2文の類似性の判定の実験
はじめに
おはようございます。今回は、タイトルの件についてお話します。
前置き
生成系タスク
古くから自然言語処理では、タスクの大まかな種類として、分類系のタスクと生成系のタスクがあります。分類系タスクは、文書分類や極性判定のような、限られた選択肢から1つを選ぶ系統のタスクです。それに対して生成系タスクは、機械翻訳や文書要約のような、文章を出力する系統のタスクです。
この記事では、生成系タスクを前提とします。
ちなみに、最近のChatGPT以降の流れで「生成AI」という呼称が出てきましたが、「生成」自体は何も最近の特別なものではありません。機械翻訳のような生成系タスクをこなせるモデルやAIは、昔からあったわけですので。
生成系タスクにおけるモデル出力結果の評価
モデル出力結果(モデルによる出力の結果)の評価についての大まかな考え方は、分類系タスクの場合と共通する面があります。
分類系タスクでは、事前にテストデータごとに正解を設定しておいて、それがモデル出力結果とどのくらい一致するかを測ります。このやり方は、例外はありますが生成系タスクにおいても同様です。
しかし細かく見れば、分類系タスクと生成系タスクとでは、モデル出力結果の評価のしかたはだいぶ異なります。
分類系タスクでは、テストデータごとに正解とモデル出力結果の一致/不一致がはっきりと分かります。あとはそれを用いて、全体の正解率、あるいは適合率、再現率、F1スコアなどのスコアを出せばいいだけです。
それに比べると、生成系タスクは事情がだいぶ複雑です。なぜなら、参照文(模範解答となる文章)とモデル出力結果に対して、一致/不一致の明確な判定基準がないからです。これについては今までにも何度か述べたので、ここでは詳しくは省略します。
否定語
ここでいう否定語は、「ない」などの否定を意味する語句です。否定語は英語ではnegationと言い、例えばno、not、never、nothingなどの単語のことです。
否定語の有無は、モデル出力結果の評価をさらに難しくさせる要素です。なぜなら、否定語の存在1つで、データの内容が正反対になるからです。
2文の間の類似性の判定
というように、2文の間の類似性の判定には多くの課題があります。
そこで今回は、ひとまず2文の間の類似性をどのくらいの精度で判定できるのかを実験することにしました。私自身を振り返ってみると、そういう実験をしたことは特になかったので。
判定には、近年登場した手法や考え方を用います。具体的には後述します。
また、より正確には「文章」ですが、便宜上この記事では単に「文」と記すことにします。
文間の類似性の評価方法の種類
今回は、次の3種類を考えます。
- BERTScore
- QGA指標(※臨時で付けた独自の名称)
- SentenceBERT
BERTScore
BERTScoreは、BERTなどのモデルを用いて文間の類似性のスコアを出力するタイプの評価指標です。BERTScoreは、ROUGE(あるいはBLEUなど)の古典的な評価指標に比べると、単語間の意味の近さを加味できる評価指標となっています。
