Ubieのモバイルアプリ(iOS/Android)では、身体の悩みを相談できる医療AIエージェントを提供しています。toCでLLMプロダクトを提供する上では、コスト最適化が重要な課題となります。
この記事では、その中核となる技術のひとつであるPrompt Cachingのプラクティスを紹介します。まだPrompt Cachingを試されていない方は、もしかすると50%~規模のコスト削減余地が眠っているかもしれません。
Prompt Cachingとは
Prompt Caching(Context Caching)は、同一の入力プロンプトを繰り返す際に、その部分をキャッシュして再利用することで、コストやレイテンシを抑えられる仕組みです。
多くのLLMプロバイダがこの機能を提供しており、キャッシュヒットした場合は入力トークンコストを90%ほど抑えることができます。
ここで勘違いしやすいのは、Prompt Cachingはあくまで入力トークンをキャッシュするだけで、出力には無関係であるということです。つまり、「Aというプロンプトを入力したら毎回Bが出力される」といった挙動にはなりません。あくまで、「Aというプロンプトを再利用すると安く速くなる」だけです。これは一般的なアプリケーションにおけるキャッシュとメンタルモデルが異なるため注意してください。
Prompt Cachingを効かせるコンテキスト設計
Prompt Cachingは、入力の先頭一致でキャッシュヒットします。具体的に、良い例と悪い例を見てみましょう。
良い例:固定システムプロンプト
まずはシンプルに、固定システムプロンプト + 毎回変わるユーザープロンプトというケースです。最初のリクエストではキャッシュは効きません。
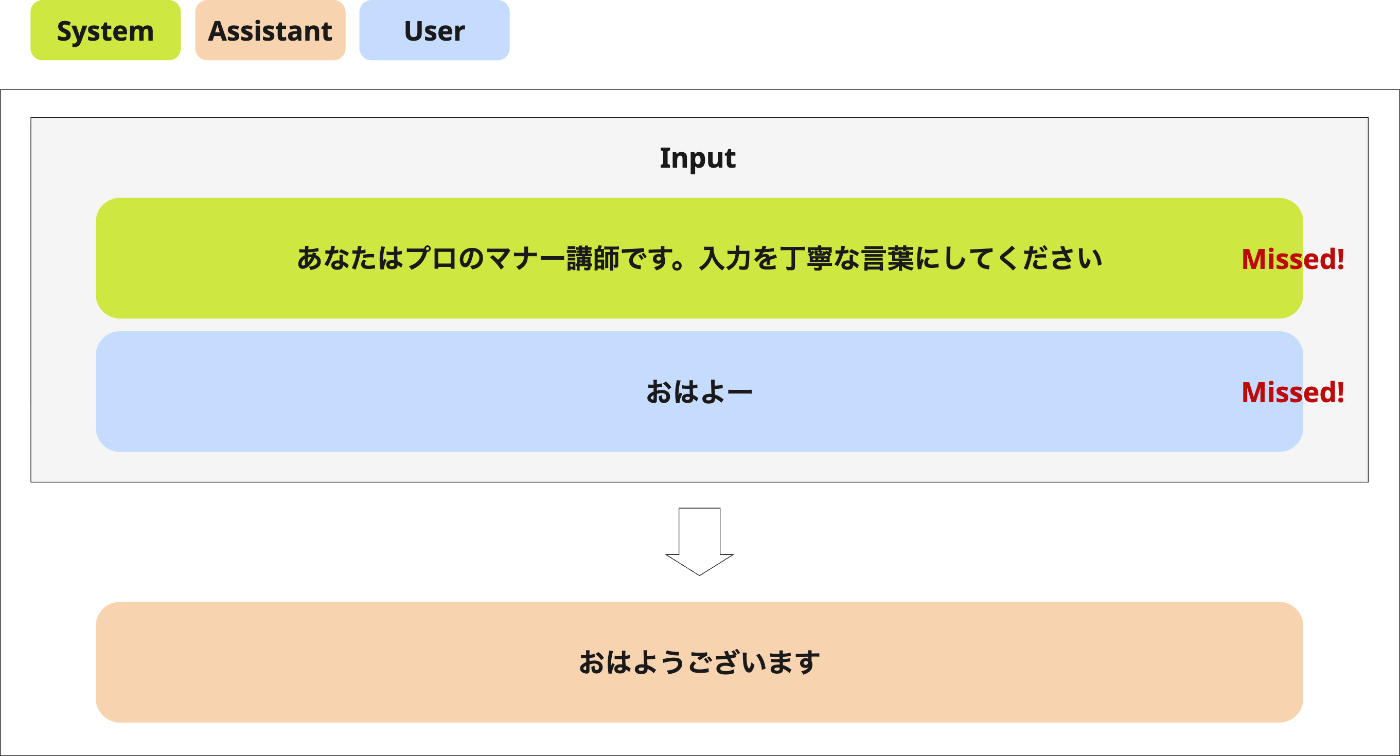
次のリクエストではユーザープロンプトだけが変わります。ここで、先頭のシステムプロンプトは前回と一致しているため、キャッシュが効きます。

