はじめに
完全自動運転の実現を目指すスタートアップ「チューリング」でエンジニアをしています、鈴木勝博です。私が所属しているDrivingSystemチームでは、自動運転向けのシステム開発を担当しています。
Linuxを用いたシステム開発を行っていると、カーネルの挙動、周辺デバイスとの組み合わせ等によって、思いがけない問題に遭遇することが少なくありません。この記事では、実際にシステム開発中に遭遇した「再現が難しく、原因の切り分けに時間を要した問題」について深堀りしてご紹介します。
概要編はこちらのテックブログにてご紹介しています。
本テックブログでは「kswapdが動作するとCPUの動作が止まる理由」の深堀を行います。具体的には下記を説明します。
- Linuxのメモリシステムの仕組み
- 問題発生した瞬間に何が起きたか?
Linuxのややマニアックな話となりますが、Linuxや自動運転ソフトウェアの開発に携わっている方の参考になれば幸いです。
チューリングの運転データ収集システムとは?
チューリングでは、独自に開発したデータ収集車を使って、日々さまざまなデータを集めています。動画やLidarの点群データはもちろん、CPUの状態などシステムに関する情報も記録しています。
NVIDIA Jetson AGX Orinを搭載した車載デバイス上でLinuxやDockerを動作させ、Dockerコンテナ内に運転データ収集システムを構築しています。システム内では複数のプロセスがPublisher/Subscriber方式の通信で連携しています。

運転データ収集システムブロック図
問題発生時のシステムの挙動
問題認識までの経緯や調査方法は以前のテックブログをご覧頂くとして、この記事では問題発生時のシステムの挙動のみを簡単に説明します。
問題発生時は運転データ収集システムがPublisher/Subscriberモデルでやりとりしているほぼ全てのメッセージが最大で1秒ほど途絶することがわかりました。

メッセージが途切れる例(横軸は秒)、グラフの断絶箇所で1秒程度途切れている
画像はカメラ映像に付与されたタイムスタンプ、カメラを保存するためのエンコーダーが付与したタイムスタンプなどを横軸に記録開始からの秒数、縦軸にメッセージが持つ値(詳細は気にしなくてOK)を取ってプロットしたものです。
カメラもエンコーダーも特定の周期、例えば30Hzなどで動作しますので、システムが正常に動作していればグラフは等間隔で右肩上がりの点が連続でプロットされます。しかし10秒地点のところ(左側1/3くらいのところ)を見ると、メッセージの送受信が途絶してグラフが大きく欠けています。
現象の調査
trace-cmd(ftraceのフロントエンド)を使ってカーネルトレースイベントを取得し、KernelSharkで観察すると下記のことがわかりました。
- kswapdが長時間(約1秒ほど)動作する。
- kswapdが長時間動作中に他CPUのプロセスの動作を妨害する。
メカニズムは後述しますが、kswapd動作中に運転データ収集システムのメッセージ送受信をするプロセスが動作できなくなりメッセージが途絶します。

現象発生時のカーネルトレースイベントをKernelSharkで見た様子
画像は現象発生時に取得したカーネルトレースイベントです。画像下部のイベントリストにて緑色にハイライトしているイベントがあります。これはページスキャン処理のイベント(CPU5で記録されたvmscan/mm_vmscan_lru_isolateイベント)で、メッセージ途絶を引き起こした原因です。
Infoの部分を見ていただくと、
- nr_requested=32
- 回収したページ数です。32ページ = 128KB回収できたことを表します。
- ページについては後ほど説明します。
- nr_scan=9911718
- 回収できるかどうか調査したページ数です。1000万ページ近くスキャンしたことを表します。
- nr_skipped=9911686
- 調査したものの回収対象ではなかったページ数です。スキャンしたほぼ全てのページが回収対象ではなかったことを表します。
- lru=inactive_file
- スキャンしたLRU list(LRUはLeast Recently Usedの略)です。Inactive File LRU listのページをスキャンしたことを表します。
- LRU listについては後ほど説明します。
いずれも単位はページです。1ページ = 4KBなので、128KB(32ページ)回収するために37GB(1000万ページ)スキャンしたことを意味します。
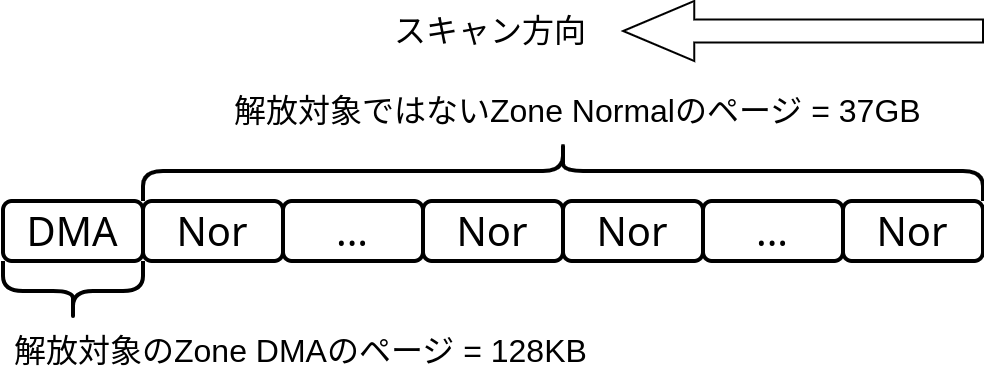
128KB回収するために37GBスキャンする様子
上のカラフルな図を見ていただくと、緑の縦線が2本あります。左側の緑の縦線が原因イベントの開始時点(Marker B、5144.543秒地点)、右側の緑の縦線(Marker A、5145.403秒地点)が原因イベントの終了時点で、2地点間の時間差(A-B Delta)は0.86秒ほどです。
タスクスイッチを含むイベントが起きている場所には縦長の棒が付くはずですが、CPU 5を見ると長期間に渡ってオレンジ色の低い帯があるのみで、何もイベントが発生していません。kswapdのページスキャン処理がCPU 5を専有しているためです。

