1. はじめに
E2E自動運転の開発を手がけるTuringでは、1日に20TBのデータを、データ収集車を使って集めており、これを使って自動運転のMLモデルを学習しています。データ収集のスピードは加速しているため、2025年末にはおよそ8PB(4万時間分に相当)のデータが蓄積される予定です。
この記事では、我々が、日々20TBずつ増えていくデータをいかにハンドリングしているか、そのデータエンジンの概要について紹介します。
その前に、そもそも何故8PBものデータを集めようとしているかについて簡単に説明させて下さい。我々のゴールは、東京のような複雑なシーンでも自動運転可能なNeural Network(以降、モデルと呼びます)を学習することです。良いモデルを学習するためには、モデルのアーキテクチャやパラメータの改善だけでなく、学習に用いるデータを改善することも大切です。この考え方は一般的に「データセントリックAI」と呼ばれています。このあたりの背景や詳細により興味がある方は、連載企画第1回の記事を参照ください。
「良質な」データとは?
では、「良質な」データとはどのようなデータを指すのでしょうか?
我々は、量、質、多様性の3つの要素が重要と考えています。
- 量:データのボリューム(自動運転のデータであれば走行時間)を指す。
- 質:カメラから得られた動画のフレーム飛びがないか、センサに異常値が含まれていないか、キャリブレーションのパラメータは正しいか、等、複数のメトリクスで定義される、データの品質を指す。
- 多様性:様々な状況におけるデータが含まれていることを指す。例えば、道幅の太さや道路の状況、交通エージェントの有無、日時など様々な状況が想定される。
以降では、まず、良質なデータの収集・抽出を可能とするデータエンジンのアーキテクチャ全体像を紹介し(2章)、その後、量、質、多様性のそれぞれの要素に対して工夫している点について詳細を紹介します(3章)。
2. データエンジンのアーキテクチャ
