はじめに
完全自動運転の実現を目指すスタートアップ「チューリング」でエンジニアをしています、坂本です。私が所属しているDrivingSystemチームでは、組み込みLinuxをベースに、自動運転システムと、自動運転モデル学習用データ収集システムを開発しています。
組み込みLinuxの開発を行っていると、カーネルの挙動、周辺デバイスとの組み合わせ等によって、思いがけない不具合に遭遇することが少なくありません。この記事では、実際にシステム開発中に遭遇した再現が難しく、原因の切り分けに時間を要した不具合について紹介していきます。同じように組込みLinuxや自動運転ソフトウェアの開発に携わっている方の参考になれば幸いです。
なお、本記事は「全プロセスが一秒止まる不具合解析」の概要編です。調査で得られた技術的な詳細やカーネル内部のメカニズムについては、別途記事で掘り下げて紹介する予定です。
チューリングの自動運転システムとは?
まず我々が遭遇した不具合の詳細について説明する前に、チューリングの自動運転システムについて軽く説明させてください。チューリングの自動運転システムは、カメラ主体のエンドツーエンド(E2E)システムであり、カメラ映像を入力として、自動運転AIが認知判断を行い、車両を制御します。
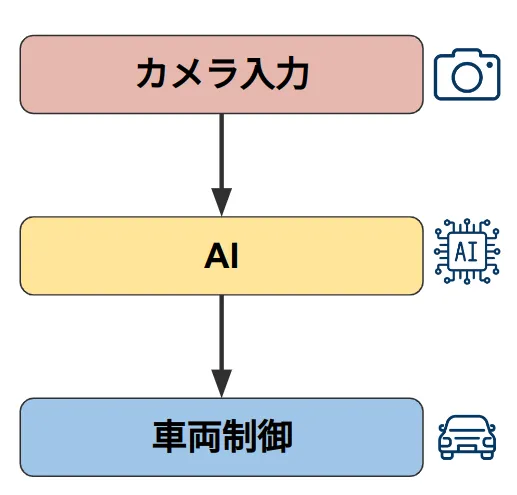
チューリングの自動運転システムのコアコンポーネント概念図
システムはLinux上で動作し、C++およびPythonで開発された複数のプロセスで構成されています。各プロセスはモジュール化されており、それぞれが特定の役割を担っています。たとえば、以下のようなプロセスがあります。
- カメラ制御:カメラの設定や映像の取得を担当
- モデル推論:AIモデルによる認知・判断を実行
- 車両制御:制御信号を生成し、車両に指示を送信
これらのプロセスは、Publisher/Subscriber方式のプロセス間通信(IPC)を通じて、データや指示をリアルタイムでやり取りします。この仕組みは、マルチコア環境を活用することで、各プロセスを並列に実行できるよう設計されています。また、システム全体を粗結合な構造にすることで、各コンポーネントが独立して動作しつつも緊密に連携することが可能です。
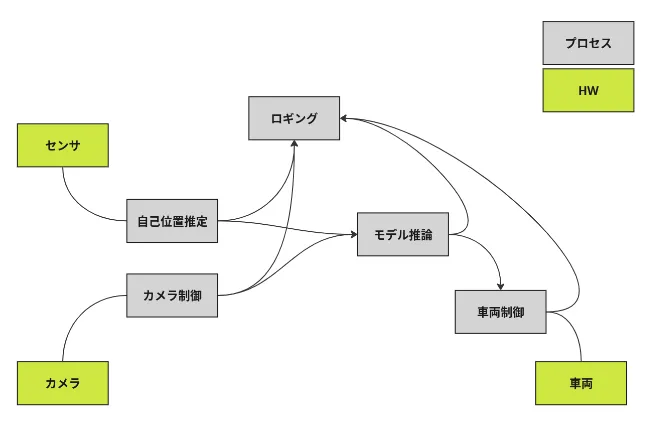
複数プロセスがプロセス間通信により協調している様子
チューリングのデータ収集システムとは?
