
VLM学習のための「Text-Printed Image」手法。テキストを画像化することでモダリティギャップを緩和しより効果的に学習できるようにする。
はじめに
チューリングでインターンをしている東京科学大学(Institute of Science Tokyo)の山辺です。
インターンでは、「画像を一切使わずに VLM を学習できるか?」というテーマで研究を進め、その成果を論文としてまとめて arXiv に投稿しました。画像付きデータを大量に集めるのではなく、テキストだけをうまく活用して VLM を学習させる、という少し変わったアプローチに取り組んでいます。論文はすでに公開されており、こちらのリンクから全文をご覧いただけます。
事前知識:TuringのVLMに対する取り組み
Turingでは自動運転に向けて、いわゆる E2E(End-to-End) モデルの活用を進めています。これは、カメラなどのセンサー入力から、最終的な運転行動までを一気通貫で出力するアプローチです。
一方で、現実の交通環境には 「頻度は低いけど難しい」状況 がたくさんあります。たとえば、工事現場で交通誘導員が立っているケースのように、ルールが固定ではなく、その場の文脈理解が強く求められるシーンです。こうした稀な、難しいシナリオには、E2Eだけで対処するのが難しいことがあります。

E2Eでは状況把握が困難な状況の例 (https://huggingface.co/datasets/turing-motors/Japanese-Heron-Bench)
そこで期待されるのが VLM です。VLM なら、シーンを
「工事現場で、近くの交差点で、白いヘルメットを被った男性が交通整理をしている」
のように言語で説明して理解することができます。この判断に基づいて運転行動を選択することにより、複雑な状況への対応力を上げることが期待されます。
このような未来を実現するために、Turing ではVLM開発にも取り組んでいます (詳細)。
モチベーション:特殊な状況ほど、画像データが集まらない
VLM を学習するには、通常画像データが必要です。しかし、VLMを活用したいような特殊な状況ほど、画像データが豊富にあるとは限りません。
特に難しいのは、事故が発生する直前のようなシナリオです。このようなシナリオでは、そもそもデータ収集自体が危険で、再現も難しいという問題があります。極端な例として「車が飛んでくる」ような事故寸前の状況を考えると、その場面のデータを現実から学習に十分な量を集めるのはほぼ不可能に近いです。
また、交通ルールが変わった場合にも問題が起きます。ルールの変更後に、改めてデータを集め直すのには時間がかかり、即時の対応が困難になります。自動運転車を現実的に運用していくことを考えると、解決策が必要不可欠です。
アイデア:テキストだけでVLMを学習しよう!
そこで着目したのがVLMをテキストデータだけで学習する、 text-centric training です。
テキストなら、人手で作ることもできますし、LLMを使って自動生成することもできます。たとえば、
・事故直前の危険シナリオを文章で記述する
・新しいルールに沿った状況説明を作る
・レアケース(工事・緊急車両・誘導員など)を意図的に増やす
といったことが実現可能になり、VLMを活用したい「頻度は低いけど難しい」状況に対応するような学習データを生成することができます。
難しさ:画像とテキストの間にあるモダリティギャップ
ただし、テキストをそのまま利用して学習しても、十分な効果が得られないことがあります。理由は、画像とテキストではモデルが受け取る入力の形式が異なり、モデル内部で得られる特徴量の分布も大きくズレるためです。このズレは モダリティギャップ(modality gap)[1] と呼ばれます。
まず、事前知識としてVLMは通常、画像を画像エンコーダ(例:ViTなど)、テキストをテキストエンコーダで特徴量に変換し、その特徴量を手がかりに言語モデルが推論・生成します。

VLMアーキテクチャの例
一方、テキストをそのまま入力する場合、その情報は画像エンコーダ側の出力を経由せず、テキストエンコーダを経由するため、特徴量に大きな乖離が生じます。そのため、モデルは「画像特徴量をどう読み取り、言語に接続するか」という回路を十分に学習できません。
その結果、テキスト理解自体は進んでも、画像を見て答えるべきタスクでは学習効果が限定的になりがちです。つまり、テキストをそのまま使うだけでは、画像モダリティ上で必要な推論がうまく学習できず、性能向上につながりにくい、という問題が起きます。
手法:Text-printed Image
そこで提案したのが Text-Printed Image(TPI) です。やることはシンプルで、テキストを画像としてレンダリングします。白いキャンバスに文章を印字した画像を作り、それを「画像」として VLM に入力できる形に変換します。

