llama.cppのテキスト生成パラメータを調整してみる
はじめに
前回投稿した記事で、大規模言語モデル(Large language Models:LLM)にELYZA-japanese-Llama-2-7b-instructを利用した日本語チャットアプリケーションをGradioで作成する方法について説明しました。
このチャットアプリケーションでいろいろと試してみると、思うような結果が出ないこともあります。大規模言語モデル(以下、LLM)によるテキスト生成は、本記事で試したELYZA-japanese-Llama-2-7b-instructモデルを含め、1トークンずつ予測生成していきます。予測時に最も可能性の高いトークン以外にも上位N個のトークンを予測しているので、どのトークンを採用するかについて複数の方法が考えられます。その方法毎にパラメータが決まっていますが、本記事ではそれを調整してみます。[1]
テキスト生成パラメータ調整用GUI
前回投稿した記事で紹介したチャットアプリケーションに、テキスト生成パラメータ調整用スライダを追加しました。Gradio Sliderコンポーネントを使うと簡単に実装できます。llama-cpp-pythonライブラリ llama_cpp.Llama.create_completionで指定するパラメータの内、テキスト生成を制御するものをスライダで調節できるようにしました。パラメータ数が多いので、スライダの値を読み取るイベントリスナー関数には、入力をリストではなく、辞書で送るようにしています。その詳細は、Gradioドキュメント Function Input List vs Dictを参照してください。この仕組みのおかげとちょとした工夫で、パラメータ名でスライダの値を管理できるようになっています。
また、スライダがたくさんあってうるさいので、Gradio Accordionレイアウトで、必要のない時は非表示にできるようにしました。
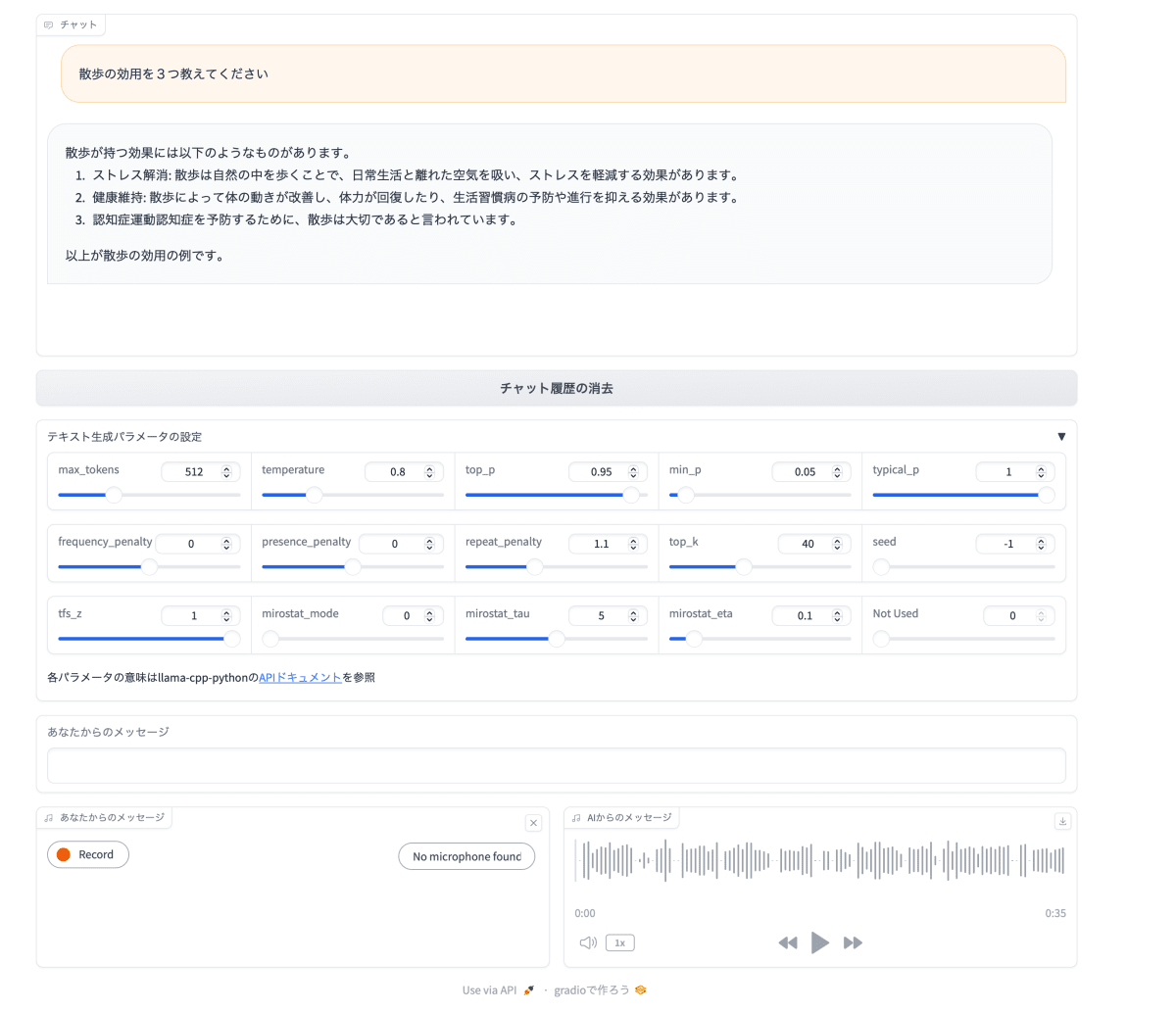
ソースコード
以下に、テキスト生成パラメータ調整用GUIを付加したチャットアプリケーションのソースコードを示します。環境構築方法は前回投稿記事の環境セットアップを参照してください。(他のプラットフォームでも動作すると思いますが、Macでのみ動作確認しています。)
ここをクリックしてソースコードを表示
import gradio as gr
from huggingface_hub import hf_hub_download
from llama_cpp import Llama
import pyopenjtalk
import whisper
import numpy as np
import torch
import torchaudio.transforms as T
B_INST, E_INST = "[INST]", "[/INST]"
B_SYS, E_SYS = "<<SYS>>\n", "\n<</SYS>>\n\n"
B_OS, E_OS = "<s>", "</s>"
DEFAULT_SYSTEM_PROMPT = "あなたは誠実で優秀な日本人のアシスタントです。"
MEMORY_LENGTH = 2
CONTEXT_SIZE = 2048
DEFAULT_MAX_TOKENS = 512
LLM_REPO_ID = "mmnga/ELYZA-japanese-Llama-2-7b-instruct-gguf"
LLM_FILE = "ELYZA-japanese-Llama-2-7b-instruct-q8_0.gguf"
model_path = hf_hub_download(repo_id=LLM_REPO_ID, filename=LLM_FILE)
llm = Llama(model_path, n_gpu_layers=128, n_ctx=CONTEXT_SIZE)
asr = whisper.load_model("small")
parameters = {}
def construct_prompt(history):
message = history[-1][0]
prompt = "{bos_token}{b_inst} {system}\n".format(
bos_token=B_OS,
b_inst=B_INST,
system=f"{B_SYS}{DEFAULT_SYSTEM_PROMPT}{E_SYS}"
)
if history is not None:
for item in history[-(MEMORY_LENGTH + 1):-1]:
prompt += "{user} {e_inst} {assistant} {eos_token}{bos_token}{b_inst} ".format(