チューリングでは、独自に開発したデータ収集車を使って、日々さまざまなデータを集めています。動画やLidarの点群データはもちろん、CPUの状態などシステムに関する情報も記録しています。データ収集システムもLinux上で動作しており、複数のプロセスがPublisher/Subscriber方式の通信で連携しています。

データ収集車
こうして得られたデータは、自動運転モデルの学習に活用されます。
不具合の発見と調査
不具合の発見と初期解析
自動運転モデルの学習には、安定したデータ品質が重要です。そのため、収集データに対して様々なチェックを行っています。そうしたチェックの中で、ごくまれに動画のフレームが欠けているケースを発見しました。
この不具合はごくまれにしか発生していなかったため、まずは過去のデータを遡って、この現象が「どのくらいの頻度で」、「いつから」起きているのかを確認することにしました。そこで協力を依頼したのがMLOps チームです。MLOpsチームは、これまでに収集した膨大なデータを一元的に管理し、学習や解析に必要な形で提供する役割を担っています。また、データ収集時のソフトウェアバージョンなどのメタ情報も管理しているため、もしソフトウェア由来の不具合であれば「どのバージョンから混入したのか」を特定することが可能です。
調査の結果、この不具合はデータ収集システムでおよそ20時間分のデータを収集するごとに1回の頻度で発生し、システムの稼働初期から存在していたことが明らかになりました。
新たなる事実の発見
動画のフレームが欠けている原因としてはいくつかの可能性が考えられます。たとえば、SSDの劣化による書き込み遅延や、CPU負荷の瞬間的な上昇といったものです。そこで、これまでに収集したデータをさまざまな観点から解析しました。しかし、決定的な手がかりは得られませんでした。ログに異常なメッセージが残っていないか、データに不自然な点がないかといった観点でも調査を続けましたが、やはり原因の特定には至りませんでした。
次のステップとして取り組んだのは、不具合が発生しているデータに共通点がないかを探す作業でした。例えば「特定の車両でのみ起きていないか」「特定のSSDで再現していないか」「計算機の起動から一定時間が経過したときに発生していないか」といった切り口で調査しました。しかし、どの観点から見ても明確な共通条件を見つけることはできませんでした。
ただ、この調査の過程で一つ新しいことが分かりました。動画のフレームだけでなく、約1秒間プロセス間通信自体が途絶している事実です。下図は、横軸に時間を、縦軸に各データごとの値をプロットしたものです。線が途切れているところがあり、ここでプロセス間通信が途絶していることが分かります。
