Mac上でLangChainとChromaデータベースを使ったベクトル検索を試す
はじめに
大規模言語モデル:Large Language Models(以下、LLM)を利用した質疑応答タスクでは、LLMが学習した時点より後の情報に基づく回答は生成できない、ハルシネーション(幻覚)と呼ばれる現象で、事実に基づかない回答を生成するなどの問題があります。その対策としてRAG(Retrieval-Augmented Generation)と呼ばれる技術があります。これは、外部情報ソースから取得した情報を用いて、LLMの精度と信頼性を向上させます。
特に、筆者が注目しているようなオンデバイスのLLMでは、比較的サイズの小さいLLMを利用するところから、RAGによりLLMの能力を補うことはとても重要です。
ところで、LLMに対して一回に入力できるデータには制限があるため、外部から取得した情報をいくらでも入力できるわけではありません。そのため、RAGでは、ユーザーの質問内容にLLMが答えられそうな情報ソースを小さいサイズの塊として抽出する必要があります。このために利用する技術の代表が、本記事のテーマであるベクトル検索です。ベクトル検索がどのようなものかをデモンストレーションするアプリケーションを作り、Mac上で実際に動作させる方法を紹介します。
ベクトル検索
外部情報ソースと言っても色々ありますが、本記事で紹介するベクトル検索アプリケーションでは、ウェブページ内のテキストを情報ソースとします。処理の流れは大まかに以下のとおりです。
- 指定したウェブページからテキスト情報を抽出
- 抽出したテキスト情報をチャンクと呼ばれるブロックに分割(ブロックのサイズはチャンクサイズ、次のチャンクとの重なるサイズはオーバーラップとして指定する)
- チャンク毎に埋め込み(Embedding)表現と呼ばれるベクトル値[1]に変換
- ユーザーの質問文を埋め込み表現(ベクトル値)に変換
- 質問文のベクトルと、各チャンクのベクトルの類似度を計算[2]
- 最も高い類似度を持つチャンク上位N個を求める
上記のとおり、テキストをそのまま比較せずに、埋め込み表現にすることにより、単語がそのままマッチングしなくても、共起しやすい単語同士は高い類似度が期待できます。たとえば、「たぬき」が含まれる文章と「きつね」が含まれる文章はおそらく高い類似度が期待できます。「俳句」と「松尾芭蕉」、「横浜」と「中華街」にも、もしかしたら高い類似度が存在するかもしれません。[3]
また、非常に高速に検索できるのもベクトル検索の特長です。
アプリケーションの構成
本記事で紹介するアプリケーションでは、LangChainから、Chromaデータベースを利用することでベクトル検索を実現します。GUIは、前回投稿記事、前々回投稿記事と同様に、Gradioを利用しました。埋め込み表現の生成は、LangChainから、Sentence Transformersを利用しています。埋め込み表現を生成するモデルには、Hugging Face Hubで公開のSentence Similarityタスク向け日本語対応モデルが利用可能と思われます。今回はその中からsentence-transformers/distiluse-base-multilingual-cased-v2を利用させていただきました。
アプリケーションのソースコード
import gradio as gr
from huggingface_hub import hf_hub_download
from langchain.document_loaders import WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
# from langchain.embeddings import HuggingFaceEmbeddings
from langchain_huggingface import HuggingFaceEmbeddings
import pandas as pd
import json
CHUNK_SIZE = 256
CHUNK_OVERLAP = 64
PERSIST_PATH = "./.chroma_db"
HF_MODEL_NAME = "sentence-transformers/distiluse-base-multilingual-cased-v2"
COLLECTION_NAME = "langchain"
# 埋め込み表現生成用モデルをHugging Face Hubから取得
embeddings = HuggingFaceEmbeddings(model_name=HF_MODEL_NAME)
# Chromaデータベースを生成
vector_store = Chroma(