このように、変化しにくいプロンプトを先頭に配置することが原則となります。
良い例:マルチターン会話
次に、会話履歴を保持するマルチターン会話のケースを見てみます。初回リクエストではキャッシュは効きません。

2回目以降は、前回までの入力部分(=会話履歴)が先頭一致するためキャッシュが効きます。

さらにその次のターンでも同様に、前回までの履歴に対してキャッシュがヒットします。

マルチターン会話においては、ターンごとに履歴の分だけ入力が増えて、非線形にコストが増加します。このようにキャッシュを利用することで、それを大幅に圧縮できます。
これはマルチターン会話以外にも、LLMの入出力を再帰的に入力しなおすシナリオ全般に有効です。例えば、LLMの出力に対してLLM-as-a-Judgeした結果をフィードバックしてリトライするような場合が考えられるでしょう。
悪い例:動的なシステムプロンプト
マルチターン会話を発展させて、システムプロンプトに現在時刻を埋め込んでみます。

続けて、次のユーザープロンプトを入力します。ここでシステムプロンプトの現在時刻も更新します。すると、システムプロンプトの先頭一致が崩れるため、その後の会話履歴部分にキャッシュが効かなくなってしまいます。

このように、マルチターン会話においては、システムプロンプトをセッション中に変更しないことが重要です。
良い例: 動的な入力はTool Use
動的な値を埋め込みたい場合は、システムプロンプトに入れるのではなく、ツールを使って動的な情報を取得させるのが適切です。
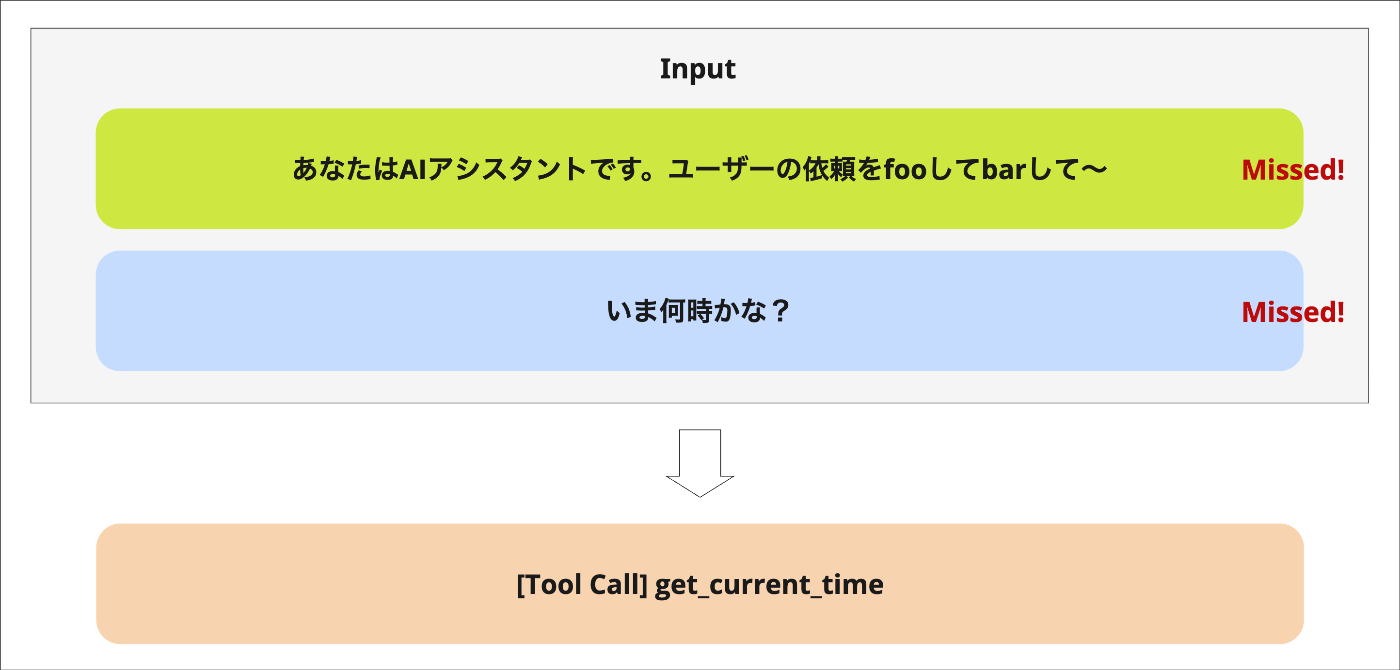
ツール実行結果を渡すことで、LLMは必要な動的値(リアルタイム時刻など)を取得できます。

