本エントリはUbie 生成AI Advent Calendar 2024の17日目、「社内用生成AI Webアプリケーションをどのように作っているか」の第6回です。
前回は、第5回 Web検索機能によって生成AIとの会話中の知識を強化するについて説明しました。今回は、音声書き起こしとプロンプト処理との連携について解説します。
意外とすごいGeminiシリーズの音声処理
音声の文字起こしは生成AIが台頭する以前からソリューションが沢山存在していました。生成AIによって多言語への対応やノイズやアクセントの違いに強いなどの一定のブレークスルーが起きたそうですが、筆者はその辺りの歴史にはあまり詳しくないです。
一旦既存のソリューションは置いておいて、生成AIの世界での音声処理に焦点を当てた場合の選択肢について考えてみます。主要なものとしてOpenAIのWhisperとGoogleのGeminiシリーズがあります。
| API | ファイルサイズ制限 | 対応フォーマット | 音声の最大の長さ |
|---|---|---|---|
| Whisper | 25MB | mp3, m4a, wav, webm, mp4, mpeg, mpga | ファイルサイズに依存するが、概ね30分程度 |
| Gemini Flash | 制限特になし | mp3, m4a, wav, webm, aiff, aac, ogg, flac | 8.4時間以下または最大100万トークン |
| Gemini Pro | 制限特になし | mp3, m4a, wav, webm, aiff, aac, ogg, flac | 8.4時間以下または最大100万トークン |
どちらも書き起こし精度は悪くなく、性能差はそこまで感じられません。そのままでも十分使えますが、やはり固有名詞などには弱い場合などもあり、Cloud Speech-to-Textや事前の辞書データを組み合わせて精度を上げる例などもあるようです。
GeminiとSpeech-to-Textで実現する高精度な文字起こし
WhisperとGeminiを比較してみると、最大のファイルサイズに大きな差があります。Whisperは1リクエストで25MBまでなので、mp3等で圧縮しても大体30分程度の音声までが限界です。一方、Geminiは1リクエストで8.4時間以下または最大100万トークンなので、殆どのユースケースに置いて十分なサイズではないかと思います。