COLLECTION_NAME,
persist_directory=PERSIST_PATH,
embedding_function=embeddings,
collection_metadata={"hnsw:space": "cosine"}
)
# Chromaデータベースからattrで指定したメタデータリストを取得し、コレクション名をキーとした辞書で返す
def get_metadata_values(attr):
info_dict = {}
for collection in vector_store._client.list_collections():
data = [meta[attr] for meta in collection.get()["metadatas"] if attr in meta.keys()]
info_dict[collection.name] = data
return info_dict
# Chromaデータベースに格納されているベクトルデータの数を取得し、コレクション名をキーとした辞書で返す
def get_num_docs():
info_dict = {}
for collection in vector_store._client.list_collections():
ids = collection.get()["ids"]
info_dict[collection.name] = len(ids)
return info_dict
# 指定したURLからベクトルデータを作成する
def make_vector_db(url):
global vector_store
sources = get_metadata_values("source")[COLLECTION_NAME]
if url in sources:
gr.Info("ベクトル情報が既に存在します")
return (gr.update(interactive=True, value=""), gr.update(interactive=True))
gr.Info("ベクトル情報を作成しています")
try:
loader = WebBaseLoader(url)
data = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=CHUNK_SIZE, chunk_overlap=CHUNK_OVERLAP
)
all_splits = text_splitter.split_documents(data)
vector_store = Chroma.from_documents(
documents=all_splits, embedding=embeddings,
persist_directory=PERSIST_PATH
)
except Exception as e:
raise gr.Error(str(e))
gr.Info(f"ベクトル情報の作成を完了しました。{str(get_num_docs())}")
return (gr.update(interactive=True, value=""), gr.update(interactive=True))
# queryで指定した文章と高い類似度を持つ上位k個の結果を返す
def vector_search(query, k):
docs = vector_store.similarity_search_with_relevance_scores(query, k=k)
headers = ["文章", "スコア", "メタデータ"]
l2d = [
[doc[0].page_content]
+ [doc[1]]
+ [json.dumps(doc[0].metadata, ensure_ascii=False)]
for doc in docs
]
df = pd.DataFrame(l2d, columns=headers)
return df
# Chromaデータベースからコレクションを削除する
def reset_db():
for collection in vector_store._client.list_collections():
if collection.name == COLLECTION_NAME:
ids = collection.get()['ids']
print('Removing %s document(s) from %s collection' % (str(len(ids)), collection.name))
if len(ids):
collection.delete(ids)
return (gr.update(interactive=False, value=""), gr.update(interactive=False))
