はじめに
5月からTuringに中途入社した棚橋です。リクルートで広告配信システムの開発や量子アニーリングに関する研究開発に関わっていました。現在、Turingのリサーチチームで完全自動運転システムの研究開発に取り組んでいます。
3行でまとめ
- 今月開催されるCVPR2023では約2400本もの論文が発表されるため、見るべき論文を事前に検索しておきたい。
- 社内で行われた大規模言語モデル(LLM)ハッカソンをきっかけに、LLMのEmbeddingを用いて論文の「検索・推薦・要約」システムを作成し公開した。
- 検索クエリに文章を使った曖昧な検索が行えたり、類似論文の推薦ができる。6/13にアップデートされたGPT3.5の新機能であるファンクション機能を使うことで、複数観点に分けて研究内容の要約を出力させた。
↓ 今回作成した、LLMを使ったCVPR論文検索システム
事の発端
Turingは、ハンドル操作を必要としない完全自動運転システム(レベル5の自動運転)を搭載した電動自動車を2030年までに実現することを目指し、自動運転技術の研究開発を行っています。レベル5の自動運転を行うには一般的な社会常識を理解する高度な知能の獲得が必須であると考えており、過去のブログ記事でPaLM-SayCanやGATOなどの基盤モデルを例に完全自動運転戦略を紹介しました。この記事にもあるように、高度な自動運転実現において画像情報を扱うことのできるマルチモーダルな大規模言語モデル(LLM)を利用することが必要であると考えています。そこで、まずはとにかく皆がLLMと仲良くなる必要があるという話になり、社内ではLLMハッカソンと称して、「LLMを使って何か面白いものを作ろう」というイベントが突如として行われました。(ある朝急に、今日はハッカソンやるぞ!となりました。)
LLMを用いた論文検索システム
LLMハッカソンの一環として、私は論文の検索システムを作成しました。最近はコンピュータサイエンス分野の盛り上がりと共に読むべき論文の量が年々増大しており、全てを把握することが難しくなりつつあるため、膨大な論文から読みたいトピックの論文を簡単に探すことができれば嬉しいと思っていました。
従来の論文検索の問題点として
- キーワード検索が貧弱 (語句の揺らぎに弱い。文章での検索に非対応。)
- 興味のある論文から類似論文を検索するのが大変
- 論文の内容を理解するのが大変
という課題を感じていました。これらを解決するために、OpenAIが提供するAPIを用いて論文の内容を埋め込みベクトルに変換し、キーワードと類似する論文を検索する仕組みを考えました。これにより
- 文章や曖昧なキーワードから論文を検索
- 興味のある論文と類似している論文を推薦
といったことが可能となります。また、ChatGPTのAPIを用いることで「研究内容を要約する」機能をつけることもできます。
Turingの一部メンバーはCVPR 2023に参加することになっていたのですが、今年のCVPRで採択された論文数は約2400本になります。もし一つの論文の内容を確認するのに3分かかると仮定すると、全ての内容を確認するのに120時間もかかることになります。そこで、今年CVPRで発表される論文の検索を簡単に行えるシステムを作成してみました。
使い方
1. 検索
上のサイトにアクセスすると検索キーワードを入力するテキストボックスがあるので、検索したい語句を入力します。検索キーワードは後でEmbedding APIによってベクトル化するので、日本語でも英語でも、文章でも問題ありません。検索キーワードとは別にコンピュータビジョンの技術用語がいくつか登録されている検索タグを追加で設定することも可能です。

検索ボタンを押すと、以下のように検索結果の一覧がすぐに表示されます。

2. ChatGPTによる論文の要約
OpenAIのAPIを使っているので、どうせなら論文の要約をしてもらうことにしました。検索結果一覧にある「この研究の何がすごいのかChatGPTに聞く」というボタンを押すと、論文の要点についてアブストラクトの文章をもとに日本語でまとめてくれます。2023/6/13のアップデートで追加されたfunction call機能を用いて、論文の新規性について3つの観点で回答を取得しています。

3. ベクトルによる類似論文の推薦
興味のある論文が見つかった場合、さらに深掘りするために類似した論文を見つけたくなることがあります。「この研究と似た論文を探す」というリンクをクリックすると、その論文と類似した論文一覧が新しいページで表示されます。これは単に元の論文のタイトルを検索キーワードとして検索した結果を表示しているだけです。

新しく導入されたFunction機能を使った研究内容の要約
6/13にOpenAIが大規模なアップデートを行い、APIからgpt3.5-turboを使った呼び出しにおいて、function機能を使うことができるようになりました。この機能を使うことで、ChatGPTがメッセージを返すのではなく、こちらが指定した関数の引数に合わせてJSONの形で出力を取得することができるようになりました。これまではChatGPTの結果を別のプログラムの入力とする場合、JSONの形式を出力するように様々なおまじないを書いていたのですが、それが不要となります。また、複数の関数を定義しておくと、適切な関数をChatGPTが勝手に選んで呼んでくれる、つまり実質的にChatGPTプラグインを作ることが可能となりました。詳細は公式ドキュメントを見てください。
今回の場合、論文の内容を幾つかのポイントに分けて要約し、項目ごとに分けて出力するようにfunctionを定義しています。このように定義したfunctionsをAPI呼び出し時に渡すことで、この関数の形式に沿って出力を返してくれます。今回は単に出力を項目ごとに分けるためにfunction機能を使っていますが、動的に呼び出す関数を変えたりすることで、ChatGPTを組み込んだシステムの開発が非常に手軽にできるようになりました。
functions = [
{
"name": "format_output",
"description": "アブストラクトのサマリー",
"parameters": {
"type": "object",
"properties": {
"problem_of_existing_research": {
"type": "string",
"description": "既存研究では何ができなかったのか",
},
"how_to_solve": {
"type": "string",
"description": "どのようなアプローチでそれを解決しようとしたか",
},
"what_they_achieved": {
"type": "string",
"description": "結果、何が達成できたのか",
},
},
"required": ["problem_of_existing_research", "how_to_solve", "what_they_achieved"],
},
}
]
検索の仕組み
仕組みは非常に簡単で、ユーザが入力したテキストをLLMを用いてベクトル化し、あらかじめベクトル化しておいた論文に対して類似検索を行うというものです。LLMのベクトル化にはOpenAIが提供する様々なGPT3ベースのモデルをEmbedding APIから用いることができます。特に、text-embedding-ada-002というモデルがコストと性能のバランスが優れているということでOpenAIからも利用を推奨されています。6/13のアップデートにより、embeddingのコストが下がり、1Kトークンあたり$0.0001となりました。これにより大きなデータに対して低コストでembeddingを計算することも可能になりました。

