Switch のキャプチャ画像からポケモン名を推定する
はじめに
ポケットモンスター ブリリアントダイヤモンド・シャイニングパール(ポケモンBDSP) が発売してはや一ヶ月が経ちました。
公式からのサポートはありませんが、有志の方が広めてくださった疑似ランダムマッチがユーザーの間で賑わっています。
しかし、疑似ランダムマッチでは、ポケモンの使用率といった統計情報が記録・公開されていません。
これらの情報を得るためには、自分でマッチした相手の統計を取るしかないのですが、対戦相手ポケモン名をタイピングし続ける作業はユーザーにとって非常に負荷がかかります。
そこで、対戦画面のキャプチャ画像からポケモン名のテキストデータを出力するアプリケーションを作成しました。
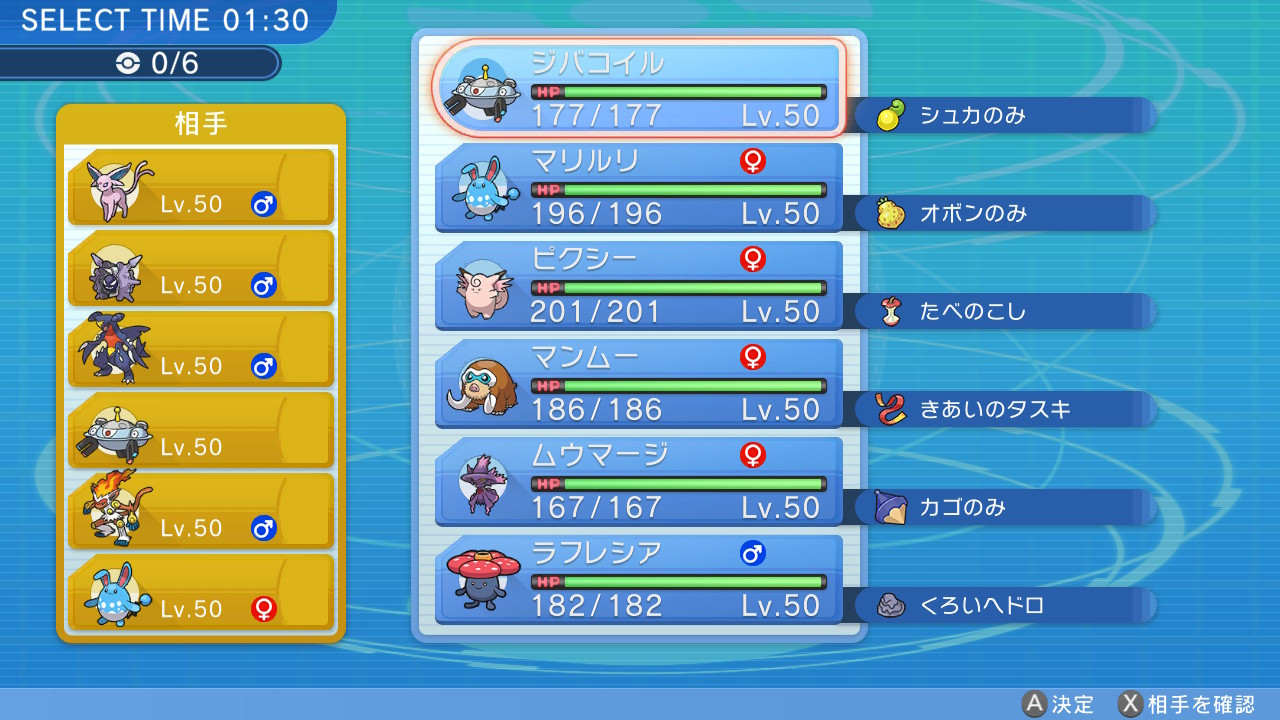
switch のキャプチャ画像サンプル

ポケモン名を推定している様子
赤い四角で囲った部分に推定したポケモン名が出力される
以降、1. 推定の準備、2. ポケモン推定のフロー、3. 性能と余談 に続きます。
1. 推定の準備
1-1. ドット絵
switch から取得した画像からポケモンのドット絵のみを切り出し、ラベル(ポケモン名)を紐づけるのは大変手間がかかります。
これを回避するため、ポケモンのドット絵をアップロードしてくださっているサイト様から、全498匹分のドット絵をスクレイピングしました。
1-2. ユニーク ID をキーとしたデータ構造
原理的には、ドット絵データとポケモンの名前が一対一で対応するデータ構造さえあればマッチングはできます。
しかし、文字列を検索のキーとするのは少々扱いにくいので、各ポケモンに対してユニークな ID キーとして割り振ります。
ポケモンには全国図鑑番号という各ポケモンに対しておおよそユニークな ID があり、これを利用します。
全国図鑑番号をそのまま ID として使うと、フォルムチェンジするポケモン(ロトム、ミノマダム)の ID が重複してしまうため、該当するポケモンには別途 末尾から ID を割り当てました。
2. ポケモン名推定
以下のフローによって、対戦画面のキャプチャ画像からポケモンの推定を行います。
- ポケモン領域の切り出し
- ポケモン領域から背景除去
- ドット絵とのパターンマッチング
2-1. ポケモン領域の切り出し
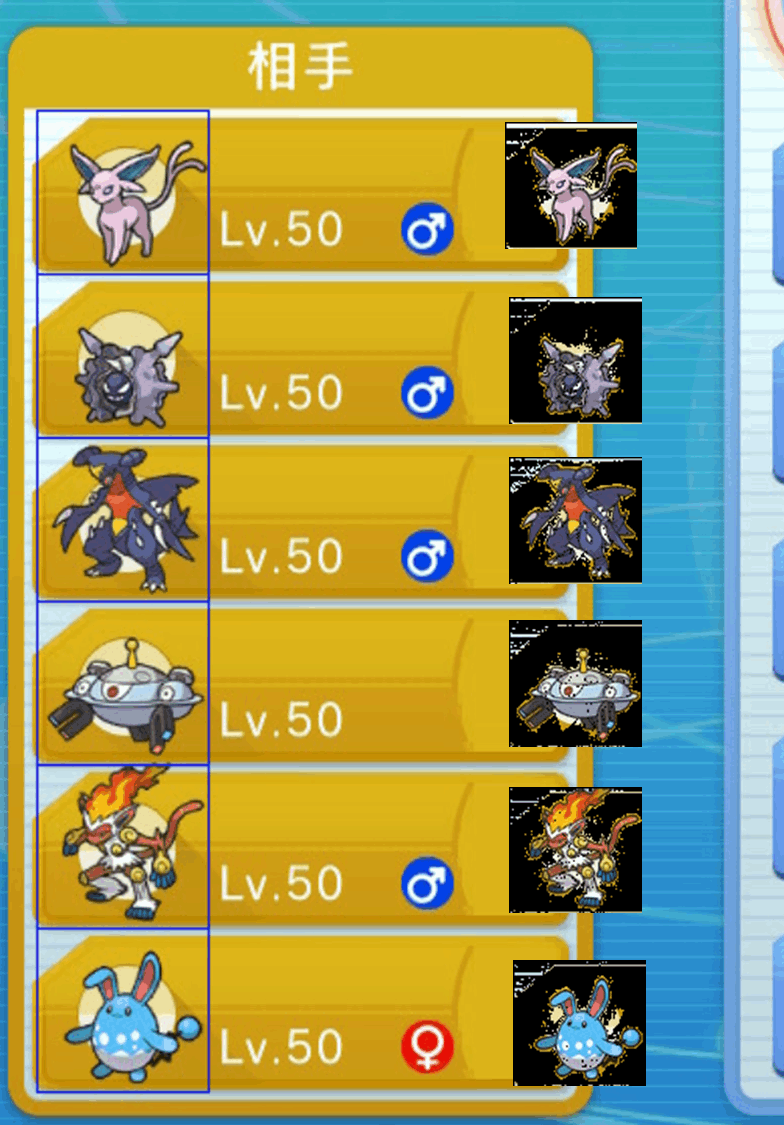
switch から取得した画像におけるポケモンの座標は常に固定されています。
そのため、あらかじめ計測した固定の座標を用いることで簡単に切り出すことができます。
以下の図では、左上の座標:(x, y) = (70, 145 + 81 * i)、サイズ:(width, height) = (85, 81) を満たすi = 0..5 の6つ四角形をポケモン領域としています。
2-2. ポケモン領域から背景除去
対戦画面においてポケモン領域内には黄色っぽい背景が含まれています。
これらの背景が含まれた状態では、パターンマッチングが十分な精度を発揮できません。
