のエラーに個別に対処していくのは非常に骨が折れあまり現実的ではない一方、本当に重要な異常が発生した時にここから異常を察知するのは困難です。
これには Sentry 公式ドキュメントのアラートのベストプラクティスが参考になります。この状態を愚直に活用するのは困難なので、本当にヤバい時にのみ通知が来るようにトリガーを工夫するとともにノイズを減らすような工夫をします。
筆者の場合、現在は以下を試しています。
- 新規のエラーが作成された場合に通知
- エラー数が閾値を超えた時に通知
これらは、大量のエラーが観測されるようなカオスな状況においても一定の異常状態に関する示唆が得られます。前者の場合は最近リリースされた機能が予期せぬ振る舞いをしていないかの検証、後者はより広い範囲で異常がないかを検知するのに役立ちます。またこれらを部分的に検知することで、複数のメンバーが関心を抱きやすい問題に立ち向かいこれ以上エラーのバリエーションが増えることを一定抑制する効果も生まれます。
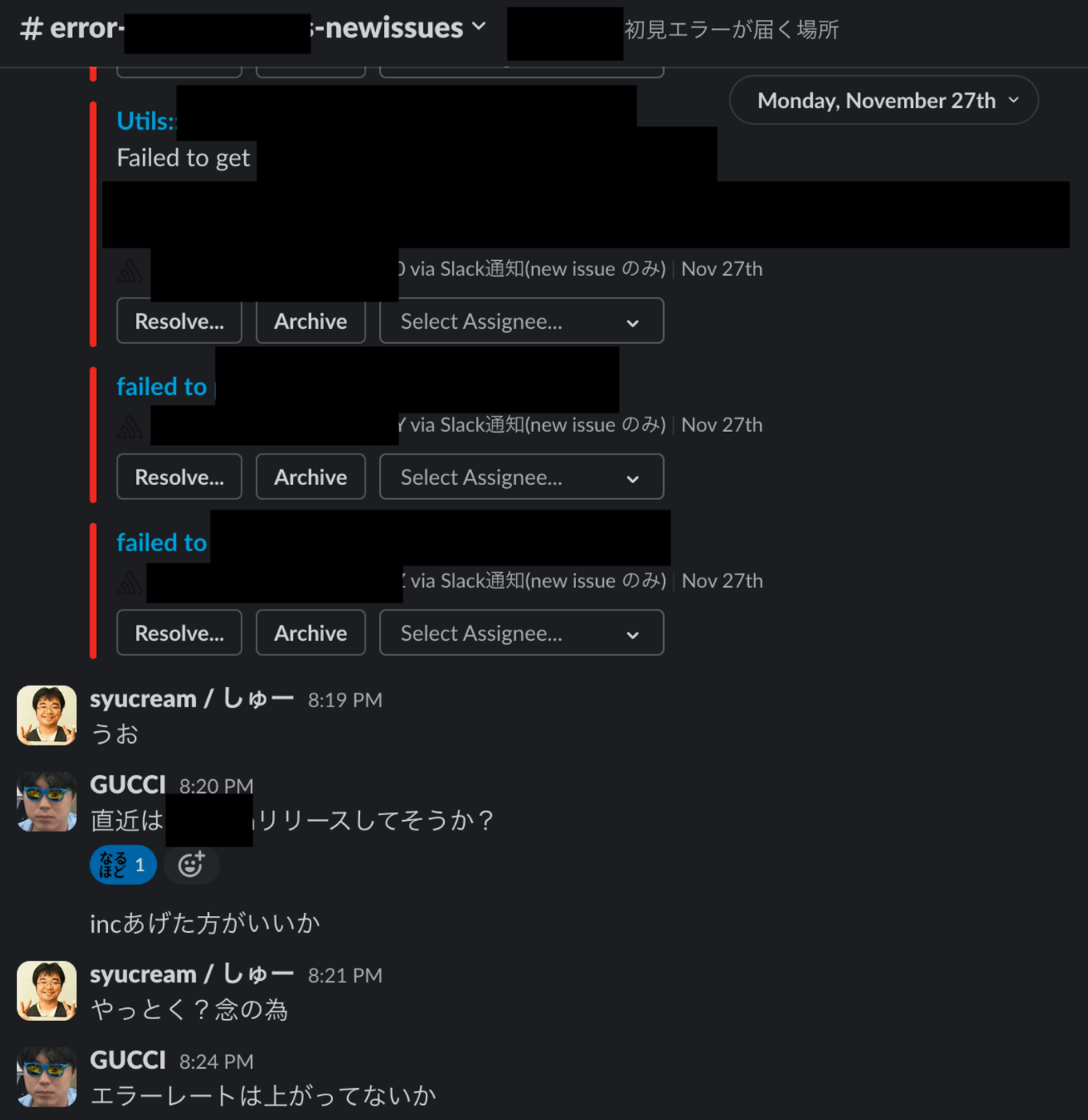
筆者は試していないですが、エラーによって影響を受けたユーザ数やリグレッションしたエラーの通知も効果があるかも知れません。
エラーのバリエーションが多くどう対処したらいいか分からない、についてはバリエーションが多い状態が正しいのであれば仕方がないでしょう。前述の通知方法の工夫をするのも良いです。一方で期待に反してバリエーションが増えているケースもあると思います。例えばフロントエンドのエラー通知です。アプリケーションコードが実行されるのがクライアントのブラウザになり、 Chrome と Safari でスタックトレースやエラー内容が異なるなどの問題が出てきます。これは前述のような新規のエラーを通知するような場合に上手く行かなくなる問題も発生させます。