with gr.Blocks() as demo:
ndocs = get_num_docs()[COLLECTION_NAME]
with gr.Row():
url = gr.Textbox(value="", label="情報ソースURL", scale=5)
vect_btn = gr.Button(value="ベクトル化")
examples = [
"https://zenn.dev/guideline",
"https://ja.wikipedia.org/wiki/コンピュータ",
"https://www.aozora.gr.jp/cards/000081/files/43754_17659.html"
]
gr.Examples(examples, url, label="情報ソースURLの例")
with gr.Row():
flg = True if ndocs > 0 else False
query = gr.Textbox(value="", label="質問", interactive=flg, scale=5)
query_btn = gr.Button(value="検索", interactive=flg)
with gr.Row():
rst_btn = gr.Button(value="ベクトル情報をリセット")
k_val = gr.Number(value=4, label="抽出数", minimum=1, maximum=100)
results = gr.Dataframe(
row_count = (1, "dynamic"),
col_count=(3, "fixed"),
label="検索結果",
headers=["文章", "スコア", "メタデータ"],
wrap=True
)
# 「情報ソースURL」テキストフィールドでリターンキーを押した時および
# 「ベクトル化」ボタンをクリックした時のイベントハンドリング
gr.on(
triggers=[url.submit, vect_btn.click],
fn=make_vector_db,
inputs=url,
outputs=[query, query_btn]
)
# 「質問」テキストフィールドでリターンキーを押した時および
# 「検索」ボタンをクリックした時のイベントハンドリング
gr.on(
triggers=[query.submit, query_btn.click],
fn=vector_search,
inputs=[query, k_val],
outputs=results
)
# 「ベクトル情報をリセット」ボタンをクリックした時にイベントハンドリング
rst_btn.click(fn=reset_db, inputs=None, outputs=[query, query_btn])
demo.queue().launch()
ソースコードに関する補足
langchain.vectorstores.Chromaクラスのコンストラクタで渡しているパラメータ collection_metadata={"hnsw:space": "cosine"} は重要です。このパラメータを渡さないと、類似度検索が正しく動作しません。[4]
アプリケーションの実行
- MacBook Air M2チップモデル(16GBメモリ)上で動作確認しましたが、macOS固有のライブラリなどは使用していないため、他のプラットフォーム上でも動作可能と思います。
環境セットアップ
- 前々回投稿記事の「環境セットアップ」のとおり、環境を構築します。
- 構築した環境を有効化するのを忘れずに
conda activate devchat - 追加で、以下のとおり、ライブラリをインストールします。
pip install langsmith langchain chromadb bs4 sentence_transformers langchain-huggingface
実行
- 構築した環境を有効化するのを忘れずに
conda activate devchat - アプリケーションの起動
python gr_vect_search.py - 以下のようなメッセージが出力されたら、http://127.0.0.1:7860 をウェブブラウザで開きます。
Running on local URL: http://127.0.0.1:7860 To create a public link, set `share=True` in `launch()`. - 「情報ソースURL」テキストボックスにウェブページのURLを入力し、リターンキーを押します(または、「ベクトル化」ボタンをクリックします)。ウェブページのテキストデータがベクトル化されChromaデータベースに格納されます。
