この記事はUbie Engineering Advent Calendar 2023の一日目です。よろしくお願いします。
背景
ユビーのシステムは言語が多様化してきたことにより、認知負荷の増加や運用負荷の増加、開発支援に仕組みづくりかけるコストの増加などの問題が発生していました。この課題を解決するためにNode.jsとGoに言語を絞っていくという意思決定をしたのが昨年です。これについては以下の記事で詳しく解説しています。
ちょうど去年のアドベントカレンダーの記事なのでこれから一年経ちました。ここでは以下のように述べられています。
Server-Side Kotlin などで書かれている既存サービスを、この技術選定の文脈でリプレイスすることは今のところ考えていません。
ただし、多くの既存サービスはドメインたくさん抱えすぎ問題があったり、色々とレガシーだったりして、徐々に別サービスに切り出していこうと考えています。それに合わせて、新たな技術スタックへ移行する予定です。
ここから一年経過して、まさに既存のサービスを新たな技術スタックへ移行するときがきたのが今です。メインのバックエンドシステムは多くのドメインを抱えており、今後も機能が増えていくことが予想され、このままモノリスとして肥大していくと将来大きな技術負債となり得ます。
システムが肥大していくことによる問題は色々ありますが、オーナーシップの問題が一番大きいと思っています。複雑に機能の入り組んだモノリスだと、複数のドメインが混ざっている機能をどこのチームがオーナーシップを持つのかが不明瞭になるという問題があります。
こうなるとインシデントが発生した場合にどこのチームが対応するのかがわからず、ほとんどのインシデントをプラットフォームチームが見ることになったり、特定の機能を使いたい、インタフェースを変更したいといった場合にどのチームが意思決定できるのかがわからずにコミュニケーションコストが増加するなどの問題が発生します。
そこでドメインごとにオーナーシップを持てるように機能を分割するための手法としてモジュラモノリスを採用することにしました。

機能を分割するための手法としてマイクロサービスも検討しましたが、システムの複雑度の増加や設計難易度の増加、データ一貫性維持の難しさなどを考慮し、まずはモジュラモノリスとして設計した上で必要に応じて段階的にマイクロサービスに移行するのがよいという判断をしました。
こういった経緯からNode.jsでモジュラモノリスのシステムを作ることになったため、今回の記事では設計や技術選定の過程について紹介できればと思います。
設計と技術選定
まず以下のような前提条件があります。
- 実装するサービスは自身でDBを持つモノリスではある
- いわゆるGateway的なBFFではない
- 既存の機能やAPIのインターフェースは変更せずに移行する
- 既存のAPIがGraphQLなのでGraphQLサーバーとして実装する
- 後ろにマイクロサービスサービスがいくつかある
- 複数プロダクトで使う認証基盤など基盤系サービス
- GraphQLだったりRESTだったりする

フレームワーク
まず、フレームワークにはNestJSを採用しました。ユビーでNode.jsのバックエンドシステムを作るときに標準的に利用されているフレームワークなのと、NestJSのモジュールシステムがモジュラモノリスと相性が良いというのが理由です。
NestJSを利用せずApollo ServerやGraphQL Yogaをそのまま利用するという方法も検討しました。NestJSはApollo ServerやGraphQL YogaなどをDriverとして指定し、モジュールやDIなどの機能を提供する、レイヤーとしてはこれらのライブラリの一つ上位のフレームワークです。
NestJSを使うメリットとしてはモジュールシステムによる依存の管理やDIによるテスト容易性などがあげられます。デメリットとしては一つレイヤーが増えることによる複雑性の増加、学習コストの増加などがあります。
これらのメリット・デメリットを比較した結果NestJSを採用しましたが、メリットのほうが圧倒的に大きいというわけではなく、状況によってどちらを選択するケースもあると思いました。
パッケージ管理
パッケージ管理はまず最初にnpm workspacesとturborepoを利用したmulti packagesなモノレポ構成を検討しました。
これによるメリットはいくつかあります
- 依存ライブラリをモジュールごとに管理できる(npm workspacesの機能)
- モジュール間の依存をpackage.jsonで管理できる(npm workspacesの機能)