以下の図は、私たちが構築したMLOps基盤の全体像ですが、ここでは、「データセットの作成」と書かれている部分(以降、データエンジンと呼びます)に絞って説明します。
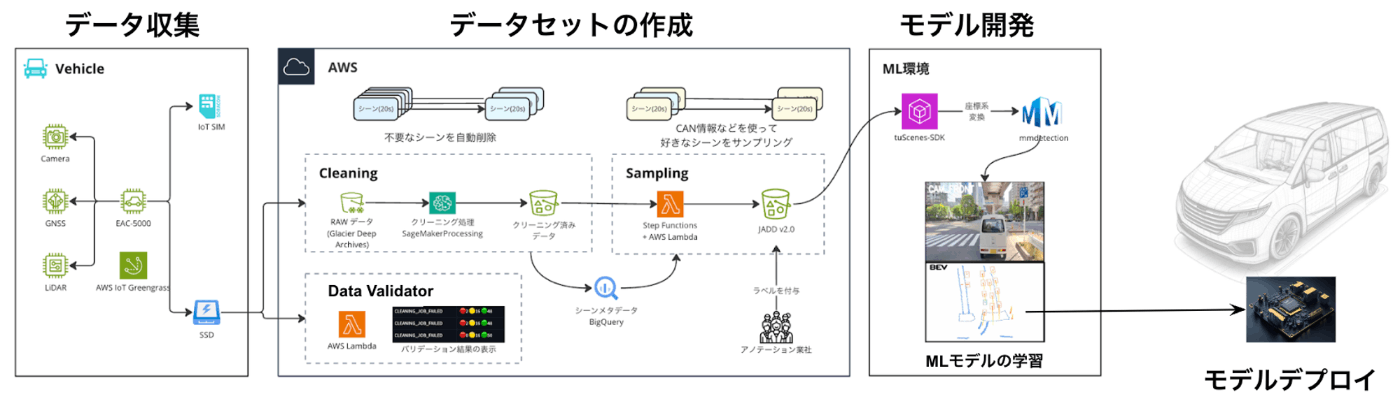
MLOps基盤の全体像
遅延評価の原則に則ったアーキテクチャ設計
データエンジンを構築するにあたって、我々は、ソフトウェアの開発でよく使われる「遅延評価(lazy evaluation)」の考え方を取り入れています。
遅延評価とは(Wikipediaより)
評価しなければならない値が存在するとき、実際の計算を値が必要になるまで行わないことをいう。(中略)ある関数を呼び出すとき、その関数が引数の全てを利用するとは限らない。条件次第で捨ててしまうような値を事前に準備することは非効率的である。このような場合遅延評価を行うと必要なときだけ値が計算されるので計算量を低減できる。
データエンジンにおける遅延評価とは、そのデータが必要となる時までは変換を行わない、ということを指します。たとえばデータ収集車からアップロードされてきた動画データは、MLモデルの学習に使うためには、動画→画像への変換や歪み補正など、様々な加工が必要となりますが、このような加工処理を、MLモデルの学習で必要とされるまではやらない、ということです。
遅延評価の考え方を取り入れているのには理由があります。
理由1:ML学習に必要なデータの予測が難しい
どのようなデータが本当に「良質な」データなのかは、データだけを見ているだけでは分からないことが多いです。実際にMLモデルを学習し、その結果を評価することによって、どのようなデータがMLの品質を向上させるかがはじめて分かることが多々あります。そのため、あらかじめ必要なデータだけを特定し、変換しておく、といったことが難しいのです。
理由2:自動運転のデータはロングテールである