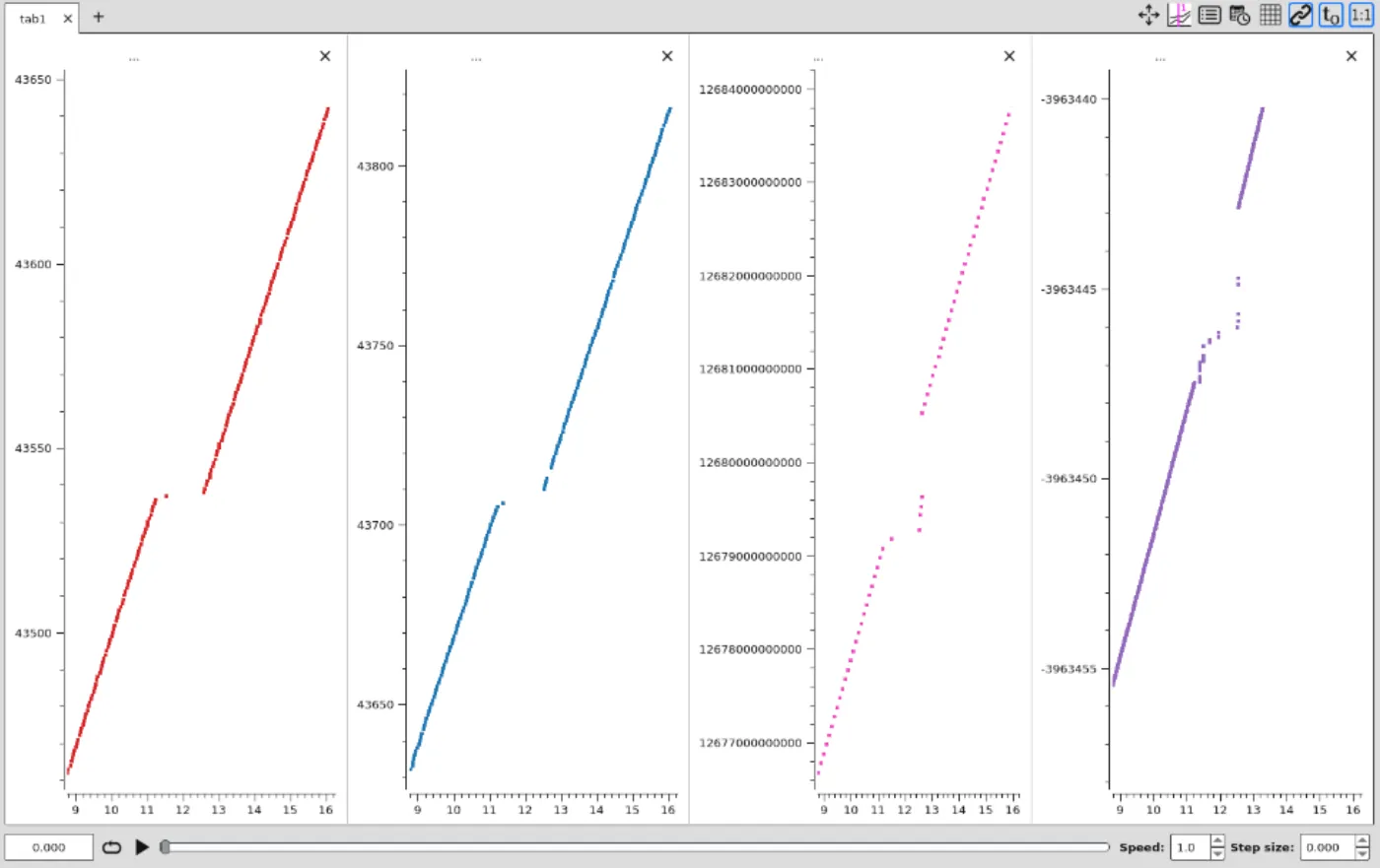
プロセス間通信が途絶した瞬間を示すグラフ。切れ目が通信の欠落を表している。
この時点で、「単なるストレージやCPUの問題ではなく、カーネル側の問題など、もっと根の深い要因が潜んでいるのではないか」と感じました。再現性が低く、発生条件も見当がつかないため、これは長期戦になるだろうという予感がありました。
再現
前述のとおり、今回の現象は単純な不具合ではなく、カーネル側の問題など根の深い要因によって引き起こされている可能性が高いと感じていました。
もしカーネル側の問題であれば、現象が起きた瞬間のカーネルやプロセスの動きを詳細に観察する必要があります。そのためにはデバッグ用にカーネルを改変してログを仕込む必要がありますが、運用中のシステムでそれを行うのはリスクが大きく現実的ではありません。そこで、机上環境で不具合を再現する必要がありました。
とはいえデータ収集運用車両での不具合発生頻度はおよそ20時間に1回、しかも条件も不明なため、机上環境で再現できるかどうかは分かりませんでした。それでも机上の計算機をできるだけ車両と同じ構成に揃え、ひたすらデータ収集を続けたところ、8時間ほど稼働させた時点で、確定ではないものの不具合を再現できることが確認できました。

机上再現機
条件の絞り込み
机上機で不具合を再現できたので、次は原因を絞り込むために条件を一つずつ変えながら検証を進めました。ソフト面ではデーモンやサービスを停止し、ハード面ではGNSSの測定器やLidarなどを順に外して再現実験を行います。
変数が非常に多いうえに、不具合の再現率も100%ではないため作業は困難を極めました。試行回数は 50回を超えましたが、試行を重ねた結果、不具合の再現には必ずLidarがethernetで接続されている状態でシステムを数時間連続稼働させることが必要だと分かりました。

不具合再現実験記録
原因の解明
ここからは少し技術的な内容に入ります。細かい仕組みやコードの話までは踏み込まず、流れだけ理解できるようにまとめています。なお、技術的な詳細については別記事で改めて解説する予定です。
原因調査
条件の絞り込みによって、Lidarが接続されている状態でシステムを数時間連続稼働させると不具合が発生するということまでは分かりました。ただし、その時にシステム内部で何が起きているのかは依然として不明でした。不具合が発生すると複数のプロセスが一斉に止まるため、より根本的な要因――とくにカーネル側で何か異常が起きているのではないかと考え、カーネルレベルの調査に踏み込みました。