- タスクをモジュールごとに定義でき、タスクの依存を考慮したキャッシュが可能(turborepoの機能)
このようなメリットを求めてmulti packages構成にしようとしたのですが、結果としてはmulti packages構成はやめて、package.jsonがルートにあるだけの普通のNode.jsのプロジェクト構成を採用しました。理由としては上記のようなメリットの恩恵を思ったよりも受けられそうにないこと、複雑性が増すことによる管理コストの増加です。例えばわかりやすい例で言えばworkspaces起因でライブラリの依存の状態がおかしくなってnode_modulesを一度飛ばしてインストールし直すというのことを何回か経験しました[1]。
また、上記メリットの恩恵が少なそうだったという話についても説明します、まずは依存ライブラリの管理です。npm workspacesを使うとpackageごとに利用するライブラリをpackage.jsonのdependenciesで管理できます。これは利用するライブラリがpackageごとに大きく異なるような構成であればメリットが大きいと思うのですが、今回のようなモジュラモノリスの場合は多くのライブラリが共通になり、バージョンも揃える必要があります。バージョンをpackage間で揃えるためのプラクティスも存在していますが、そういった仕組みを導入・管理するコストと比べてメリットが小さいと判断しました。これについては正直どちらがいいかは微妙なところで、しばらく運用してみてやはりpackageごとにライブラリを管理したほうがメリットが大きそうという判断でworkspacesを利用する可能性はあります。
次にモジュール間の依存の管理です。npm workspacesでは特定のモジュールがどのモジュールに依存しているかをpackage.jsonで管理できます。
// module-c/package.json
"dependencies": {
"@modules/module-a": "*",
"@modules/module-b": "*"
}
モジュラモノリスにおいてモジュール間の依存をわかりやすく可視化するのは重要なので、これは便利ではあるのですが、NestJSのモジュールシステムを使うことにより代替可能です。
@Module({
imports: [ModuleA, ModuleB]
})
export class ModuleC {}
最後にタスクの管理とキャッシュです。turborepoを使うとnpm scriptsのタスクの依存関係を考慮して実行してくれたり、適切にキャッシュしてくれます。この機能は便利なのでnpm workspaceを利用せずにturborepoだけ利用できるのであればそうしたいところですが、workspaceを使う前提の設計なのでそれは難しそうでした。
キャッシュの機能については、ローカルではモジュールごとにテストやlintは実行すればいいし、CIではキャッシュの設定ミスで本来落ちるべきCIが通ることがあると怖いので可能な限りキャッシュしたくないので、まあ実はそんなにメリットはないのかもしれないと思っていて、タスクの実行速度が開発のボトルネックになってきたときに再考しようと思います。
データベース
ORMについてPrismaを採用しました。
これについては社内でも標準的に利用されておりあまり議論の余地はありませんでした。Prismaのスキーマやクライアントをどのように扱うかですが、これはモジュラモノリスならではの設計になっています。
Prismaのスキーマもモジュールごとに管理したいので、モジュールごとのディレクトリの下にそれぞれが管理するスキーマファイル作成しますが、Prismaの複数のスキーマファイルに対応していないので、これをprisma-importというツールを使って結合します。
./src
├── libs
│ └── medico-db
│ ├── index.ts // schema.prismaを読み込んだPrisma Clientをexportする
│ ├── schema.prisma // prisma-importで結合されたスキーマ
│ └── base.prisma
└── modules
├── user
│ └── user.prisma
└── post
└── post.prisma
// libs/db-client/base.prisma
generator client {
provider = "prisma-client-js"
}