また、今回は検索対象が2400と少ないので、すべての論文とキーワードのスコアを計算してスコアが最も高いtop-Nの論文を取得しています。スコアはベクトル同士の内積で表現できるので、論文のベクトルをあらかじめN×Dの行列として保持しておき、これとキーワードのベクトルとの行列積を計算すれば良いだけです。(Nは論文数、Dは埋め込み次元数)
以下のコードでは、OpenAI APIを使ってクエリテキストの埋め込みを取得し、すべての論文に対してスコアを計算しています。この時、論文のタイトル、アブストラクトに対してスコアを計算し、パラメータalphaによる加重和を最終スコアとしています。
import openai
import numpy as np
# あらかじめベクトル化した論文の埋め込み。N*Dの行列。
title_vec = load_title_vec()
abst_vec = load_abst_vec()
meta_df = load_meta_df()
def vectorize(text: str, model="text-embedding-ada-002"):
text = text.replace("\n", " ")
return openai.Embedding.create(input = [text], model=model)['data'][0]['embedding']
def calc_score(query_vector: np.ndarray, alpha: float):
title_score = title_vec @ query_vector
abst_score = abst_vec @ query_vector
return alpha * title_score + (1 - alpha) * abst_score
def search(query_text: str, alpha: float, k: int):
# OpenAI APIを使ってベクトル化
query_vector = vectorize(query_text)
score = calc_score(query_vector, alpha)
top_k_indices = np.argsort(-score)[:k]
return meta_df.iloc[top_k_indices]
今回と異なり、検索対象が多い場合には、検索対象のベクトルを量子化などによって圧縮しておくことで高速に検索を行うことが可能です。これを容易に行うライブラリとしてFacebook Researchが開発したFaissが有名で、GPU演算にも対応しており、数十億というアイテムに対してベクトル検索を高速に行うことが可能です。
また、マネージドなベクトル検索エンジンとしてはGoogle Cloud PlatformでVertex AI Matching Engineというサービスが利用できます。数十億というベクトルに対して高速な検索を行うことができ、さらにデータのバッチ更新やストリーム更新にも対応しています。高負荷な状況でもスケールして利用することができるので、ECサイトにおけるアイテム推薦や画像/映像の検索サービスなどで活用が進んでいます。
![[ref] https://cloud.google.com/vertex-ai/docs/matching-engine/overview](https://res.cloudinary.com/zenn/image/fetch/s--pB8MKTbB--/https://storage.googleapis.com/gweb-cloudblog-publish/original_images/ScaNN_tom_export.gif)
[ref] https://cloud.google.com/vertex-ai/docs/matching-engine/overview
埋め込みを用いたChatGPTの拡張: LlamaIndex
埋め込みベクトルを用いた検索の応用として、ChatGPTを大きな文書データベースに対して利用する方法について紹介します。ChatGPTで用いられるGPT3.5では入力できるトークンのサイズが4000程度に限られているため、トークンに収まらない文書の内容については質問を投げかけることができませんでした。
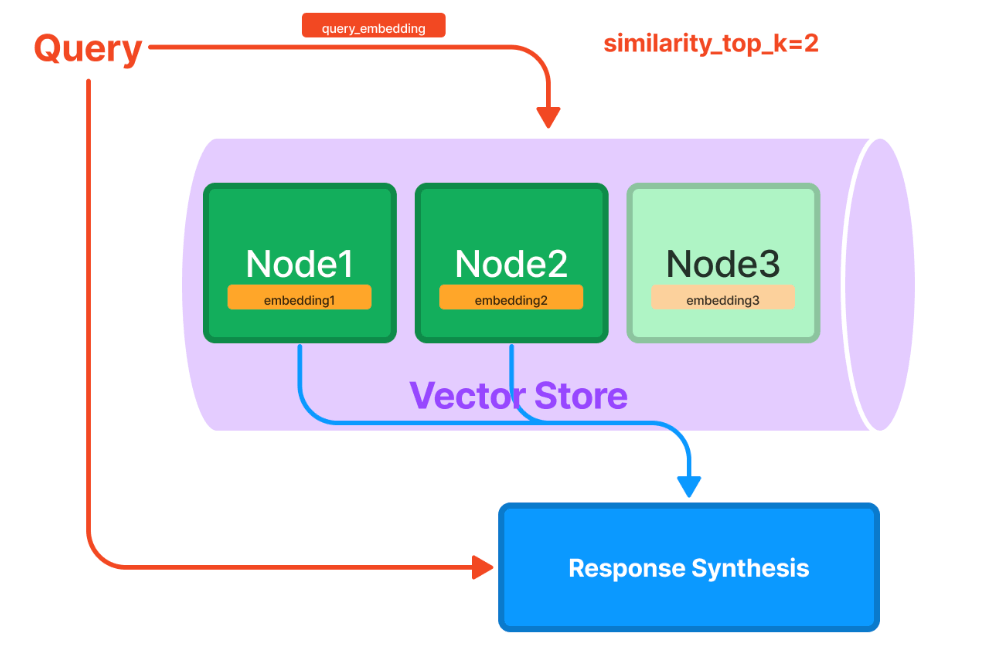
しかし、LlamaIndexというソフトウェアを使うことで非常に大きな文書に対してChatGPTを用いて質問を行うことが可能となります。例えば、社内のnotionドキュメントで蓄積された知識に対して質問を投げかけることができます。仕組みとしては、検索対象のドキュメント(以下の図のNode1~Node3)に対してあらかじめ埋め込みベクトルを計算しておきます。文書が大きい場合は小さいサイズに分割しておきます。検索クエリが投げられると、検索クエリのベクトルを計算し、類似度が高いNodeだけを抽出します。検索クエリと関連度が高い文書だけがResponse Synthesisモジュールに送られ、それらの少量のドキュメントに対して改めてChatGPTの質問を投げかけることで、最終的な回答が生成されるという仕組みです。このように、埋め込みベクトルを用いることで、ChatGPTの拡張性を高めることができます。
LlamaIndexのインデックスを既存のドキュメントから構築することができる様々なローダーがhttps://llamahub.ai/で公開されており、NotionやSlack, Google Docsなどから文書を読み込むことが可能です。
「自動運転」キーワードによる検索結果例
論文の検索システムの話に戻ります。例えば、「自動運転」をキーワードとして検索してみると、多くの自動運転に関する論文を検索することができます。以下にその一部の結果と、ChatGPTによる要約を掲載します。CVPRはコンピュータビジョンに関する国際会議なので、特にカメラ画像からの入力をもとに周囲の道路や車の情報を推論するためのモデルの研究が多く見られます。また、以下に掲載している多くの論文では車体に取り付けた複数のカメラからの情報を統合して鳥瞰図(Bird Eye View)を作成するモデルを元に発展しています。この技術については、過去に弊社いのいちが関東3D勉強会で発表した資料「マルチカメラを用いた自動運転の3D Occupancy Prediction」で詳しく述べていますが、もともとTeslaが2022年のCVPR Workshop、その後のTesla AI Day 2022で発表したことで大きく話題になったモデルです。TeslaはEV業界だけではなく、自動運転の研究開発においても業界を牽引する存在となっています。
CVPRで発表された自動運転に関する新しい研究成果については後ほど出すブログ記事にてレポートしたいと思います。今年は自動運転に関するワークショップが5つも開かれる予定なので、ワークショップについても目が離せません。
CVPR 2023 自動運転に関するワークショップ
- End-to-End Autonomous Driving: Perception, Prediction, Planning and Simulation
- Secure and Safe Autonomous Driving Workshop and Challenge (SSAD)
- Vision-Centric Autonomous Driving (VCAD)
- Workshop on Autonomous Driving (WAD)
- Workshop on End-to-end Autonomous Driving
まずは今回公開した検索システムを用いることで興味のある論文を検索して楽しんでもらえたらと思います。
インターン、中途採用の募集
Turingでは夏の学生インターンと中途採用の募集を行っています!コンピュータビジョンに興味ある方はもちろん、多くのポジションでエンジニアを募集していますので、ぜひご検討ください!
以下、「自動運転」キーワードによる検索結果例
Planning-Oriented Autonomous Driving
Yihan Hu, Jiazhi Yang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai, Senyao Du, Tianwei Lin, Wenhai Wang, Lewei Lu, Xiaosong Jia, Qiang Liu, Jifeng Dai, Yu Qiao, Hongyang Li
1. 既存研究では何ができなかったのか
既存の自動運転システムは順序付けされたモジュールタスクとして特徴付けられており、個々のタスクに対してスタンドアロンモデルを展開するか、別々のヘッドを持つマルチタスクパラダイムを設計しています。しかし、これらのアプローチは誤差が蓄積されることやタスクの連携が不十分になる可能性があります。
2. どのようなアプローチでそれを解決しようとしたか
既存の問題を解決するために、自動運転の究極の目標である計画に焦点を当てて最適化されたフレームワークを提案しています。これにより、知覚と予測の主要な要素を見直し、計画に貢献するようにタスクを優先順位付けします。さらに、Unified Autonomous Driving(UniAD)という、1つのネットワークで全スタックの運転タスクを組み込んだ包括的なフレームワークを導入しています。
3. 結果、何が達成できたのか
UniADは、各モジュールの利点を活用し、エージェント相互作用に対してグローバルな観点から補完的な特徴抽象を提供するように精巧に設計されています。タスクは、統一されたクエリインターフェースを用いて計画に向けてお互いを促進するように通信されます。UniADをnuScenesベンチマークに適用することで、広範なアブレーション実験を通じて、この哲学を用いた効果が、すべての点で先行研究を大幅に上回ることが証明されました。さらに、コードとモデルが公開されています。


