画像とキャプションから質問応答ペアを自動作成する方法、およびVQAへの応用
はじめに
こんばんは。今回は、次の論文の紹介です!
All You May Need for VQA are Image Captions

※本記事にある画像や数式は、当論文より引用しています。
目次
- 導入
- ネックとなっている事柄
- データ作成の方法
- 作成されるデータの質の検証
- 応用に関する考察
導入
画像質問応答とは
AI関係の中でもとりわけ高度なタスクとして、VQA(Visual Question Answering)というものがあります。これは、ある画像とそれに関する質問が与えられた際に、その質問に回答するタスクです。ここでは、このタスクを画像質問応答と呼ぶことにします。
画像質問応答について、以下にいくつか説明します。
事例
事例があると分かりやすいと思うので、1つ紹介します。こちらは昨年頃、東芝社が開発した画像質問応答AIです。
https://www.global.toshiba/jp/technology/corporate/rdc/rd/topics/21/2109-02.html
フリーで使用可能なモデル
sonoisaさんが日本語向けのVL-T5というモデルを開発し、誰でも使えるように公開してくださいました。このモデルは、VQAモデルの一種になると思います。
https://qiita.com/sonoisa/items/618ebcc3db1558c13038
また、Hugging FaceにもVQAモデルが公開されていました。こちらはアカウントがなくてもすぐに画像質問応答を試せるようになっているので、興味があれば試してみてはいかがでしょうか。
https://huggingface.co/dandelin/vilt-b32-finetuned-vqa
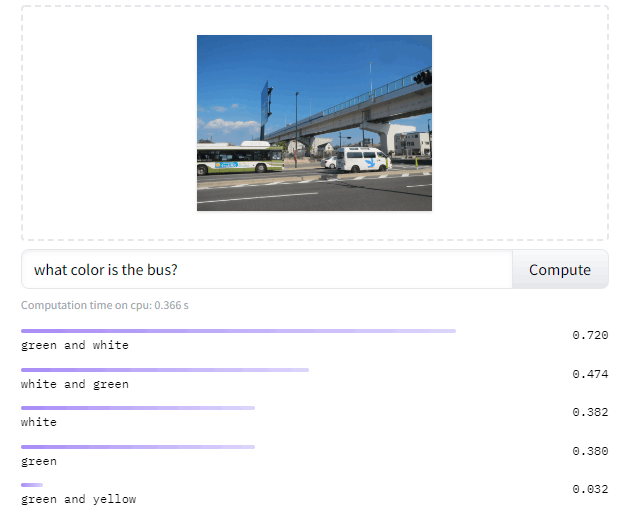
私も試しました。この画像に加え、「バスは何色ですか?」という英語の質問文を入れました。回答としてgreen単色のみを期待していたら、予想外にもgreen and whiteと複数の的確な色を出してくれました。
キャプション
キャプションは、ある画像などについての短い説明文のようなものです。後述の通り、今回提案されている手法には、各画像に対するキャプションの準備が必要となります。
質問生成モデルと質問応答モデル
自然言語処理において、質問生成モデルというものと、質問応答モデルというものがあります。今回の提案手法には、これらのモデルの両方が使われています。
これらのモデルについては以前、次の記事にも書いています。この記事を読んでおいたほうが今回の記事に対する理解も深まりやすいと思うので、よろしければご参照ください。
画像質問応答に関する最新の研究例
調査をしているうちに、こちらのスライドを拝見しました。ありがたく、勉強させていただいています。
https://deeplearning.jp/how-much-can-clip-benefit-vision-and-language-tasks/
※論文『How Much Can CLIP Benefit Vision-and-Language Tasks?』の解説ページです。
ネックとなっている事柄
画像質問応答自体の説明はここまでにして、ネックとなっている事柄に移ります。
現状、データ量に課題があるようです。画像質問応答の場合、データは「画像」、「質問」、「回答」の三つ組(triplet)から成っています。
このようなデータを人力で大量に作成するのは、他のタスク以上にコストがかかりそうです。
そこで当論文は、なるべく人手をかけずに、自動的にデータ量を増やすための手法を提案しています。