調査方法は2つです。ひとつはtrace-cmdでカーネルイベントを収集し、それをkernelSharkで解析する方法。もうひとつはカーネルに追加ログを仕込み、ビルドして焼き直し、挙動を直接観察する方法です。
kernelShark で不具合発生時のカーネルトレースを確認したところ、CPU が止まる直前には毎回必ずkswapdというプロセスが動作していることが分かりました。
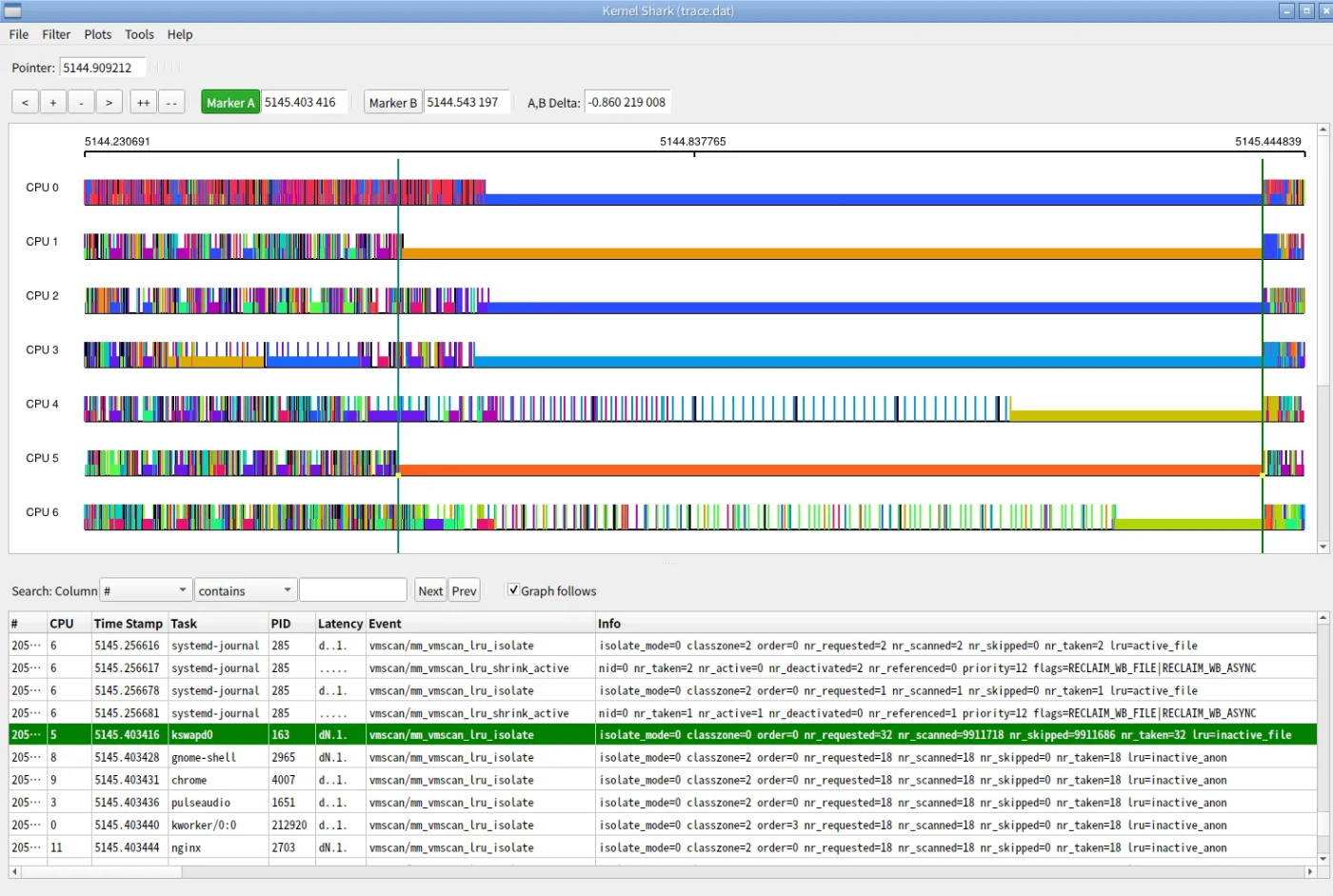
kernelsharkで可視化した結果。kswapdの動作直後からCPUが停止状態に入っている様子が確認できる。
kswapdが動作するとCPUの動作が止まる理由
では、なぜkswapdが動作するとCPU全体の処理が止まってしまうのでしょうか。
カーネルにログを仕込んで調査した結果、原因はkswapdが動作時に取得するロックにありました。kswapdはメモリの回収処理を行うときにロックを握るのですが、処理に時間がかかるとその間ほかのプロセスも同じロックを待たされてしまい、結果としてシステム全体の動作を阻害してしまうのです。
ではなぜkswapdの処理がそこまで長引くのでしょうか。その背景には、使用している計算機のメモリ構成があります。チューリングで使っている計算機のメモリは60GBのZone Normalと2GBの Zone DMAで構成されています。通常はZone Normalを優先的に利用しますが、Zone Normalが枯渇してくるとZone DMAからもメモリが割り当てられます。
kswapdは「回収リスト」をスキャンしながら不要ページを回収します。このとき、Zone DMAのページを回収しようとしてもリストの並びによってはZone DMAのページがほとんど含まれておらず、大量のZone Normalページを延々とスキャンする羽目になることがあります。結果としてkswapdのロック保持時間が極端に伸び、他のプロセスが動けなくなる――これが「全プロセスが一秒止まる」根本原因でした。

問題発生時の回収リスト。Zone DMAに到達する前にZone Normalを大量にスキャンしている。
このあたりの詳細については別でテックブログを出す予定なので、ここでは、「kswapdがZone DMAを回収する際に時間がかかってしまってしまうことが原因で、各プロセスの動作が止まってしまうことがあるんだなー」ぐらいで理解していただければと思います。
対策と今後の課題
対策
