はじめに
チューリングで自動運転第一グループのマネージャをやっている棚橋です。
今週、チューリングは無事にシリーズA 1st closeの資金調達を発表することができました。
E2E自動運転の開発においても、ようやく都内を30分ほど走行できるレベルに到達しつつあります。しかし、ここに至るまでの道のりは決して平坦ではなく、多くの失敗や試行錯誤を積み重ねてきました。実際にチューリングでは今まで累計約30万kmもの走行データを取ってきました。この記事ではこれまでの開発の道のり、そして今後について書きたいと思います。
E2E自動運転開発は簡単?

E2E自動運転のタスクは極めてシンプルです。過去のカメラ映像をもとにして未来の運転アクション(軌跡または加速度とステア舵角)を予測するだけです。タスクとしてはわかりやすいので、一見すると簡単に見えますが、実際に作ってみると大変なことばかりでした。
E2E開発の道のり
チューリングは2024年春から本格的にE2E自動運転開発を始めました。今と比べると当時はE2E自動運転をどうやって作れば良いかよく理解していませんでした。そもそも、当時国内ではE2E自動運転モデルを作って動かした実績のある人はいませんでした。海外ではTeslaやWayveなどごく少数の企業が開発に成功していましたが、ほとんど情報がない中でとにかく手探りで進めるしかありませんでした。まず最初に車両チームと車両ソフトウェアチームと一緒にアルファードを改造してデータ収集車両を作成しました。運用し始めた頃はカメラのフレーム落ちやセンサーの時刻同期がうまくできない問題、SSDにデータが書き込めなくなる原因不明の問題などトラブルが多発し、日々デバッグ作業に追われていました。これらの問題と1ヶ月以上格闘してようやく安定してデータ収集ができるようになりました。

次に、データをクラウド上にアップロードし、データのバリデーションやデータセットを作成することができるシステムを作りました。当時のパイプライン(下図)は今よりかなり簡易的なものでしたが、動画の画像の切り出し処理などをAWS Lambdaといったサーバーレスで処理する仕組みとすることで同時に数千の処理を実行して大規模データでも高速に処理できる仕組みでした。

上のインフラと合わせて、車両制御の開発も行いました。走行試験は柏の葉にあるテストコースで行ったのですが、ちょうどチューリングが柏の葉から大崎にオフィス移転したタイミングだったので、大崎から柏の葉に通う必要があり大変でした。最初は制御担当チームがパストラッキングできる制御モジュールの開発を行い、決められた経路に沿って走行できるかの試験を行いました。次に、テストコースを走行して取得したデータで学習したモデルを制御モジュールと結合する試験を行いました。このプロジェクトにおいては、E2Eのモデルを学習から推論、制御まで一貫して動かしたのはこれが最初でした。テストコースのデータだけで学習を行うとモデルが過学習してしまい、置いてある看板の位置や雑草の成長具体によってモデルの動きが変わってしまうという「E2E開発あるある」も一通り体験しましたが、その後様々な改良を重ねて下の動画のようにゆっくり周回できるようになりました。

小さなテストコースでは一旦ゆっくり走るようになったものの、実際の公道を走るにはより高い速度で走る必要がありました。制御モジュールに様々な改良を行い、大きなテストコースを貸し切って走行試験を行いました。曲率の高い道やバンクのついた道のデータを取得し、そのデータを元にまた改良を行うことで車の走りも良くなってきました。

限定したエリアで、信号機や横断歩道のあるシーンでの走行試験も始めました。最初は信号や横断歩道で止まることが難しく苦戦しましたが、データ取得方法を試行錯誤することで横断歩道で歩行者を認識して止まるなど、複雑な動作ができるようになりました。また、地図で目的地を設定すると、ナビゲーションのルートに従うモデル開発も行いました。以下の動画ではナビに従って自動運転を動かしている様子で、中央のタッチディスプレイでナビの目的地を設定することができます。

より広いエリアに汎化して走行できるモデルを作るために、当時の制御チーム(現先行開発チーム)は単一車両単一ドライバーに絞ったモデルの開発を開始しました。また、教師データとなる車の経路を高精度に作成するための改良も行いました。より広範囲の多様なデータを収集してモデルの学習を行うことで、初めて見た道路でも徐々に安定して走行できるようになりました。

さらに同チームで制御、モデル構造、データの改善を重ねることで、都心部の難しいシーンも走行できるようになってきました。以下の動画はチューリングの平和島オフィスから大崎オフィスに向かって自動運転走行している途中の映像です。交通量が多い割に路駐車両が多く車線も狭いですが、複雑な交通の中を人間のように運転することができました。