データ作成の方法
前提や事前準備
各画像に対して、キャプションが付いていることが前提です。キャプションを用いて、データを作成します。ここでいうデータは三つ組(画像、質問、回答)を指しますが、画像はすでにあるので、実質的には質問と回答のペアの作成が目的です。
また、質問生成モデルと質問応答モデルの準備も必要です。
ちなみに、画像そのものはデータ作成に用いません。
データ作成の全体像
全体像は次の通りです。大きく、4つのステップから成ります。
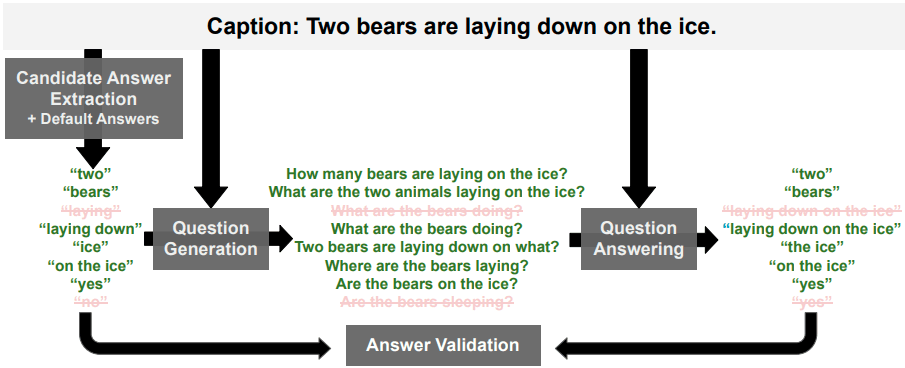
各ステップ
- 質問の回答のネタとなる単語またはフレーズの抽出
上の図でいうと、一番左側の箇所に該当します。
細かく言えば、抽出だけでなく、"yes"や"no"の回答も追加します。これにより、クローズドな質問も作ることができ、質問のバリエーションを増やせます。この箇所にはいろいろと工夫が入っていて興味深いです。この処理には、論文『QACE: Asking Questions to Evaluate an Image Caption』を参考にしているようです。
https://arxiv.org/abs/2108.12560
- 各回答についての質問の作成
別途準備しておいた質問生成モデルを用いて、1.で作成した各回答についての質問を作成します。これは、上の図の中央に相当します。
- 質問への回答
別途準備しておいた質問生成モデルを用いて、2.で作成した各質問に回答します。これは上の図の右側です。
画像のキャプションから質問回答ペアを作成すること、あるいはその作成されたデータは、論文上ではVQ2A(Q2はQの2乗のような書き方)と表記されています。
- 質問応答ペアの選別
上の1.の回答それぞれにつき、3.の回答を比較します。ある一定以上の類似レベルであれば、その回答と質問のペアを採用します。
考察
以上が大まかなデータ作成の流れです。ロジック自体は割と理解しやすいと感じました。確かにこのやり方なら、あまり人手をかけずに、ほとんど自動的にデータをたくさん増やせそうです。
そうなると、今度は作成されるデータの質が気になります。
作成されるデータの質の検証
ここからは、作成されるデータの質について述べていきます。
データの質の検証方法や実験結果を、当初は順序立てて説明しようと考えていました。ですが、あえていきなり実験結果から持ち出すことにします。このほうが、かえって早く理解できそうだと考えたためです。
結果
これが結果の表です。
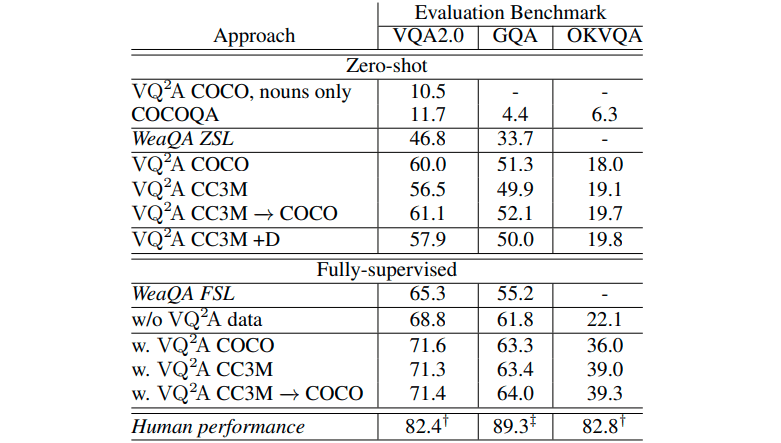
これをどのように見ていけばよいのか、ひとつずつ説明します。
まず、各列ごとにベンチマークがあります。さしあたり、VQA2.0に注目してください。見どころは、大きく2つあると思います。
見どころ1
1つ目は、既存のVQAモデルを用いる場合と、今回自動作成したデータを学習して作ったモデルを用いた場合とでの、「正解率」の比較です(「正解率」については後述の補足をご覧ください)。
前者のモデルを用いる場合は、「WeaQA ZSL」の行に相当します。表にある通り、この場合の「正解率」は46.8%です。
後者のモデル(今回作成したモデル)にはいくつかの種類がありますが、たとえば「VQ2A COCO」に注目してください。これは、COCO-CAPというデータセットから画像質問回答三つ組データを自動作成し、そのデータを学習してモデルを作った場合です。この場合の「正解率」は60.0%となり、前者のモデルに比べてだいぶ高い「正解率」を出せました。
