本エントリはUbie 生成AI Advent Calendar 2024の20日目、「社内用生成AI Webアプリケーションをどのように作っているか」の第7回です。
前回は、第6回 音声書き起こしとプロンプト処理を連携するについて説明しました。今回は、リアルタイム文字起こしに関して説明します。
録音後の文字起こしも悪くないが、リアルタイムの方が楽
当初、リアルタイム文字起こしのアイデアを見た時、あまりピンと来ていませんでした。音声の文字起こし機能はすでにあるし、そこまで重要だろうか?しかし、実際に作り、使ってみたところかなり便利である実感が湧きました。
リアルタイム文字起こしのファーストバージョンの作者は@ngsw_taroです。
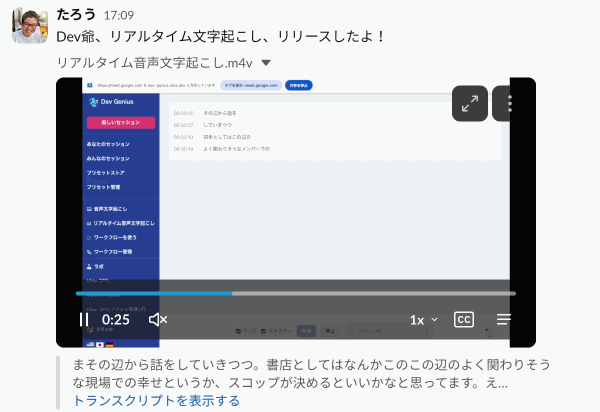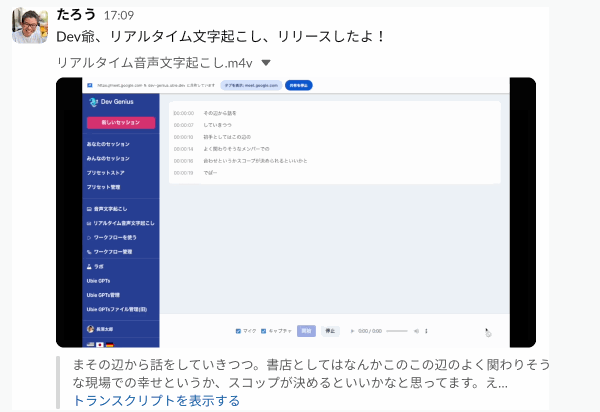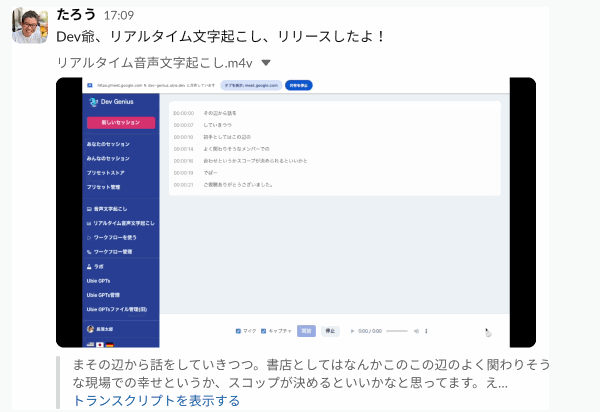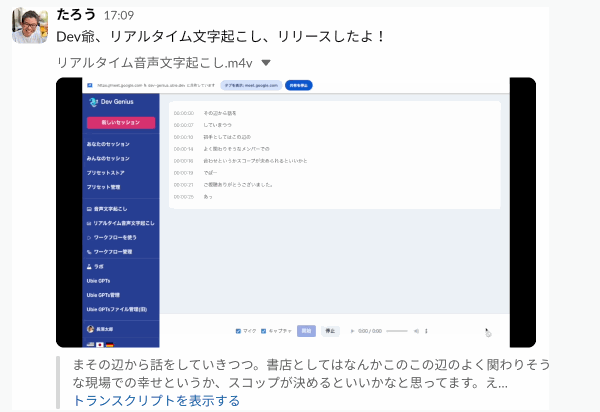
リアルタイム文字起こしが良いと感じた点は以下の通りです。
- 録音が終わった時は文字起こしが終わっている
- 録音中に文字起こし結果が随時分かる
- 必要に応じてその場で編集できる
- 録音中の内容をプロンプト処理できる
- 進行状況の可視化、論点整理などに使える

ミーティング後すぐにまとめを作成
リアルタイム文字起こしの機能を使って、オンラインカンファレンスを数トラック同時に文字起こししながら視聴するという人も現れました。
実現のための要素を分解する
リアルタイム文字起こしをいきなり作ろうとしてもなんだか難しそうです。一旦この機能を実現するために必要な要素を分解してみます。
ざっくりと4つの要素に分解できました。これらの要素の実現性を検討すればよさそうです。

なんかそんな難しくなさそうだな
Dev Genius[1]では、それぞれの要素を以下の方法で実現しています。

あとはつなげるだけだ
音声を録音する
Dev GeniusはNext.jsのアプリケーションなので、ユーザの実行環境はブラウザです。MediaRecorderを用いれば、マイクやブラウザ上の音声を録音できます。
// コード例
const startRecording = async () => {
// マイクからの音声を取得
const microphone = await navigator.mediaDevices.getUserMedia({ audio: true });
// ブラウザタブの音声を取得
const tab = await navigator.mediaDevices.getDisplayMedia({ audio: true });
// マイクとブラウザタブの音声を結合
const mediaSources = [microphone, tab];
const audioContext = new AudioContext();
const destination = audioContext.createMediaStreamDestination();
mediaSources.forEach((mediaSource) => {
const source = audioContext.createMediaStreamSource(mediaSource);
source.connect(destination);
});
const mediaStream = destination.stream;
// ユーザー環境の利用可能なMimeTypeを推測する
const mimeType = detectMimeType();
const mediaRecorder = new MediaRecorder(mediaStream, { mimeType });
// 録音開始
mediaRecorder.start();
}
const detectMimeType = (): string => {
const mimeTypes = ["audio/mp4", "audio/mpeg", "audio/aac", "audio/wav"];
if (typeof window === "undefined") return "";
return (
mimeTypes.find((mimeType) => MediaRecorder.isTypeSupported(mimeType)) ??
"audio/mpeg"
);
};
getDisplayMedia()を用いると以下のように、タブを選択するダイアログが出てきます。