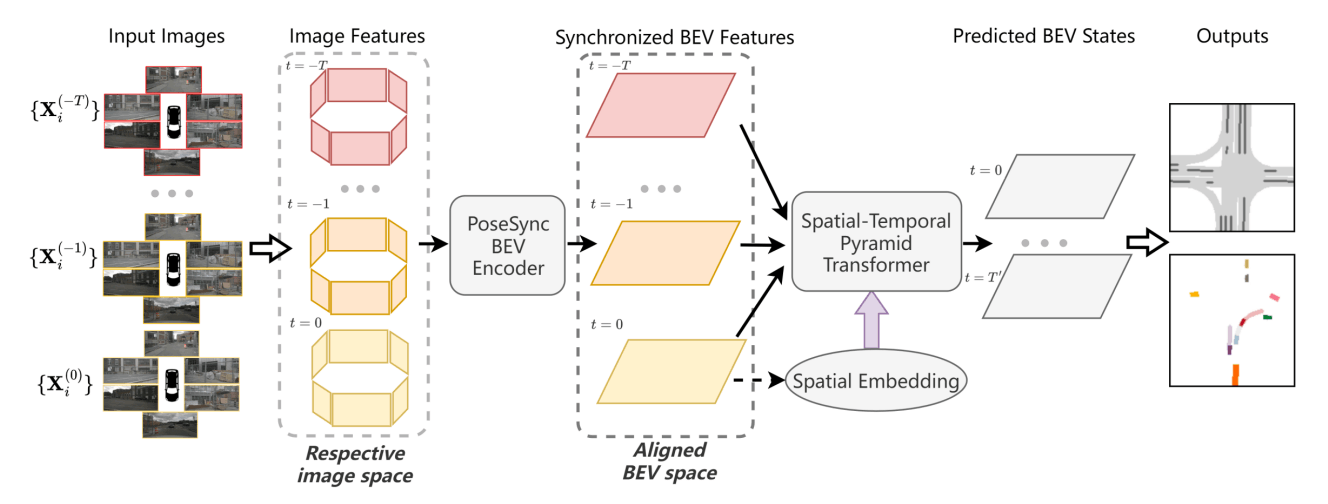
TBP-Former: Learning Temporal Bird's-Eye-View Pyramid for Joint Perception and Prediction in Vision-Centric Autonomous Driving
Shaoheng Fang, Zi Wang, Yiqi Zhong, Junhao Ge, Siheng Chen
1. 既存研究では何ができなかったのか
既存の研究では、複数のカメラビューとタイムスタンプで得られた特徴量を同期させることが難しく、これらの空間-時間的特徴をさらに活用することが困難であった。
2. どのようなアプローチでそれを解決しようとしたか
この問題を解決するために、Temporal Bird's-Eye-View Pyramid Transformer (TBP-Former)が提案され、2つの新しいデザインが含まれている。まず、ポーズ同期されたBEVエンコーダが提案されており、任意のカメラポーズでの生の画像入力を共有された同期されたBEV空間にマップする。次に、空間-時間的なピラミッドトランスフォーマが導入され、多尺度のBEV特徴を包括的に抽出し、空間的事前情報のサポートを受けて未来のBEV状態を予測する。
3. 結果、何が達成できたのか
nuScenesデータセットでの実験により、提案されたフレームワークが全体的に最先端の視覚ベースの予測手法を上回ることが示された。
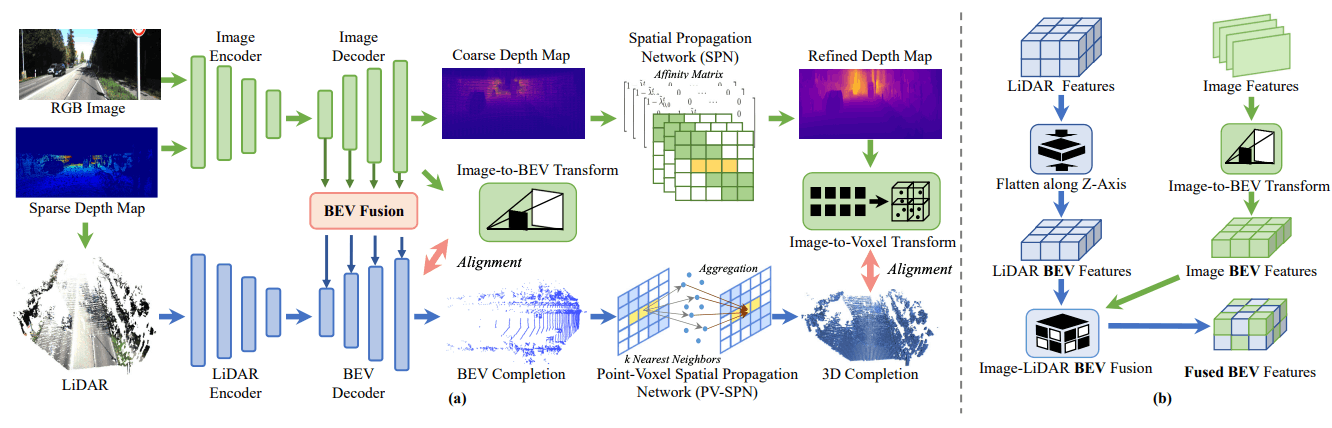
BEV@DC: Bird's-Eye View Assisted Training for Depth Completion
Wending Zhou, Xu Yan, Yinghong Liao, Yuankai Lin, Jin Huang, Gangming Zhao, Shuguang Cui, Zhen Li
1. 既存研究では何ができなかったのか
既存の研究では、LiDARを用いた深度補完において、空間幾何学的制約を活用して画像ガイド付き深度補完の性能を向上させることができたが、効率が低く、一般化性能が十分でなかった。
2. どのようなアプローチでそれを解決しようとしたか
BEV@DCモデルを提案し、訓練時にリッチな幾何学的詳細を持つLiDARを包括的に利用し、推論時には画像(RGBと深度)のみを入力とする強化された深度補完方法を採用することで、効率と一般化性能を向上させることを試みた。
3. 結果、何が達成できたのか
ひとつの画像入力のみで、BEV@DCモデルは基本モデルへ大幅な改善をもたらした。具体的には、KITTI深度補完ベンチマークなど、複数の評価基準で最先端の性能を達成し、Top-1ランクを獲得することができた。
Neural Map Prior for Autonomous Driving
Xuan Xiong, Yicheng Liu, Tianyuan Yuan, Yue Wang, Yilun Wang, Hang Zhao
1. 既存研究では何ができなかったのか
既存の研究では、高精度(HD)なセマンティックマップを作成するのに労力のかかる手動アノテーションプロセスを用いており、これはコストが高く、タイムリーな更新が難しいという問題があった。また、オンラインセンサー観測に基づくローカルマップの推論は、センサーの認識範囲や遮蔽物の影響を受けやすく、制約があった。
2. どのようなアプローチでそれを解決しようとしたか
Neural Map Prior (NMP)というグローバルマップのニューラル表現を提案し、自動的なグローバルマップの更新とローカルマップ推論性能の向上を目指した。ローカルマップ推論に強力なマップ事前情報を取り入れるため、現在の特徴と事前特徴の相関を動的に捉えるクロスアテンションを用いた。また、グローバルニューラルマップ事前情報の更新には、学習ベースの融合モジュールを使って、過去の探索からの特徴融合をネットワークに導いた。
3. 結果、何が達成できたのか
nuScenesデータセットでの実験結果により、提案したフレームワークがほとんどのマップセグメンテーション/検出方法と互換性があり、困難な天候条件や拡張された地平線でのマップ予測性能を向上させることができることが示された。これは、グローバルマップ事前情報を構築するための初めての学習ベースのシステムとなる。