この精度の低下を回避するべく、背景除去を行いました。
背景除去は、前のステップで切り出した6つのポケモン領域を重ね合わせることで実現します。
各ポケモン領域間で、同じ座標に位置するピクセルの色が同じ場合は、背景だと推定して黒色に塗りつぶします。
switch のキャプチャ画像内におけるポケモン領域と、その横に背景除去後のポケモン領域を配置した図を以下に示します。
大半の領域において背景をうまく除去できていますが、重ね合わせて背景除去をしてる関係上、小さいポケモンを含む領域内では背景が少し残っています。
2-3. ドット絵とのパターンマッチング
今回の実装では、1. ヒストグラム相関 と 2. AKAZE 特徴量による 2種類のマッチング手法を利用しました。
基本的に、1. ヒストグラム相関 によるマッチング手法の方が精度は高く、2. AKAZE 特徴量によるマッチングは補助的に利用しています。
具体的には、1. と 2. のそれぞれにおいてマッチング率の高いポケモンの候補を算出します。
その後、候補ポケモンの重複の有無に応じて、以下のいづれか3種類のフローで候補を絞り込みます。
A. 1. と 2. で算出した候補内で重複するポケモンが1匹のみのとき、そのポケモンを推定結果として出力します。
B. 1. と 2. で算出した候補内で重複するポケモンが複数匹のとき、それらのポケモンのうち、1. の手法によるマッチング率が最も高いポケモンを推定結果として出力します。
C. 1. と 2. で算出した候補が重複しない時、1. の手法によるマッチング率が最も高いポケモンを推定結果として出力します。
以降では、1. と 2. の詳細なアルゴリズムを説明します。
2-3-1. ヒストグラム相関によるマッチング
2枚の画像間のマッチング率を、ピクセルの色ヒストグラムがどの程度一致するか?で表現する手法です。
まず、それぞれの画像内でピクセルの色ごとに正規化ヒストグラムを作成します。
その後、各色に対して、2枚の画像間で小さい方のヒストグラム値を足し合わせます。
この値がマッチング率を表し、値が大きいほどマッチングしていることを示します。
ヒストグラムのピークとなる色が異なるとこの値は小さくなり、ピークとなる色が一致するとこの値は大きくなる と考えるとわかりやすいです。
これをナイーブに実装すると、RGB 24bit 画像の場合、ヒストグラムのカラム数が 2の24乗ととても大きな数になってしまい、除去しきれていない背景といったノイズの影響が大きくなってしまいます。
これを回避するため、今回の実装では色合いを 216 種類に量子化しています。
コード例を以下に示します。
double make_matching_hist(cv::Mat& src1, cv::Mat& src2){
std::vector<double> hist1, hist2;
const int num_hist = 216;
hist1.resize(num_hist, 0);
hist2.resize(num_hist, 0);
