文書要約モデルの性能の新しい評価指標について2(QuestEval)
こんばんは。今回は、こちらの論文にて提唱されている新しい評価指標「QuestEval」 について、記事を書きます。
QuestEval: Summarization Asks for Fact-based Evaluation
※本記事にある画像は、当論文より引用しています。
本記事は、こちらの記事の続きとなります。こちらの記事を先に読まれることをおすすめします。
文書要約モデルの性能の新しい評価指標について1(QAGS)
前置き
QAGS
前回の記事(「文書要約モデルの性能の新しい評価指標について1(QAGS)」)では、文書要約におけるQAGSという新しい評価指標について論じました。QAGSの主なメリットとして、人間による参照文の作成が不要であること、および既存の評価指標に比べて要約の良し悪しの人的判断が加味される点を挙げました。
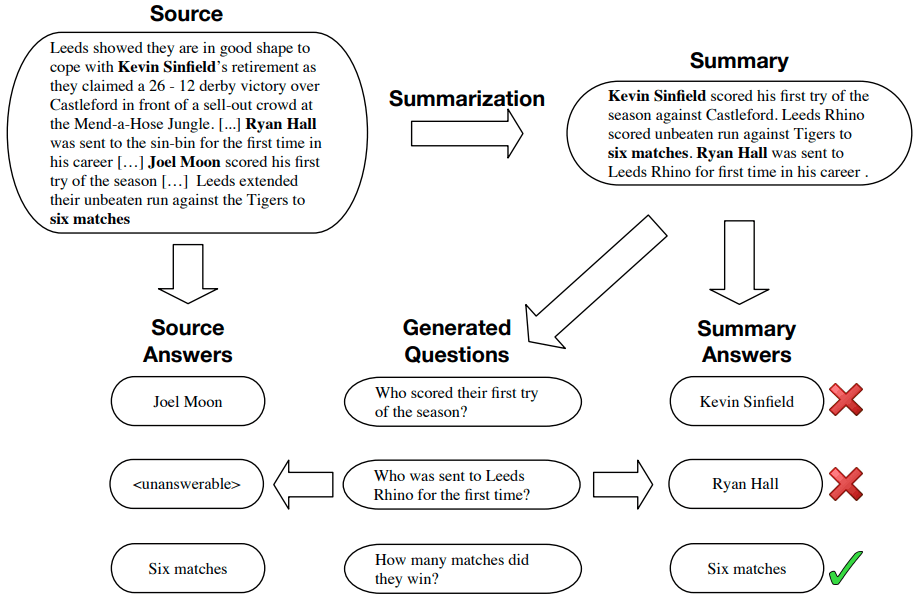
今回の前置きはここまでです。さっそくQuestEvalの説明に入っていきます。QAGSさえ理解していれば、QuestEvalを理解するのはそんなに難しくないと思います。
新しい評価指標QuestEval
QuestEvalによる評価の仕組み
当論文にこのような図があります。
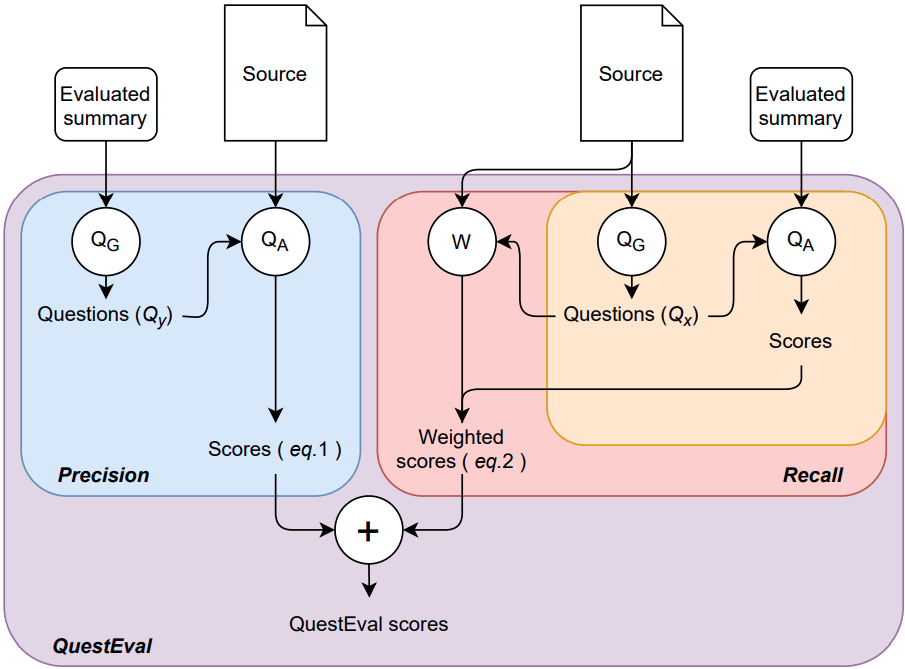
この図中の紫色のブロックよりも上にあるSource、およびEvaluated Summaryが、QuestEvalにおける入力内容です。Sourceと要約対象文書のことで、Evaluated Summaryは候補文(文書要約モデルを用いて要約対象文書を要約したもの)のことです。これらは左右それぞれにありますが、いずれも共通のものです。
途中の計算過程に「Precision」と「Recall」があり、最後にこれらの演算(調和平均など)によりQuestEvalのスコアが得られます。これら「Precision」と「Recall」が、QuestEvalの肝となります。なお、本記事では区別を付けやすくするため、これらPrecisionとRecallをカギかっこで括ります。
「Precision」
実のところ、この「Precision」はQAGSと同様のものです。図中の「Precision」の枠は、候補文を質問生成モデルにかけて質問を生成し、「要約対象文書ベースで回答した内容」と「候補文ベースで回答した内容」(いずれも、質問応答モデルを用いて回答を生成する)の類似度のスコアを出す処理です。ですので、「Precision」は実質的にQAGSと同等であることが分かります。
「Recall」
「Precision」との違い
図中の赤いブロックで囲まれた「Recall」の中に、オレンジのブロックがあります。このオレンジのブロックを、左側の「Precision」のブロックと見比べてみてください。両者の違いは、質問生成モデルの入力くらいであることが分かります。左側の「Precision」では質問生成モデルの入力は候補文でしたが、右側のオレンジのブロックでは質問生成モデルの入力は要約対象文書になっています。この箇所が、QAGSにはない、QuestEvalの主な新規性となります。
