文書要約モデルの性能の新しい評価指標について1(QAGS)
こんばんは。今回は、こちらの論文にて提唱されている新しい評価指標「QAGS」 (Question Answering and Generation for Summarization)について、記事を書きます。
Asking and Answering Questions to Evaluate the Factual Consistency of Summaries
※本記事にある画像は、当論文より引用しています。
※本記事には、次の関連記事があります。
-
文書要約モデルの性能の新しい評価指標について2(QuestEval)
https://zenn.dev/ty_nlp/articles/ae6ca0d20a1cf3 -
文書要約の評価指標QAGSにおいて、2種の回答の類似度をどう測るか
https://zenn.dev/ty_nlp/articles/ee4e17b6191987
前置き
文書要約タスクは、自然言語処理における言語タスクの一種です。文書要約タスクなどについて、前置きとしていくつか述べておきます。
文書要約モデルの性能の評価の流れ
文書要約モデルは、文書要約タスクのできるモデルです。他の言語タスクの場合と同様に、文書要約モデルの性能を評価したい場面があると思います。
細かな違いはあれど、文書要約モデルの性能の評価の大まかな流れは、次の通りです。
まず、要約対象文書をいくつか準備します。同時に、各要約対象文書に対して1つの参照文(意味は下の表にあります)を設定しておきます。次に、文書要約モデルを用いて各要約対象文書を要約し、各要約対象文書に対する候補文(意味は下の表にあります)を1つ作成します。最後に、各要約対象文書ごとに、参照文と候補文がどれだけ近しいかを評価します。通常、評価の際には何らかの評価指標によって数的評価を算出します。
| 用語名 | 意味 |
|---|---|
| 要約対象文書(source) | 文字通り、要約対象の文書。文書要約モデルを用いて、この文書を要約する。 |
| 参照文(reference) | 要約対象文書の要約の正解となる文章の1つ。人間が設定しておく。文書要約タスクにおいては明確な正解はないため、参照文は複数のパターンがありうる。 |
| 候補文 | 文書要約モデルを用いて要約対象文書を要約した結果の文章。 |
既存の有名な評価指標
古くからある評価指標の中でも有名なものとして、BLEUとROUGEがあります。これらの評価指標の特徴は、参照文と候補文を、各単語の重複の多さによって評価することです。とにかく単語レベルでの評価というのが要点です。
文書要約タスクの分野では、今でも評価指標としてROUGEがよく用いられます。
また、比較的新しい評価指標としてはBERTScoreがあります。BLEUやROUGEに比べると、BERTScoreは文脈(context)を加味する評価指標です。
質問生成モデルと質問応答モデル
一見すると文書要約とは無関係に思えますが、必要になるのであらかじめ説明しておきます。
質問生成モデルとは、与えられた文書に関する質問文を作るモデルです。そのようなモデルがあるとは、当論文を読んで初めて知りました。
質問応答モデルは、「何かを説明する文書」と「質問文」を入力すると、前者を手掛かりにして後者に回答するモデルです。
当論文には、文書要約モデルに加えて、これら質問生成モデルと質問応答モデルが出てきます。このように3種類の意味合いのモデルがあるので、これらの位置づけを踏まえていただけたらと思います。
新しい評価指標QAGS
QAGSによる評価の仕組み