Text-printed Imageの例
この単純明快な方法が、データ生成という観点で重要な要件を満たします。
1. あらゆる LVLM に即時適用できる
TPI は “ただの画像” なので、既存の学習パイプラインにそのまま組み込むことができます。追加の変換器や特別なモデル設計を要する先行研究[1,2,3]と比較してより実用的です。
2. テキストが持つセマンティクスを維持できる
Text-to-Image model(拡散モデルなど)で画像を生成すると、テキストの内容と生成画像が完全に一致しないことがあります。一方でTPIはテキストをそのまま使用して画像を生成するため、セマンティクスを保持し、より高品質な画像を生成することができます。
3. データ生成が簡単で高速
レンダリングは軽量で、GPU を使わずに作れるため高速です。一般的にVLMの学習には膨大な量のデータを必要とするため、この効率の良さが実用性を確保します。
以上のように、TPI は「テキストの意味を保ったまま入力を画像側に寄せる」ことで、モダリティギャップの影響を抑えつつ、既存の VLM 学習パイプラインにそのまま載せられる点が特徴です。
実験
では実際に、実画像を用いた通常の学習に比べて、テキストのみを用いた提案手法による学習(text-centric training)がどの程度の性能を発揮するのか、実験で検証を行います。
実験設定
データセット
性能比較のために、以下の3種類のデータセットを使用します。
- General VQA:一般的な性能を測定するベンチマークとして、ScienceQA[4], OK-VQA[5], VizWiz[6]を使用します。
- Text VQA:文字情報を含む画像を対象とするベンチマークとして、ChartQA[7]、InfoVQA[8]、DocVQA[9]を使用します。
- Domain-specific VQA:より応用的なタスクとして、自動運転ベンチマークであるDriveLM[10]を使用します。
また、各タスクで提供されている学習用データセットをモデルの訓練に使用します。これらのデータにはオリジナルの画像が含まれているため、これをGround Truthとして用い、 Qwen2.5-VL-32B により画像からテキストを抽出します。
ベースライン
比較のためのベースラインとして以下の手法を使用します:
- Text-only:テキストをそのまま使って学習
- Text-to-Image:Stable Diffusion XL 1.0 でテキストから画像生成し、学習に使う
- GT-Image:各タスクにおいて提供されている学習用の画像をそのまま使用して学習
このうち、GT-Imageだけはテキストではなく、実際の画像を使用しているため、「本物の画像を用いた学習と比較してどれくらい性能が向上するか?」を評価するためにベースラインとして用いています。
学習による性能向上の比較結果

Text-printed Imageによる性能向上の比較。各値は各タスクにおける精度を示します
この結果から、以下の点が明らかになりました。
- モダリティギャップによりテキストをそのまま用いた学習(Text-only)の効果は限定的:Text-only では、多くのモデル・タスクにおいて性能向上が十分ではありません。これは、前述のモダリティギャップにより、学習時に入力するテキストと推論時に入力する画像の間に大きな違いが生じ、画像を前提とした推論に必要な学習が進みにくいことが一因だと考えられます。
- Text-to-Image は数字・文字の生成が苦手なため一部のタスクでは効果が限定的:Text-to-Image は、ChartQA/InfoVQA/DocVQA で効果が低下しています。これらのタスクでは、数字や文字を含む画像を正確に生成する必要がありますが、Text-to-Image はそのような生成が得意ではなく、結果として学習に使える品質の画像を作りにくいことが原因だと考えられます。
- Text-Printed Image は高い性能向上を示す:上記ベースラインの限界を踏まえると、Text-Printed Image が最も大きな性能向上を達成していることが分かります。さらに、一部のモデル・タスクでは GT-Image に迫る改善も見られ、Text-Printed Image が有望な方向性であることを示唆しています。
t-SNEによる特徴量の比較結果
さらに、定性的な評価としてText-printed Imageの特徴量がテキストと比較してどれほどオリジナル画像に近づいているのかも確認してみました。特徴量がオリジナル画像に近いほど、モダリティギャップを解消し、学習データとして適切であることを示唆します。入力データを LVLM に通して得られる特徴量に対して t-SNE を適用し、分布の違いを可視化します。