user=item[0],
e_inst=E_INST,
assistant=item[1],
eos_token=E_OS,
bos_token=B_OS,
b_inst=B_INST
)
prompt += "{message} {e_inst}".format(
message=message,
e_inst=E_INST
)
return prompt
def text2speech(history):
text = history[-1][1]
audio, sr = pyopenjtalk.tts(text)
return sr, audio
def speech2text(audio, history):
sr, y = audio
# 整数型から浮動小数点型へ変換
y = y.astype(np.float32)
y /= np.max(np.abs(y))
# サンプルレートをWhisperが対応する16kHzへリサンプリング
y_tensor = torch.from_numpy(y).clone()
resample_rate = whisper.audio.SAMPLE_RATE
resampler = T.Resample(sr, resample_rate, dtype=y_tensor.dtype)
y2_tensor = resampler(y_tensor)
y2_float = y2_tensor.to("cpu").detach().numpy().copy()
# 音声認識
result = asr.transcribe(
y2_float,
verbose=True,
fp16=False,
language="ja"
)
text = result["text"]
history += [[text, None]]
return history
def user(user_message, history):
return "", history + [[user_message, None]]
def bot(history):
# プロンプトを作成
prompt = construct_prompt(history)
print(prompt)
# 推論
print(parameters)
streamer = llm.create_completion(prompt, stream=True, **parameters)
# 推論結果をストリーム表示
history[-1][1] = ""
for msg in streamer:
message = msg["choices"][0]
if 'text' in message:
new_token = message["text"]
if new_token != "<":
history[-1][1] += new_token
yield history
with gr.Blocks() as demo:
# テキスト生成パラメータ用Sliderコンポーネントを保持する辞書
# キーはパラメータ名、値はSliderコンポーネントオブジェクト
param_sliders = {}
# Sliderコンポーネントオブジェクトを作成する関数
def make_param_slider(**kwargs):
global param_sliders
assert "label" in kwargs.keys()
# 作成したオブジェクトはparam_sliders辞書に登録する
param_sliders[kwargs["label"]] = gr.Slider(**kwargs)
# Sliderコンポーネントオブジェクトの値を読み取る関数
def load_parameters(param_val_dict):
global parameters
for k, v in param_sliders.items():
# キー:パラメータ名、値:Sliderから読み取った値
parameters[k] = param_val_dict[v]
chatbot = gr.Chatbot(label="チャット")
clear = gr.Button("チャット履歴の消去")
# テキスト生成パラメータをAccordionコンポーネント内にまとめる
with gr.Accordion("テキスト生成パラメータの設定", open=False):
with gr.Row():
make_param_slider(minimum=0.0, maximum=CONTEXT_SIZE-256, value=DEFAULT_MAX_TOKENS, step=1.0, label="max_tokens")
make_param_slider(minimum=0.0, maximum=3.0, value=0.8, label="temperature")