なんか見たことある
音声を区切る
音声を区切る方法として、固定の秒数を用いてもいいかもしれません。しかしその場合、発話中の音声を分断する場合があり、文字起こしの精度に影響を及ぼしてしまいます。発話の途切れ目を検出して、途切れ目で区切れるとよさそうです。
ブラウザ上で利用できるHarkというライブラリがあります。これを用いると、音声ストリームの発話の開始と終了を検出し、イベントとして受け取れます。
const speakingEvent = hark(mediaStream);
speakingEvent.on("speaking", () => {
// 発話開始
});
speakingEvent.on("stopped_speaking", () => {
// 発話が終わったら録音を停止して、再開する
mediaRecorder?.stop();
mediaRecorder?.start();
});
文字起こしする
区切った音声を文字起こしします。区切った音声は以下のように取り出します。
const chunksRef = useRef<Blob[]>([]);
// 録音データを溜める
mediaRecorder.ondataavailable = (event: BlobEvent) => {
chunksRef.current.push(event.data);
};
// 録音が終わったら、溜めた音声データを文字起こしに渡す
mediaRecorderRef.current.onstop = () => {
if (chunksRef.current.length === 0) {
console.log("chunks is empty");
return;
}
const mediaBlob = new Blob(chunksRef.current, { type: mimeType });
// 音声データを文字起こしに渡す
onReceive(mediaBlob);
chunksRef.current.length = 0;
};
あとは単純にAPIにデータを渡すだけです。リアルタイム文字起こしではWhisperを用いています。Gemini 1.5 Proでも良いのですが、Dev GeniusではVertex AI経由でRate Limitを小さめにしているので、特に制限のないWhisperを用いています。Whisperはおおよそ30分程度の文字起こしが限度ですが、発話の区切り単位での文字起こしであればほぼ問題になりません。
永続化する
あとは文字起こしした情報を永続化するだけ。ここはあんまり言う事はないですがとりあえずデータベースのテーブルの例だけ書きます。
CREATE TABLE public.realtime_transcription_segments (
id serial4 NOT NULL,
realtime_transcription_id int4 NOT NULL,
"start" int4 NOT NULL, -- 音声全体における、この音声の開始時間
"text" text NOT NULL, -- 文字起こし結果
blob_type text NOT NULL, -- 音声データのMimeType
blob_size int4 NOT NULL, -- 音声データのサイズ
blob_duration int4 NOT NULL, -- 音声データの長さ
blob_content text NOT NULL, -- 音声データ(Base64)
created_at timestamp(3) DEFAULT CURRENT_TIMESTAMP NOT NULL,
);
音声をBase64にしてデータベースに保存していますが、実際はGCSやS3に保存するのが良いでしょう。
音声を区切る長さのスレッショルドを調整する
上記の要素がそろえばリアルタイム文字起こしを実現できます。ただ、音声周りについてはまだ改善の余地があります。Harkによる音声の区切りの検出は、特に長さについては考慮してくれません。たとえば「あー」とか「うん」といった短い音声も区切られてしまいます。こういった1秒や1秒未満の音声を文字起こしした場合、ハルシネーションが起こるケースが多いです。

はじめしゃちょー...?ユーチューバーが出がち
そこで、Harkでの区切りの他に、スレッショルドを設けて最小の長さを担保する仕組みを追加しました。以下は最低10秒の音声を区切るようにする例です。
const isSpeakingRef = useRef(false);
const speakingStartAtRef = useRef<number | null>(null);
const threshold = 10000; // デフォルトは10秒にしています。
const speakingEvent = hark(mediaStream);
speakingEvent.on("speaking", () => {
isSpeakingRef.current = true;
});
speakingEvent.on("stopped_speaking", () => {
if (!isSpeakingRef.current) {
return;
}
// 経過時間を計算する
const speakingDuration = Date.now() - speakingStartAtRef.current!;
if (speakingDuration < threshold) {
return;
}
speakingStartAtRef.current = Date.now();
mediaRecorder?.stop();
mediaRecorder?.start();
});
録音中や録音後にプロンプトで処理する
リアルタイム文字起こしの良い点は、その場で文字起こししたデータを処理できることです。現在まで話したことのサマリや、残論点、ネクストアクションなどをリアルタイムに整理することができ、様々なシーンで活用が可能です。

聞き逃しても安心
リアルタイムでのプロンプト処理のほかに、録音後に一括したプロンプト処理もできます。議事録の作成のほか、文字起こしした内容を使って必要な情報を抽出したり、その場で生成AIと会話して調査や相談したりもできます。

モバイルアプリケーションチームのミーティング内容からネクストアクションを洗い出す
まとめ
リアルタイム文字起こしを実現する方法について解説しました。この機能における生成AIの役割は全体から見るとそれほど大きくありません。しかし社内ではかなりインパクトのあるものとなりました。生成AIを要素技術として捉えることで、既存の技術との組み合わせで新しいものを作ることができるのではないかと思います。
-
Ubieの社内で内製している生成AI Webアプリケーションです。普段はdev爺と呼ばれています。 ↩︎

Discussion