CPU0上のプロセス動作が妨害されている様子
他のCPU、例えばCPU 0を見ると、ページスキャンイベント開始直後はイベント発生していますが、しばらくすると青色の低い帯のみになりイベントが発生しなくなります。ページスキャンイベントの終了直後からイベント発生が再開しています。ここからページスキャン処理によって、プロセスの動作が妨害されている様子が伺えます。
Linuxメモリ管理の基礎知識
上記の動きは何がマズイか?を説明する前に、Linuxのメモリ管理の用語、概念等の基礎部分を説明します。ご存知の方は次章までスキップしてください。
ノードとゾーン
Linuxはメモリをノード(Node)とゾーン(Zone)に分けて管理します。

ノードとゾーンの構造
ノードはNUMA(Non-Uniform Memory Access)で効率良くメモリアクセスするために存在します。NUMAはメモリによってアクセス速度が異なり、下記の性質を持ちます。
- 近くて速いメモリから割り当てたほうが良い
- 遠くて遅いメモリはメモリが足りないときだけ割り当てたほうが良い
OrinはNUMAではない(あえて区別するためUMAと呼ぶこともある)のでノードは1つだけ存在します。
ゾーンはノード内のメモリを用途ごとに分けるために存在します。よく見かけるのはZone DMAとZone Normalです。
- Zone DMA: DMA転送用のメモリを確保する領域
- アドレスの若い方(0x0000_0000に近いアドレス)に配置されます。
- 周辺HWのアドレスバスに制限があり、0に近い一部アドレスしかアクセスできないことがあります。例えば先頭4GB(いわゆる32ビットに制限されたアドレス)まで、などです。そのため0に近い物理アドレスのメモリを割当てる必要があります。
- Zone Normal: その他の領域
- 通常のプロセスやカーネルがメモリを要求したときに使われる領域です。
Orinの場合は
- Node 0
- Zone DMA (2GB)
- Zone Normal (60GB)
のみ存在します。Zone DMA32は0バイトです。
[ 0.000000] Zone ranges:
[ 0.000000] DMA [mem 0x0000000080000000-0x00000000ffffffff]
[ 0.000000] DMA32 empty
[ 0.000000] Normal [mem 0x0000000100000000-0x0000001033ffffff]
ゾーンのアドレスとサイズはLinux起動ログのZone ranges:に表示されています。上記はOrinの例で、ゾーンDMAは0x8000_0000〜0xffff_ffff = 2GB、Normalは0x1_0000_0000〜0x10_33ff_ffff = 60.8GBであることがわかります。
ゾーンとページ
ゾーンに割り当てられたメモリ領域はページと呼ばれる単位で区切って管理されます。Orinの場合は1ページ = 4KBです。