入力特徴量に対するt-SNEによる可視化
モダリティギャップによりTextデータの特徴量はGT-Imageの分布から大きく離れやすい一方で、Text-printed ImageはよりGT-Imageに近い場所に位置しています。
この結果から、Text-printed Imageによりモダリティギャップが緩和された可能性が示唆されます。
データ拡張への応用
ここまでの実験では、各タスクに付属する学習データに含まれるGround Truth 画像からテキストを抽出し、そのテキストを用いて学習を行ってきました。しかし実運用上ではそのような画像は限られています。
そこで、より実用的な設定として 少数データから人工テキストデータを生成するデータ拡張における実験を行います。
Self-Instruct によるテキスト生成
今回は、LLM向けのデータ拡張手法として知られる Self-Instruct[11] をベースに、与えられた学習データから追加のテキストデータを自動生成します。設定として以下を使用します。
- 生成モデル:GPT-4o-mini
- 生成回数:10,000 サンプル
- 重複・類似の除去:ROUGE-L を用いて、既存データと似通った生成結果をフィルタリング
既存の学習データとほぼ同じ文面を増やしても多様性が増えないため、ROUGE-L によるフィルタリングで「新規性の低いサンプル」を取り除き、より多様なテキストを確保することを狙っています。
シードデータが少数の場合の結果
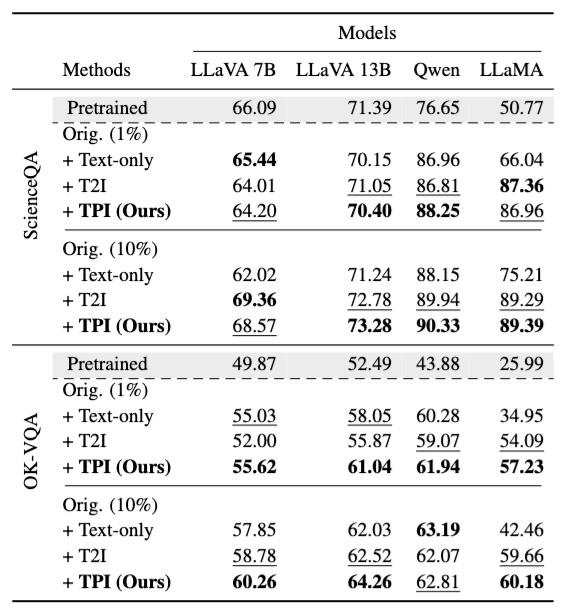
少数の学習データからデータを拡張した時の実験結果
結果を見ると、オリジナルの学習データの一部しか与えられない場合でも性能が向上していることが分かります。特に OK-VQA では、すべてのモデルにおいて大きな性能向上が確認できました。
これは、少数データ環境でも人工的に生成したデータが有効な学習信号として機能していることを示唆しています。
シードデータが完全な場合の結果

完全な学習データからデータを拡張した時の実験結果
さらに、シードデータとして完全な学習データが与えられた場合でも、追加のテキスト生成によりさらなる性能向上を実現できることが分かります。
単に「データが少ないときの穴埋め」だけでなく、十分なデータがある状況でも改善余地があるのは興味深いです。
限界と今後の方向性
一方で、タスクやモデルによっては効果が限定的なケースも見られました。
この要因として、今回の拡張手法がLLM向けの Self-Instruct をほぼそのまま適用したものであり、VLM特有の要請との間にギャップがある可能性が考えられます。今後は、VLM向けのデータ拡張手法を新たに構築していくのが研究の方向性として面白いと考えています。
おわりに
本記事では、インターンで取り組んだ 「画像なしで VLM を学習する」 というテーマについて、背景・モチベーションから手法、実験を紹介しました。
画像データが集めづらい特殊で重要な状況に対して、テキストをうまく使って学習を前に進めるための一つの実装として、提案手法はシンプルで扱いやすい選択肢になり得ると考えています。
興味がある方は、ぜひ論文もご覧ください:
謝辞
メンターとして常に的確なアドバイスと温かいご支援をくださった高橋さんに、深く感謝申し上げます。また、同じインターンとして日々の研究において多くのご助言をいただいた早稲田さん、塩野さんにも、心より感謝申し上げます。さらに、研究に集中できる素晴らしい環境をご提供くださったチームの皆様にも、厚く御礼申し上げます。このような貴重な機会を賜りましたこと、誠にありがとうございました。
参考文献
[1] Yuhui Zhang, Elaine Sui, and Serena Yeung. Connect, collapse, corrupt: Learning cross-modal tasks with uni-modal data. In The Twelfth International Conference on Learning Representations, 2024.
[2] Liang, Victor Weixin, et al. "Mind the gap: Understanding the modality gap in multi-modal contrastive representation learning." Advances in Neural Information Processing Systems 35 (2022): 17612-17625.
[3] Yu, Xiaomin, et al. "Unicorn: Text-only data synthesis for vision language model training." arXiv preprint arXiv:2503.22655 (2025).
[4] Lu, Pan, et al. "Learn to explain: Multimodal reasoning via thought chains for science question answering." Advances in Neural Information Processing Systems 35 (2022): 2507-2521.
[5] Marino, Kenneth, et al. "Ok-vqa: A visual question answering benchmark requiring external knowledge." Proceedings of the IEEE/cvf conference on computer vision and pattern recognition. 2019.
[6] Gurari, Danna, et al. "Vizwiz grand challenge: Answering visual questions from blind people." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
[7] Masry, Ahmed, et al. "ChartInstruct: Instruction Tuning for Chart Comprehension and Reasoning." Findings of the Association for Computational Linguistics ACL 2024. 2024.
[8] Mathew, Minesh, et al. "Infographicvqa." Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2022.
[9] Mathew, Minesh, Dimosthenis Karatzas, and C. V. Jawahar. "Docvqa: A dataset for vqa on document images." Proceedings of the IEEE/CVF winter conference on applications of computer vision. 2021.
[10] Sima, Chonghao, et al. "Drivelm: Driving with graph visual question answering." European conference on computer vision. Cham: Springer Nature Switzerland, 2024.
[11] Wang, Yizhong, et al. "Self-instruct: Aligning language models with self-generated instructions." Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers). 2023.

Discussion