Difyでpdfファイルを読み込めるようなブロックを作成してみよう
皆さん、Difyは使っていますか?difyはローコードでエージェント、RAG等のアプリを簡単に作成でき、アプリの使用状況や仕組みの裏側まで簡単に見れるので非常に便利です!
一点気になるのが執筆時点(2024年6月)ではpdfファイルの入力には対応していません。業務上pdfファイルの分析をしてほしい、みたいな場面多いですよね?
しかし一工夫するとローカルや共有フォルダーのpdfファイルを読み込めるようなブロックを作れます!
仕組み
仕組みとしては以下のようになります。
- Difyにファイルパスを入力
- 自前で建てたpdf読込サーバーにファイルパスを送信
- サーバーでファイルを分析、テキストを抽出して返す
- テキスト分析開始!
やっていきましょう!
0. Difyをローカルで建てる
まずDifyをローカルで建てる必要があります!
これは他の方のを参考にお願いします。
ファイルパスはDifyが建てられているPCからアクセスできないといけないので自身のPCか共有フォルダーである必要があります。自分はwslで建てています。
1. Difyにファイルパスを入力
Difyを建てられたらワークフローでアプリを作成していきます。
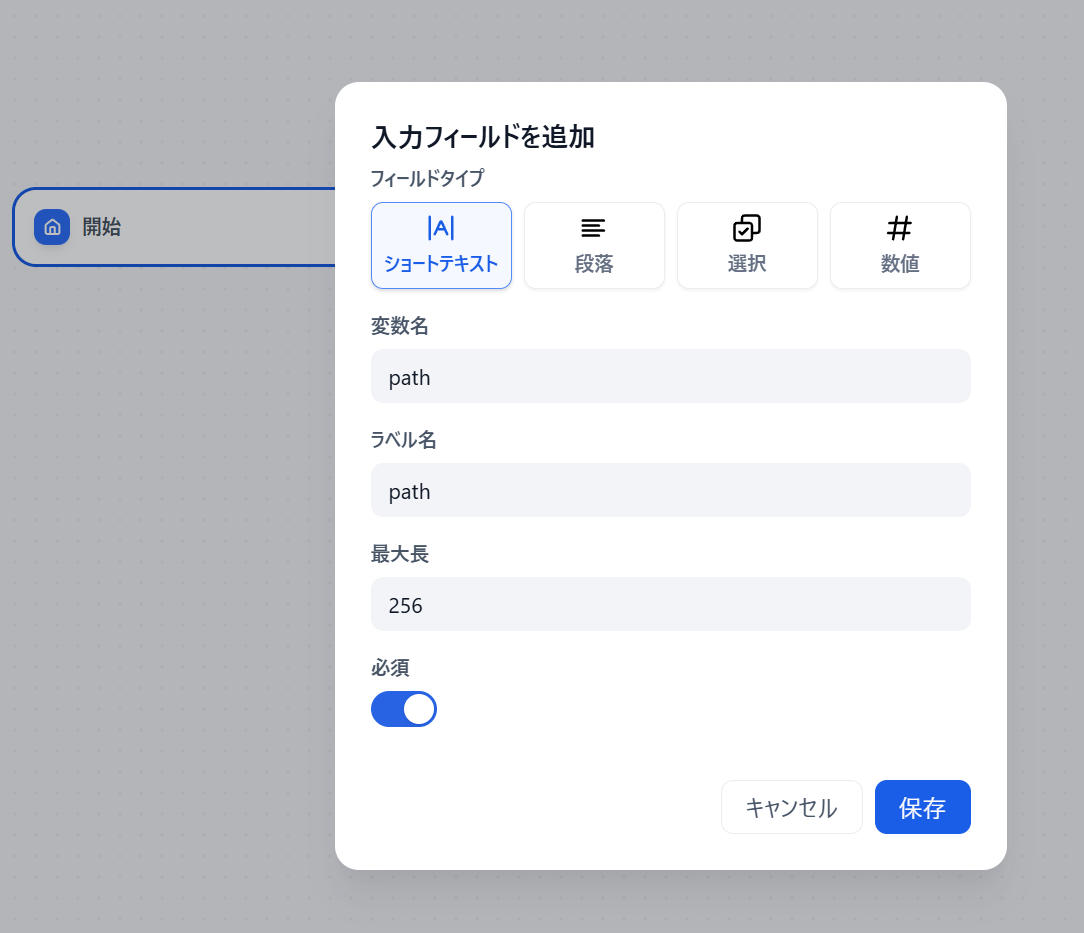
開始ブロックにフィールドタイプはショートテキストで変数名はpathとしています。
2. 自前で建てたサーバーにファイルパスを送信
サーバーにファイルパスを送るのはコードブロックを使用します。
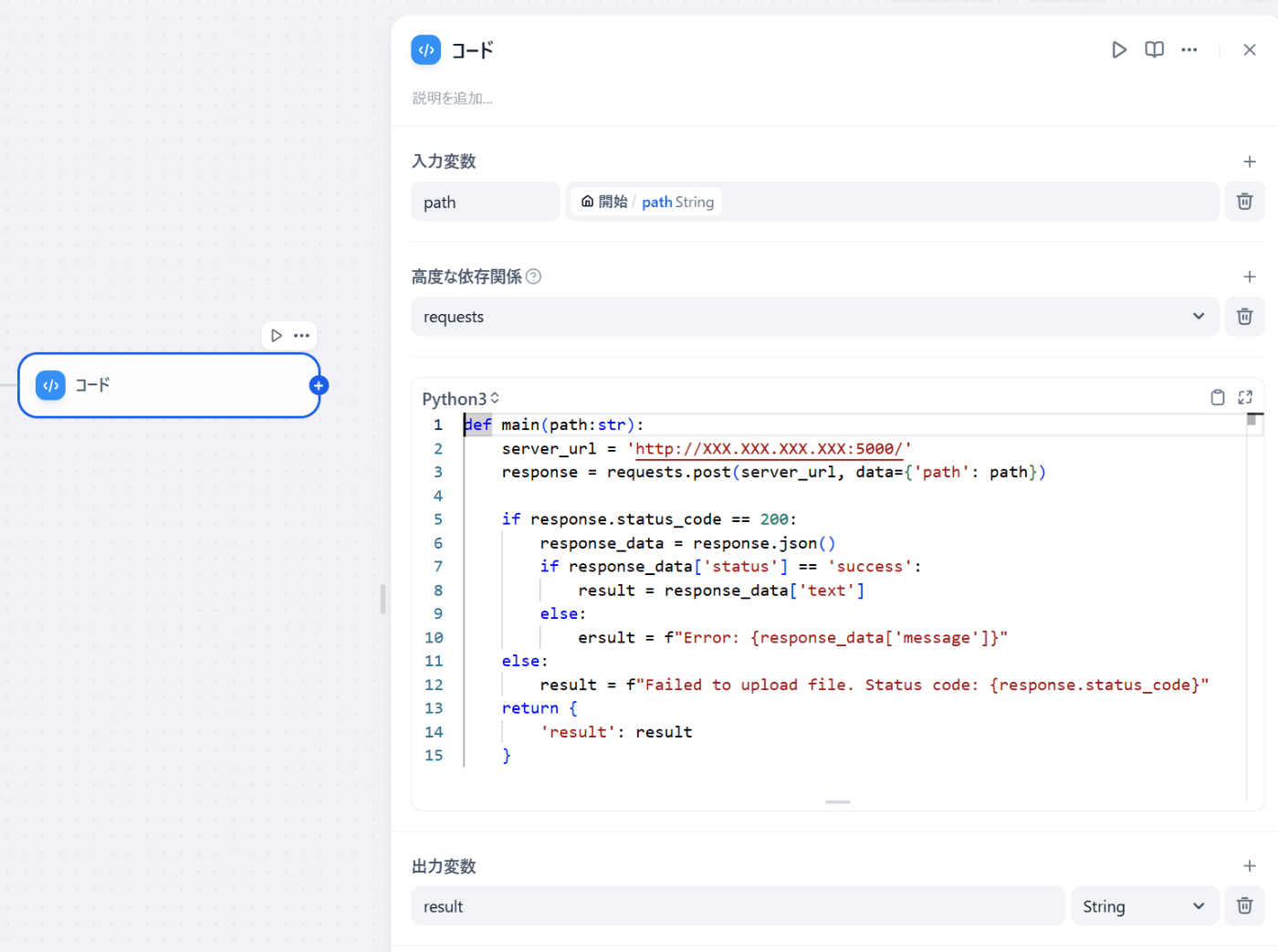
入力変数は先程指定したpathです。
高度な依存関係でrequestsを選択します。
コードはpython3で以下になります。
このコードはサーバーにパスを送って、サーバー側で読み取り成功すればpdfのテキストをゲットして、失敗したらエラーメッセージを出す、ということになっています。
def main(path: str):
# サーバーのURLを設定
server_url = 'http://XXX.XXX.XXX.XXX:5000/'
# サーバーにPOSTリクエストを送信し、ファイルパスを渡す
response = requests.post(server_url, data={'path': path})