SkyEye: Self-Supervised Bird's-Eye-View Semantic Mapping Using Monocular Frontal View Images
Nikhil Gosala, Kürsat Petek, Paulo L. J. Drews-Jr, Wolfram Burgard, Abhinav Valada
1. 既存研究では何ができなかったのか
既存研究では、Bird's-Eye-View(BEV)のsemantic mapを生成するために完全に教師あり学習パラダイムを使用する必要があり、多くの注釈付きBEVデータに頼っていたため、データの収集や処理のコストが高かった。
2. どのようなアプローチでそれを解決しようとしたか
この論文では、単一のモノクルフロントビューイメージからBEV semantic mapを生成するための最初のセルフスーパーバイズドアプローチを提案している。トレーニング中、FVでのシーンの経時的な空間一貫性をFVセマンティックシーケンスに基づいて強制することにより、BEVのグランドトゥルースアノテーションの必要性を克服し、セルフスーパーバイズド学習の2つのモードを使用して学習を実現している。
3. 結果、何が達成できたのか
結果として、KITTI-360データセットでの評価により、このセルフスーパーバイズドアプローチは、完全に教師あり方法と同等のパフォーマンスを発揮し、完全に教師ありアプローチに比べて1%の直接的なスーパーバイズが可能であるという競争力のある結果を達成した。また、著者らは彼らのコードとBEVデータセットを公開している。