Dev Genius[1]の音声書き起こし機能では、Gemini 1.5 Proを使用しています。
事前のプロンプトを設定可能にする
音声を書き起こすといっても様々な目的があります。単純に正確に書き起こしたい場合もあれば、音声の内容を要約したい場合などもあるでしょう。
そのため、事前にプロンプトを設定可能にしておくことで、目的に合わせて柔軟に対応できるようにしています。

以下はMP3のファイルをフォームから受け取って、Gemini 1.5 Proで音声を書き起こすServer Actionsの実装例です。
"use server";
import { VertexAI, GenerativeModel, InlineDataPart } from "@google-cloud/vertexai";
export const createTranscription = async (formData: FormData) => {
// formDataからファイルとプロンプトを受け取る
const uploadFile = formData.get("file") as File | null;
const prePrompt = formData.get("prePrompt") as string | null;
if (!uploadFile || uploadFile.type !== "audio/mp3") {
console.error("Invalid file");
return;
}
// ほんとは別にbase64にしなくてもいいかも
const arrayBuffer = await uploadFile.arrayBuffer();
const buffer = Buffer.from(arrayBuffer);
const base64 = buffer.toString("base64");
const vertexAI = new VertexAI({
project: process.env.VERTEX_PROJECT_ID,
location: "asia-northeast1",
});
if (!vertexAI) {