BERTScoreは、モデル利用による評価指標としては結構著名だったと思います。それより前は、Word2Vecなどがありました。ですが、当時のBERTのインパクトは強かったですし、実際にBERTScore自体は既存の評価指標よりも有力であるという実験結果も得られました。
ただし、「単語の重複ぐあいを見る」というROUGEの難点を、BERTScoreは十分に克服できているわけではありません。ROUGEを「狭義の単語の重複ぐあい」と形容するなら、BERTScoreは「広義の単語の重複ぐあい」と形容できるにすぎないです。
そういう事情や、新しい評価指標が出てきた背景から、今ではBERTScoreは良くも悪くもベースライン的な評価指標になっていると思います。
QGA指標
これは、文書要約の評価指標QAGSを応用した評価指標です。
Q・G・Aはそれぞれ、質問・生成・回答を意味する英単語のイニシャルに基づいたものです。この評価指標を、ここでは仮としてQGA指標と呼ぶことにします。
このQGA指標によるスコアは、次の2つの調和平均です。
1つは、1つ目の文を元にして生成した質問に対して、2つ目の文を用いてどの程度正答できるかです。まず、その正解率を出します。
もう1つは、1つ目の文と2つ目の文を入れ替えた場合の正解率です。
SentenceBERTを用いた指標
SentenceBERTは、BERTのようなモデルを基にして、文間の類似性を追加で学習したようなモデルです。このモデルを用いると、新たな2文の間の類似度を算出することができます。
SentenceBERTについては、特にオージス総研さんとsonoisaさんの記事を参考にさせていただいています。
SentenceBERTは単語の重複ぐあいを見るようなものではないので、BERTScoreに比べると画期的と言えます。
なお、SentenceBERT自体はモデルの名称ですが、便宜上、この記事では評価指標を指すものとします。
実験の手順
ここから、実験についてのより具体的な話に入っていきます。
手順1.文データの準備
まず、文データを準備します。
今回は、次の2種類のデータパターンを設定しました。
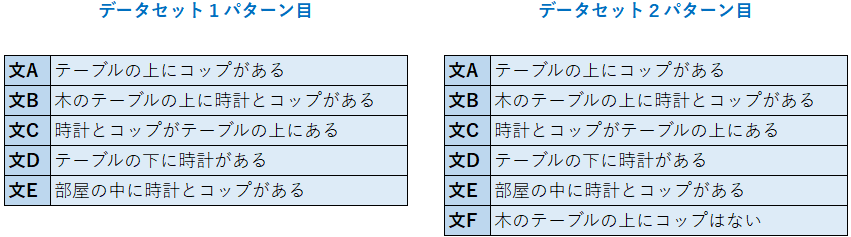
2つ目のデータパターンでは、否定語を付けて、他の文と意味の相反する文を追加しています。
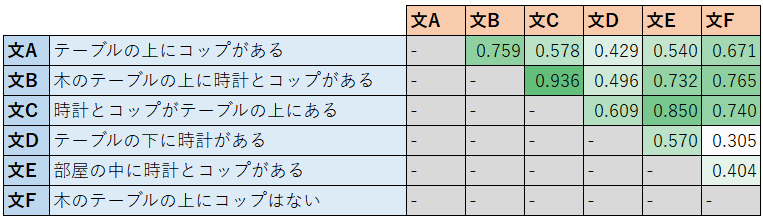
そういう文に対して類似性をうまく判定できるかに興味があるため、そういう文を追加しました。上の表でいうと、文Fのことです。
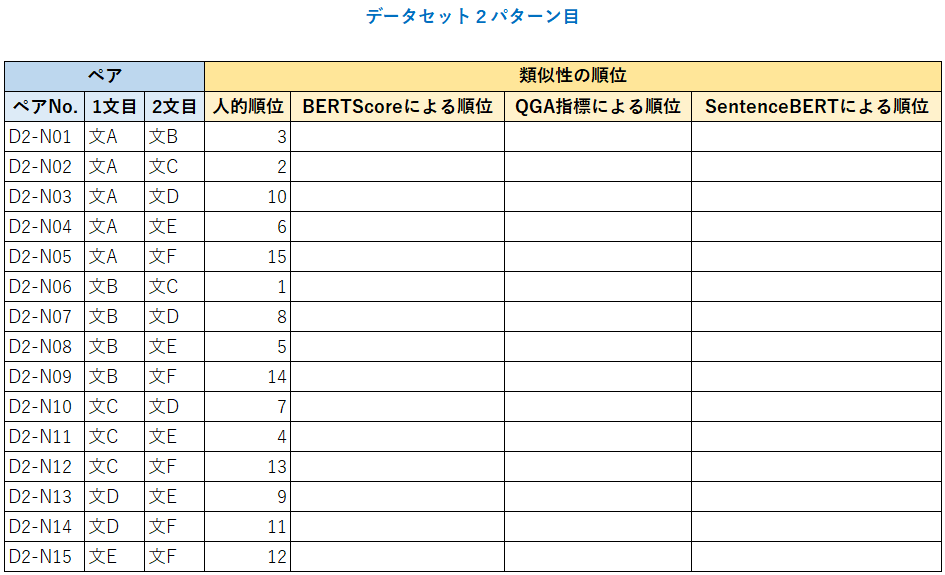
手順2.文のペアの間の類似性の順位付け
次に、データパターンごとに、文のペアの間での類似性の順位付けをします。別の言い方をすると、類似性の順位リストを作ります。
その際、人手による順位づけに加え、各評価指標に基づく順位付けの両方を作成します。
人的順位付けは、次のようにしました。

