
※各登壇パートを終え、まとめセクションで集合する松井氏、三本木氏、小宮山氏
truestar株式会社 プロダクト開発部所属のしんやです。
当エントリでは、2025年09月11日(木)、12日(金)にグランドプリンスホテル新高輪 国際館パミールで開催された『Snowflake World Tour TOKYO 2025』のセッション『データコラボレーションが拓く、未来のビジネス価値創造 - 生成AIが示すデータ活用の最前線 -』の参加・聴講内容をレポートします。
セッション概要
公式サイトのセッションタイムテーブルによるセッション概要は以下の通りです。
セッションレポート
ここからは本セッションの参加・聴講内容をレポートします。
データコラボレーションの現状とSnowflake Marketplaceを中心とした外部データ活用の可能性(by 三本木 宏氏)

- 当セッションはメインのスピーカー2人、truestarの小宮山さん、CCCMKの松井さんという強力なお二方をお迎えしてのお話なので、非常に示唆に富む内容になるのではと考えています。
- ここでは私からはデータコラボレーションの現状をお話させて頂き、小宮山さん松井さんのデータ活用事例へと展開、最後にまとめをお話したい。
データコラボレーションの現状
- 下記図はSnowflake既存ユーザー様におけるデータのやり取り・関係性を線で繋げたネットワーク図。左が2020年04月、そして右が2025年01月。この5年間で様々なデータにリクエストが頻繁に行われてきているというのがお分かりいただけると思います。
- こういったデータのやり取りは自社で分析を進めていくうえで、外部のデータプロバイダーが提供するデータを取り込んでいる、データの共有ということが非常に活発に行われていることが結果として繋がりの拡大に現れてきているとも言えます。

データプロバイダーとは
- 基本に立ち返って「データプロバイダーとは何か」をまとめてみました。
- 基本的には
- データプロバイダーのデータはある程度質が担保されている
- それらと社内のデータを掛け合わせる事で深く分析を行うことが出来、インサイトが得られる
-
組織の目的に合ったことをより効率的にできるようになることを助けてくれるのがデータプロバイダー(のデータ)。

Snowflake Marketplace
- SnowflakeではSnowflake Marketplaceというプラットフォームを展開・運営しています。ECサイトやアプリストア等のデータ版とイメージしてもらえたらと。
- 現在、グローバルで全部合わせると約800以上のプロバイダーさんから3400以上のリストが掲載されています。
- また、日本国内でも日本のエコシステムが順調に成長しており、日本の会社さんも一部抜き出した上でこちらに掲載させていただきました。
- カテゴリとしては位置情報、テキスト関係の情報、金融経済関連のマーケット情報、気象情報、各種パブリックなオープンデータなど、様々なデータが展開、掲載されています。