- 「質問」テキストボックスに質問を入力し、リターンキーを押します(または、「検索」ボタンをクリックします)。
- 「検索結果」データフレームに検索結果が表示されます。アプリケーション起動後最初の表示はレイアウトが崩れます。データフレームをスクロールすると正しいレイアウトで表示されます。2回目以降の表示ではこの問題は発生しません。
注意点
- 検索結果の抽出数は「抽出数」フィールドで調整できます。
- アプリケーションを起動したパス直下の .chroma_db フォルダにChromaデータベース永続化用データが保存されます。アプリケーション起動時、このフォルダからデータベースへデータが読み込まれます。アプリケーションのソースコードを変更して、前回起動時とデータの整合性が保てなくなる場合[5]は、アプリケーション起動前に .chroma_db フォルダを削除してください。
- 「ベクトル情報をリセット」ボタンをクリックするとChromaデータベースからすべてのデータが削除されます。 .chroma_db フォルダは削除されませんが、このフォルダ内のデータも削除されます。
例
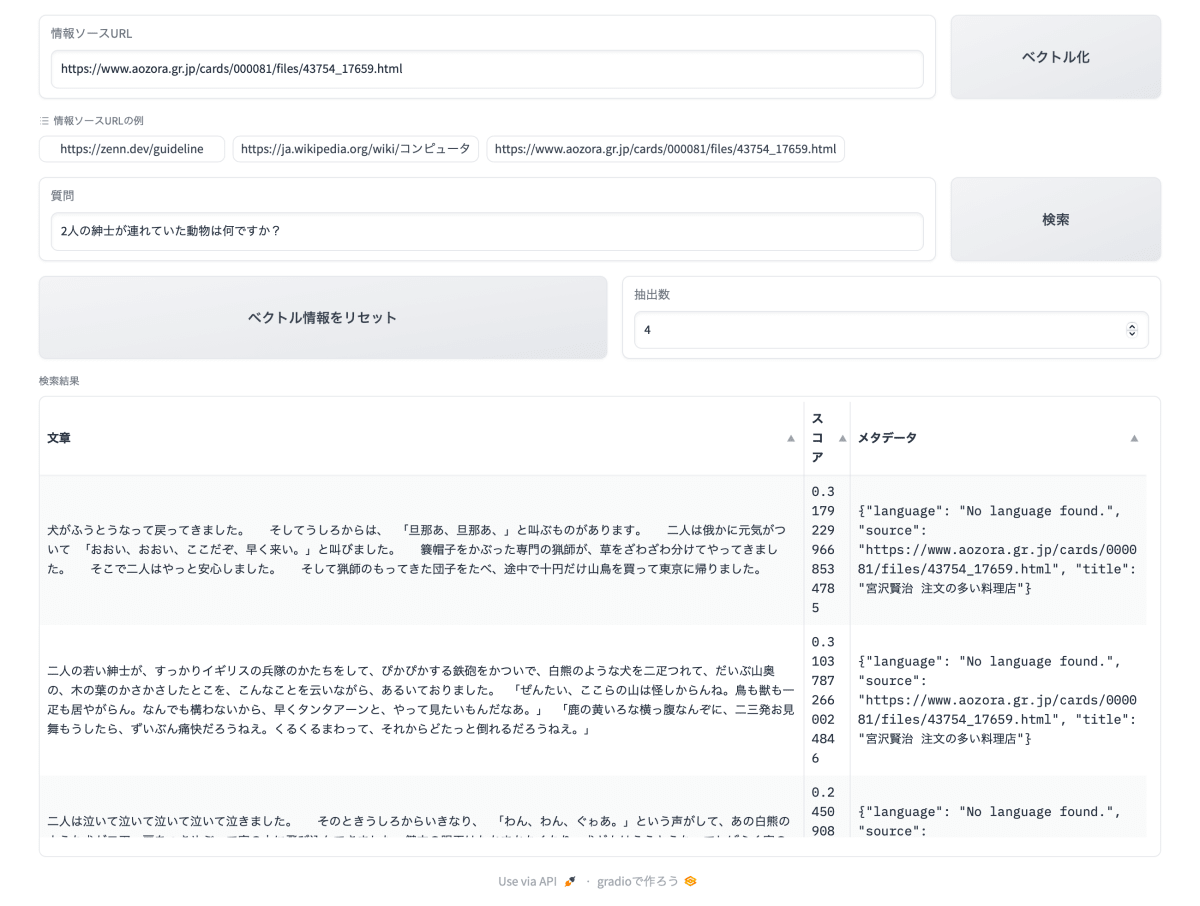
外部情報ソースの題材として青空文庫で公開されている宮沢賢治 著「注文の多い料理店」を利用させていただきました。情報ソースURLにはhttps://www.aozora.gr.jp/cards/000081/files/43754_17659.htmlを指定します。チャンクサイズは256、オーバーラップサイズは64です。
質問は、 2人の紳士が連れていた動物は何ですか? としました。
以下、抽出された上位4個のチャンクです。スコアは0から1の値で、1が最も高い類似度を示します。1位のチャンクからでも、正しい回答が生成できそうですが、2位のチャンクが最適だと思います。良い結果だと思います。
スコア:0.31792299668534785
犬がふうとうなって戻ってきました。 そしてうしろからは、「旦那あ、旦那あ、」と叫ぶものがあります。 二人は俄かに元気がついて「おおい、おおい、ここだぞ、早く来い。」と叫びました。 簔帽子をかぶった専門の猟師が、草をざわざわ分けてやってきました。 そこで二人はやっと安心しました。 そして猟師のもってきた団子をたべ、途中で十円だけ山鳥を買って東京に帰りました。
スコア:0.31037872660024846
二人の若い紳士が、すっかりイギリスの兵隊のかたちをして、ぴかぴかする鉄砲をかついで、白熊のような犬を二疋つれて、だいぶ山奥の、木の葉のかさかさしたとこを、こんなことを云いながら、あるいておりました。「ぜんたい、ここらの山は怪しからんね。鳥も獣も一疋も居やがらん。なんでも構わないから、早くタンタアーンと、やって見たいもんだなあ。」「鹿の黄いろな横っ腹なんぞに、二三発お見舞もうしたら、ずいぶん痛快だろうねえ。くるくるまわって、それからどたっと倒れるだろうねえ。」
スコア:0.24509084151924876
二人は泣いて泣いて泣いて泣いて泣きました。 そのときうしろからいきなり、「わん、わん、ぐゎあ。」という声がして、あの白熊のような犬が二疋、扉をつきやぶって室の中に飛び込んできました。鍵穴の眼玉はたちまちなくなり、犬どもはううとうなってしばらく室の中をくるくる廻っていましたが、また一声「わん。」と高く吠えて、いきなり次の扉に飛びつきました。戸はがたりとひらき、犬どもは吸い込まれるように飛んで行きました。 その扉の向うのまっくらやみのなかで、
スコア:0.204444088557187
「あるきたくないよ。ああ困ったなあ、何かたべたいなあ。」「喰べたいもんだなあ」 二人の紳士は、ざわざわ鳴るすすきの中で、こんなことを云いました。 その時ふとうしろを見ますと、立派な一軒の西洋造りの家がありました。 そして玄関にはRESTAURANT西洋料理店WILDCAT HOUSE山猫軒という札がでていました。「君、ちょうどいい。ここはこれでなかなか開けてるんだ。入ろうじゃないか」「おや、こんなとこにおかしいね。しかしとにかく何か食事ができるんだろう」
まとめ
ベクトル検索は一から実装するととても大変なものだと思いますが、LangChainとChromaデータベースを使うと容易に試すことができます。Gradioにより作成したGUIでベクトル検索の結果確認も容易です。
ベクトル検索の出力する結果は、単純な文字列マッチングとは異なり、かなり融通のきく人間的とさえ感じられるもので、とても興味深いです。まだ、きちんと調査していませんが、どの埋め込み表現生成モデルを利用するかでかなり結果も変化し、これも興味深いです。
Discussion