datasource db {
provider = "postgresql"
url = env("DATABASE_URL")
}
// modules/user/user.prisma
import { Post } from "../blog/post"
model User {
id Int @id @default(autoincrement())
name String
posts Post[]
}
// modules/blog/post/post.prisma
import { User } from "../user/user"
model Post {
id Int @id @default(autoincrement())
title String
description String
user User
}
これを以下のコマンドで結合して schema.prisma を出力します。
$ prisma-import --schemas './src/{modules,libs}/*/db/*.prisma' --output schema.prisma
結合したスキーマを読み込んだPrisma Clientを全てのモジュールで利用します。モジュールごとにクライアントを作成するとコネクションがモジュール増加に伴って増えてしまうので、クライアントを単一にすることでコネクションも使い回すことができます。トレードオフとして自分が管理しているテーブル以外にも簡単にアクセスしてしまうという問題があります。今のところレビューなどで担保する方針ですが、lintなどの仕組みを用意する可能性もありそうです。
モジュールごとにPostgreSQLのスキーマを分けるという方針も検討しています。現状のテーブルは全てpublicスキーマにあるため、徐々に移行していくことになりますが、新規で作る機能はスキーマをわけていくかもしれません。ただ、Prismaのmutli schemaの機能がpreview featureの状態で安定していなさそうなのと、この仕組みだとスキーマごとにクライアントを作るようなので、コネクションが増える問題がありそうで、そのまま採用するかは微妙なところです。
また、モジュール間のjoinやtransactionについてはモジュールの独立性を高めるために、基本的にjoinは禁止、transactionはデータの整合性を保つメリットのほうが大きければ状況に応じて許可、が妥当なラインかと考えています。
Migration
DBのマイグレーションはPrismaのmigrationを利用するのが妥当ではありますが、今回はsqldefを利用することにしました。これは以下のような理由です。
- 積み上げ型のmigrationは現状の状態を別途データとして持たないといけないので仕組みやプロセスが複雑になる
- Prismaのスキーマはcheck制約やコメントなどの一部のテーブル定義を表現できない
- Prisma migrationでalter文を書けばこれらの機能を利用することは可能だが、スキーマを見ただけで完全なテーブル定義がわからないというのがデメリット
- 手元で開発するときにスキーマを色々試しながら開発するのがややめんどう
- 開発中はスキーマを手で変更しつつ、変更が確定したら
prisma db pushとprisma migrate devを使って変更したぶんの migration を出力することが可能だが、DBのReset が必要になるケースが多い - 規模の大きいサービスだとseedのデータもでかくなるのでなるべくResetしたくない
- 開発中はスキーマを手で変更しつつ、変更が確定したら
こういった問題をsqldefを使うと解決できるため、今回はsqldefを採用しました。なお、私がsqldefのメンテナのため何か問題があった場合にすぐに対応できるというのも採用に至った理由の一つです。
テーブル定義を変更するときにPrismaとSQLを二重で変更する必要がでてきますが、これはトレードオフとして受け入れます。管理するのをSQLだけにして prisma db pull でPrismaのスキーマを自動生成するという方法も検討しましたが、@map などのアノテーションが利用できなくなるという理由で不採用となりました。
GraphQL
GraphQLのスキーマもモジュールごとに管理します。
./src
└── modules
├── module-a
│ └── graphql
│ └── module-a.graphqls
├── module-b
│ └── graphql
│ └── module-b.graphqls