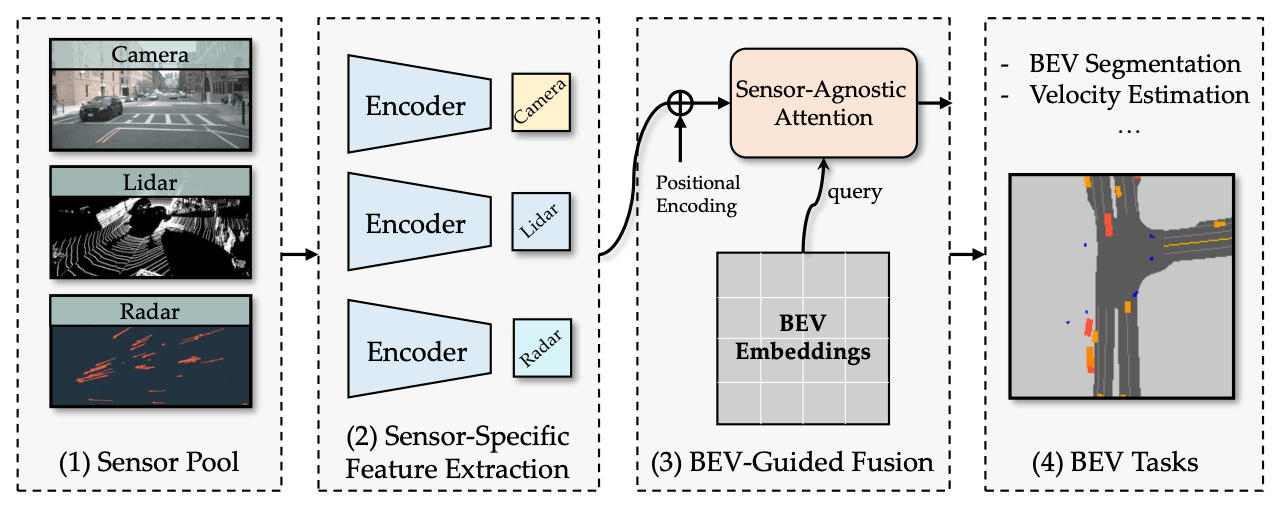
BEV-Guided Multi-Modality Fusion for Driving Perception
Yunze Man, Liang-Yan Gui, Yu-Xiong Wang
1. 既存研究では何ができなかったのか
既存研究では、複数のセンサーを統合し、さまざまなタスクをエンドツーエンドのアルゴリズムで取り扱うことが難しく、多様なセンサーを直接的なBEVガイダンスの下で一元化することができませんでした。
2. どのようなアプローチでそれを解決しようとしたか
BEVGuideという新しいBird's Eye-View (BEV)表現学習フレームワークを導入することで、カメラ、Lidar、Radarセンサーなどの多様なセンサープールからの入力を受け付け、汎用性の高いトランスフォーマーバックボーンを使ってBEVの特徴埋め込みを抽出し、BEVガイドされたマルチセンサー注意ブロックを設計して、センサー固有の特徴からBEV表現を学習するアプローチを取りました。
3. 結果、何が達成できたのか
このフレームワークは、軽量なバックボーン設計により効率的であり、ほぼ任意の入力センサー構成に対応する高い柔軟性を持っています。その結果、BEVGuideは、多様なセンサーセットでBEVパーセプションタスクにおいて優れた性能を達成することができました。
Understanding the Robustness of 3D Object Detection With Bird's-Eye-View Representations in Autonomous Driving
Zijian Zhu, Yichi Zhang, Hai Chen, Yinpeng Dong, Shu Zhao, Wenbo Ding, Jiachen Zhong, Shibao Zheng
1. 既存研究では何ができなかったのか
既存の研究では、Bird's-Eye-View(BEV)表現を使用した3Dオブジェクト検出モデルのロバスト性に関する体系的な理解が欠けていました。これは、自動運転システムの安全性に密接に関連しています。
2. どのようなアプローチでそれを解決しようとしたか
著者らは、さまざまな代表的なモデルを自然で敵対的なロバスト性の観点から評価し、BEV表現を使用することがモデルの挙動にどのような影響を与えるかを理解しようとしました。また、3D空間で敵対的なパッチを適用することにより、空間的・時間的な一貫性を保証するとともに、自動運転シナリオにおいて現実的な3D一貫性パッチ攻撃を提案しました。
3. 結果、何が達成できたのか
以下のいくつかの重要な発見が得られました。1) BEVモデルは、表現力のある空間表現のおかげで、さまざまな自然な条件や一般的な破損に対して、以前の方法よりも安定しています。2) BEVモデルは、冗長なBEV特徴が原因で、敵対的なノイズに対して脆弱です。3) カメラ-LiDAR融合モデルは、マルチモーダル入力により、さまざまな設定で優れた性能を発揮しますが、BEV融合モデルは、点群と画像の両方の敵対的なノイズに対して脆弱です。これらの発見は、BEV検出器の応用での安全性問題に警鐘を鳴らし、よりロバストなモデルの開発を促進する可能性があります。