この結果は、当論文による画像質問回答三つ組データの自動作成方法の良さを表していると言えます。「正解率」が高いということは、学習に用いたデータ(つまり今回自動作成したデータ)の質が良いということです。
見どころ2
もう1つの見どころは、作成したモデルをfine-tuningすることの効果です。
表の下のほうに、「w/o VQ2A data」という行があります。これは、対象のベンチマークであるVQA2.0のデータを学習してモデルを作った場合です。それに対して「w. VQ2A COCO」は、VQA2.0のデータを用いて、上の「VQ2A COCO」のパラメータをfine-tuningした場合です。結果、上の「VQ2A COCO」のパラメータをfine-tuningした場合のほうが高い「正解率」を出せました。VQA2.0とGQAではあまり差が出ませんでしたが、OKVQAでは顕著な差が出ています。
この結果も、当論文による画像質問回答三つ組データの自動作成方法の良さを表していると言えると思います。ちょうど、「別のデータを使って事前学習したモデルをfine-tuningすることで、従来のアプローチより高い性能を出せるようになった。」ことに似ています。これは逆に言えば、事前学習に用いたデータ(今回自動作成したデータ)の質の高さを物語っていると思います。当論文による手法なら、このような質の高いデータを作成できるということです。
補足1:「正解率」
上のように、あえて正解率をカギカッコで括っています。これは、当論文にある実験上の正解率なるものの定義が少し特殊であり、さらにベンチマークによって定義が異なるためです。そこで、「正解率」とカギカッコで括り、普通の正解率との区別を付けています。
なお、この「正解率」の定義は割愛します(うまく読み解けなかったので…)。
補足2:作成するVQAモデル
こちらの図は、各実験においてどのようなVQAモデルを作るかの図です。
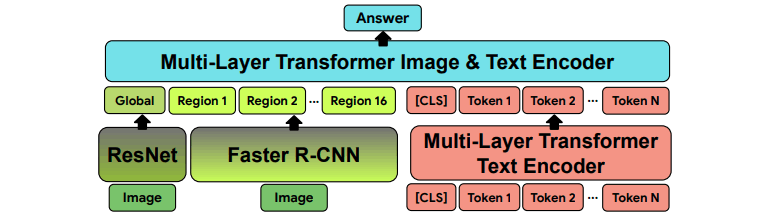
入力はもちろん、画像と質問です。出力は回答です。前述の実験結果は、このようにして作ったモデルを評価した結果ということになります。
こちらもあまり理解できなかったので、詳しい説明は省略します…。
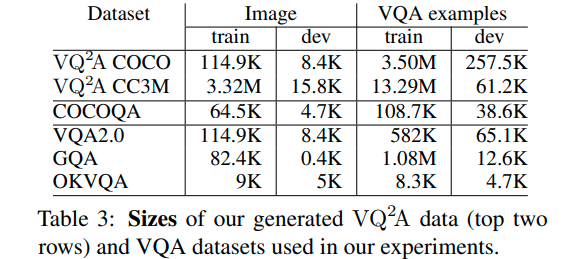
補足3:主要なデータセットやベンチマークの一覧
主に次のものがあります。詳しくは当論文をご確認ください。
応用に関する考察
何と言っても、当論文の提案手法により自動作成されるデータは、抱えている画像質問応答タスクを高精度で解くことを目指す際に使えそうです。それは、前述の実験結果が示していると言えます。
そのより具体的なやり方の例としては、自動作成されたデータを事前学習したモデルに対してパラメータのfine-tuningを施すことです。そしてそのfine-tuning済みのモデルを用いて、画像質問応答タスクを解くことです。
あとは、あまり機会はないかもしれませんが、自前の画像データに対して独自に質問回答ペアを作成したい場合には、当論文の提案手法が有益だと思います。
ちなみに、画像キャプションモデルによりキャプションを生成し、既存のキャプションの代わりに用いた場合に、自動作成されるデータの質はどうなるのか興味深いところです。
もしその場合にデータの質がいくぶん劣るのなら、なるべく的確なキャプションを準備することが大事ということになると思います。逆にデータの質があまり変わらないなら、画像にキャプションが付いていなくてもそれなりに質の良いデータを作れそうです。
終わりに
以上のように、当論文による質の高いVQA向けデータの自動作成の手法を紹介しました。
この記事を最後まで読んでいただき、ありがとうございました。
Discussion