収集された運転データのほとんどは類似したデータであり、特に人間の高度な判断が必要となるような場面は少なかったりします。しかし、レベル5の自動運転を実現する上では、エッジケースのデータこそが重要となります。
逆に言うと、大半の正常系のデータは、その一部のみを使うだけで、他は永遠に使われない可能性があるのです。そのため、事前に全てのデータを処理して持っておくことは、非効率的であると言えます。
この遅延評価の考え方に基づき、データエンジンを、データレイク層とデータセット層の2層で構成しています(下図参照)。データレイク層では、車両からアップロードされたデータを、扱いやすくする為に分割して最低限のクレンジングを行った後、ほぼそのままの形で保持します。また同時に、これらデータに対してメタデータを付与し、メタデータストアに格納します。
MLの学習でデータが必要になった場合、まずMLエンジニアはこのメタデータストアを参照し、必要なデータを特定します(図中①)。特定したデータはデータレイクから抽出され、その場でMLの学習に必要な形に変換が行われて、データセットレイヤに保存されます(図中②)。
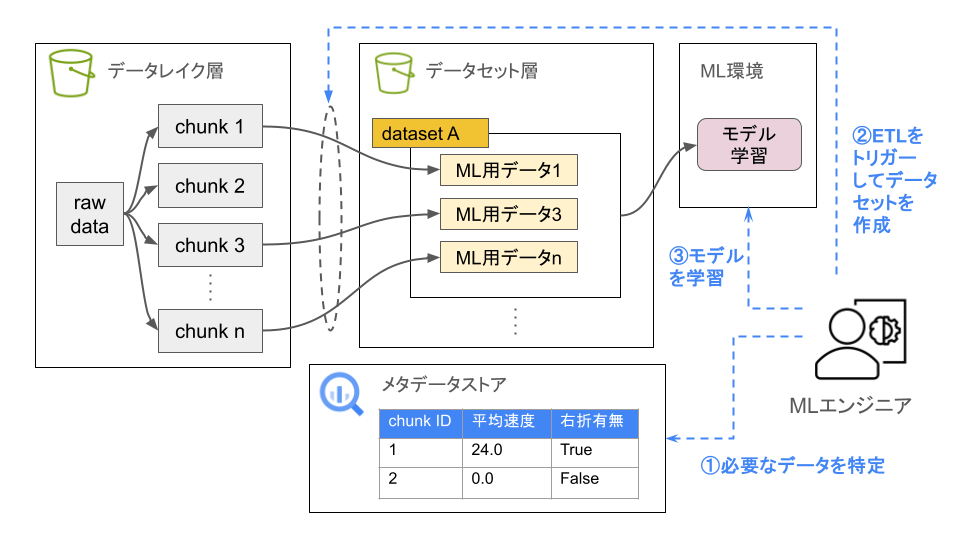
データエンジンの全体像と処理のフロー
3. データの量・質・多様性向上に向けた取り組み
データの量に対処する
20TB/日で増え続けるデータに対応するために、データエンジンの処理のほとんどは、スケールアウト可能な形で設計しています。
たとえばデータレイク層からデータセット層へのETL処理は、独立して可能な単位に分割した上で、分散処理できるようにしています。具体的には、全体をawsのStepFunctionsとLambdaを使って構成し、StepFunctionsが備えるDistributedMapの機構を用いることで、分散並列処理を実現しています。この構成によって、例えば数十時間、あるいは100時間越えのデータセットであっても、Lambdaを1,000並列で実行することで、ETL処理を数分で完了できます。
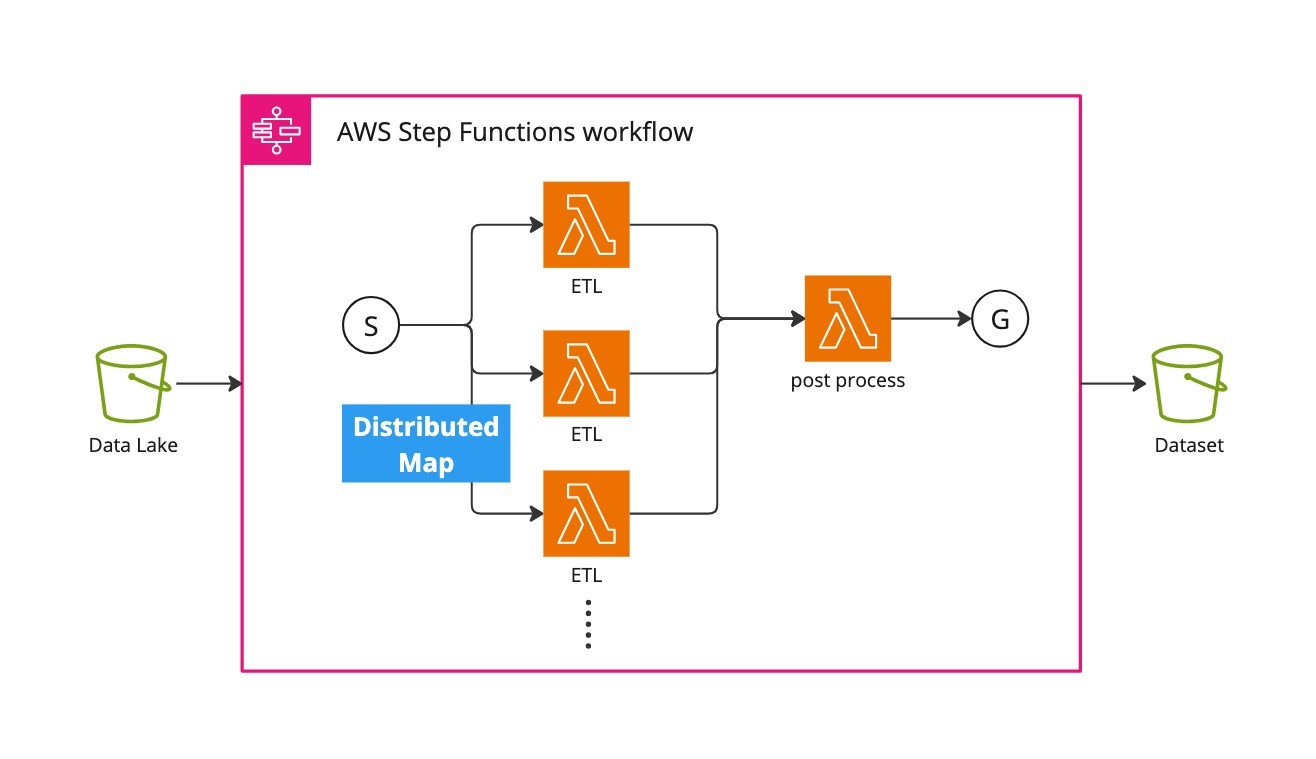