いよいよQAGSについてです。QAGSは、当論文が提唱した新しい文書要約の性能の評価指標です。
QAGSは、これまでとは異なる新しいやり方で要約の性能を評価します。この図を用いて説明します。
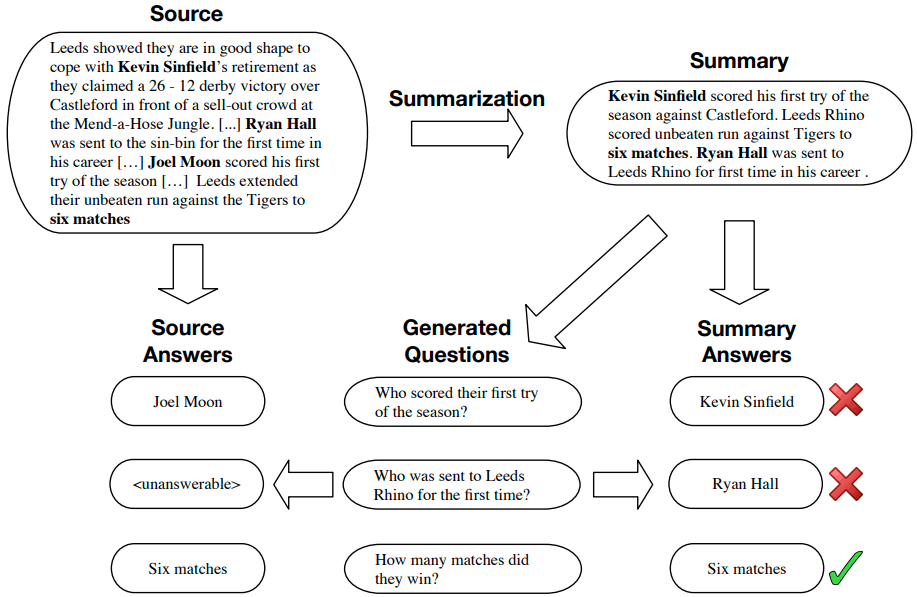
図中の左上にあるのは要約対象文書(source)です。そして図中の右上にあるのが、何らかの文書要約モデルにより作成された候補文です。
文書要約モデルの性能の評価は、各候補文ごとに行います。評価の流れは、次の3ステップから成ります。
- 質問生成
作成された候補文を元にして、事前に用意した質問生成モデルにより質問を生成します。図中では、下段の中央にある質問群に相当します。
- 質問応答
次に、それらの各質問に、事前に用意した質問応答モデルにより次の2種類の方法で回答します。図中では、下段のそれぞれ左側と右側に相当します。
・要約対象文書を手掛かりとして、質問応答モデルにより質問に回答する。
・作成した要約を手掛かりとして、質問応答モデルにより質問に回答する。
- 回答内容の類似度の評価
そして、2種類の回答内容を比較し、回答内容の類似度を評価します。全体的に類似度が高いほど、QAGSによる評価が高くなる…という仕組みです。
図中の右下にある×印やOKの印は、2種類の回答内容が左右で類似(あるいは完全に一致)しているか否かを意味します。
QAGSの利点
QAGSの主な利点は、次の2点になると思います。
- 人間による参照文の作成が不要
多くの場合、人間にとって要約対象文書を要約する作業は大変です。要約対象文書を注意深く読んで理解する必要がありますし、読解した内容を簡潔に記述するのもひと苦労です。
それに、そもそも分類系のタスク(文書分類や極性判定など)などに比べて、文書要約タスクはたいてい正解があまり明確ではなく、いくらでも参照文の作りようがあります。そうかといって、参照文を複数パターン作ろうとすると、それだけ労力がかかってしまいます。
その点、QAGSなら参照文の作成は不要です。
- 従来の評価指標に比べて、人間による要約の良し悪しの判断がスコアとして反映されやすい
これは後述の実験による裏付けですが、人間による要約の良し悪しの判断が反映されやすいようです。これは換言すれば、QAGSによる評価のスコアが高いほど、人間から見て的確な要約となる傾向があることを意味します。
そのため、人的判断を加味して複数の文書要約モデルの性能を比較したい場合に、QAGSは特に有益な評価指標になると思います。
初めてQAGSを知ったときは、とても画期的な評価方法だと思いました。参照文を人間が準備しておくのを、疑いようもなく必須だと思っていたからです。
最初、これでうまく評価できるのかは判断できませんでしたが、少なくとも候補文が要約対象文書に沿った内容であるほど、最後に出力される2種類の回答内容が一致しやすいことは想像できます。
QAGSによる評価スコアの算出
先ほど述べた通り、生成された各質問について2種類の方法で回答しますが、そこで着目するのは質問ごとの2種類の回答内容の類似度です。QAGSによる評価スコアは、質問ごとの2種類の回答内容の類似度の平均値となります。
類似度の測り方(定義)として当論文が挙げている例を読み解くと、ROUGE-1のF1スコアのようです。例えば、上の図中の一番下の質問に対する回答はいずれも「Six matches」になっており、この場合の類似度はもちろん1です。ちなみに、仮に一方のみの回答が「Six」だとすると、類似度は2/3になると思います。
実験