ゾーンとページの構造
ページをバラバラに割当て解放し続けると外部フラグメンテーションが発生しやすいので、LinuxではBuddy Allocatorというアルゴリズムを使って外部フラグメンテーションの発生をなるべく抑えます。Buddy Allocatorの仕組みはここでは詳しく書きませんが、
- 隣り合う2のべき乗のページ数(orderと呼ばれる)を1つの領域としてまとめて管理する
- order 0 = 2 ^ 0ページ = 1ページ
- order 1 = 2 ^ 1ページ = 2ページ
- order 2 = 2 ^ 2ページ = 4ページ
- …
- 各領域の空きページはリストに繋がっている
- メモリ割当時は要求されたサイズに近い領域を使う
- メモリ割当時に要求されたサイズに近い領域がなければ、1段上のサイズの領域を2つに割り、1つは割当に使ってもう1つはリストに繋ぐ
- メモリ解放時に2つの連続した空き領域ができたら、2つの領域を1段上のサイズに融合してリストに繋ぐ
こんな感じになっています。正確にはゾーンはorderごとのフリーエリアに分かれていて、フリーエリアに用途別(migrationと呼ばれる)のフリーリスト(コードだとfree_areaと書かれていることが多い)があり、フリーリストにページが並んでいます。

ゾーンとフリーリスト、migrationの構造
Orinで使用しているLinux 5.15では1ページ領域〜4096ページ連続領域のリストが存在します。
$ cat /proc/buddyinfo
Node 0, zone DMA 0 0 0 0 0 1 1 1 1 1 1 1 122
Node 0, zone Normal 121252 54945 53787 40411 15916 6057 2136 721 325 274 132 66 2746
各ノード、各ゾーンに領域がどれだけ空いているかは/proc/buddyinfoで見ることができます。
LRU list
Linuxは空きメモリが不足してきたときに「使っているけど回収して良いページを回収する」仕組み(reclaimと呼ばれます)があります。使用中のページはLRU list(LRUはLeast Recently Usedの略)に並べて管理しています。LRU listはコード上ではlruvecと書かれていますが、以降の説明ではLRU listで統一します。