make_param_slider(minimum=0.0, maximum=1.0, value=0.95, label="top_p")
make_param_slider(minimum=0.0, maximum=1.0, value=0.05, label="min_p")
make_param_slider(minimum=0.0, maximum=1.0, value=1.0, label="typical_p")
with gr.Row():
make_param_slider(minimum=-2.0, maximum=2.0, value=0.0, label="frequency_penalty")
make_param_slider(minimum=-2.0, maximum=2.0, value=0.0, label="presence_penalty")
make_param_slider(minimum=0.0, maximum=3.0, value=1.1, label="repeat_penalty")
make_param_slider(minimum=0.0, maximum=100.0, value=40.0, step=1.0, label="top_k")
make_param_slider(minimum=-1.0, maximum=1000, value=-1, step=1.0, label="seed")
with gr.Row():
make_param_slider(minimum=0.0, maximum=1.0, value=1.0, label="tfs_z")
make_param_slider(minimum=0.0, maximum=2.0, value=0.0, step=1.0, label="mirostat_mode")
make_param_slider(minimum=0.0, maximum=10.0, value=5.0, label="mirostat_tau")
make_param_slider(minimum=0.0, maximum=1.0, value=0.1, label="mirostat_eta")
gr.Slider(label="Not Used", interactive=False)
gr.Markdown("""
各パラメータの意味はllama-cpp-pythonの[APIドキュメント](https://llama-cpp-python.readthedocs.io/en/latest/api-reference/#llama_cpp.Llama.create_completion)を参照
""")
msg = gr.Textbox("", label="あなたからのメッセージ")
with gr.Row():
audio_in = gr.Audio(sources=["microphone"], label="あなたからのメッセージ")
audio_out = gr.Audio(type="numpy", label="AIからのメッセージ", autoplay=True)
# テキスト入力時のイベントハンドリング
msg.submit(
user, [msg, chatbot], [msg, chatbot], queue=False
).then(
load_parameters, {item for item in param_sliders.values()}, None
).then(
bot, chatbot, chatbot
).then(
text2speech, chatbot, audio_out
)
# 音声入力時のイベントハンドリング
audio_in.stop_recording(
speech2text, [audio_in, chatbot], chatbot, queue=False
).then (
load_parameters, {item for item in param_sliders.values()}, None
).then(
bot, chatbot, chatbot
).then(
text2speech, chatbot, audio_out
)
# チャット履歴の消去
clear.click(lambda: None, None, chatbot, queue=False)
demo.queue().launch()
実験するときの注意点
- デフォルトのseed値(-1)では、毎回ランダムにseed値を生成します。そのため、テキスト生成パラメータの設定と、ユーザー入力(プロンプト)を固定しても、LLMが生成するテキストは毎回異なります。seed値を固定する(たとえば0に設定)ことにより、結果が再現できるものになります。
