Archetype ベースの ECS を読む (→ 読まない、図解のみ)
ECS への関心
以前 sparse set ベースの ECS を作りました (toecs) 。肝心のグループ機能がお留守ですし Scheduler もありませんが、自分のゲーム開発にはもう十分。ある程度満足してしまいました。
ところが archetype ベースの ECS に関しては、内部実装がイメージできません。たとえば struct Entity の内部データはどのようになっていて、どのように Component との対応を取るのでしょうか。
さらに sparse set ベースの ECS と archetype ベースの ECS のハイブリッドもあり (bevy ECS) 、この内部構造も気になります。 2 つの ECS を上手く繋ぐだけで済むのか、他方が一方の中に組み込まれるのか、何か細かいサポートが大量に必要になるのか?
たまにソースを読んで調べていきます。
どのライブラリを読むか
まだ Query ベースの API と和解していないので、特にどれかに惹かれることもないです。強いて言うなら flax というスペルは良いですね。
-
bevy_ecs (29,733 行)
読むメリットが大きいため、逆に気分が乗らないかもしれません。 -
dotrix_ecs (892 行)
短い! 概要は観れるかもしれません。 -
edict (15,802 行)
参照カウントや変更の検出を builtin でやってくれるそうです。実験的過ぎるかな。 -
flax (15,586 行)
かなり特徴的な API を持つ ECS です。面白いかも。 -
flecs (40,979 行)
憧れがありますが、どこまで C に付き合うか。コスパは良くないでしょう。 -
hecs (7,508 行)
無難な選択で気分も乗りますが、無難過ぎるきらいはあります。 -
legion (13,616 行)
開発も止まっている気がしますし、さすが古いですね。
Building an ECS シリーズ
Sparse set ベースの ECS と言えば EnTT, archetype ベースの ECS と言えば flex! flex の作者こと Sander Mertens の記事を読んでいきます。
※ 訳ではなく僕の解釈を書いています 。
Building an ECS #1: Where are my Entities and Components
(Archetype ベースの) ECS の作り方を教えるぞというシリーズです。
-
Typeとは component 組である -
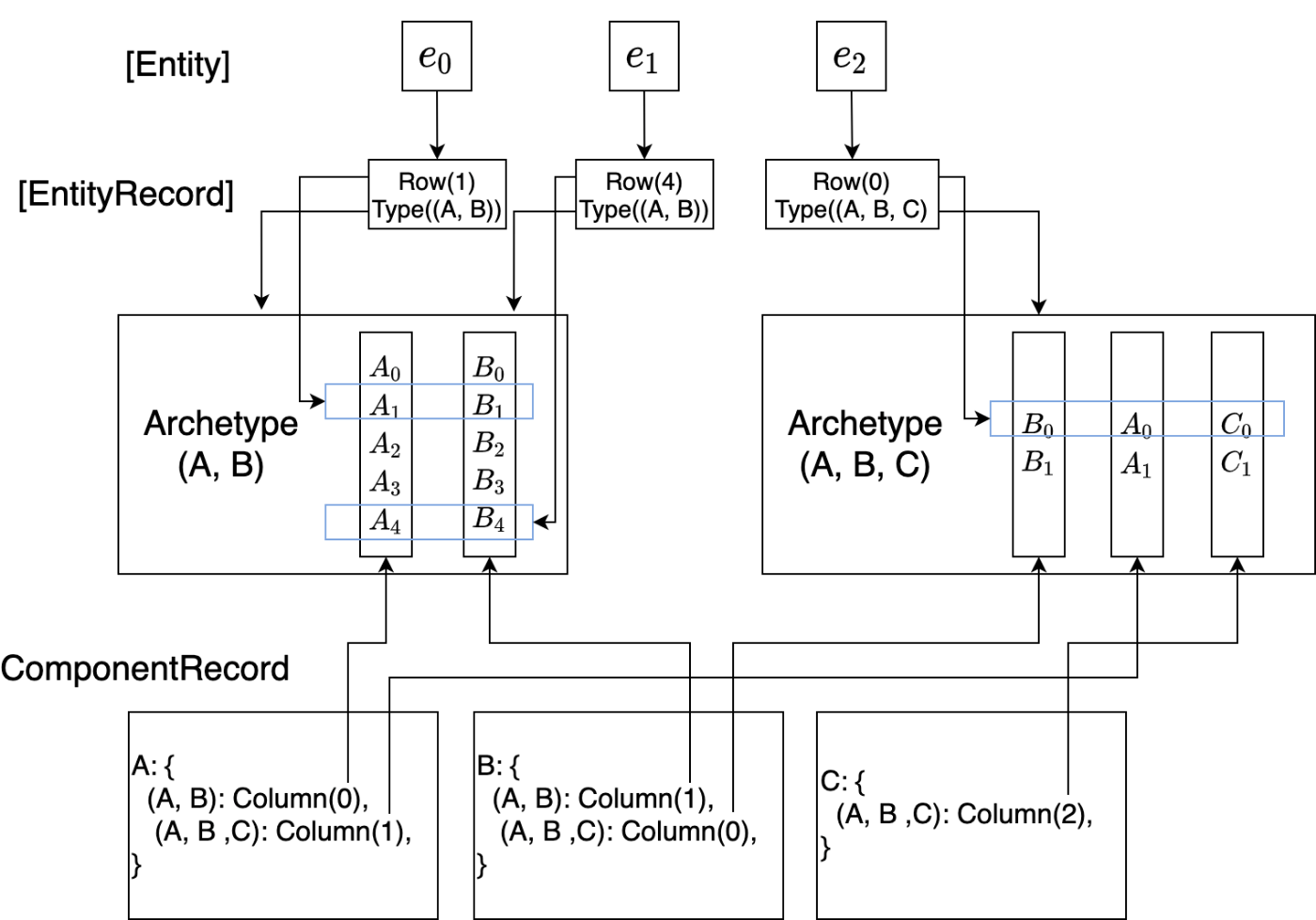
ArchetypeとはType毎のストレージである - 実装のため、以下のマップを作る:
-
entity_index:Entity→Archetype -
component_index:ComponentId→ArchetypeSet(ID のセット) -
ComponentId→ArchetypeSet,ArcheTypeSet→ArchetypeIdという形でマップを作る
-
Building an ECS #2: Archetypes and Vectorization
- 配列のループはキャッシュ効率が良いため高速である。さらに SIMD (single instruction / multiple data: 固定長ベクトル演算) 命令を使用できる可能性があり、 2 ~ 16 倍速くなる。
- SIMD 命令は空欄の無い連続した配列にのみ適用できる。
- (Sparse set ベースの ECS で見られるような) グループを使った並べ方の工夫では、任意の component の組み合わせに対して連続した配列を作ってループすることはできない。たとえば
(A, B),(B, C),(C, A)という 3 つの組み合わせがあれば、すべてのループを密な配列に対するループにすることはできない。 -
Archetypeベースのストレージでは、Type毎に (component 組毎に) SoA ストレージ (vector<Column>) を用意する。なおこのストレージでは対象の型が動的に決まるため、Vec<T>のTに相当する型情報を消す必要がある (Column) 。-