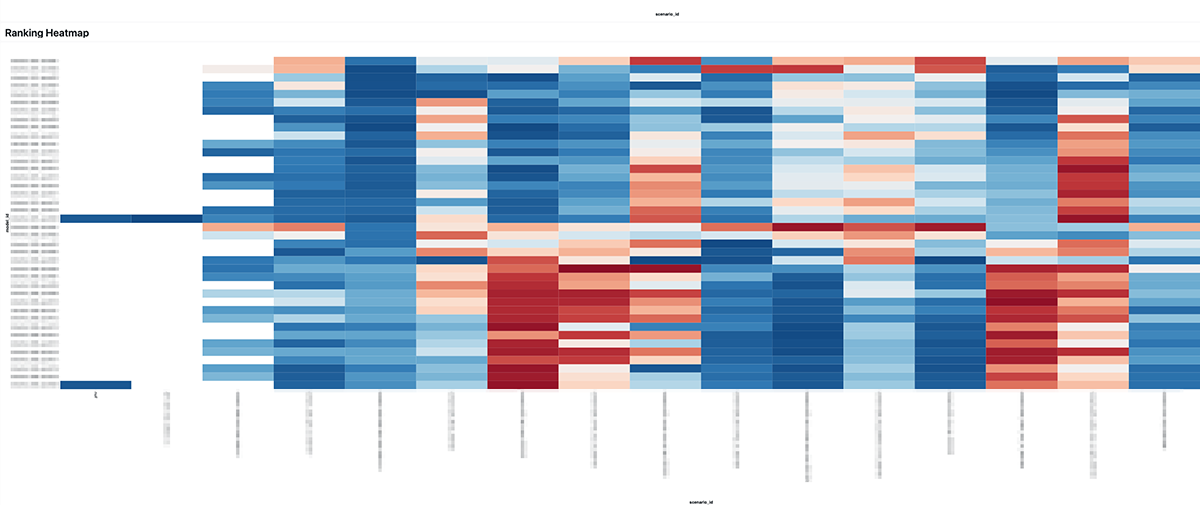
また、最近はモデル評価を行うためのシナリオテスト環境をMLOpsチームが構築しています。信号での停止など複数のシナリオがあらかじめ用意されており、学習途中のモデルのopen-loopでの性能を評価することができます。以下の画像はシナリオテストの結果を可視化するダッシュボードで、列がシナリオ、行がモデルに対応し、性能が良いほど青く表示されます。シナリオテストを使うことで、実験に行く前にモデルの挙動や性能をあらかじめ推測できるようになりました。また、モデルが改良されるごとに全体が青くなってくるので自分たちのモデルの成長具合をわかりやすく認識することができます。
データ量を多くすればするほど運転の性能が良くなると言われていますが、ただデータ量を増やせば高い走行性能が出る訳ではありませんでした。ScaleUpチームは、この課題に対してデータの取得方法や走行方法の見直しを行い、先行開発チームのモデルをベースとして、データを増やすと運転がよくなる方法を見つけることが出来ました。以下はその方法を使って学習したモデルで、30分近くハンドルとアクセル無操作で自動運転走行した時の動画です。
模倣学習ではエキスパートデータのみを用いて学習を行うので、分布外の状態からの復帰が苦手という問題があります。これを解決するために強化学習を使った自動運転開発も行っています。強化学習ではモデルを動かすためのシミュレーション環境が必要になります。E2E自動運転モデルの場合、モデルの入力が画像データです。そのため、CG(コンピュータグラフィックス)のシミュレーションの画像は現実との見た目のギャップ(sim2real ギャップ)が大きく、使うことが出来ません。そこで、3DGS(3D Gaussian Splatting)で現実の道路環境を学習し、これを用いて強化学習を行えるようにしました。以下の動画は実際の道路環境を3DGS空間で再現し、その中を学習済みのモデルが走行した時の様子です。対向車が来ているので少し待ってから右折発進する状況をうまく再現することが出来ています。このように、3DGSはモデルのclosed-loop評価にも使うこともできますし、強化学習の環境としても使うことができます。

この3DGSの空間内で強化学習を行っている様子が以下の動画です。左の動画はまだ学習初期の状態で、右折仕切れずに途中で打ち切りとなってしまっています。学習がうまく進むと、右の動画のように綺麗に右折できるようになります。また、動画の下部にはモデルが推定したRLにおけるvalue値、つまりその状況の安全度がプロットされています。学習が進むと適切なvalue値が推測されるようになっていることが確認できます。

このようにして強化学習したモデルを公道で走行したのが以下の動画です。左は模倣学習で学習したとあるモデルですが右折中にパスが不安定になっています。一方このモデルに強化学習fine-tuneを行うとうまく曲がれるようになりました(右)。まだRLの学習の規模は大きくないですが、今後さらに多様なシーンで強化学習を行える仕組みを整えていく予定です。