私的に「Precision」と「Recall」を解釈すると、次のようになります。
| QuestEvalの構成要素 | 解釈 |
|---|---|
| 「Precision」 | 「要約対象文書の内容に照らし合わせて、候補文の内容自体が正しい」ほど、「Precision」は高い値を取る。 |
| 「Recall」 | 要約対象文書の内容の要点がたくさん候補文に反映されている」ほど、「Recall」は高い値を取る。 |
上のように解釈すると、「Precision」・「Recall」は、文書分類の性能の評価指標である適合率・再現率と似たように考えられそうです。また、適合率と再現率はトレードオフの関係なので、両方を加味することが重要です。
そう考えると、QuestEvalは、適合率に相当する「Precision」と再現率に相当する「Recall」の両方をうまく加味できていると言えそうです。
各質問に対する重み
ただし、QuestEvalにはまだ押さえておくべき要素があります。それは、質問生成モデルによって生成された各質問に対する重みづけです。重要度を意味する重みを、各質問に付与します。そして、質問ごとのスコア(2種類の回答内容の類似度)の平均を取る際に、その重みを加味した加重平均を取るようにするのです。
今、重要度と書きました。当論文を読み解くと、要約対象文書についての重要な情報について問うている質問ほど、重要度が高いということです。それなら、重要度を意味する重みを加味するのはうなずけますね。具体的な方法の記述は割愛しますが、事前に各質問に重みをつけているようです。
また、「Precision」にはこの重みは出てきません。その理由は不明ですが、ひとつ仮説が立ちます。「Precision」は質問生成の入力元が要約対象文書であるゆえ、重要な情報について問うている質問が生成されやすく、よってことさら質問に重みをつける必要はない…ということなのかもしれません。
実験
既存の評価指標に比べて要約の良し悪しの人的判断が加味されるQAGSに比べて、QuestEvalはそれ以上に要約の良し悪しの人的判断が加味されるのか。今回は、このことに焦点を当てて説明します。
前提
データセット
当論文にはSummEvalというデータセットと、QAGS-XSUMというデータセットが用いられています。SummEvalの持つ特徴についても論じたいため、今回はSummEvalに絞って説明します。
SummEvalは、文書要約タスクにおいて最もよく用いられるデータセットCNN/DMから作られたデータセットです。特徴の1つは、各候補文に対して評価項目が4種類もあることです。具体的には次のものです。また、各評価項目の意味合いを読み取った結果も載せています。
| 候補文の評価項目 | 意味合い |
|---|---|
| Consistency | 候補文の中にある正しい記述の割合(「Precision」と同等) |
| Coherence | 良い構造をしていること |
| Fluency | 読みやすさ |
| Relevance | 要約対象文書の内容がどれほど多く記述されているか(「Recall」と同等) |
このデータセットには、各評価項目について候補文を人力で評価(アノテーション)した結果も含まれています。評価項目の種類をこれだけ豊富に持つデータセットを初めて知り、興味を覚えています。