console.error("Vertex AI not found");
return;
}
const generativeModel = vertexAI.getGenerativeModel({
model: "gemini-1.5-pro-001",
});
const inlinePart: InlineDataPart = {
inlineData: {
data: base64,
mimeType: "audio/mp3",
},
};
const textPart = {
text: prePrompt || `音声を書き起こしてください。読みやすいように句読点や改行を追加し読みやすくしてください。`,
};
const request = {
contents: [{ role: "user", parts: [inlinePart, textPart] }],
};
const transcriptionPromise = generativeModel.generateContent(request);
return transcriptionPromise
.then(result => {
const text = result.response.candidates
?.map(candidate => candidate.content.parts.map(c => c.text))
.join("\n");
return text;
});
};
実際に試してみると、以下のような結果が得られました。書き起こし対象の動画は https://www.youtube.com/watch?v=NIQDnWlwYyQ を利用しました。

元は英語だけど日本語にしてくれるんですね
事前プロンプトを変えると以下のようになります。
内容を要約し箇条書きにしてください。

これはこれでわかりやすい
プリセットと連携する
ほとんどの場合、一旦音声をそのまま書き起こすことになるでしょう。その後の加工を自由に行えるからです。
Dev Geniusでは、書き起こし内容を簡単にチャットで処理できるようにしています。プリセットと組み合わせることで、簡単に目的の出力を得られます。