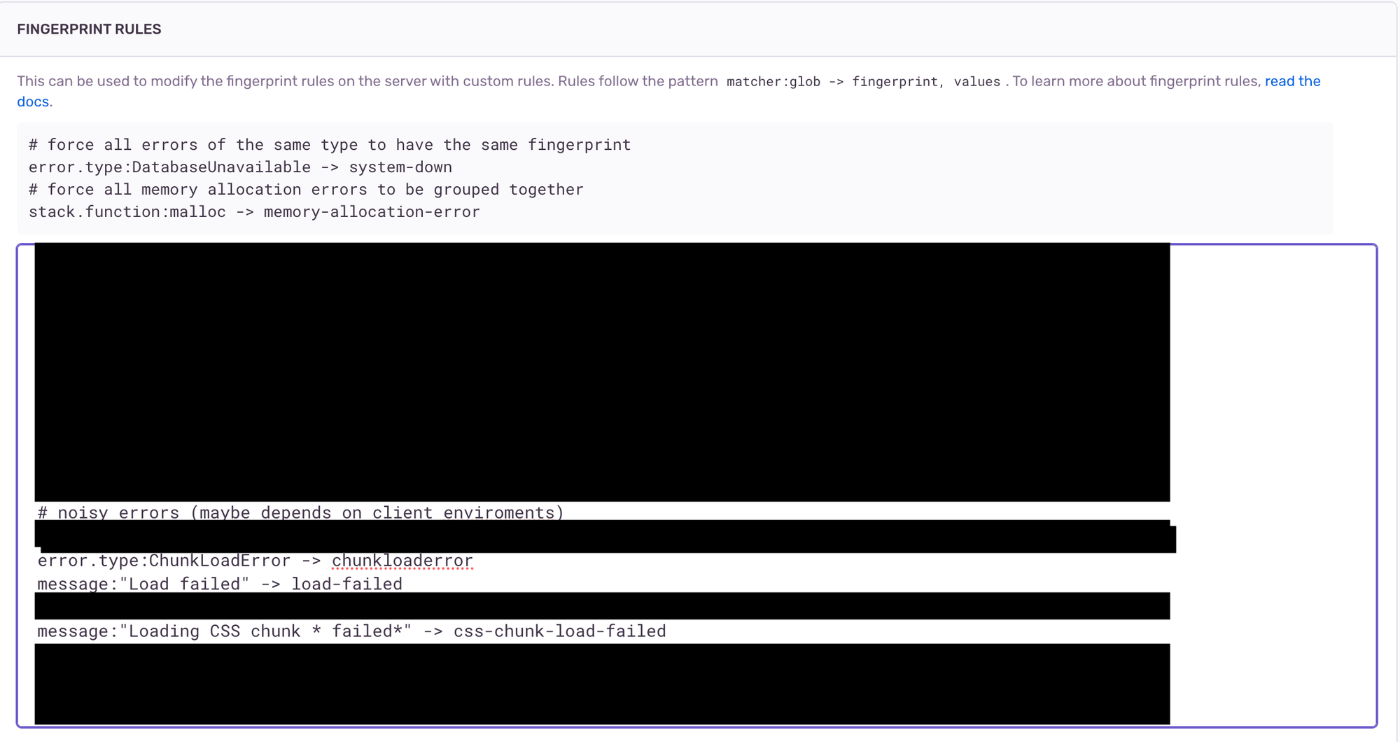
もしバリエーションがあるエラーが同一なエラーと見做せる場合はグルーピングしてしまうのも良いでしょう。 Sentry では fingerprint (スタックトレースなどエラーに関する情報をベースとした識別情報) によってエラーを区別して、同じ fingerprint を持つエラーを Issue という形でグルーピングします。
逆に fingerprint が異なると違う Issues に属することになるため、バリエーションが余計に生まれたり新規エラー通知にノイズが乗ることになりえます。これを避けるため、もし事前に fingerprint として好ましい値がわかるようなら Sentry にエラーを送る前にカスタム fingerprint を生成するようにするのも良いでしょう。またもっと手軽に、 Sentry で捕捉された後に fingerprint をカスタマイズするルールも設定できるので活用するのも良いです。例えば筆者は Next.js で動かしているフロントエンドサービスにおいてたまにありがちだがバリエーションが出てしまうエラーを集約するような fingerprint をいくつか設定しています。
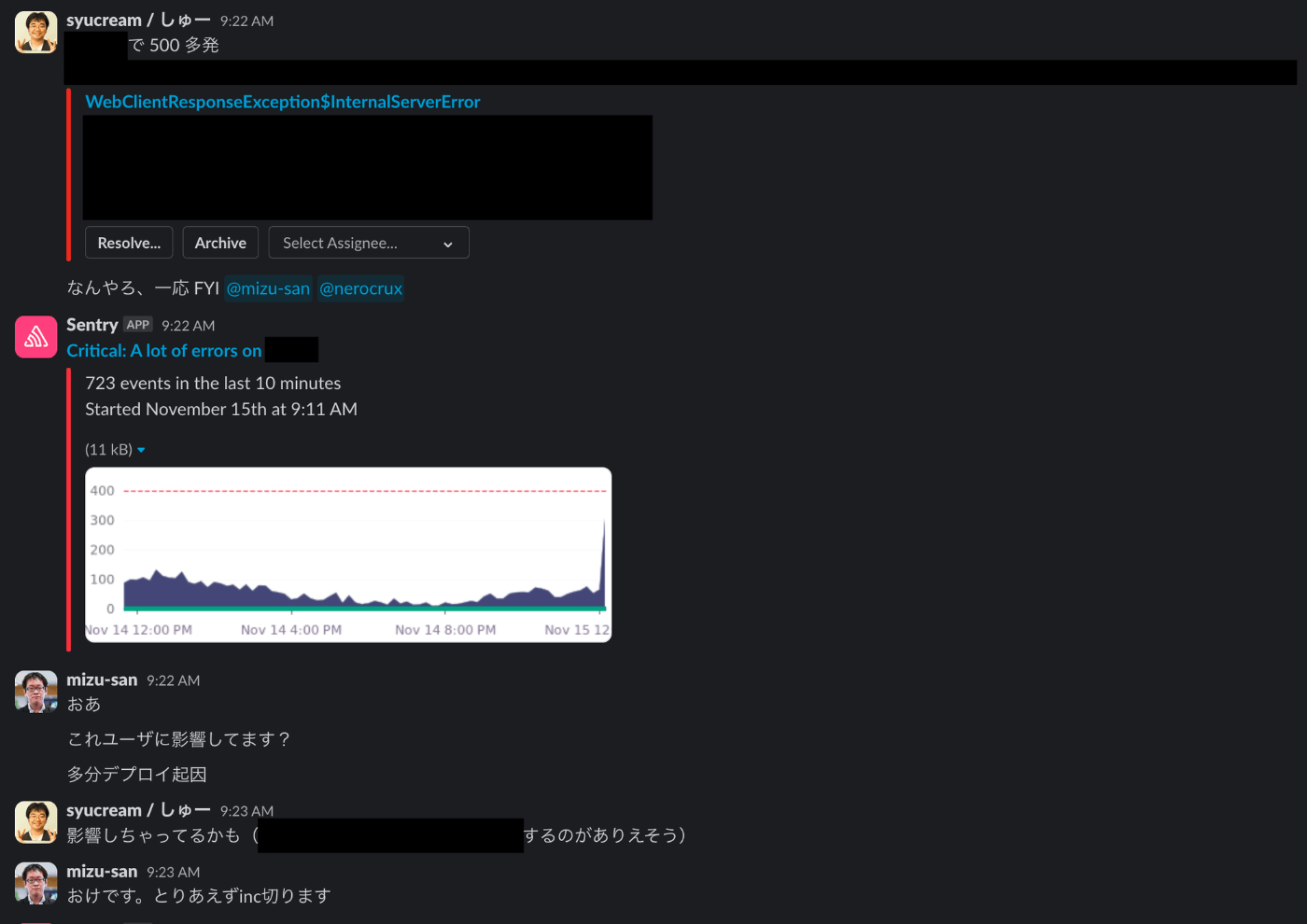