# HTTPステータスコードが200(成功)かどうかを確認
if response.status_code == 200:
response_data = response.json()
# ステータスが'success'かどうかを確認
if response_data['status'] == 'success':
# テキストを結果として取得
result = response_data['text']
else:
# エラーメッセージを結果として取得
result = f"Error: {response_data['message']}"
else:
# HTTPリクエストが失敗した場合のエラーメッセージ
result = f"Failed to upload file. Status code: {response.status_code}"
# 結果を辞書形式で返す
return {
'result': result
}
server_urlは次で説明するpdf読込サーバーのipアドレスを指定してください。
出力変数はresultです。
3. サーバーではファイルパスを受け取ったらファイルを分析、テキストを返す
pdf読み取りサーバーはDifyと同じPCで建てて構わないです。
パッケージのダウンロード
pip install flask request jsonify pypdf2
pypdfでpdfを読み込むサーバーをflaskで建てます
コードは以下になります。
from flask import Flask, request, jsonify
from PyPDF2 import PdfReader
# Flaskアプリケーションのインスタンスを作成
app = Flask(__name__)
# ルートエンドポイントを定義し、POSTリクエストを処理
@app.route('/', methods=['POST'])
def upload_file():
response_data = {}
pdf_path = request.form['path'] # クライアントから送信されたPDFファイルのパスを取得
if pdf_path: # PDFファイルのパスが提供されているかを確認
try:
with open(pdf_path, 'rb') as pdf_file: # 指定されたパスからPDFファイルを読み込む
reader = PdfReader(pdf_file)
text = ""
for page in reader.pages: # PDFの全ページからテキストを抽出
text += page.extract_text()
response_data['status'] = 'success' # 処理が成功した場合のステータスを設定
response_data['text'] = text
except Exception as e: # エラーが発生した場合の処理
response_data['status'] = 'error'
response_data['message'] = str(e)
else:
response_data['status'] = 'error' # ファイルパスが提供されなかった場合のステータスを設定
response_data['message'] = 'No file path provided'
return jsonify(response_data) # レスポンスデータをJSON形式で返す
if __name__ == '__main__':
# 自身のIPアドレス(0.0.0.0)とポート5000でアプリケーションを起動
app.run(host='0.0.0.0', port=5000, debug=True)
サーバーを実行!
python XXX.py
4. テキスト分析開始!
ここからはそれぞれ好きなようにブロックを作っていく形になります!
テキスト抽出だったり、LLMに読み込ませたり…。pdfを読み込ませられると一気にアプリの幅が広がりますね!
まとめ
ここまでお読みいただきありがとうございます。pdfファイルを扱うシナリオは、ビジネスの現場でよくあることです。今回の方法を応用することで、Difyの機能を拡張し、より多様なデータソースに対応できるようになります。是非、試してみてください。今後もDifyを活用した効率的なアプリ開発を目指して、引き続き学びを深めていきましょう。
このブログが皆さんのプロジェクトに役立つことを願っています。質問やフィードバックがありましたら、ぜひコメントでお知らせください。それでは、良い開発ライフを!
Discussion