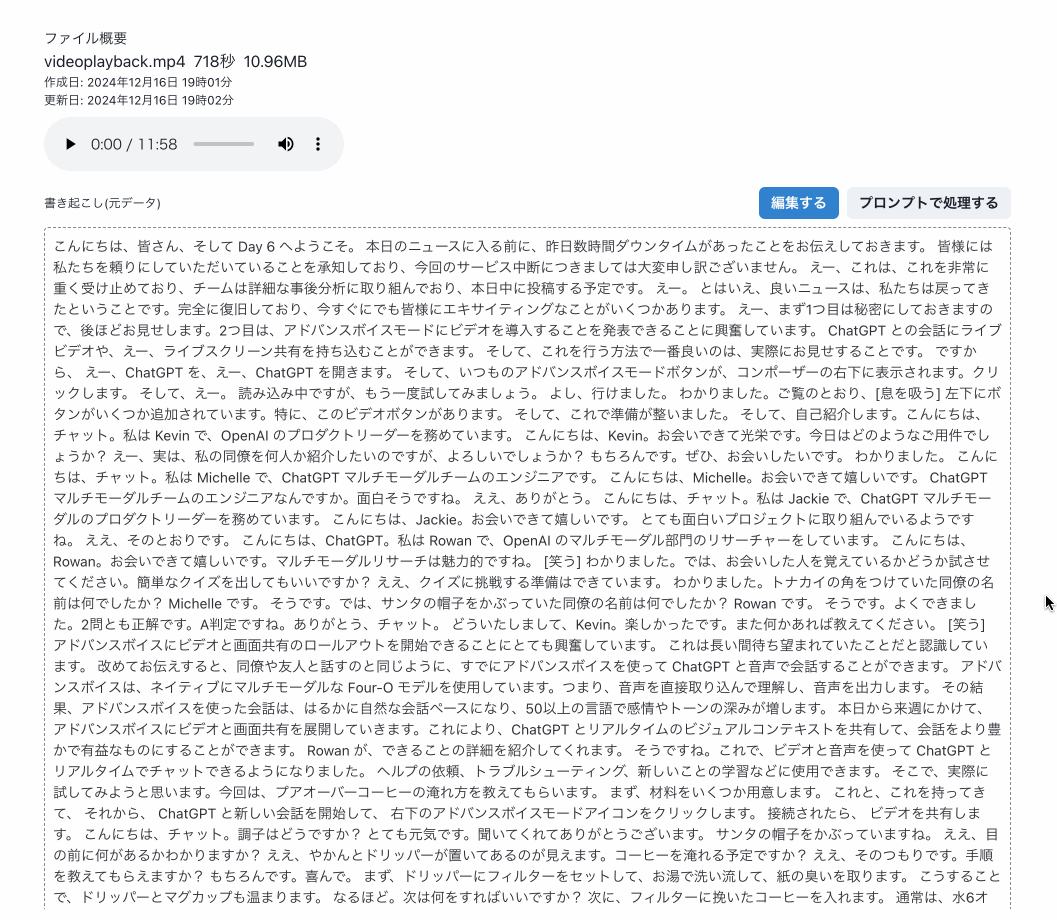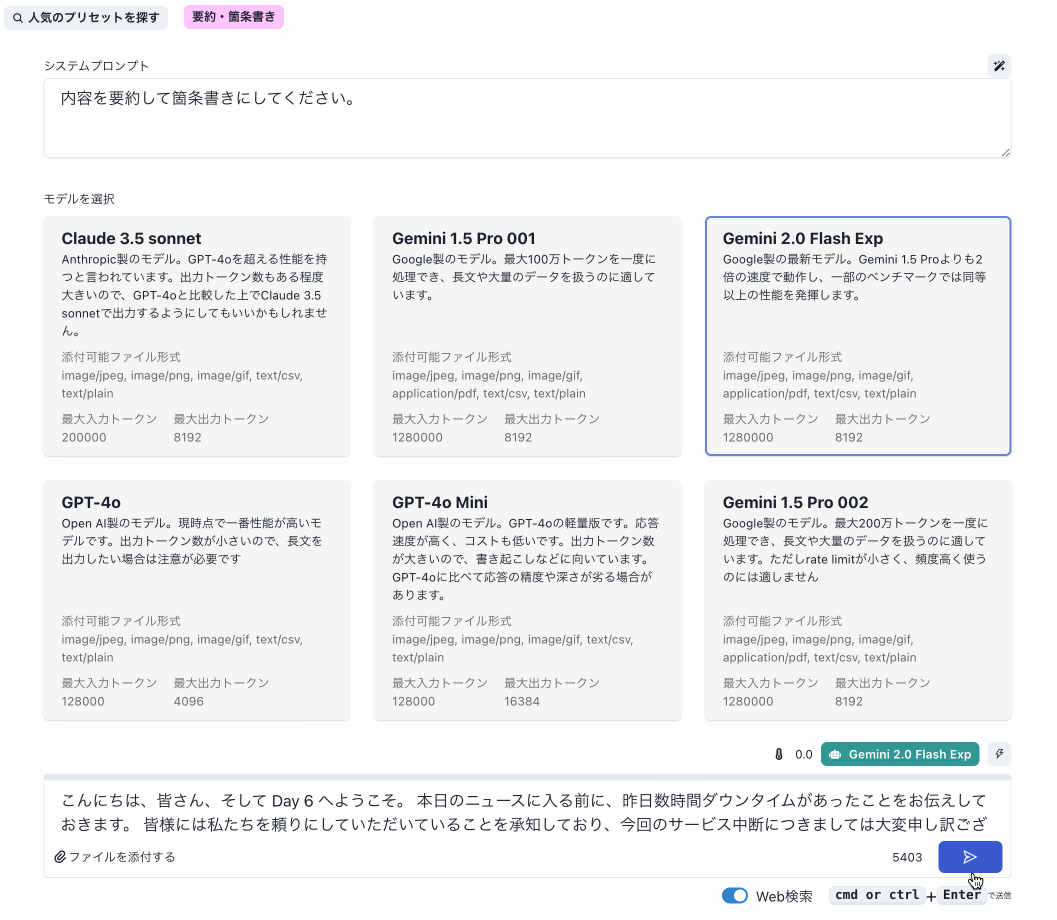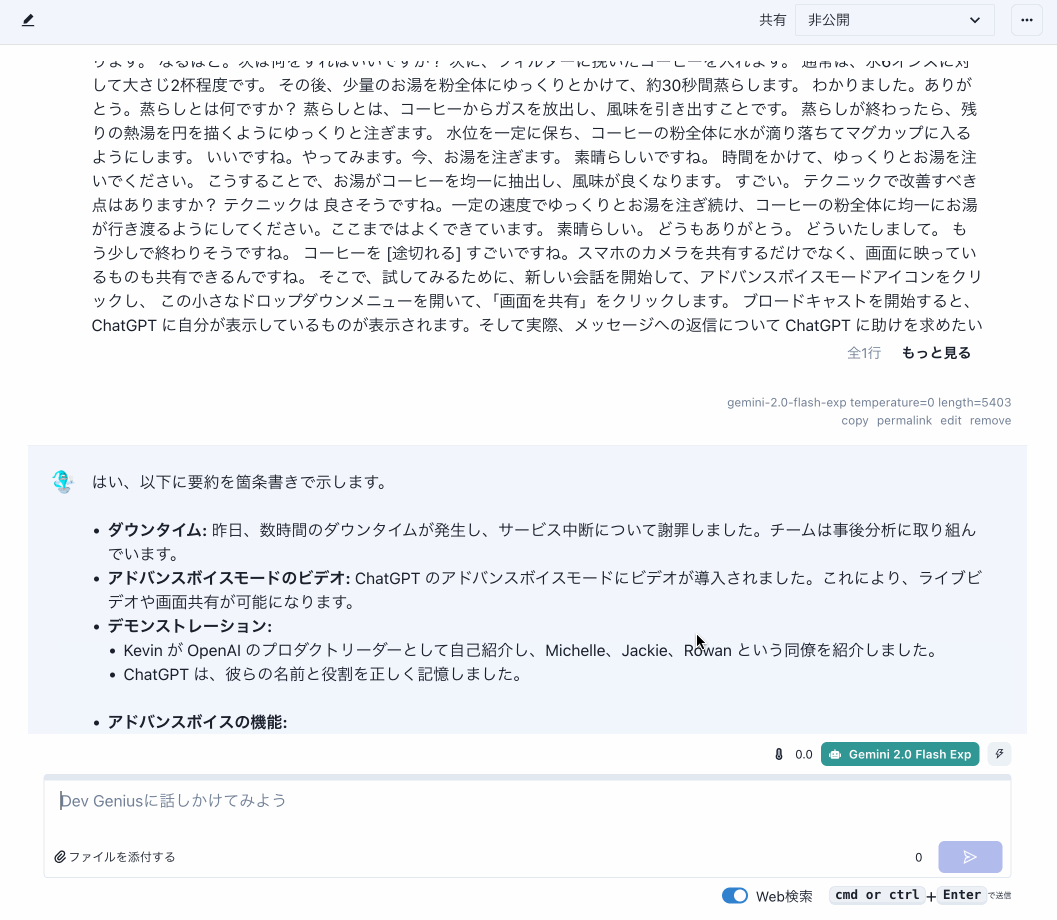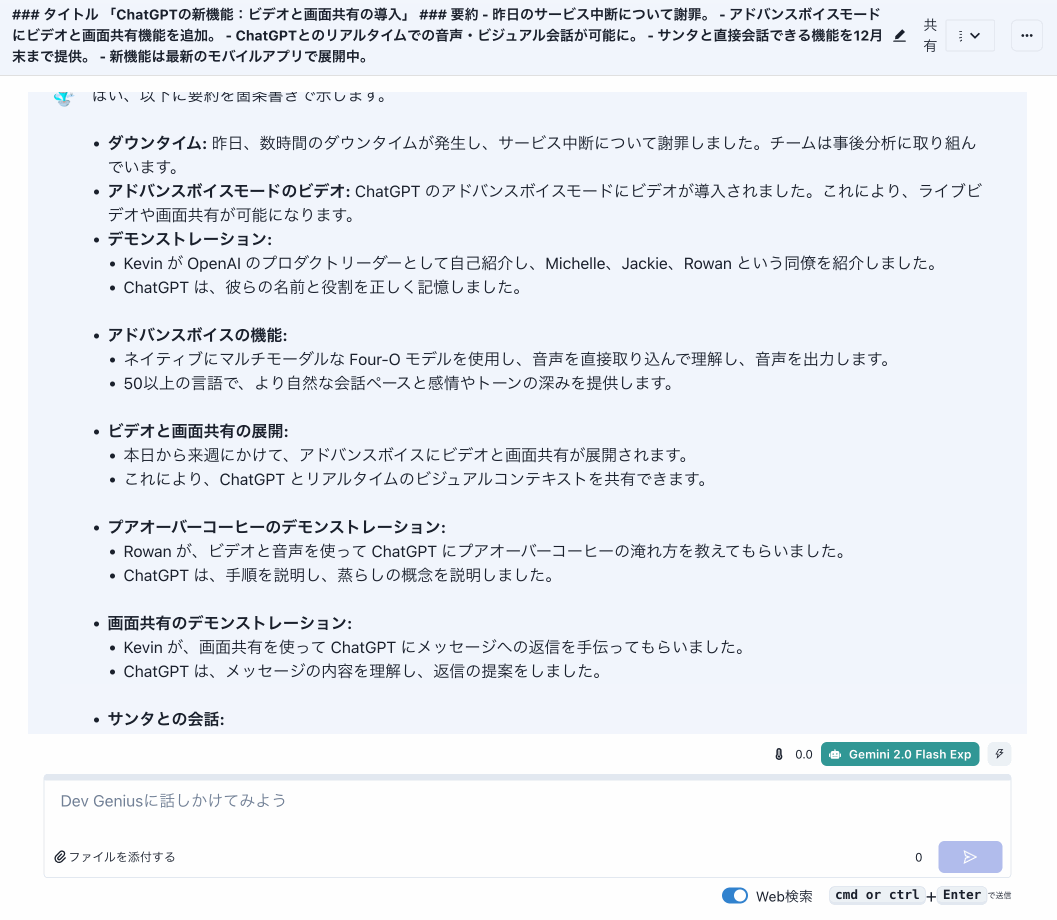
ChatGPTのビデオと画面共有の機能は気になりますね
ミーティングの動画等の場合であれば、内容の要約のほかに、自分のネクストアクションを抽出したり、あるいはそのアクションに向けて相談したりもできます。
おまけ、ffmpegをブラウザで使うことで動画変換リソースを分散させる
Gemini 1.5 Proは動画ファイルの処理サポートしていますが、音声付きの場合は50分までが上限となります。動画の内容理解を目的とした機能なので、音声書き起こしに利用するのはややオーバースペックでありつつ、処理可能な長さは物足りません。
なので、動画ファイルの場合は音声ファイルに変換した上で書き起こしの処理を行いたくなります。当初はサーバ側でffmpegをインストールし、変換処理を行っていました。現在ではWebAssemblyを用いて、フロントエンドでffmpegを動かし、動画を音声に変換することでリソースを分散させるようにしています。以下は選択したファイルをmp3に変換する例です。変換したファイルをFormDataに追加してPOSTすることで、サーバ側では常に音声ファイルだけを意識すれば良くなります。この実装は@yukukotaniが行ってくれました。
import { FFmpeg } from "@ffmpeg/ffmpeg";
import { fetchFile, toBlobURL } from "@ffmpeg/util";
import { ProgressEventCallback } from "@ffmpeg/ffmpeg/dist/esm/types";
const ffmpeg = new FFmpeg();
const FFMPEG_CORE_URL = "https://unpkg.com/@ffmpeg/core@0.12.6/dist/umd";
async function convertVideoToMp3(file: File, onProgress: (progress: number) => void): Promise<File> {