前述のとおり、今回の不具合はkswapdがZone DMAを回収しようとした際、リストの並びによっては大量のZone Normalページを延々とスキャンしてしまい、その結果長時間処理にハマってしまうことが原因でした。
そこで対策として、ユーザープロセスからの要求では、Zone DMA指定で要求されない限りZone DMAを使わないような設定に変更しました。具体的には、システムのメモリ割り当てを以下のように調整しました。
echo "30 30 30 0" > /proc/sys/vm/lowmem_reserve_ratio
Zone DMAは本来デバイスドライバ用に確保されている領域であること、我々の環境ではZone DMAに対してZone Normalが十分大きいことの2点から、この方法で問題なく運用できると判断しました。
この修正によって、Zone Normal が枯渇しても Zone DMA を使わなくなり、kswapd が長時間スキャンに陥ることもなくなりました。結果として、不具合は解消しました。
残された課題
今回の設定変更により、現象は再現しなくなりました。ただし、これはあくまで発生していた症状に対する対症療法でしかありません。なぜLidarが関わると問題が起きるのか、具体的にどのようなメカニズムで発生していたのかは、この時点ではまだ明確ではありませんでした。
そこで追加の調査を進めた結果、カーネルレベルでの仕組みの全体像もある程度つかめてきています。詳細なメカニズムや調査の過程については、別途テックブログで掘り下げて紹介する予定です。
まとめ
以上が今回私たちが調査し、修正に至った不具合の概要です。全プロセスが一秒止まる原因は、システムによるメモリ管理の方法にありました。
カーネルのコードを読んだり自分でビルドしたのは初めてでしたが、同僚に助けられながら取り組み、多くを学ぶことができました。技術者として大きな糧になったと感じています。
私たちチューリングでは、一緒に完全自動運転の実現を目指す仲間を募集しています!今回ご紹介した自動運転システムのソフトウェア開発に加え、自動運転AIの開発、MLOps、組み込み、Web開発など、幅広いポジションで募集しています。
興味を持っていただいた方は、ぜひDMなどでお気軽にご連絡ください。カジュアル面談やオフィス見学も歓迎です。また、「おいしいご飯を食べたい」という理由でも大丈夫です!ライトな交流から始めてみませんか?
最後までお読みいただきありがとうございました。それでは、次回の記事もお楽しみに!

Discussion
保護を最大するなら値は最小値の1だとマニュアルに書かれていますが、なぜ30にされているのでしょうか?