LRU list(= lruvec)の構造
LRU listは使用中のページが並んでいるリストで、Doubly linked listになっていて順方向にも逆方向にも辿れます。追加するときは先頭から、辿るときは末尾から参照します。用途ごとに分かれていて、代表的なものは下記の通りです。
- Inactive Anon: 使われる頻度の低い匿名ページ(プロセスがmallocなどで確保したメモリと思ってもらえればOK)
- Active Anon: 使われる頻度の高い匿名ページ
- Inactive File: 使われる頻度の低いページキャッシュ(ファイル内容のキャッシュ)
- Active File: 使われる頻度の高いページキャッシュ
ページ回収の仕組み
Linuxのページ回収はざっくり分けて2つの経路があります。
- Direct reclaim
- メモリを要求したプロセスが自らページを回収します。
- kswapd
- ページ回収を専門に行うカーネルスレッドです。
- 各ゾーンには空き領域の閾値(watermark)が設定されていて、閾値を下回るとkswapdがページ回収を始めます。
ここでページ回収の仕組みを全て説明することはできないので、他のプロセスを妨害してしまう仕組みに関係するところだけ取り上げます。
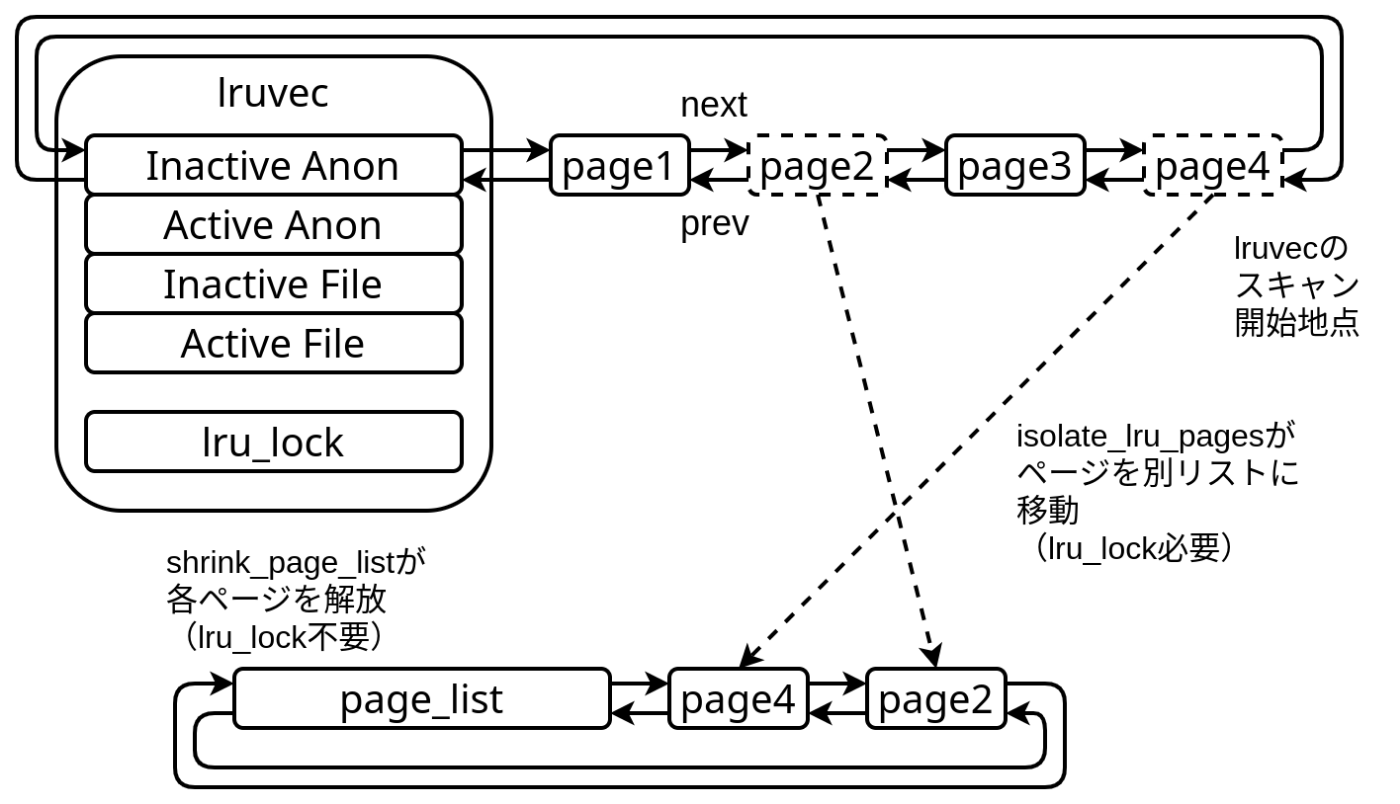
ページスキャン処理
ページ回収するプロセスまたはkswapdはページ回収を行うとき、LRU listを末尾からページスキャン処理(isolate_lru_pages)で回収して良いページかそうでないかを調べ、回収して良いページであればLRU listから別のリストにページをつなぎ直します。このとき他のページ回収処理と同時に実行すると同じページを2回解放したり、LRU listが壊れたりするので排他用スピンロック(lru_lock)を取得する必要があります。
ページリストは後のページ解放処理(shrink_page_list)が参照し、リストに繋いだページを解放します。二度手間に見えますが、lru_lockを取得する時間をなるべく短くするためにページスキャン(lru_lock必要)とページ解放(lru_lock不要)が分けられています。
システムが止まる要因
以上でLinuxメモリ管理の基礎知識の説明は終わりです。話を戻し、問題が起きた瞬間について説明します。
LRU listの長時間スキャン
問題が起きた瞬間は、kswapdのページスキャン処理(vmscan/mm_vmscan_lru_isolateイベント)に非常に時間がかかっていました。調査した結果、特定の条件下で発生するようです。
- Zone Normal、Zone DMAが空いていない
- 大量のZone Normalのページと少量のZone DMAのページが同一のLRU listに繋がれている
- Zone DMAのページ回収(reclaim)が発生する
- kswapdがZone DMAのページ回収をしようとして、Inactive File LRUリストをスキャンすると問題が発生します。
これらの条件が揃うと下記のようにInactive File LRU listに大量のページが並びます。