await ffmpeg.load({
coreURL: await toBlobURL(
`${FFMPEG_CORE_URL}/ffmpeg-core.js`,
"text/javascript",
),
wasmURL: await toBlobURL(
`${FFMPEG_CORE_URL}/ffmpeg-core.wasm`,
"application/wasm",
),
});
await ffmpeg.writeFile(file.name, await fetchFile(file));
const progressCallback: ProgressEventCallback = (e) => {
onProgress(Math.floor(e.progress * 100));
};
ffmpeg.on("progress", progressCallback);
await ffmpeg.exec(["-i", file.name, "-f", "mp3", "output.mp3"]);
const mp3Data = await ffmpeg.readFile("output.mp3");
const mp3File = new File([mp3Data], "output.mp3", {
type: "audio/mp3",
});
ffmpeg.off("progress", progressCallback);
ffmpeg.deleteFile(file.name);
return mp3File;
}
まとめ
社内の生成AI Webアプリケーションにおける音声書き起こしとプロンプト処理の連携、おまけでWebAssemblyを用いてフロントエンドで音声変換する処理について説明しました。ほぼAPIを利用しているだけなのでシンプルな作りです。今後は書き起こしデータの共有設定や、事前プロンプトでのプリセット利用などいくつかの改善が考えられます。音声書き起こしは大抵ワンショットで終わらず、その後要約やレポーティングや情報抽出などを必要とする場合が多いでしょう。この点についてはワークフローに関するエントリでまた触れたいと思います。
-
Ubieの社内で内製している生成AI Webアプリケーションです。普段はdev爺と呼ばれています。 ↩︎

Discussion