オンデバイス(ローカル)LLMとLangChainを利用したRAGチャットアプリの作り方
はじめに
ローカルで動作するLLM[1]チャットボットの作り方と、ベクトル検索について、過去に記事を作成しました。
今回はそれらを組み合わせて、RAG(Retrieval-Augmented Generation)を利用したオンデバイスLLMチャットボットを作成したので紹介します。
RAG
ベクトル検索の記事でも述べましたが、もう一度、RAGについておさらいします。RAGは、外部情報ソースから取得した情報を用いて、LLMの精度と信頼性を向上させる技術で、大雑把に捉えると、以下のような構成になると思います。
LangChainを利用すると、RAGを容易に実装できるので、今回はLangChainを利用しました。
会話型検索チェイン
LangChainに、LangChain Expression Language(LCEL)が導入され、コンポーネント同士を接続してチェインを作ることが、より少ないコーディングで実現できるようになりました。LCELを利用することで、RAGを組み込んだチェインを以下のように簡潔に記述できます。
chain = setup_and_retrieval | prompt | llm | output_parser
詳細は、LangChainドキュメント:LangChain Expression Language:Cookbook:RAGにあります。
LCELを利用して、RAGを利用したチャットボットを構成するのに必要最小限のコードは以下のようになります。LLMにはMeta Llama2をベースに、日本語追加事前学習を行なったELYZA-japanese-Llama-2-7b-instruct[2]を利用しています。但し、そのモデルそのままではなく、Q4_K_S方式で量子化したものをllama-cpp-pythonで推論を実行しています。
from huggingface_hub import hf_hub_download
from langchain_community.llms import LlamaCpp
from langchain_community.vectorstores import Chroma
# from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.document_loaders import WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
from langchain_huggingface import HuggingFaceEmbeddings
CONTEXT_SIZE = 2048
LLM_REPO_ID = "mmnga/ELYZA-japanese-Llama-2-7b-instruct-gguf"
LLM_FILE = "ELYZA-japanese-Llama-2-7b-instruct-q4_K_S.gguf"
CHUNK_SIZE = 256
CHUNK_OVERLAP = 64
EMB_MODEL = "sentence-transformers/distiluse-base-multilingual-cased-v2"
COLLECTION_NAME = "langchain"
SRC_INFO_URL = "https://www.aozora.gr.jp/cards/000081/files/43754_17659.html"
# LLMを生成
model_path = hf_hub_download(repo_id=LLM_REPO_ID, filename=LLM_FILE)
llm = LlamaCpp(
model_path=model_path,
n_gpu_layers=128,
n_ctx=CONTEXT_SIZE,
f16_kv=True,
verbose=True,
seed=0
)
# 埋め込み表現生成用モデルを準備
embeddings = HuggingFaceEmbeddings(model_name=EMB_MODEL)
# 指定したURLから情報ソースをロード
loader = WebBaseLoader(SRC_INFO_URL)
data = loader.load()
# ロードしたテキストをチャンクに分割
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=CHUNK_SIZE, chunk_overlap=CHUNK_OVERLAP
)
all_splits = text_splitter.split_documents(data)
# ベクトル化してベクトルDBへ格納
vector_store = Chroma.from_documents(
documents=all_splits, embedding=embeddings
)
# ベクトルDBをLangChainのRetrieverに設定、抽出するチャンク数はkで設定
retriever = vector_store.as_retriever(search_kwargs={"k": 2})