外部データ検証サイクル
-
データプロバイダーのデータを活用するとして具体的にどんなことができるのか。以下はその概念図。
- おそらく一昔前であれば色んなところに足を運び様々な会社さんを訪ねて多くの人手を介したあとでようやく「そのデータを有効化、利活用できるか」という判断に持っていくことが出来ていました。
- これがSnowflake上であればSnowflake Marketplace上の仕組みを使う事で一元化されたプラットフォーム上でやりたいことが実現出来ます。
-
スライド上では各種アクションが回っているだけですが、実際は上昇スパイラルのような形になっています。アクションをどんどん繰り返して行くことで自社データの活用範囲や自社データの価値を高めることやデータを活用したアプローチの高度化、世界観拡大のお手伝いをすることが出来ます。
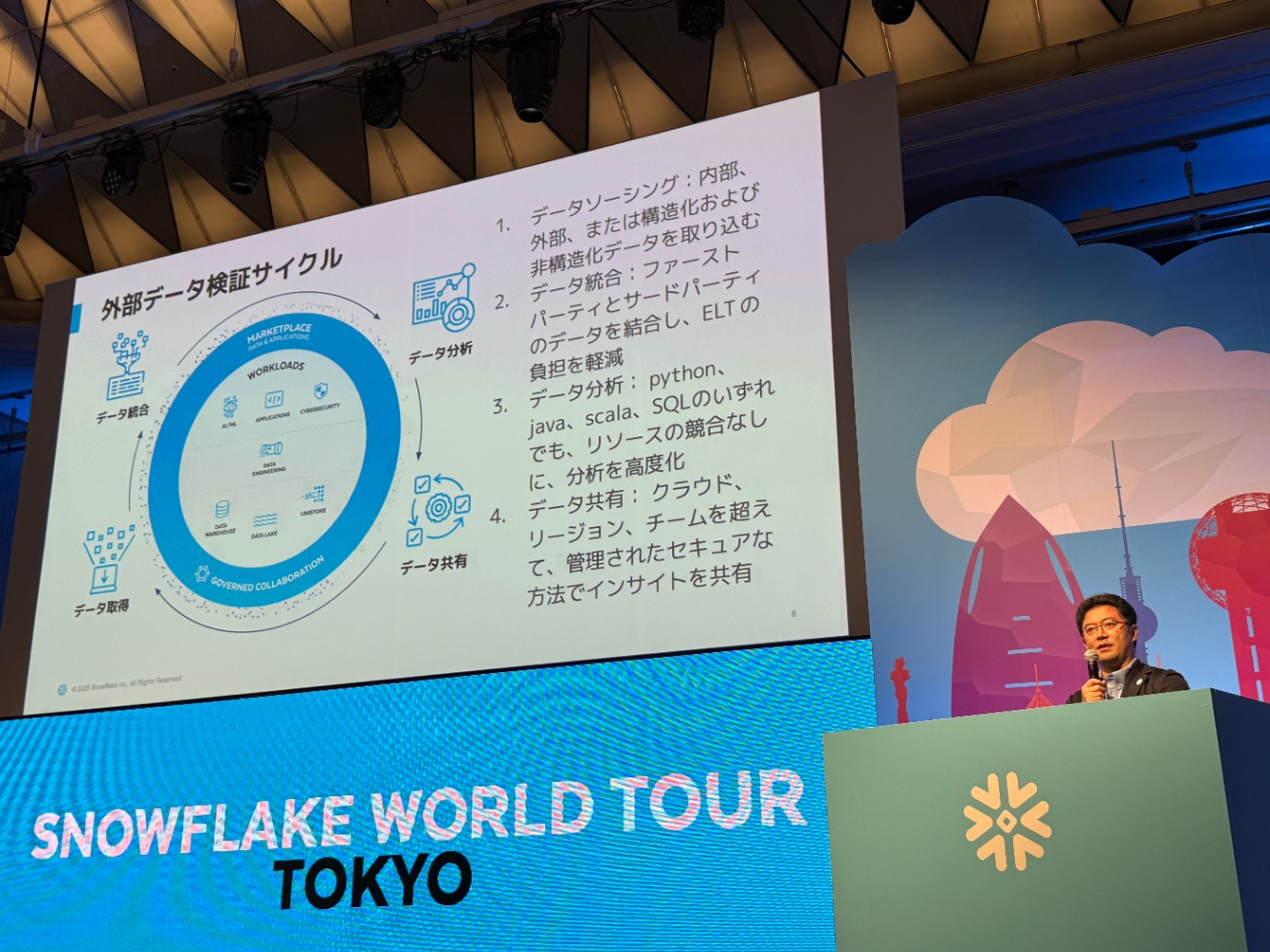
-
以上、こんなことができますよといった大まかな世界観をお話しさせていただきました。
-
それが実際どんな風にできるのかといったところは、truestar小宮山さんの方からお話いただければなと思います。よろしくお願いいたします。

便利なオープンデータが1秒で手に入る。そう、PODBならね。(by 小宮山 紘平氏)

- 自己紹介
- 株式会社truestar プロダクト開発部のディレクター。インフラエンジニア出身のデータエンジニアです。Snowflakeは2022年に使い始めて凄い気に入り、色々情報発信をしていたらSnowflake Data Superheroに選出頂きました。

- 会社紹介
- データコンサルティング領域で10年以上の実績があります。
- 主なサービスはデータアナリティクス(分析)、データビジュアライゼーション(可視化)、データプレパレーション(前処理)など。
- 社内には私を含めてSnowflake Data Superhero、Snowflake Squadが複数名在籍しています。