BEVFormer v2: Adapting Modern Image Backbones to Bird's-Eye-View Recognition via Perspective Supervision
Chenyu Yang, Yuntao Chen, Hao Tian, Chenxin Tao, Xizhou Zhu, Zhaoxiang Zhang, Gao Huang, Hongyang Li, Yu Qiao, Lewei Lu, Jie Zhou, Jifeng Dai
1. 既存研究では何ができなかったのか
既存の鳥瞰図 (BEV) 検出器は、VoVNet のような特定の深さの事前学習済みバックボーンに依存しており、急速に発展している画像バックボーンと BEV 検出器のシナジー作用を阻害していました。
2. どのようなアプローチでそれを解決しようとしたか
BEV検出器の最適化を容易にするために、perspective view supervisionを導入することを優先しました。そのために、perspective headからの情報が、最終的な予測のために鳥瞰図 (BEV) ヘッドに送られる二段階 BEV 検出器を提案しています。
3. 結果、何が達成できたのか
提案された方法は、伝統的かつ現代的な幅広い画像バックボーンで検証され、大規模な nuScenes データセットで新たな最先端の結果を達成しました。また、教師データの形式と提案された検出器の一般性に焦点を当てた包括的なアブレーション研究を実施しました。この手法の有効性が評価されたことが確認されました。

ReasonNet: End-to-End Driving With Temporal and Global Reasoning
Hao Shao, Letian Wang, Ruobing Chen, Steven L. Waslander, Hongsheng Li, Yu Liu
1. 既存研究では何ができなかったのか
既存の研究では、都市部の密接な交通状況において、シーンや物体の未来の挙動を予測し、急に現れる遮蔽された物体などの稀な悪条件に対処することが困難でした。
2. どのようなアプローチでそれを解決しようとしたか
ReasonNetという新しいエンドツーエンドの運転フレームワークを提案し、運転シーンの時間的およびグローバルな情報を幅広く利用することで解決を試みました。時系列の物体の挙動について推論することで、異なるフレーム間の特徴の相互作用や関係を効果的に処理し、シーンのグローバル情報について推論することで、全体的な認識性能を向上させ、遮蔽された物体からの潜在的な危険を予期することが可能になります。
3. 結果、何が達成できたのか
DriveOcclusionSimという遮蔽イベントを含む公開ドライビングシミュレーションベンチマークをリリースし、複数のCARLAベンチマークで実験を行い、提案モデルが既存の方法を上回るパフォーマンスを達成し、CARLAリーダーボードのセンサートラックでトップにランクインすることができました。

Towards Domain Generalization for Multi-View 3D Object Detection in Bird-Eye-View
Shuo Wang, Xinhai Zhao, Hai-Ming Xu, Zehui Chen, Dameng Yu, Jiahao Chang, Zhen Yang, Feng Zhao
1. 既存研究では何ができなかったのか
既存のカメラのみを使用した3Dオブジェクト検出アルゴリズムは、入力画像のドメインが訓練データと異なる場合、性能が大幅に低下するリスクがあった。
2. どのようなアプローチでそれを解決しようとしたか
ドメインギャップの原因を分析し、鳥瞰図(BEV)の特徴分布が主な問題であることを特定した。これを解決するために、メトリック深さの予測からスケール不変の深さへ変換して深さ推定をカメラの内部パラメータ(焦点距離)から切り離し、ホモグラフィーを利用して外部パラメータ(カメラのポーズ)の多様性を増やすために動的パースペクティブ増強を実行した。さらに、複数の疑似ドメインを作成し、特徴表現がよりドメイン非依存になるように敵対的訓練ロスを構築するために、焦点距離の値を変更した。
3. 結果、何が達成できたのか
提案されたアプローチであるDG-BEVでは、Waymo、nuScenes、およびLyftのデータセットで実験を行い、未見の目標ドメインでの性能低下を緩和しながら、ソースドメインの精度を損なわずに一般化と効果が実証された。