また、これら4種類の項目はBLEUやROUGEなどの評価指標とはまた別物ですので、区別をつけるために「評価項目」と記述しています。
このデータセットの特徴は他にもありますが、今回の記事では割愛します。
モデル
詳細は不明ですが、実験に用いられた質問生成モデルも質問応答モデルも、SQuAD-v2とNewsQAを学習して構築されたようです。
実験結果
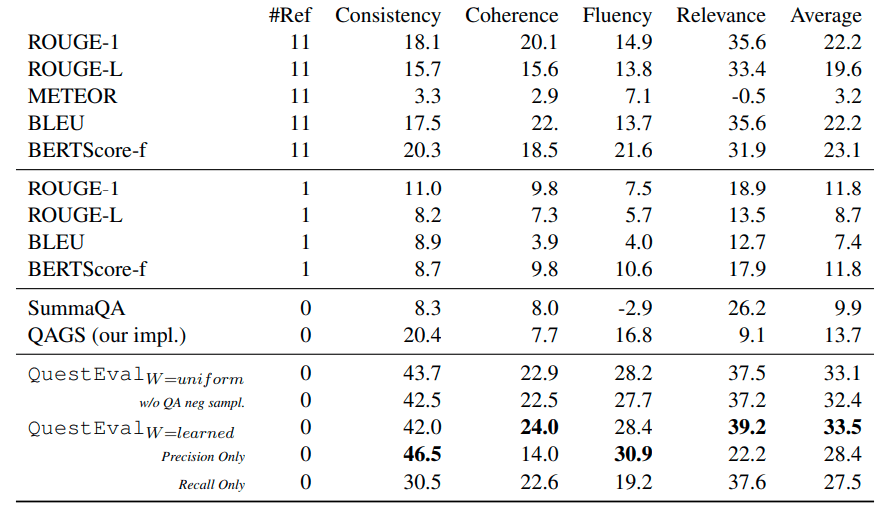
この表は、データセットSummEvalを用いた実験の結果です。
上の結果の表の見方
表の左側に並んでいるBLEU、ROUGE、BERTScoreなどは、文書要約モデルの性能の各評価指標です。見ての通り、この中にはQAGS、そして当論文にて提唱されたQuestEvalも入っています。
これらの評価指標の優劣を比較します。どういう観点で比較するか。例えば、SummEvalの中に評価項目Consistencyがあります。知りたいのは、「どの評価指標(BLEU、ROUGE、BERTScore、QAGS、QuestEvalなど)なら、Consistencyの高い候補文に対して高い評価値を付けることができるか」です。言い換えれば、知りたいのは、Consistencyとの相関係数の高い評価指標です。
なぜこれを知りたいのかというと、Consistencyは人的判断による評価項目です。そのため、Consistencyとの相関係数の高い評価指標があれば、その評価指標は要約の良し悪しの人的判断が加味されることになるためです。もちろん今回望む結果は、QuestEvalが最もConsistencyとの相関係数が高くなることです。上の表は、この相関係数を始めとした、各組合せごとの相関係数がまとめられたものです。これを見ることで、どの評価指標が比較的高い相関係数を持つのかが分かります。ただし、QAGSの論文と同様に、上の表の値は元の相関係数の100倍ではないかと考えています。
ここまで、Consistencyを例にとりましたが、他の評価項目Coherence、Fluency、Relevanceについても同様です。
結果に対する解釈
改めてこの実験結果を見ると、比較対象の中にQAGSがあっても、QuestEvalが総合的に突出した相関係数を出していることに驚かされます。QAGSに比べて、「Recall」の要素の取り込みが奏功したと言えると思います。
ちなみに、相関係数0.5の相関ぐあいはこのくらいで、あまり強くないです。QuestEvalでさえも総じて0.5には届かず、まだまだです。それでも、これまでの評価指標に比べればだいぶ相関係数が高くなり、かなり進歩したと思います。
終わりに
前回のQAGSも今回のQuestEvalも、文書要約だけでなくその他の文書生成系タスク全般にも使えるかもしれません。応用先としては、自然言語処理にとどまらず、Image Captioningなどのマルチモーダルの分野もあると思います。応用しようとなると課題は多いかもしれませんが、それでも今回のQuestEvalは、人的評価をできるだけ加味したい場合には有益な知見になりそうです。
最後まで読んでいただき、ありがとうございました!
Discussion