最後に、サービスへの影響がわかりにくいは既に触れた「エラー数が閾値を超えた時に通知」などの工夫でカバーできる部分があると考えます。あるいは Sentry だと影響を受けたユーザ数も通知のトリガーにできるのでそれを採用するのも良いでしょう。通常時ではあり得ないような発生エラー数を閾値において通知を行うことで、広範囲の異常を検知するとともに顧客影響の広さなど対処すべきかどうかを会話しやすくなります。
おわりに
Sentry によるエラー監視と運用上起こりやすい問題、筆者の対処法について触れてきました。これをやっていれば安心という完璧なプラクティスが無く、泥臭く運用していくしかないところが一定あると感じます。一方で Sentry はツール側 SDK 側両方で機能とオプションが数多くあり、真に適切に支えていればもっと賢く使えるのではとも考えています。とはいってもエラー監視で全てを行う必要もなく、他のツールによる適切な SLO 監視をして組み合わせて使うのもありそうですね。
また、先日の Ubie Advent Calender の記事でクオリティカルチャーに関する言及がありましたが、エラー監視のような機能のリリース後に明らかになる課題に関しても連携してやっていきたいところです。プロダクトの品質、のようなより抽象度の高い課題に対して開発・運用のプロセスのどこで何を目指すかを明瞭にすることでプロセス全体の生産性を向上することにも繋げられると思います。
さて、 Ubie Engineering Advent Calendar 2023 の 10 日目の記事は icchi による記事です。引き続きお楽しみください。

Discussion