Lambdaを並列実行することで高速なETLを実現
メタデータの計算、登録処理についても同様に、ECSを活用することでスケールアウト可能な設計としています。具体的には、タスクキューを用いた構成を採用することで、将来的にアップロードされるデータ量が増えた場合であっても、Workerの数を増やすことで対応できる見込みです。
また、メタデータの計算処理の中には、CPUを使っても問題ないものと、GPUを用いた方が速く効率がよいものが混在していいます。例えば、各画像にどのような物体が写っているかといった情報をメタデータとして格納しているのですが、このような処理はMLを用いるためGPUによる高速化が期待できます。WorkerとしてCPUとGPUインスタンスの2種類を用意し、物体検知のようなGPU intensiveなタスクはGPUインスタンスで処理し、それ以外のタスクは安価なCPUインスタンスで処理する、といった構成も可能としています。
実際の実装については、まずは簡便さを優先して、queueとしてRDBのテーブルを、workerとしてAWS ECSを使っています。
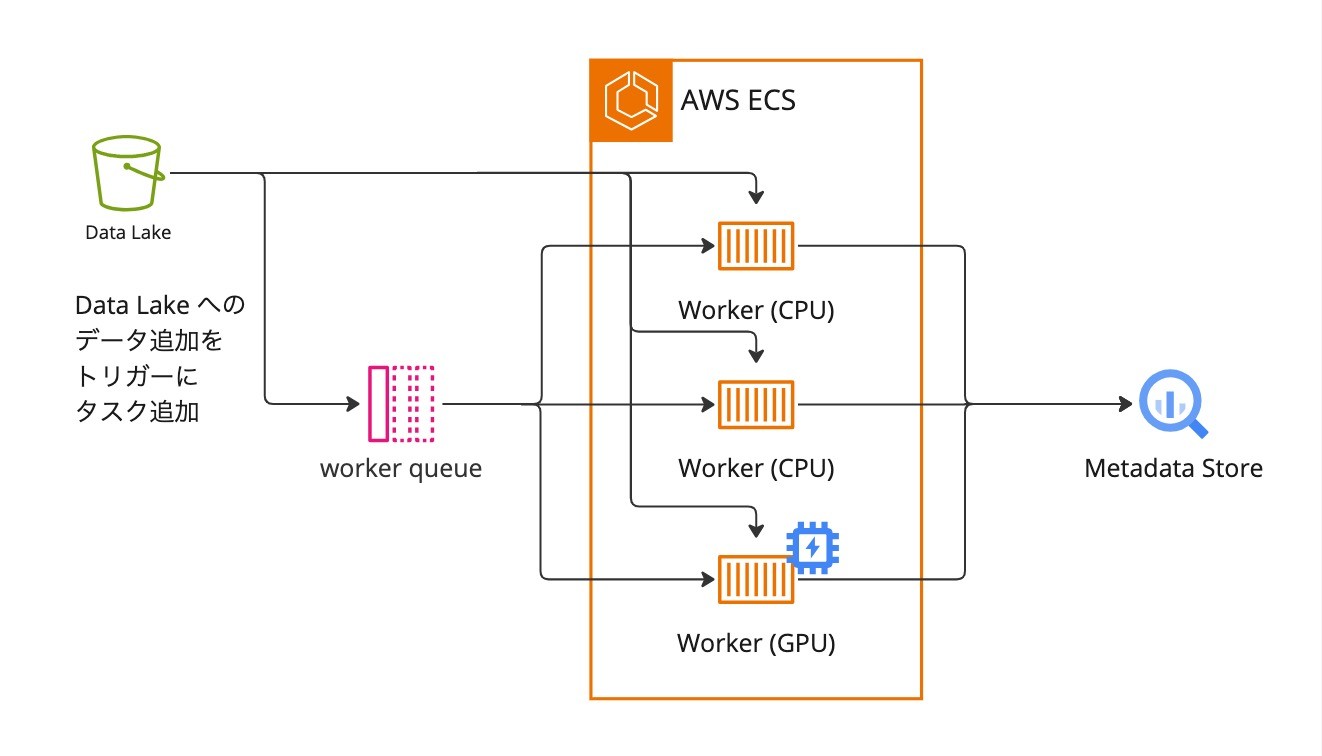
タスクキューによってスケールアウト可能なメタデータの計算・登録処理を実現
データの質に対処する
データの質を確保するために、データのValidationを実装しており、データレイク層に新しくデータが追加される度にこれが実行されます。Validationの内容としては、例えばファイルが壊れていないか、といった基本的なものから、タイムスタンプの一貫性が確保されているか、フレーム飛びはないか、といった中のコンテンツを確認するものまで様々存在し、現時点では75のチェックが実行されています。
また、Validationの結果は、以下のような社内向けのweb画面から見ることができる他、ある一定の期間ごとに、heatmapとして可視化することで、時系列を踏まえたエラーの傾向を見ることもできるようになっています。