Pix2map: Cross-Modal Retrieval for Inferring Street Maps From Images
Xindi Wu, KwunFung Lau, Francesco Ferroni, Aljoša Ošep, Deva Ramanan
1. 既存研究では何ができなかったのか
既存研究では、自動運転車が使用する都市の道路地図のトポロジーを、生の画像データから直接推定することができなかった。
2. どのようなアプローチでそれを解決しようとしたか
著者らは、Pix2Mapというメソッドを導入し、画像と既存の地図(トポロジを符号化した離散グラフ)の共同、クロスモーダルな埋め込み空間を学習することで、クロスモーダルリトリーバルとしてこの問題に対処しようとした。
3. 結果、何が達成できたのか
Argoverseデータセットを用いた実験評価により、画像データだけから、既知の道路と未知の道路の対応するストリートマップを正確に取得することが可能であることが示された。さらに、取得したマップを使用して既存のマップを更新や拡張することができ、視覚的なローカリゼーションや空間グラフからの画像検索に関する証拠概念の結果も示された。

Learning and Aggregating Lane Graphs for Urban Automated Driving
Martin Büchner, Jannik Zürn, Ion-George Todoran, Abhinav Valada, Wolfram Burgard
1. 既存研究では何ができなかったのか
既存研究では複雑な車線のトポロジー、分布外のシナリオ、画像空間での著しい遮蔽に苦しんでいたため、大規模で一貫性のある車線グラフのマージングが困難であった。
2. どのようなアプローチでそれを解決しようとしたか
著者らは、複数の重複するグラフを単一の一貫性のあるグラフに集約する革新的なボトムアップアプローチを提案しました。モジュール式の設計により、グラフニューラルネットワークを使用して任意の車両位置からego-respective successor laneグラフを予測し、これらの予測を一貫性のあるグローバル車線グラフに集約することができます。
3. 結果、何が達成できたのか
大規模な車線グラフデータセットでの詳細な実験により、提案手法は著しい遮蔽領域でも高度に正確な車線グラフを生成し、グラフの一貫性を高めながら一貫性のある予測を排除することができることが示されました。また、著者らはデータセットとコードを公開しています。

Implicit Occupancy Flow Fields for Perception and Prediction in Self-Driving
Ben Agro, Quinlan Sykora, Sergio Casas, Raquel Urtasun
1. 既存研究では何ができなかったのか
既存研究では、オブジェクト検出に続いて検出されたオブジェクトの軌跡を予測するか、全シーンに対して密度およびフローグリッドを予測することができなかった。
2. どのようなアプローチでそれを解決しようとしたか
研究者らは、1つのニューラルネットワークで時間にわたって占有とフローを暗黙的に表現し、知覚と将来の予測を統一的に取り扱うアプローチを提案した。また、効率的かつ効果的なグローバル注意機構を追加したアーキテクチャを設計した。
3. 結果、何が達成できたのか
実験の結果、提案手法は、都市部および高速道路の両方で現行の最先端を上回る性能を発揮した。また、必要のない計算を回避することができ、運動計画者によって連続した時空間の位置で直接クエリできるため、実世界の応用に適していると考えられる。

V2V4Real: A Real-World Large-Scale Dataset for Vehicle-to-Vehicle Cooperative Perception
Runsheng Xu, Xin Xia, Jinlong Li, Hanzhao Li, Shuo Zhang, Zhengzhong Tu, Zonglin Meng, Hao Xiang, Xiaoyu Dong, Rui Song, Hongkai Yu, Bolei Zhou, Jiaqi Ma
1. 既存研究では何ができなかったのか
既存の自動運転車の知覚システムは、遮蔽に対して敏感であり、長距離の知覚能力が不足しているとされている。これは、レベル5の自動運転を実現する上での主要なボトルネックである。また、Vehicle-to-Vehicle (V2V) の協調知覚システムには自動運転産業を革新する可能性があることが示されているが、実世界のデータセットが不足しており、この分野の進歩が阻害されている。
2. どのようなアプローチでそれを解決しようとしたか
実世界の大規模なV2V知覚のためのマルチモーダルデータセットであるV2V4Realを提案し、データは多様なシナリオで走行するマルチモーダルセンサーを搭載した2台の車両によって収集された。V2V4Realデータセットは、協調3Dオブジェクト検出、協調3Dオブジェクトトラッキング、および協調知覚のSim2Realドメイン適応という3つの知覚タスクを導入する。
3. 結果、何が達成できたのか
V2V4Realデータセットは、410 kmの走行領域をカバーし、20KのLiDARフレーム、40KのRGBフレーム、5つのクラスの240Kのアノテーションされた3Dバウンディングボックス、およびすべての走行ルートを網羅するHDMapsを含んでいる。さらに、3つのタスクにおいて最近の協調知覚アルゴリズムの包括的なベンチマークを提供している。これにより、V2V協調知覚技術の発展が促進されることが期待される。
Visual Exemplar Driven Task-Prompting for Unified Perception in Autonomous Driving
Xiwen Liang, Minzhe Niu, Jianhua Han, Hang Xu, Chunjing Xu, Xiaodan Liang
1. 既存研究では何ができなかったのか
既存のマルチタスク学習アルゴリズムは、計算リソースと推論時間の効率性を向上させるために設計されていますが、それらは主に自動運転の範囲外の異なるタスクのために設計されており、自動運転におけるマルチタスク方法の比較が難しい状況が存在していました。また、既存のマルチタスク学習方法と単一タスクのベースラインとの間には、大きな性能差があることがわかっていました。
2. どのようなアプローチでそれを解決しようとしたか
著者らは、自動運転における包括的なマルチタスク学習方法の評価を可能にするために、大規模な自動運転データセットを用いて、オブジェクト検出、意味的セグメンテーション、走行可能領域セグメンテーション、およびレーン検出といった4つの一般的な知覚タスクについて、既存のマルチタスク方法の性能を詳細に調査しました。そして、VE-Promptという効果的なマルチタスクフレームワークを提案しました。このフレームワークでは、タスク固有のプロンプトを通じて視覚的な見本を導入し、モデルを高品質のタスク固有の表現を学習する方向に導きます。具体的には、バウンディングボックスと色ベースのマーカーに基づいた視覚的な見本を生成し、目標カテゴリの正確な視覚的外観を提供し、性能ギャップを緩和します。
3. 結果、何が達成できたのか
VE-Promptフレームワークを用いた実験により、マルチタスクのベースラインを向上させることができ、さらに単一タスクのモデルを上回ることが示されました。これにより、自動運転におけるさまざまなマルチタスク学習方法の性能評価が可能になりました。また、トランスフォーマーベースのエンコーダと畳み込み層を効率的かつ正確な統一された知覚のために結合することができました。