entity_index:Entity→(Archetype, Row)に変更 (Row=size_t)
-
ここまで、試しに Rust で書いてみました
pub fn get_component<'w, T>(e: Entity, c: ComponentId, world: &'w World) -> Option<&'w T> {
let e_index = world.entity_info.index.get(&e)?;
let c_index = world.component_info.index.get(&c)?;
let archetype = &world.archetypes[e_index.archetype_id.raw as usize];
let component_index = c_index.map.get(&archetype.id)?.clone();
Some(&archetype.vecs[e_index.component_vec_id][component_index])
}
-
Componentの挿入はArchetypeの変更に繋がる。 - ここまで、記事では
Type { Vec<ComponendId> }をハッシュマップのキーにしていたが、これは非常に遅い。そこで archetype のグラフを考える。 - ある
ArchetypeのEntityから 1 つのComponentを追加/削除したとき、移動する先のArchetypeをキャッシュする:(ArchetypeId, ComponentId) → ArchetypeId。Edge { add: ArchetypeId, rm: ArchetypeId }を使ってArchetypeの移動をグラフの形でキャッシュする。このEdgeはレジーに生成 (キャッシュ) して、とんでもない量のメモリを使わないようにする。 - これまで SoA (Struct of Arrays) の形で
Archetypeストレージを実装してきた (vector<Column>) 。 AoS (Array of Structs) の形と比べてどうなのだろうか?- SoA は特定の component のみをキャッシュに載せる。 AoS はすべての component をキャッシュに載せる。特定の component のみにアクセスすると分かっているなら SoA の方が効率が良い。どの component にアクセスするか分からないなら AoS の形ですべてキャッシュに載せたほうが効率が良い。
- AoS ストレージはオフセットやアラインメントの計算が難しい。
- 通常
Archetypeは SoA の形で実装される。 Component の数が多くても SoA なら影響が少ないし、重いシステムは大抵特定の component のみに関心がある。
所々『本当か〜?』と思いつつも 良かった ! めちゃめちゃ良かった。
やはり archetype ベースの方が sparse set よりも複雑ですが、すでに内部実装が大体把握できてしまったのが凄い。後はイテレータのために、ある component 組を持つすべての Archetype を列挙する操作とキャッシュが必要な気がします。自力で実装するのはまだキツいかな〜。
もっと Sander Mertens ……を挫折
※ 訳ではなく僕の解釈を書いています 。
Making the most of ECS identifiers
flex の C++ 版 API を把握していないと読めませんでした。内容的にもエクストリームな感じがします。
内容・感想
ComponentId を Entity として扱う
-
Componentに対し分類タグを追加する? 読み取れなかった…… -
Componentに対しリフレクション情報を追加する。 - 動的に設定できるからスクリプティングに有利? 読み取れなかった……
- シングルトンの表現
世代番号を保存する
flex では世代番号は 16 bit (0 ~ 65535) 。
セーブロードしてず〜っとゲームを遊んでいたら超えそうな気がする。普通に 32 bit 使えば良いのでは……?