# Llama2プロンプトテンプレート
template = """<s>[INST] <<SYS>>
あなたは誠実で優秀な日本人のアシスタントです。前提条件の情報だけで回答してください。
<</SYS>>
前提条件:{context}
質問:{question} [/INST]"""
# LangChain LCELでチェインを構築
prompt = ChatPromptTemplate.from_template(template)
output_parser = StrOutputParser()
setup_and_retrieval = RunnableParallel(
{"context": retriever, "question": RunnablePassthrough()}
)
chain = setup_and_retrieval | prompt | llm | output_parser
# チェインを起動して、回答をストリーミング出力
for s in chain.stream("2人の紳士が連れていた動物は何ですか?"):
print(s, end="", flush=True)
上記のコードを、MacBook Air M2チップモデル(16GBメモリ)で実行した結果は以下のとおりです。LLMの読み込みが行われるので、少し時間がかかります。最初の起動時は、LLMのダウンロードも行われるので、さらに時間がかかります。
AVX = 0 | AVX_VNNI = 0 | AVX2 = 0 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | SSSE3 = 0 | VSX = 0 |
2人の紳士が連れていた動物は、犬です。
文章中に、「二疋つれて」とあり、これは「2匹」を示しています。
llama_print_timings: load time = 308.76 ms
llama_print_timings: sample time = 5.56 ms / 63 runs ( 0.09 ms per token, 11328.90 tokens per second)
llama_print_timings: prompt eval time = 22617.47 ms / 823 tokens ( 27.48 ms per token, 36.39 tokens per second)
llama_print_timings: eval time = 3402.10 ms / 62 runs ( 54.87 ms per token, 18.22 tokens per second)
llama_print_timings: total time = 26208.42 ms / 885 tokens
デモアプリケーション
GradioでGUIを実装したRAGチャットボットをGitHubで公開しています。よろしかったら、お試しください。
MacOSとLinux(Ubuntu)で動作確認しました。Google Colabでも動作します。
使い方
起動後、「情報ソースURL」テキストボックスに、RAGの情報ソースとなるウェブページのURLを入力し、リターンキーを押します。ウェブページの内容がチャンクに分割され、ベクトル化され、Chromaデータベースに格納されます。
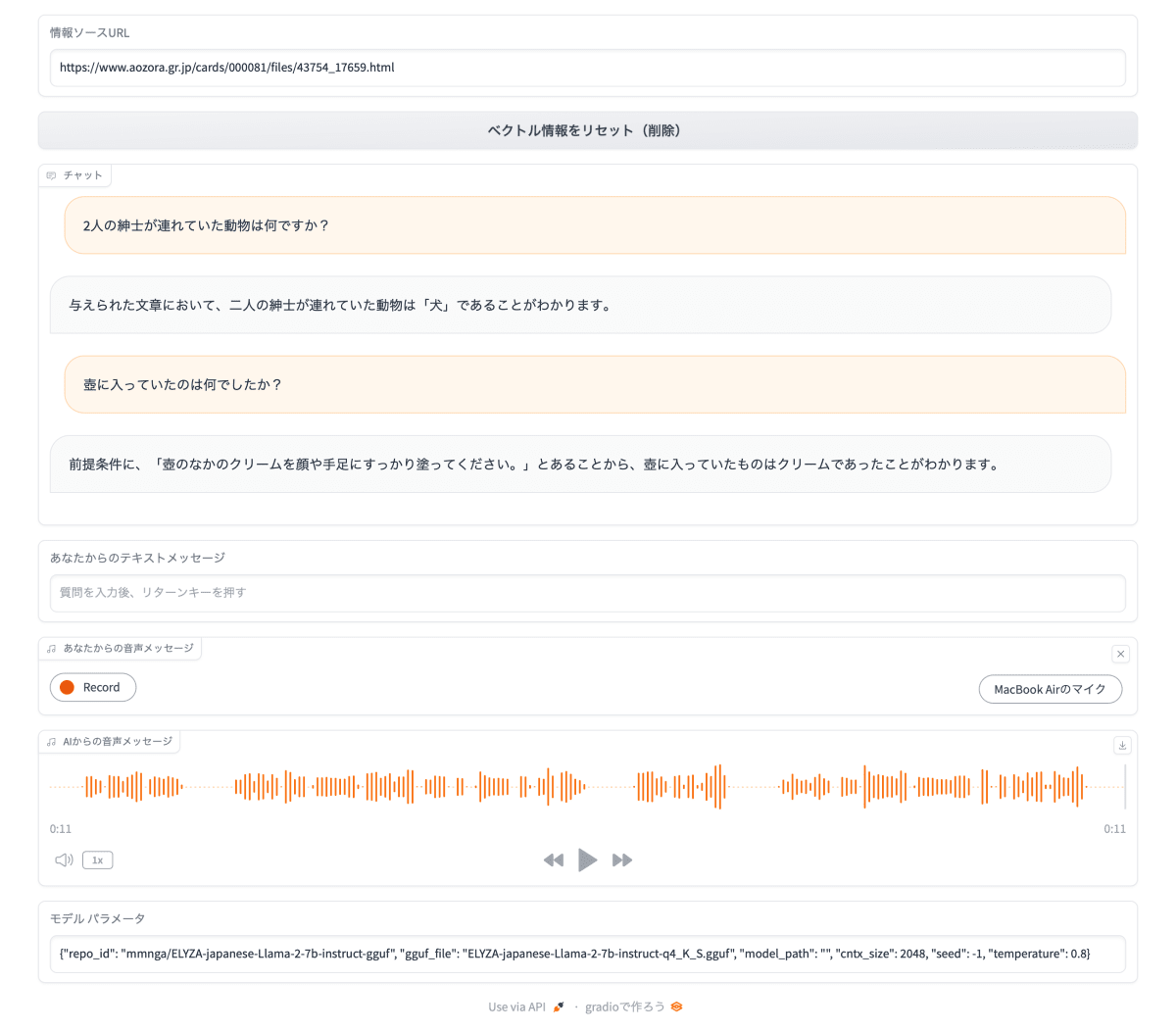
以下のいずれかの方法で質問を入力します。
- 「あなたからのテキストメッセージ」テキストボックスに質問文を入力し、リターンキーを押す。
- 「あなたからの音声メッセージ」オーディオコンポーネントの「Record」ボタンをクリックして、マイクから音声で入力する。

以下のように、回答が表示され、音声でも回答が出力されます。(原因は不明ですが、MacOSでは音声が自動的に出力されないことがあります。)
補足
- 情報ソースURLは入力される度に、データベースに追加されるので、複数のウェブページを情報ソースにすることができます。
- データベースの内容は、チャットボットを起動したパスの直下にある .chroma_db フォルダに保存されます。
- 次にチャットボットを起動したとき、 .chroma_db フォルダが存在すれば、そこからデータベースが復元されます。
- 「ベクトル情報をリセット(削除)」ボタンをクリックすると、データベースからすべてのデータが削除され、同時に .chroma_db フォルダからもデータが削除されます。.chroma_db フォルダ自体は削除されません。
- ソースコード上に定義されている、チャンクサイズなどを変更して、既存データと整合性が取れなくなる場合は、.chroma_db フォルダを削除してください。
まとめ
LangChainのおかげで、RAGを利用したチャットボットがかんたんに実装できるのをご理解いただけたと思います。但し、今回の実装が非常に単純なため、期待した回答を得られない場合もあります。チャンクサイズを変えたり、抽出したチャンクをさらに加工したり、いろいろと工夫することで、より良い結果が得られる可能性がありますし、何より、その工夫が楽しいと思います。
Discussion