- max_tokensでLLMが生成するテキストのトークン数を制限します。これを0に設定すると、llama_cpp.Llamaクラスのコンストラタで設定するテキストコンテキストサイズn_ctx(本記事のコードでは2048に設定)を超えない範囲で最大数のトークンを生成します。長い文章で表れる、LLM特有の同じフレーズの繰り返しなどをチェックしたい場合は、この設定が役立ちます。
- 通常、LLMは過去の会話を記憶できないため、本記事で紹介のチャットアプリケーションでは、過去2回分のやり取りをプロンプトに含めています。単純にパラメータの影響を見たい場合は、過去のやり取りを含めないように毎回、チャット履歴の消去をした方が良いと思います。
- 上記のとおり、過去のやり取りもプロンプトに含まれるため、プロンプトはかなり長くなり、その分もテキストコンテキストサイズn_ctxを消費します。その結果、生成できるトークン数も影響を受けます。
- パラメータの影響は、LLMの生成するテキストの自由度が大きくなる場合に顕著になるようです。これは、LLMの知識によって回答が生成されるプロンプトよりも、「〜に関するお話をつくってください」のようなプロンプトの方がパラメータの影響を見やすいということです。物語をつくる指示は、生成されるテキストが長くなるで、短くしたい場合、詩をつくる指示をするのも良いかと思います。
パラメータの意味
| パラメータ | デフォルト値 | 意味 |
|---|---|---|
| max_tokens | 512[2] | 生成するトークン数の上限 |
| temperature | 0.8 | トークンをサンプリングするときの確率分布形状を制御する値。小さい値を設定すると、生成するトークンの一貫性が保たれる。大きい値を設定すると多様性が増す。0に設定すると、常に最も確率の高い候補が次のトークンとして選ばれる。 |
| top_p | 0.95 | Top-pサンプリング[3]パラメータ。確率の高い順にトークンを選び、確率の和が、この値になるまでトークンを加えていく。0.95の場合は、確率の高い順に、モデル出力全体の95%が次のトークンの候補となる。 |
| min_p | 0.05 | Min-pサンプリング[4]パラメータ。次のトークンの候補に加えるトークンを判断するときの確率最小値 |
| typical_p | 1.0 | Locally Typical Sampling[5]パラメータ。1に近い値は、より文脈に一貫性のあるトークンの生成を促し、0に近い値はより多様なトークンの生成を促す。1.0を設定するとLocally Typical Samplingは無効になる。 |
| frequency_penalty | 0.0 | 過去に同じトークンが現れた回数によってペナルティを課す。 |
| presence_penalty | 0.0 | 過去に同じトークンが現れたかどうかでペナルティを課す。 |
| repeat_penalty | 1.1 | 生成されたテキスト内のトークンシーケンスの繰り返しを制御。より大きい値は繰り返しに大きなペナルティを課し、繰り返しを抑制する。 |
| top_k | 40 | Top-Kサンプリングのパラメータ。確率の高いkトークンからのみサンプルする。 |
| seed | -1 | シード値。0より小さい値はランダムにシード値を生成する。生成されるテキストに再現性を求める場合は、固定する。 |
| tfs_z | 1.0 | テールフリーサンプリング[6]のパラメータ。文脈によって、次のトークンとして候補に加えるべきトークン数は異なるため、Top-Kサンプリングで代替として考案された方法がテールフリーサンプリング。候補から切り捨てる部分(テール)を動的に判断する。1.0の場合、切り捨てることなくすべてのモデル出力トークンを候補に加えるので、テールフリーサンプリングの効果は無効となる。通常、0.9〜0.95 |
| mirostat_mode | 0 | Mirostatサンプリング 0:無効にする、1:Mirostat、2:Mirostat 2.0。Mirostatは、テキスト生成中に生成されたテキストの品質を所望の範囲内で積極的に維持するアルゴリズム[7] |
| mirostat_tau | 5.0 | 値が低いほど、より焦点が絞られ一貫性のあるテキストになり、値が高いほど、より多様で潜在的に一貫性の低いテキストになる。 |
| mirostat_eta | 0.1 | Mirostat学習率。アルゴリズムが生成されたテキストからのフィードバックにどれだけ速く反応するかに影響。学習率が低いと調整が遅くなり、学習率が高いとアルゴリズムの応答性が向上する。 |
参考:
Generation Flags
llama_cpp.Llama.create_completion