PODB(Prepper Open Data Bank)について
- Prepper Open Data Bank、略してPODBと言います。
- 国が公開しているようなオープンデータを活用しようとすると、各社が自分たちでデータを取得してきてデータ基盤に入れるという形を取るのが主流ではあります。ただそれだと非常に手間でもありますし、それならばデータプロバイダーが選んだ、整備したデータをMarketplaceで展開するのが効率的ですし便利です。
- truestarもデータプロバイダーとしてPODBをSnowflake Marketplaceに展開・提供しています。無償で利用可能です。

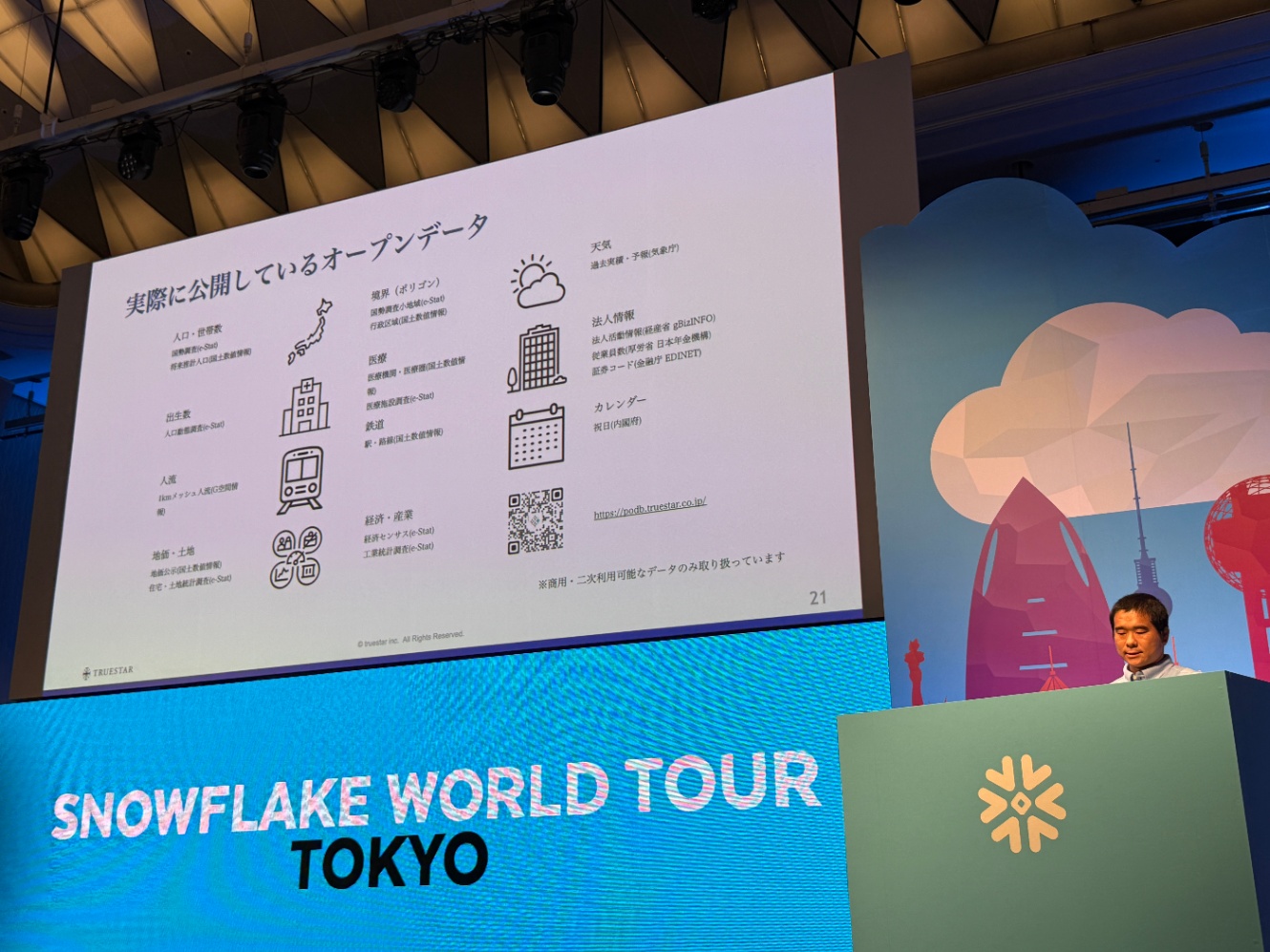
- 以下は現在PODBで展開しているデータセットの一覧です。商用・二次利用可能なデータのみを取り扱っています。
実際に使う手順もとても簡単です。Snowflake Marketplace上で「truestar」で検索していただくとデータセットの単位で情報がヒットするので必要なものを選択するだけです。これだけで自社のデータベースを扱うように、PODBが提供するデータを利用することができるようになります。