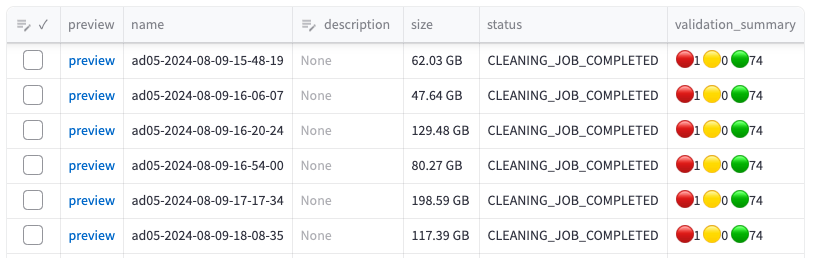
社内向けのweb画面。一番右のカラムのvalidation_summaryがvalidationの結果を表している。赤いのがエラー、黄色がwarning、緑がPassした数を表している。色が濃いほどseverityが高い。

Validation結果のheatmap表示。縦軸が日時、横軸がValidationの種類を表している。
データレイク層の時点で質の低いデータは削除すればよいのではと思う方もいらっしゃるかもしれませんが、先に述べたように、何をもって質が低いかを最初の時点で判断することは難しいため、データレイクには品質に関わらず、全てのデータを残した上で、後で品質によってフィルタリングが可能なように、品質に関するデータをメタデータとして格納しています。
これにより、データセットを作成する際に、品質のメトリクスを指定してフィルタリングすることができます。例えば車両の位置情報(以降、gnssと呼びます)の品質として、gnssの位置情報が正確に取得できているかどうか、というgnssの精度情報がmetadataとして入っており、これを使うことで、位置情報の精度が高いデータのみをフィルタリングして学習に使うといったことを可能にしています。
下図は、gnssの精度が低い経路のみを地図上にプロットしたものです。お台場周辺では、レンボーブリッジ上の経路や首都高の高架下の経路において、品質が低下していることが分かります。
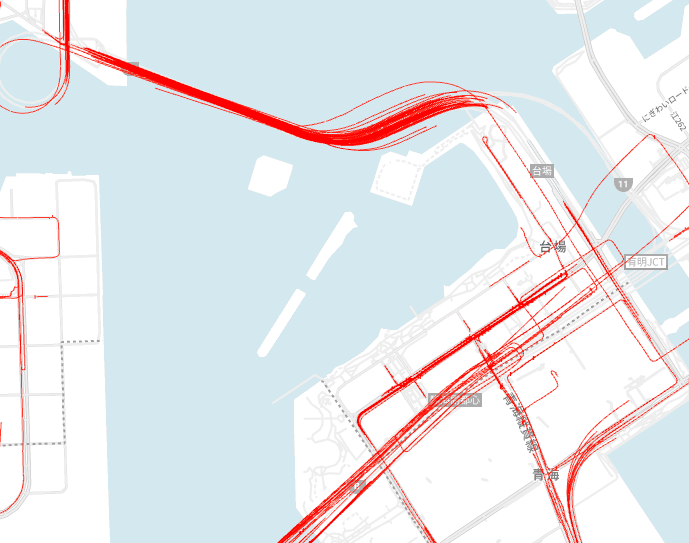
レインボーブリッジや高架下で精度が低下しやすいことが見て取れる。
多様性に対処する
データの多様性に対処するために、メタデータストアには、様々な種類の情報を格納しています。
現時点でフィルタリングに使うことができる情報としては、例えば以下のようなものがあります。