チューリングと世界の競合を比較すると、まだようやくスタートラインに立ったという状況です。しかし、自動運転業界の技術潮流は凄まじい速度で変化しており、その流れに適応できるかどうかが勝敗を分けます。その点において、チューリングの最大の強みは開発と改善サイクルの速さであり、どこにも負けていないと自負しています。
E2E自動運転開発は始めてから1年半で都内を30分走行するところまで来ることができました。また、平均で週に11回の走行実験、19個の新しいモデルを作成しており、日々モデルの改善を積み重ねています。このスピードこそがチューリングの強みであり、今後もこの勢いをさらに加速させていきたいと思います。
E2E自動運転開発はチーム戦
従来のモジュラー型の自動運転では、認識、予測、制御といった各レイヤーごとにチームを作ることができるので、モジュールの構成がそのまま組織の形となります。一方、E2Eの場合、1つの大きなNNで処理が完結しているため、従来の機能分割では責任分界点が曖昧になりがちです。そこで自動運転第一グループでは、E2Eモデルの 「学習と進化のプロセス」そのものを組織構造として具現化 しました。以下のように課題を切り分けることで4つのチームがそれぞれの強みを活かしながら連携し解決していく体制を取っています。以下では各チームの具体的な取り組みを紹介します。

E2E先行開発チーム
このチームは様々な技術を自由度高く開拓する探検家のようなチームです。担当領域はソフトウェアだけにとどまらず、カメラ位置、センサーなどのハードウェア、データ収集方法まで含めて、E2E自動運転の未踏領域を先行的に開拓します。日々走行実験を行い、試行錯誤を重ねながらスピード感を持って開発を進めています。最近は以下のような取り組みを行っています。
-
データ収集レシピの確立
モデルの汎化性能が大きく向上するデータ収集の方法を見出しました。 -
Transformerベースのマルチカメラ自動運転モデルを開発
日々の走行実験で地道に改善を繰り返した結果、効率的に学習可能かつ高精度なモデルを開発しました。このモデルが別のチームにもベースモデルとして提供されています。
他にも様々な取り組みを行っているので、詳しくは以下のインタビュー記事をご覧ください。
E2Eスケールアップチーム
このチームの目的はとにかくデータ量をスケールさせることです。データ量を多くすればするほど運転の性能が良くなると言われていますが、実際にはデータを多くしたからと言って簡単に性能が上がるわけではありません。このような課題に対してうまくデータをスケールさせるための方法を探索しており、最近はデータ数を増やすとそれに比例してモデルが賢くなるようになってきました。
RLチーム
模倣学習の限界を突破するために作られたのがRLチームです。強化学習を行うためには、E2Eモデルをシミュレートして動かす環境が必要です。新しく発足したばかりのチームですが、すでに3DGS (3D Gaussian Splatting)を使ったシミュレーション環境で強化学習を行い、学習したモデルを公道で走らせるところまで出来ています。
MLOpsチーム
上の3つのチームを支えるお母さん的存在がMLOpsチームです。学習に使う大規模GPUクラスタの環境整備や、収集した走行データから学習に使うためのデータセットを作成する仕組みづくりを担当しています。最近は、モデルを評価するためのシナリオテストを整備し、モデルの評価が手軽にできるようになりました。E2E自動運転ではモデルの改善サイクルをどれだけ速く回せるかが競争力です。このチームのおかげで、新しいアイデアを思いついたらすぐに実験できる環境が整っています。
Turingは一緒に開発する仲間を募集中です
E2E自動運転は「総合格闘技」のような領域です。カメラも、GPUも、データも、シミュレーションも、学習も、すべてが繋がって初めて前に進みます。Turing には、そのすべてがあります。
- 大規模GPUクラスタ
- データセントリックなMLモデル開発
- 模倣学習から強化学習、世界モデルに至るまでの技術の幅の広さ
- ハードとソフトをまたぐ開発文化
もし 「世界レベルのE2E自動運転を、日本発で作りたい」 と思っているなら、これほど面白い場所はありません。

Discussion
調達おめでとうございます
記事も参考になりました✨
これからも頑張ってください
ありがとうございます!応援の言葉、大変励みになります!
素晴らしい!
日本発のE2Eの実現性をリアルに感じました。
特にNNと組織構造の部分は面白かったです。
応援してます!
ありがとうございます!日本でE2E自動運転開発を行えるのはすごく意義があると思っています。
やることがはっきり見えている感じが素晴らしいです。個々の技術力と組織の構成がうまくかみ合ってていいですね。
そのように言ってもらえるのは嬉しいです!