PODBの新展開
- 上記ここまでで紹介してきた内容(PODB)は無償で利用できるラインナップですが、このたびより価値が高いデータを有償で提供する「PODB Plus」というサービスを最近始めました。
-
現在のラインナップは以下の通り。まだまだ少ないですがかなり有用なデータとなっておりますので、ご興味ある方はぜひMarketplaceにアクセス、及びご検討頂ければと思います。
-
続いて、このオープンデータ/PODBを実際に活用頂いているお話をCCCMKの松井さんにお話頂きます。よろしくお願いします。


CCCMKにおけるデータシェアリングとPODBの活用事例(by 松井 太郎氏)

-
自己紹介
- 営業職からITへ異動、現在ではCCCMKのシステム責任者をやっています。
- コミュニティ活動についても我々のノウハウや記事をコミュニティシェアしていった結果今年2025年、Snowflake Data Superheroに選出頂きました。
-
企業紹介
- Vポイントというサービスを展開しています。累計1.3億人の会員、年間利用者数7000万人規模。どのようなライフスタイルで一体何を買っているのか、そういった情報を我々のデータベースにに統合させてもらっています。

- Vポイントというサービスを展開しています。累計1.3億人の会員、年間利用者数7000万人規模。どのようなライフスタイルで一体何を買っているのか、そういった情報を我々のデータベースにに統合させてもらっています。
-
Vポイントのソリューションについて:
- IDに紐づく顧客データに基づいたインサイト分析、企業やメーカー様に対して我々のデータを活用したマーケティングのご支援をさせて頂いています。
- toC向けにはお得なサービスを提供しつつ、toB向けには蓄積されたデータに基づいて信頼度のある分析であったり効果検証、施策の提案などを提供するサービスとなっています。

CCCMKにおけるデータシェアリングの活用
-
このような展開をしていく中で、我々は多くのデータを「データシェアリング」によって活用しています。
- 今日お話にあったtruestarさんのPODBデータもその1つです。
- また、グループ会社間でもデータシェアを行っています。
- 三井住友カード様とのデータ連携も進めています。
-
そんな形で様々なデータを統合しながらVポイントというサービスを通じてお客様に様々な形でのコンサルティングなどを行っています。

-
そういったことが評価されまして、今回発表もされましたが「データコラボレーション賞」を受賞させて頂きました。誠にありがとうございます!

Snowflake Marketplaceに公開、どんな風に活用出来るの?
- 我々もこのMarketplaceに公開し、チャレンジしてみたいという事で「レシーカ」というサービス、これはレシートをアップロードしたらポイントが必ずというものになっていますが、このデータを少し加工したサンプルデータをMarketplaceに公開しました。

- こういったデータがどのように活用出来るか。レシートの情報を分析することでお客様がどういったものを買われているのか、お客様が何らかのお支払いをしたデータ、お客様のライフスタイルに密接に関係した情報がありますので、それらに基づいた商品ごとの分析や類似するお客様に対してのさらなるライフスタイルのご提案といったことをこのデータを使って活動出来るかな、と考えています。興味のある方は是非触ってみてください。

CCCMKにおけるPODBの活用
- 少し話を戻しましてtruestarさんとのコラボについて。
- 先ほどの紹介でtruestarさんがMarketplaceで展開されている「PODB」をCCCMKでも活用しているというお話をしましたが、カレンダー情報であったり都道府県、市区町村のデータ、また鉄道や路線といった情報もここから入手することが出来ます。