ページスキャン処理が長時間に及ぶ例
Inactive File LRU listにはZoneの区別がないので、Zone NormalのページとZone DMAのページが混在します。
kswapdが回収したいのはInactive File LRU listに並んでいるZone DMAのページですが、Zone DMAのページがスキャン開始位置から非常に遠い位置にある場合、回収対象ではないZone Normalを大量にスキャンしなければなりません。結果ページスキャン処理が長引いて、ページスキャン処理中に保持するロック(lru_lock)を長時間保持します。
我々の運転データ収集システムの性質がこれらの条件を満たしていました。
- Zone Normal、Zone DMAが空いていない
- ログ記録によりファイルに大量の書き込み(カメラ動画、LiDAR点群ファイル)を行うため、ページキャッシュでメモリが全て消費されます。
- 大量のZone Normalのページと少量のZone DMAのページが同一のLRU listに繋がれている
- ログは一度書いたら読まないので、Inactive File LRU listにほぼ全てのページキャッシュが繋がれます。
- Zone DMAのreclaimが発生する
- ログ記録し続けるため、ページキャッシュ用のメモリ確保要求が常に発生し、ページ回収処理要求も常に発生します。
他プロセス動作を妨害
kswapdのページスキャン処理が長引いてlru_lockを長時間保持すると、運転データ収集システムの他プロセスの動作を阻害します。
他プロセスのメモリ確保/解放とkswapdのページ回収は基本的に独立であり、並列に動作しますが、一部のメモリ確保/解放処理で同じlru_lockを取ります。例えば下記のような処理です。
- Direct reclaim処理
- ページフォルト処理
- munmap
これらの処理はkswapdのページスキャン処理が終わってlru_lockが解放されるまで待ちます。カーネル内で止まってしまい、タスクスイッチもできずただ待ち続けます。
メモリ確保/解放を行わない一部のプロセスは動きますが、別のプロセスにタスクスイッチされ、運悪くスイッチ後のプロセスがメモリ確保/解放処理を行うと、lru_lock解放待ちになってCPUを専有します。この現象は全てのCPUで発生し得えるため、最悪全てのCPUがlru_lock解放待ちのプロセスで専有されます。
全てのCPUがlru_lock解放待ちのプロセスに専有されると、どのCPUもタスクスイッチできなくなり、メモリ確保/解放を行わないプロセスがいたとしても実行の機会は訪れません。
こうして全プロセスが動けなくなって、メッセージ送受信が途絶します。
残された課題と調査
運転データ収集システムのプロセス間通信が途切れてしまう瞬間に、Linuxカーネル内で何が起きるのか?が判明しました。
残る課題は問題発生より「前」のメカニズム、すなわちどうしてこの状態に陥るのか?特になぜLRU listのスキャン開始位置からはるか遠くにしかZone DMAのページがないのか?について明確に説明できていません。この部分も調査を進めており、さらにマニアックな話になりそうですが、別途テックブログで紹介予定です。
まとめ
以上、今回私たちが調査した、運転データ収集システムの全プロセスが1秒止まる不具合のメカニズムです。概要編の対策で述べたとおり、設定が悪かっただけなのですが、その結論に至るまでLinuxカーネルのコードや挙動を詳細に調べる必要がありました。今回の問題は思った以上の深さに調査の苦労はあったものの仕組みがわかった瞬間は爽快でした。
私たちチューリングでは、一緒に完全自動運転の実現を目指す仲間を募集しています。今回ご紹介した自動運転システムのソフトウェア開発に加え、自動運転AIの開発、MLOps、組み込み、Web開発など、幅広いポジションで募集しています。
興味を持っていただいた方は、ぜひDMなどでお気軽にご連絡ください。カジュアル面談やオフィス見学も歓迎です。「おいしいご飯を食べたい」という理由でも大丈夫です!ライトな交流から始めてみませんか?
最後までお読みいただきありがとうございました。それでは、次回の記事もお楽しみに!

Discussion
はじめまして。最初の記事から気になっていたのですが、
SCHED_DEADLINE等のスケジューラの切り替えには言及がない点が意外でした。これは今後出てくる内容でしょうか? 私自身 (博士課程の学生です) は専門ではないのですが、周囲の学生がその研究を行っていてぼんやりとだけ知っていたため、気になりました。また6.12からのPREEMPT_RTも大いに関係しそうですが、同様に記事でもコメントでも言及がないようです。ただこれは「本番環境に投入するには新し過ぎた」という判断も大いにあり得そう、と推測しています。
『Zone Normalを大量にスキャンしてるから時間がかかる』のならZone DMAを消したところで一番端のNorをスキャンするのに時間がかかるのでは?
色々忙しくて投稿2回目を読むのに間が空いてしまいました。面白いですね。今のkswapdはこうなっているんですね。
kswapdはカーネルスレッド化はされていないのでしょうか。全メモリエリアをスキャンするとスレッド化してもあまり意味はないかな。
例えばNUMA nodeごとにスキャンと回収するようにして、他のCPUのアクセスバスをロックしないようにすればkswapdと違うCPUで動いているプロセスはメモリアクセス出来るし、1回のスキャンも短くなります。もちろん、フラグメンテーションは起きやすくなりますが・・・
と言ったことを、LKMLで投稿して相談したり、そこで方向性がある程度見えてくればKernel Summit 分科会のMM/FS/Storage Summitで発表してみるのもいいかもしれません。
自分が英語が出来ればぜひともやってみたいですが・・・(笑)
あ、あとLinux Kernelのメモリ管理システムは富士通の亀澤さんが世界的第一人者だったりします。