→ 後述の type flags が 8 bit 使うため?
Relations
flex の 64 bit の ID は以下の 2 通りの解釈がある。
-
flex::entity:EntityId(32 bit) + 世代番号 (16 bit)
こちらはEntityの ID 。 -
flex::id: 2 つのEntityを指す
こちらはComponentの ID 。
ComponentIdを Entity として使う話と両立できるのだろうか? 世代番号はComponentIdasEntityの場合には不要?
Partitioning
さらに bit を分けて利用する。
Type flags
さらに 8 bit 削って特定の要素に使います。
Component を Entity として使うのは面白いですね。もっと詳細が知りたいです。
その他のハックでは、無理に ID の bit を使わなくても sparse set で情報を割り当てれば良い気がしました。どうなのでしょうね。
Why Vanilla ECS Is Not Enough
この話も難しく、実装はハックです。うーむ
内容・感想
- ECS にはデータ構造と設計という 2 つの面がある
- バニラ ECS (記事中では明確に定義されている) では様々なパタンを上手く表現できない:
- データ階層。バニラ ECS では最速でイテレート可能な形で階層を表現できない。
-
Componentの共有。特定のフレームワークが特定の内部データ表現に依ってこの機能を実現している。これらは ECS そもものが持つ語彙では無い。 - 多数のインスタンス。ある
Componentのインスタンスを複数挿入する方法が用意されていない。 - 実行時のタグ。タグが静的に (型で) 表現できるなら良いが、タグが動的に増えていく場合はバニラ ECS で表現できない。
- Entity の状態。普通にバニラ ECS の上で状態を実装すると、間違えて 2 つの状態を同時に ON にしてしまったりする。
- 究極的に宣言的なプログラミング。たとえば
Componentの追加時・削除時に走るシステムの表現。 - システムの実行順。
よって Entity の定義を拡張し、以下の定義を追加する:
- A component identifier is an entity
- タグを entity として動的に生成し追加する
- A component can be annotated with a role
- 親子関係などを設定できる??
flexのドキュメントを読むのが良さそう。
- 親子関係などを設定できる??
- An <entity, component> tuple can have 0 .. N components
- たとえば
(Entity, BuffA)と(Entity, BuffB)に対して同じTimercomponent を追加する。あるいは(Entity, Entity)も可能なので動的な値に関してTimerを追加できる。
- たとえば
その他 System も再定義する。略
このように、 ECS の定義を拡張する形でより良いフレームワークが考えられるという話?
Entity を実行時に生成できる Component 型のように扱うのはかなりハックな気がします。理解も難しい。
Building Games in ECS with Entity Relationships
前の 2 つよりは分かるけれども、ついていくのは難しい……
-
Entity同士の関係性がフレームワークに 1 級市民として支持されることは少ない。たとえば関係性のあるEntityが破壊されたり、複数のEntityとの関係性を作りたい場合はどうするだろうか? - (
flexの) entity relashionships は entity のグラフを描きグラフのクエリを書くための統合された手段である。その実装は 1 見複雑に見えるが、大半は ECS の中に存在する機能を作り直したり調整するだけである。 - Relation というのは 2 つのものを追加することである。たとえば
(Likes, Dog)を追加すれば entity likes dog という関係性を表現できる。 Generics のある言語で表現するなら、Relation<Likes, Dog>を追加するようなものだ。 - ここで
Dogの部分を型ではなく変数にすれば、 entity attacks entity2 のような表現ができる。 entity2 は実行時に決定できるというのが component 型を使うのと異なるところだ。 - ここでの relashionship は値毎に別のものとして扱われる (?) 。同じものとして扱って重複を避けるためには、 exclusive relashionship を作る。
- 以下略
うーむストレージの話以外はついていくのが難しい。