└── module-c
└── graphql
└── module-c.graphqls
これを結合するのはprisma-importのようなツールは不要で、NestJSのResolverモジュールでglobで指定するだけです。
GraphQLModule.forRoot<YogaDriverConfig>({
driver: YogaDriver,
typePaths: ['../modules/**/*.graphqls'],
})
モジュールごとにスキーマを管理することによって、スキーマがバラけて一覧性が欠けるという問題や、GraphQLのスキーマは import のような依存解決の仕組みをもっておらず、全てがグローバルな型となるので、スキーマの依存関係がわかりづらいという問題があります。これらの問題はspectaqlやgraphql-voyagerといったスキーマのドキュメンテーションツールを使うことで解決します。
また、NestJSなのでコードファーストという手法もあります。コードファーストにすることで ESM の import を使って依存がわかりやすくなる、一枚のスキーマに出力できるので一覧性がよくなるなど、いくつか利点はあります。しかし、ユビーはほとんどのGraphQLサービスがスキーマファースになっており、NestJSのコードでスキーマを書くよりもGraphQLのスキーマ言語を書くほうが慣れているので、慣れているシンタックスで記述できるというメリットのほうを取り、スキーマファーストを採用しました。
Schema Stitching
多くのモジュールのデータソースはDBですが、マイクロサービスにリクエストするモジュールもいくつかあります。このとき、GraphQLのマイクロサービスに接続する場合はSchema Stitchingを利用します。
Schema Stitchingを使うと、マイクロサービスのスキーマをマージし、フィールドの解決も設定を書くだけで自動でマイクロサービスにリクエストして解決してくれ、マイクロサービスへのリクエスト処理の記述を大幅に減らすことができます。
例えば、スキーマのマージは以下のようなイメージです。 Post はモジュラモノリスがDBをデータソースとして持つモジュール、 User は User Service というマイクロサービスが持つモジュールとします。このとき、モジュラモノリス側で User の型は ID を持つだけですが、Schema Stitching でマージすることで User 型がマージされたスキーマとして提供されます。
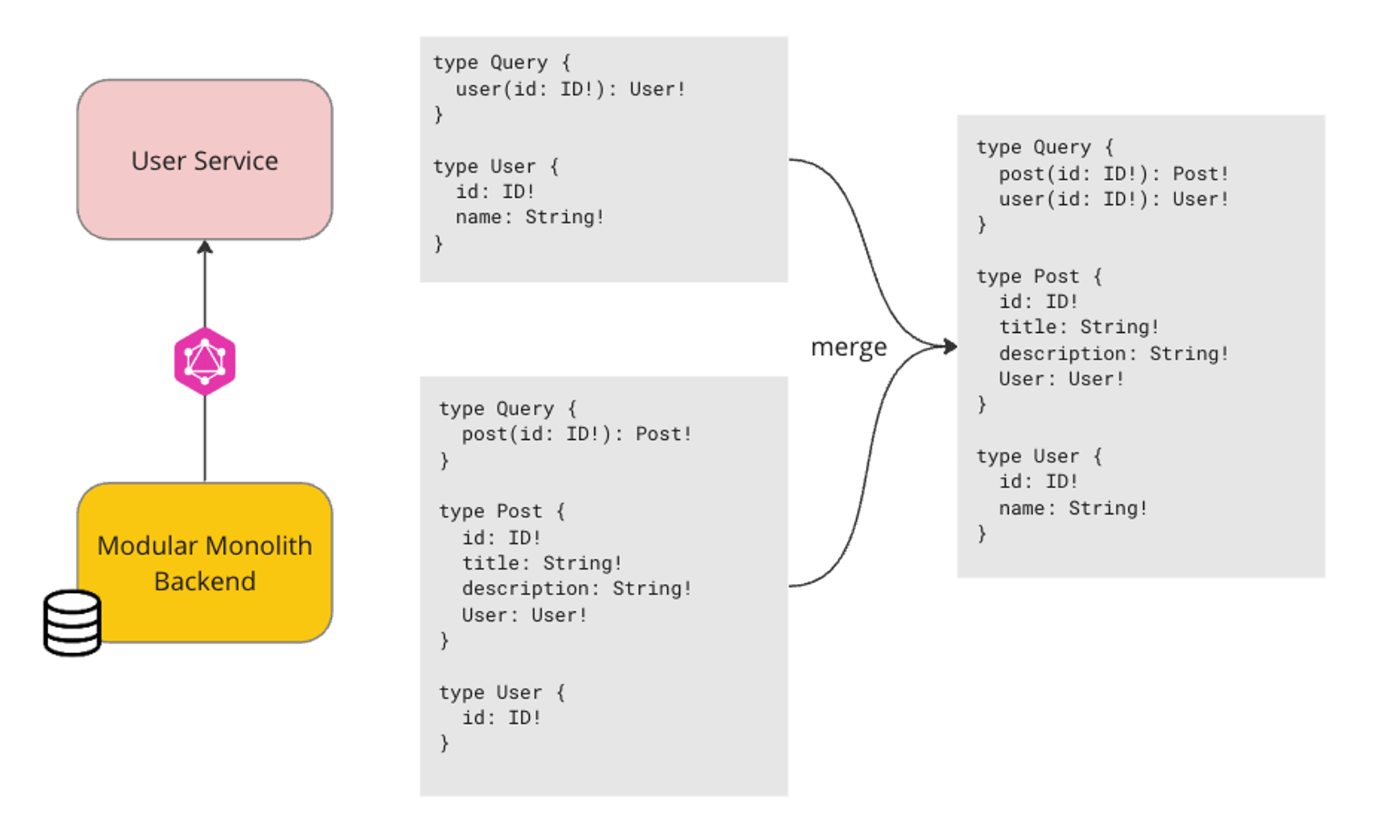
Resolverに関しても、以下のような設定を書くだけで自動で user(id: ID!) のクエリを呼び出して解決してくれます。
const executor = buildHTTPExecutor({ endpoint });
const schema = await schemaFromExecutor(executor);
const subschema = {
schema,
executor,
merge: {
User: {
selectionSet: "{ id }",
fieldName: "user",
args: ({ userId }) => ({ id: userId }),
},
},
};
@Resolver("Post")
export class PostResolver {
@Query()
async post(_, args) {
const post = await getPost(id: args.id);
return {
id: post.id,
userId: post.userId, // このuserIdを見てUser Serviceに自動でリクエストしてUser typeをresolveしてくれる
}
}
}
技術選定における対抗としてはGraphQL MeshやApollo Federationなどです。薄いBFFのようなGatewayを実装する場合はこういったツールのほうが向いていそうですが、今回のような一部のモジュールだけでGraphQLのスキーママージを入れる場合はSchema Stitchingが必要十分であると判断しました。
モジュール間通信