例
「発光ダイオードを讃える詩をつくってください」という指示を与えて、生成されるテキストを見てみました。シード値は0に固定しました。
まずは、デフォルト設定で。
{'max_tokens': 0, 'temperature': 0.8, 'top_p': 0.95, 'min_p': 0.05, 'typical_p': 1, 'frequency_penalty': 0, 'presence_penalty': 0, 'repeat_penalty': 1.1, 'top_k': 40, 'seed': 0, 'tfs_z': 1, 'mirostat_mode': 0, 'mirostat_tau': 5, 'mirostat_eta': 0.1}
光る道しるべ
咲き誇る一輪の花
人類が歴史を紡ぎ
未来は明るいかも
temperatureを0に変更。
{'max_tokens': 0, 'temperature': 0, 'top_p': 0.95, 'min_p': 0.05, 'typical_p': 1, 'frequency_penalty': 0, 'presence_penalty': 0, 'repeat_penalty': 1.1, 'top_k': 40, 'seed': 0, 'tfs_z': 1, 'mirostat_mode': 0, 'mirostat_tau': 5, 'mirostat_eta': 0.1}
照らしてくれるその優しき光
世界中に救いを与えたなら
白から色へと進化を遂げた
人類が夢見た理想のような
無音の時計や、遠くまで
照らしてくれる街路灯の光
いつもそばにあるから
安心感を与えてくれる
弱った体を癒やしてくれる
健康な身体を作ってくれる
未来は明るいのだと
思わせてくれる
そのすべてが愛おしい
発光ダイオード
temperatureを3に変更。
{'max_tokens': 0, 'temperature': 3, 'top_p': 0.95, 'min_p': 0.05, 'typical_p': 1, 'frequency_penalty': 0, 'presence_penalty': 0, 'repeat_penalty': 1.1, 'top_k': 40, 'seed': 0, 'tfs_z': 1, 'mirostat_mode': 0, 'mirostat_tau': 5, 'mirostat_eta': 0.1}
LED灯火よ、輝け!
あなたこそ人類に新しき命を
電球の時代が終わり、我が身を尽くすとき
我等は捉え難き道を行くと決めた
過信も自信も大事よ。あなたこそ照らす光
明るさを増やしてくれ、低エネルギー
地球の子ども達に安息を与えてくれ
白色から青々と緑の風景へ
新時代の扉を開け。その足下で我等が夢
大きく育つでしょう。そこで愛の誓い
目標達成のため共に疾駆せよ!光り輝く未来へ向かって
top_kを100に変更。
{'max_tokens': 0, 'temperature': 3, 'top_p': 0.95, 'min_p': 0.05, 'typical_p': 1, 'frequency_penalty': 0, 'presence_penalty': 0, 'repeat_penalty': 1.1, 'top_k': 100, 'seed': 0, 'tfs_z': 1, 'mirostat_mode': 0, 'mirostat_tau': 5, 'mirostat_eta': 0.1}
LED灯火よ、輝け!
あなたこそ人類に新しき命を
電球の時代が終わり、我が身を尽くすとき
我等は捉え難き道を行くと決めた
過信も自信も大事よ。あなたこそ照らす光
明るさを増やしてくれ、低エネルギー
夢は迷路にならず、未来の道しるべとなれ
地球に優しい発展、永遠の命題だよ。
まとめ
テキスト生成パラメータの変更で、生成されるテキストが大きく変化するのは分かりましたが、私の勉強不足のせいか、パラメータ値の意味とその影響が、まだ、しっくりきません。さらに勉強して、もっと理解できたら本記事を更新していこうと思います。
-
Text generation web UIという有名がオープンソースがあって、それを使えばわざわざ自分でつくる意味はないとも思えますが、自分専用のGUIを簡単に作れるようになっておくと、実験をするのに便利だと思います。 ↩︎
-
本記事で紹介しているアプリケーションで設定しているデフォルト値 ↩︎
-
Min P sampler implementation [alternative to Top P/Top K] ↩︎
-
Mirostat: A Neural Text Decoding Algorithm that Directly Controls Perplexity ↩︎
Discussion