Think Twice Before Driving: Towards Scalable Decoders for End-to-End Autonomous Driving
Xiaosong Jia, Penghao Wu, Li Chen, Jiangwei Xie, Conghui He, Junchi Yan, Hongyang Li
1. 既存研究では何ができなかったのか
既存研究では、デコーダーに負荷がかかりすぎるため、適切な安全領域を見つけ出したり、将来の自動車の行動を予測することに課題があった。
2. どのようなアプローチでそれを解決しようとしたか
研究では、2つの原則を用いて問題を解決しようとした。(1) エンコーダーの容量を十分に活用すること。(2) デコーダーの容量を増やすこと。具体的には、まずエンコーダーの機能を利用して、予測される航跡と行動を予測します。その後、その位置と行動を基に、安全性クリティカルな領域を想像して将来の状況を予測します。予測された座標周辺のエンコーダーの機能も取得し、細かい情報を入手します。最後に、予測した将来の情報と取得した情報を基に、予測した座標からのオフセットを予測して座標を精度よく調整する方法が提案されている。
3. 結果、何が達成できたのか
この研究では、提案した方法により、安全な自動車の走行を達成することに成功した。閉ループベンチマークにおいて、最先端の性能を達成し、さらに抽出された知識によってデコーダーの容量を拡張することができた。

ProphNet: Efficient Agent-Centric Motion Forecasting With Anchor-Informed Proposals
Xishun Wang, Tong Su, Fang Da, Xiaodong Yang
1. 既存研究では何ができなかったのか
既存研究では、多様なソースからの入力の異質性、エージェント行動の多様性、そしてオンボード展開に必要な低遅延を同時に満たすことが難しかった。具体的には、複雑な入力を効果的にエンコードし、広範囲な未来の軌跡をカバーする多モーダル予測を生成するのが困難であった。
2. どのようなアプローチでそれを解決しようとしたか
本論文では、アンカー情報を活用した効率的な多モーダルモーション予測のためのエージェント中心モデルを提案する。まず、モダリティに依存しない戦略を設計し、複雑な入力を統一的な方法で簡潔にエンコードする。次に、ゴール指向のコンテキストを持つアンカーと融合した多様な提案を生成し、広範囲の未来の軌跡をカバーする多モーダル予測を導く。さらに、ネットワークアーキテクチャは非常に一様で簡潔であり、実世界展開に適した効率的なモデルが得られる。
3. 結果、何が達成できたのか
実験により、提案されたエージェント中心ネットワークは、予測精度において最先端の方法と比較して有利であり、シーン中心レベルの推論遅延が達成できることが示された。これにより、自動運転システムにおいて効率的なモーション予測が可能となる。

GINA-3D: Learning To Generate Implicit Neural Assets in the Wild
Bokui Shen, Xinchen Yan, Charles R. Qi, Mahyar Najibi, Boyang Deng, Leonidas Guibas, Yin Zhou, Dragomir Anguelov
1. 既存研究では何ができなかったのか
既存研究では何ができなかったのか。 既存の研究では、人間がキュレーションした画像データセットや手動で作成されたシンセティック3D環境からのレンダリングを利用して3Dアセットを学習することができたが、遮蔽、光学条件の変化、ロングテール分布といった実世界の運転設定に関連する課題に対処できていなかった。
2. どのようなアプローチでそれを解決しようとしたか
どのようなアプローチでそれを解決しようとしたか。 著者たちは、GINA-3Dという生成モデルを導入して、カメラとLiDARセンサーからの実世界の運転データを使って、複数の乗り物や歩行者の写真のような3Dの暗黙のニューラルアセットを生成することにより、これらの課題に取り組んでいる。GINA-3Dは、画像の生成モデリングにおける最近の進歩に触発された、学習された三平面の潜在構造を用いて、表現の学習と生成モデリングを2つの段階に分離することで、これらの課題に対処している。
3. 結果、何が達成できたのか
実世界の運転データを利用したGINA-3Dモデルは、Waymo Open Datasetから収集した52万枚の乗り物と歩行者の画像から構築された大規模なオブジェクト中心のデータセット、およびパワーショベル、ゴミ収集車、ケーブルカーなどのロングテールインスタンスを含む新しい80,000枚の画像セットを評価する。このアプローチは、既存の手法と比較して、生成された画像やジオメトリの質と多様性で最先端の性能を達成できることが示されている。


Discussion