再度時間を質問しても、同じようにツール呼び出しが行われて最新の時刻を回答します。ここで、プロンプトはあくまでそのまま積み上がっているため、会話履歴にキャッシュを効かせたまま動的な入力を行うことができています。

このように、「いかに過去の履歴を破壊しないか」という視点で積み上げるとキャッシュが効きやすいです。
実装例とコスト
次に、OpenAI, Gemini, Claude の各モデルそれぞれでのキャッシュ利用方法とコストへの影響を紹介します。
OpenAI
OpenAIモデルではデフォルトで、先頭が一致する入力を自動抽出してキャッシュしてくれます。
つまり、次のようにただプロンプトを送るだけで、先頭の固定部分であるシステムプロンプトにはキャッシュが効くようになります。
import { ChatOpenAI } from "@langchain/openai";
const model = new ChatOpenAI({
model: "gpt-5-mini",
});
const response = await model.invoke([
new SystemMessage({
content: [
{
type: "text",
text: "あなたはプロのマナー講師です",
},
{
type: "text",
text: "与えられたメッセージを丁寧語にしてください",
},
],
}),
new HumanMessage(RANDOM_MESSAGE_FROM_USER),
]);
ただし、キャッシュ対象のプロンプトが1024トークン以下だとキャッシュできません(つまり上記のサンプルコードはキャッシュできません)。
キャッシュ書き込みには、標準の入力トークンコスト以外に追加のコストはありません。そしてキャッシュヒットした場合は、入力トークンコストが90%安くなります[1]。つまり、先述のコンテキスト設計さえちゃんとしておけば自動的に安くなるともいえるでしょう。
Gemini
Geminiも同様に、自動でキャッシュしてくれる暗黙的キャッシュが有効になっています。
ただし、マルチリージョンによるものなのか、何度かリクエストを送らないとキャッシュしてくれないことがあります。キャッシュ戦略はGoogle内のブラックボックスであり、手を入れることはできません。
とはいっても多くの方にとっては暗黙的キャッシュで十分かと思いますが、カリカリにチューニングしたい場合は、明示的キャッシュを使って先にキャッシュを作っておき、それを明示的に利用してリクエストすることができます。
暗黙的キャッシュの場合は、OpenAIと同様に書き込みの追加コストはなく、キャッシュヒット時には入力トークンコストが90%安くなります[2]。一方で、明示的キャッシュには、キャッシュ保持期間に応じたストレージコストがかかります。
詳細はドキュメントを参照してください。
Claude
Claude では、OpenAIやGeminiのような自動キャッシュ機能はありません。代わりに、cache_control オプションを用いて明示的にキャッシュを有効化できます。
import { ChatAnthropic } from "@langchain/anthropic";
const model = new ChatAnthropic({
model: "claude-sonnet-4-5@20250929",
});
const response = await model.invoke([
new SystemMessage({
content: [
{
type: "text",
text: "あなたはプロのマナー講師です",
},
{
type: "text",
text: "与えられたメッセージを丁寧語にしてください",
cache_control: { type: "ephemeral" }, // ここを追加
},
],
}),
new HumanMessage(RANDOM_MESSAGE_FROM_USER),
]);
cache_control を設定したブロックより前に位置するプロンプトがキャッシュの前方一致の対象となります。つまり上の例の場合では、システムプロンプト全体がキャッシュ対象となり、デフォルトで5分間(設定すると1時間)キャッシュされます。
Claudeでは、キャッシュに書き込む際は通常の1.25倍、読み込む際は0.1倍のコストがかかります。つまりなんでもキャッシュするとコストが高くなる可能性があります。
詳細はドキュメントを参照してください。
なお、マルチターン会話においてPrompt Cachingを導入することによるコストの変化は、TTLなどを考慮しつつ次のようにシミュレーションすることができます。
実際の会話ログが溜まっているテーブル:
CREATE TABLE messages (
session_id UUID NOT NULL, -- マルチターン会話セッションのID
input_token_size INTEGER, -- LLMに入力したトークン長
output_token_size INTEGER, -- LLMが出力したトークン長
created_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP -- LLM実行日時
)
分析クエリ:
分析クエリ
WITH -- =========================
-- Import CTE
-- =========================
import_messages AS (
SELECT
id,
session_id,
input_token_size,
output_token_size,
created_at,
ROW_NUMBER() OVER (
PARTITION BY session_id
ORDER BY
created_at
) AS call_seq_in_session
FROM
messages
),
-- =========================
-- Logical CTE
-- =========================
-- 前のメッセージとの入出力トークンサイズ、日時差分を取得
logic_with_prev AS (
SELECT
m.*,
LAG(m.input_token_size) OVER (
PARTITION BY m.session_id
ORDER BY
m.call_seq_in_session