- 我々(CCCMK)が持っているお客様の深いデータと、truestarさんが提供する企業のデータ、オープンデータといういわゆる網羅性のある全国規模のデータ、特定領域における網羅されたデータを掛け合わせる事で効果的な、独自の分析がしやすくなると思っています。

- 一例となりますが、色々な分析をする中で駅であったり路線などの情報を含めたエリア分析などをお客様に行うことがよくあります。そんなときに今までですとGoogleマップであったり何らかの公開情報をスクレイピングするような形で取得したものをプロットし、データセットを作りながら公開するというのが非常に手間となっていました。
- そういったところにこのPODB、駅路線情報を活用すると、駅の緯度経度情報までが整備された状態で分析を進めることが出来ます。今まで数日掛かっていた作業がそれこそ2時間ほどで出来るようになってしまった、という次第です。アナリストに依頼せずとも分析結果をすぐにお客様、営業先に納品出来るという事でとても助かっています。


PODB活用例の紹介:みなとみらいの横浜みなとみらいを中心に、東横線の出来事に我々の加盟店情報をアップした状態で、それに基づいて駅ごとのキーポータルのパワー等を可視化している

PODB活用例の紹介:九州福岡のデータ。路線図ととに路線を選択し、その路線の駅ごとにどういったお客様がいるのか、年齢構成はどうか、ライフスタイルはどうかということをレポーティングしている
CCCMKが考えるPODBの価値
- 公開されているオープンデータというのはたくさんありますが、それらを"使えるデータ"として整えるには非常に手間が掛かります。
- SnowflakeのMarketplaceで取得さえすればすぐ使える、という仕組みがあるのは本当に助かっています。アナリストからするとすぐ活用出来るというのは本当に嬉しい。
- オープンデータについてはデータの更新頻度、メンテナンスなどの地道な作業が発生しうる状況ではありますが、PODBについては適宜データ更新が為されており、常に最新のデータが使えるというのが大きな利点かなと思っています。
- また、こういったオープンデータって「実際どうやって使ったらいいんだろう?」みたいなところで悩むことも多いですが、PODBに関してはデータが構造的に整備されていますし色んな事例を公開頂いているので、我々にとってもとても使いやすく感じています。
- 我々自身がデータ加工やデータ取得、そういった事に悩むことなく、本業であるデータ分析やデータ価値向上に専念できる、手助けをしてくれるのがPODBの良さ、価値なのかなと思います。

という事で引き続き小宮山さんに、truestarが提供する更なるサービスについてご紹介頂こうと思います。

Semantic Viewを使って生成AI時代を満喫しよう(by 小宮山 紘平氏)

誰もがアナリストな世界を想像してみよう
- 引き続き小宮山です。よろしくお願いします。
- Semantic Viewを使って生成AI時代を満喫しよう、というお話ですがまずは皆さん、「アナリストの世界」というのを想像して見てください。
- (ジョン・レノンのイマジンの歌詞に倣って)自分専属のAIアナリストと一緒に仕事をするような世界、そういう時代がすぐそこまで来ている。そこに対してしっかり準備しておけばあなたもその未来を手に入れられる、というふうに考えています。

Semantic ModelとSemantic View
-
ではその「準備」は何をすればよいのか?ここでお話したいのが「Semantic Model(セマンティックモデル)」と「Semantic View(セマンティックビュー)」です。
-
生成AIというのは「今日からAIアナリストになってください」とお願いしただけではなってくれません。
-
AIアナリストにするためには、AIに「自分たちが持っているデータはどういうもので、どんなデータが入っているか」という"仕様書"が必要です。この仕様書にあたるものがSemantic Modelだと思っていただけると良いと思います。
-
"データの仕様書"という観点だと、「データカタログ」や「Semantic Layer(セマンティックレイヤー)」という単語、皆さんももしかしたら聞いたことがあるかもしれませんが、同じような概念として存在していました。
- データカタログとは、データの仕様に関するものを検索出来るようにしたものです。
- Semantic Layerはビジネス用語と物理的な列に関する情報の"対応表"のようなものです。Lookerを御存知の方はあれをイメージしてもらえると非常に分かりやすいと思います。
-
これらは実際運用してみるとわかるんですけれども、いずれも整備やメンテナンスが非常に大変です。