モジュール間で機能を呼び出す場合は、単なる関数呼び出しにします。NestJSなのでProviderとして定義して利用することになります。例えばPost ModuleとUser Moduleがあるとして、User ModuleがUserに紐づくPostのデータを取得したいとすると、User ModuleはPost ModuleのServiceの関数を呼び出すだけです。(一旦Schema Stitchingの話しは忘れてください)

@Injectable()
export class PostService {
async getPostsByUserId(id: number): Promise<Post[]> {
// fetch posts
}
}
@Injectable()
class UserService {
constructor(private postService: PostService) {}
doSomething() {
const posts = await this.postService.getPostsByUserId(id);
// do something
}
}
このとき、それぞれのモジュールは NestJS の規約で imports/exports を明示する必要があります。
@Module({
exports: [PostService],
providers: [PostService],
})
export class PostModule {}
@Module({
imports: [PostModule],
providers: [UserService],
})
export class UserModule {}
これによってモジュール間の依存関係の管理を明示的に行うことが可能になります。代替案としてはRPCのような仕組みを用意したり、モジュール間もGraphQLで会話するなどの方法などですが、TypeScriptの型でインターフェースは担保されており、依存関係の明示もNestJSの機能で賄えるため必要十分であると考えています。
テスト
テストについては、モジュラモノリスであることとNestJSであることを活かして、他のモジュールをmockできるところに利点であると思っています。これによって、自分たちが管理しているテストが他のモジュールの変更によって壊れることが減ります。
コードの雰囲気はこんな感じです。
describe("User", () => {
let app: INestApplication;
beforeAll(async () => {
const module = await Test.createTestingModule({ imports: [AppModule] })
// Userモジュールのテストなので依存している他のモジュールの機能はmockする
.overrideProvider(PostService)
.useValue({
getPostsByUserId: (id: number) => {
// return mock response
}
})
.compile();
app = module.createNestApplication();
app.init();
});
afterAll(async () => {
await app.close();
});
it("query user", async () => {
const { data } = await request(app.getHttpServer())
.query(gql`
query user {
user(id: 1) {
id
post {
id
title
}
}
}
`)
.expectNoErrors();
});
});
別途モジュールを結合したインテグレーションテストも必要にはなってきますが、モジュールに閉じたテストを書けることでモジュールの独立性が高くなることを期待しています。
まとめ
Node.jsでのモジュラモノリスの設計方針や技術選定について紹介しました。今回紹介したのはまだ設計段階なので、実装や運用をする中で方針が変わることや別の観点が見えてくることもあるとは思いますが、現時点での方針が何かしらの参考になればと思います。また、この設計を実装するにあたってスポットでお手伝いしていただける方を募集していますので、もし興味がある方はぜひお願いします。
また、スポット以外でも絶賛採用強化中ですので、このようなシステムの設計から関わりたいという方やユビーに興味があって話を聞いてみたい方がいましたら、まずはカジュアルにお話しましょう!
明日は@m_mizutaniさんがセキュリティの面白い話しを書いてくれると思いますのでご期待ください!
-
pnpmにすればマシになるという話しはありそう ↩︎

Discussion