Normal zoneが充分に大きい場合、
Normal zone page size * (1 / 30) > MDA32 zone page sizeになるので、30も1も同義になるから30にしているのでしょうか。
swapイン・アウトしてる最中に対象のプロセスだけ止められれば良いのでしょうけど、異なるプロセスの仮想メモリ空間上に書かれた同じ内容のメモリは省メモリ化の為に物理メモリ上では共有されており、異なる内容が書かれて初めて別の物理メモリが割り当てられます。swapもそれに準じていたり、メモリが潤沢にあっても参照頻度の低いメモリはswapアウトされたり、断片化した物理メモリを仮想メモリ空間上では連続している様にみせたりと、メモリ管理は複雑なのでkswapdがスワップイン・アウト中はユーザプロセスが全停止しているのかもですね。長時間稼働させ尚且つ集中的なswapイン・アウトでプロセスが一時停止するのが問題になるのであればswappinessを10や5にする、絶対にメモリが不足しないのであれば0やswapoffしてもいいかもしれません。
この辺はカーネルの問題というより、走らせる側のアプリケーションに応じたカーネルのチューニングの話なので不具合と言うと、多分リーナスに怒られます(笑)
swapではありませんが、メモリ管理を自前で行う必要のない高級言語のガベージコレクションも地味に重い処理なので、ミリ秒単位で止まると困るゲーム開発でもたまに話題になってますね。
おそらくですが、lowmem_reserve_ratioの値はドライバなどの行うメモリ割当の一部の割当先なども変更したと思います、そしてswapプロセスが動くということはメモリ割当できない状況かつタイミングを考えると新たなメモリ割当要求(kmalloc,mallocなど)が動いた結果だと考えられます。問題のLidarを接続しているときに発生するということであれば、データの読み出し頻度が遅かったり読み出し切れていないなどの問題でドライバなどの用意しているバッファにデータがたまり続けている(バッファが肥大化し続けている)のではないでしょうか。
swapが走るということはどこかでHeap領域などのメモリが確保され続けているのだと思うので現状は2GBで2時間だった時限爆弾が60GBで100時間以上になっただけではないでしょうか?
どこで問題が起きているかは使用メモリが増え続けているプロセスがないかを調べるのがてっとり速いと思うのでそれをおすすめします。
組み込みLinux といってもこういうことが起きるのですね。複雑な組み込みシステムで、こういった脇役が起こす問題発見は相当しんどいですね。まだ問題を起こしそうなkswapdが心配ですね。
結論から申し上げます。
組み込みLinuxは制御システムの為に作られたものではありません。
制御システムを構築しない限り解決する問題ではありません。
オペレーティングシステムはオペレーションの為に作られました。
メインフレームと呼ばれていた大型コンピュータのメインメモリは
僅か128Kバイトと少なく、多くのジョブを走らせる為にMMUが
必要だった。MMU(メモリマネジメントユニット)は外部記憶装置
(HDD)にメモリのイメージを作成してメインメモリとのスワップを
して大きなタスクを実行していました。
RTOSもオペレーションの為に作られました。
小さなメモリと遅いCPUと遅いI/Oの入出力を効率よくする為に
タスクスイッチの機能であるタスク管理システムを構築しました。
このタスク管理システムが問題を引き起こしてたまにタスク実行の
順番を間違える事が起き、根本原因の解決には至っておりません。
面白そうな話で興味深いです。
昔Linuxカーネル開発者をやっていたときのことを久しぶりに思い出しました。自分がやっていたきはkernelSharkなんてものもなかったので、ひたすら大量の出力とにらめっこでした。
テックブログも楽しみにしています。
興味深い記事をありがとうございます。私はkswapdの動作には詳しくないのですが、本当に全てのプロセスが停止してしまうようなロックが長時間確保されるなんてことが起こりうるのでしょうか。実際にスワップイン・アウトする瞬間なら分かるのですが、いつ終わるか分からないページ探索中に、全てのプロセスに影響を与えるようなロックを確保し続けるというのは直感的に納得できません。もし具体的なロックの名前が分かっていたら教えていただきたいです。
こういうシステムでも動的にメモリを確保解放してるんだな…
複雑なシステムだからやむを得ないのだろうけど、そうなると常に不確定要素が付きまとうな。