-
これまではアナリストが実際にデータを使おう、ってなった時にアナリスト側で意味不明の情報とかデータを見てその都度判断していました。人間は上司に「いい感じにお願い」って言われたらやっちゃうんですね。
-
この状況が、生成AIが出てきて一変しました。単純に「こういうデータが欲しい」といっても「データが取得出来ません」とか「定義をこうしてくれれば返すことが出来ます」というように、必要なデータ、メタデータをちゃんと定義せざるを得ない状況になって来ました。

- Semantic Modelのお話。1人の人間が自社の凄い膨大なデータ、基盤の凄い詳細な仕様書前にすると圧倒されるという反応をすると思うんですけれども、AIも似たような感じで同じような情報量を前に同じような指示をしても、問いに対する適切なSQLを生成してくれなかったりします。適切なサイズで「一人のアナリスト用の仕様書」と作ってあげる必要があります。

Semantic Viewは、Snowflakeにおけるこの「Semantic Model」を作ることが出来る機能です。 SnowflakeにおけるSemantic ModelとSemantic Viewの関係性がご理解頂けたと思います。

PODBとSemantic View
- 世はまさに「大データ活用時代」ということで、これまではBIや機械学習が出てきた際にもビッグデータの文脈で色々言われていたものはありましたが、生成AIの台頭で一気に「データを活用したい」というニーズが増えていっています。
- 大事なのがデータの活用方法。外部にあるデータ、自社以外のデータも活用して世界を広げていくというのがこれからはとても大事になってきます。

- データプロバイダーについて、今後はセマンティックビューを添えて、すぐ使えるような状態でデータを提供していくというのが「一流データプロバイダー」に求められるようになっていくと思います。
- SnowflakeはMarketplaceで、データと共にセマンティックビューを同時に提供する機能を最近実装しました。
- 実際に弊社が公開しているPODBを見ていただくとお分かり頂けますが、実データと共にViewの下、Semantic Viewが用意されています。

- Semantic Viewという機能自体は今年のSnowflake Summitで発表された新しい機能なんですが、その発表時にtruestarの名前も出して頂きました。機能発表と同時にPODB=Semantic Viewを備えたデータである、ということをSnowflake Marketplaceを通じてアナウンスさせて頂いた形になります。

- 今お話した部分、PODBでSemantic Viewがどのように提供・付与されているのかを紹介します。
Marketplaceのページに飛んでいただくと、カテゴリの部分に「Cortex AI Ready」というのがついていますが、これが付いているデータはSemantic Viewが利用出来るようになっている、生成AIを活用出来るような形になっています。そんなわけでPODBはCortex AI Readyです。

- また、PODBには「Data for Good」というタグも付いています。これはSocial for good、データを活用して社会課題に取り組み、プラスの影響を生み出すことを意味していますよという意味でもあります。



(Semantic View同士を掛け合わせて活用して使ってみるというデモを実演。
こちらは詳細を別途ブログで展開しています)
- まとめです。生成AIを「AIアナリスト」にするためにはSemantic Viewの活用が不可欠です。このSemantic Viewを作っていく、整備していくというところを踏まえて誰もがアナリストな世界を実現していければと思います。
- そして最後にこれが一番大事、これを覚えておいてください。truestarはAI Readyな会社です。Semantic Viewの整備にお悩みでしたら是非お声がけ頂ければと思います。ありがとうございました。

まとめ
という訳で最後は本日登壇された御三方(三本木氏、小宮山氏、松井氏)が壇上に集い、三本木氏によるセッションの総括を述べる形で締めとなりました。

当エントリは同僚(且つ上司)による発表でもあったので通常セッションレポートよりもボリュームと詳細度、臨場感多めの内容でレポートさせて頂きました。データコラボレーション、データ共有というものが今後の更なるデータ利活用を進めていくうえで欠かせないものである、Snowflakeではその流れを後押しする仕組み(Snowflake Marketplace)や仕組み(Snowflake Semantic View)がある...という事が三者三様のセッション展開で実感頂けたのかなと思います。
※登壇頂いた松井様個人のZennブログにて当セッションの裏話的なところにも触れて頂いています。よろしければ合わせてお読み頂けますと幸いです。