- データを取得した日時
- 取得したエリア(お台場、大崎、渋谷、など)
- 車両の走行状態(加速、原則、急ブレーキ、停止など)
- 周辺の交通オブジェクトの有無(人、車、信号機など)
- 運転の状態(右折、左折、直進、ウィンカーを出している、など)
また、これらのメタデータを作成する上でも、遅延評価の考え方を採用しています。例えば運転の状態というメタデータを作成する際には、ダウンサンプリングしたCAN(Controller Area Network、車載ネットワークを指す)のデータをメタデータとして保持しておき、そこから動的に特徴量を生成するようにしています(具体的には、SQLとして生成ロジックを記載し、ビューとして特徴量を保持しています)。こうすることで、例えば、右折というメタデータを、緩やかな右折と急な右折を別々の情報として管理したいとなった場合にも、データを再作成せず、生成ロジックを書き換えるだけで対応が可能です。
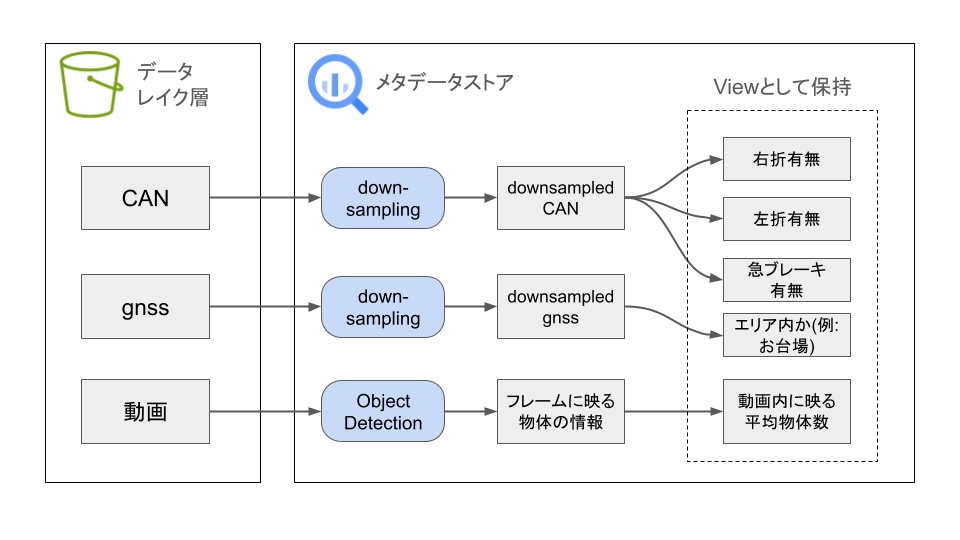
メタデータの登録処理フロー
4. おわりに
ここまで、データセントリックAIを実現するために不可欠なデータエンジンの説明をしてきましたが、これからもっと進化が必要です。例えばデータセットが増えるにつれ、重複が多くなり無駄も増えるため、ETLしたデータをキャッシュする機構が必要になると予想しています。また、今回はデータエンジンに焦点を当てましたが、MLOpsというより広い範囲で考えると、特定のデータセットから作成されたモデルとその学習・推論の結果を保存・トラッキングする仕組み(実験管理)や、Active Learningの機構の導入など、やるべきことはまだまだあります。
膨大かつ様々なモダリティのデータを扱う、データエンジン、MLOps基盤の開発に興味があるソフトウェアエンジニアがいましたら、ぜひ@myasumotoまで連絡下さい。カジュアル面談やオフィス見学などライトな交流も大歓迎です。

Discussion