評価指標に基づく順位付けの方法は、例えばBERTScoreなら、まず次のようにペアごとのBERTScoreを算出します。

その結果を見て、あとはBERTScoreの高い順に順位をつければOKです。ちなみに、BERTScoreの場合だと順位は次のようになります。

また、評価指標ごとのスコアの具体的な算出方法は、次のようにしました。
- BERTScore
Hugging Faceの定番のモデル「'bert-base-multilingual-cased'」を用います。Pythonのコードは、次の記事をご参照ください。
- QGA指標
この指標のスコアの算出も、上の記事のコードに基づいています。記事にある最後のセルにおいては、「要約対象文書」に1つ目の文を、「候補文」に2つ目の文を設定すればOKです。
- SentenceBERT
sonoisaさん作成の、次のSentenceBERTのモデルを用います。ペア内の文ごとにベクトルを出したあとにそれらベクトルの間のコサイン類似度を求め、それをスコアとします。
手順3.2種類の順位リストの間の相関の度合いの測定
手順2までで、2種類の順位リストが得られたので、あとは順位リスト間の相関の度合いを測ります。
今回は、次の2種類の基準で測ることにします。
- スピアマンの順位相関係数
- 正解率
ここでいうスピアマンの順位相関係数は、いわば普通の相関係数(ピアソンの相関係数)の順位版です。正確な定義は少し異なりますが、ここでは省略します。
また、ここでいう正解率は、2つのペア(ペアのペア)ごとに「どちらのペアのほうが類似性が高い?」にどのくらい正答できるかを意味します。
これらの基準については、次の記事の後半あたりでも少し述べています。ご参考までに。
実験の結果
次の表が、実験結果の要約です。
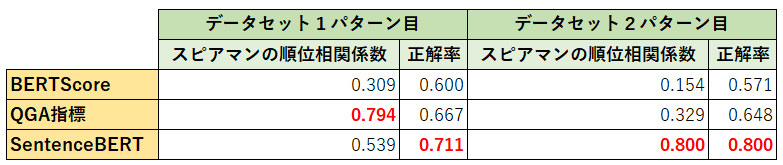
1つ目のデータパターンでは、全体的にQGA指標が良い感じです。SentenceBERTも、正解率が高くて有力です。
それに対して2つ目のデータパターンでは、SentenceBERTが突出してベストな結果になりました。つまり、QGA指標に比べて、SentenceBERTは否定語に対して格段に頑健性があるということです。個人的には、かなりインパクトのある結果です。
2つ目のデータパターンにおいてQGA指標が悪い結果になったのは、次の各散布図を見ればうなずけます。
QGA指標では、明らかな外れ値が3つほど見られます。これら3点はすべて、文Fを含むペアです。文Fを含むペアは5通りなので、5回中3回も、QGA指標は人的順位から大きく外す順位づけをしたことになります。これでは、悪い結果になるのも致し方ないです。
- 1つ目のデータパターンにおける各散布図

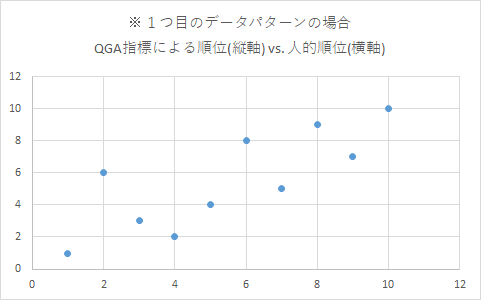
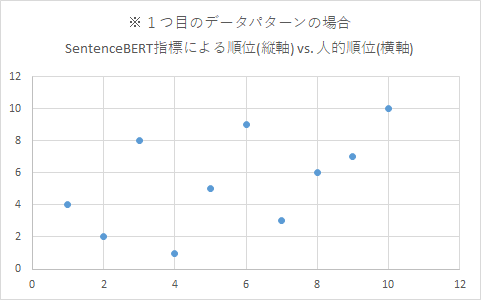
- 2つ目のデータパターンにおける各散布図



ちなみに、評価指標ごと、かつペアごとのスコアは次の通りです。
- BERTScore

- QGA指標
- SentenceBERT

SentenceBERTの場合、否定語を持つ唯一の文Fを含むペアが、他のペアに比べてはっきりと低いスコアを出せていることを確認できます。
また、QGA指標において、調和平均(スコア算出結果)の元となる値は次の通りです。

表の見方としては、例えば1つ目の文が文A、2つ目の文が文Bの場合の値(調和平均の元)が0.672です。
終わりに
SentenceBERTの強さを感じました。
BERTScoreだと、どうしても「単語の重複ぐあいを見る」の域を出ないです。QGA指標も、キーワードの存在がスコアに直結しやすい指標なので、その意味ではBERTScoreと大きく異なるとは言えないです。
それらに比べると、SentenceBERTにはそういう要素は特にありません。その名称が表すように、単語よりも文単位で類似性を測る仕組みになっているからです。
今回も記事をお読みいただき、ありがとうございました。
Discussion