当論文には、主に3種類の実験について記述されています。今回は1つ目の実験に焦点を当てて説明します。1つ目の実験は、人間による要約の良し悪しが評価スコアとしてどのくらい反映されるかを、各評価指標間で比較するものです。
前提
データセット
用いられたデータセットは、CNN-DMとXSUMです。これらのデータセットは文書要約タスクの実験においてよく用いられるものです。
ただし、本実験では文書要約モデルから候補文を作成する代わりに、各データセット内の各要約対象文書に備わっている要約文章を、候補文として用いています。
人力によるアノテーション
アノテーションのしかたも興味深いです。
各候補文は、1つまたは複数の文(sentence)で構成されています。そして1つの候補文の中にある各文ごとに、元の要約対象文書に照らし合わせて、その文が正しいかどうかを判定します。ここでいうアノテーションは、この判定のことです。1つの文につき、3つ分をアノテーションします(おそらく、1つの文につき3人がアノテーションを担当するということだと思います。)。
ちなみに当論文によると、下のような画面からアノテーターがアノテーションをしていたようです。

また、以上の説明を図にすると、下のようになります。
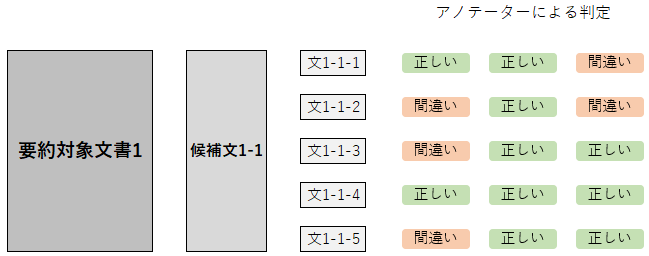
話を簡略化するために、要約対象文書を1つに絞っています。また、1つの要約対象文書に対して候補文が複数の場合もありますが、ここでは候補文を1つだけとしておきます。
この図は、要約対象文書に対して候補文、それから候補文を1文ずつに分解したもの、および各文に対して3回分アノテーションした結果の例を示しています。
候補文の良し悪しの判断
アノテーションを終えると、各文につき3つのアノテーションが付けられたことなります。そうなると、各文ごとに多数派のラベル(正しいか間違いか)が自動的に判明します(アノテーションの数は文ごとに3つなので、2つ以上付いているラベルが多数派となります)。
そこで、候補文の良し悪しの人的判断は次のようにします。すなわち、候補文を構成する文の数に占める、多数派のラベルが「正しい」である文の数の割合でもって、候補文の良し悪しの人的判断のスコアとします。上の図でいうと、1番目、3番目、4番目、および5番目の文は、「正しい」が多数派です。よって、候補文の良し悪しの人的判断のスコアは4/5で0.8となります。
モデル
用いられたモデルは次のそれぞれのモデルです。
| 箇所 | モデル |
|---|---|
| 作成した要約から質問を生成するモデル(質問生成モデル) | fine-tuning済みのBART |
| 生成された質問に回答するモデル(質問応答モデル) | fine-tuning済みのBERT |
結果
実験の結果はこちらです。
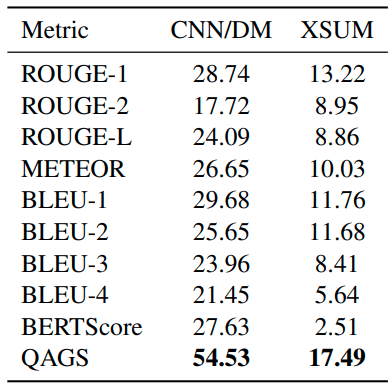
この表の各値は、「人的判断によるスコアの高さ」と「評価指標による評価スコアの高さ」の相関係数です。ただ、ふつう相関係数は-1から1までの値なので、この表にある相関係数の値は100倍とかされたものなのかもしれません。
この結果を見ると、他の評価指標に比べてQAGSがはっきりと高い相関係数を示しています。よって、人間による要約の良し悪しが比較的強く反映されていることが示唆されます。
終わりに
以上のように、今回は当論文に書かれた、文書要約の新しい評価指標を紹介しました。QAGSなら、人手による参照文の作成が不要となります。また、人的判断を加味して複数の文書要約モデルの性能を比較したい場合に、QAGSは特に有益な評価指標になると思います。
最後までお読みいただき、ありがとうございました。
Discussion