) AS prev_input_token_size,
LAG(m.created_at) OVER (
PARTITION BY m.session_id
ORDER BY
m.call_seq_in_session
) AS prev_created_at
FROM
import_messages AS m
),
--- 前のメッセージとの日時差分からキャッシュのTTL(5分)以内か判定
logic_tokens_with_ttl AS (
SELECT
*,
CASE
WHEN prev_created_at IS NULL THEN FALSE
WHEN TIMESTAMP_DIFF(created_at, prev_created_at, MINUTE) <= 5 THEN TRUE
ELSE FALSE
END AS cache_valid
FROM
logic_with_prev
),
logic_token_breakdown AS (
SELECT
session_id,
call_seq_in_session,
input_token_size,
output_token_size,
cache_valid,
prev_input_token_size,
CASE
WHEN call_seq_in_session = 1 THEN 0 -- 初回はcache readなし
WHEN NOT cache_valid THEN 0 -- TTL切れ時もcache readなし
ELSE prev_input_token_size -- TTL内のみ前回までをcache read
END AS cached_tokens_read,
CASE
WHEN call_seq_in_session = 1 THEN input_token_size -- 初回は全てcache write
WHEN NOT cache_valid THEN input_token_size -- TTL切れ時も全て再cache write
ELSE GREATEST(input_token_size - prev_input_token_size, 0) -- TTL内は差分のみcache write
END AS cached_tokens_written
FROM
logic_tokens_with_ttl
),
logic_token_original_cost AS (
SELECT
*,
(1.0 / 1000000) AS input_token_cost_per_token, -- Claude Haiku 4.5: Price (/1M tokens): Input: $1.00
(5.0 / 1000000) AS output_token_cost_per_token, -- Claude Haiku 4.5: Price (/1M tokens): Output: $5.00
FROM
logic_token_breakdown
),
logic_costs_per_call AS (
SELECT
*,
input_token_cost_per_token * input_token_size AS original_input_cost,
input_token_cost_per_token * (0.10 * cached_tokens_read) AS cached_tokens_read_cost,
input_token_cost_per_token * (1.25 * cached_tokens_written) AS cached_tokens_written_cost,
output_token_cost_per_token * output_token_size AS original_output_cost,
FROM
logic_token_original_cost
),
-- =========================
-- Final CTE
-- =========================
final AS (
SELECT
DATE_TRUNC(DATE(created_at), MONTH) AS month,
SUM(original_input_cost) AS original_input_cost_sum,
SUM(original_output_cost) AS original_output_cost_sum,
SUM(
cached_tokens_read_cost + cached_tokens_written_cost
) AS simulated_input_cost_sum,
SUM(original_input_cost + original_output_cost) AS original_total_cost_sum,
SUM(
cached_tokens_read_cost + cached_tokens_written_cost
) AS simulated_total_cost_sum,
SUM(original_input_cost + original_output_cost) - SUM(
cached_tokens_read_cost + cached_tokens_written_cost
) AS total_cost_saving_sum, -- コスト削減量
SAFE_DIVIDE(
SUM(original_input_cost + original_output_cost) - SUM(
cached_tokens_read_cost + cached_tokens_written_cost
),
SUM(original_input_cost + original_output_cost),
) AS total_cost_saving_rate -- コスト削減率
FROM
logic_costs_per_call
GROUP BY
month
)
SELECT
*
FROM
final
ORDER BY
month;
すでにログが取れている場合はサクッと試算できるので試してみてください。思ったより減ります。
おわりに
Prompt Cachingの仕組みとプラクティスを紹介しました。まずは冒頭のシステムプロンプトからだけでも、ぜひ試してみてください。
それから、この後も Ubie Tech Advent Calendar 2025 にはおもしろ記事が続きます。ぜひチェックしてください。

Discussion