int hist1_max = src1.rows*src1.cols;
int hist2_max = src2.rows*src2.cols;
for(int j=0;j<src1.rows;++j){
cv::Vec3b *src = src1.ptr<cv::Vec3b>(j);
for(int i=0;i<src1.cols;++i){
int bin = rgb2bin(src[i][0], src[i][1], src[i][2]);
hist1.at(bin)++;
}
}
for(int j=0;j<src2.rows;++j){
cv::Vec3b *src = src2.ptr<cv::Vec3b>(j);
for(int i=0;i<src2.cols;++i){
int bin = rgb2bin(src[i][0], src[i][1], src[i][2]);
hist2.at(bin)++;
}
}
double result = 0.0;
for(int i=0;i<num_hist;++i){
hist1.at(i) /= hist1_max;
hist2.at(i) /= hist2_max;
result += std::min(hist1.at(i), hist2.at(i));
}
return result;
}
2-3-2. AKAZE 特徴量によるマッチング
2枚の画像間のマッチング率を、AKAZEによって検出した特徴点間の距離で表現する手法です。
AKAZEは、改良したガウシアンフィルタを用いて画像内のコーナーを特徴点として検出します。
その後、2枚の画像の全特徴点同士の距離の算術平均を求めます。
この値がマッチング率を表し、値が小さいほどマッチングしていることを示します。
今回の実装では、OpenCV4 で実装されている AKAZE detector を利用しました。
コード例を以下に示します。
double make_matching_akaze(cv::Mat& src1, cv::Mat& src2){
// 特徴点の抽出
cv::Ptr<cv::Feature2D> akaze = cv::AKAZE::create(cv::AKAZE::DESCRIPTOR_MLDB, 0, 3, 0.001f);
std::vector<cv::KeyPoint> key1, key2;
akaze->detect(src1, key1);
akaze->detect(src2, key2);
// 特徴量の計算
cv::Mat des1, des2;
akaze->compute(src1, key1, des1);
akaze->compute(src2, key2, des2);
// 特徴量マッチング
cv::Ptr<cv::DescriptorMatcher> hamming = cv::DescriptorMatcher::create("BruteForce-HammingLUT");
std::vector<cv::DMatch> match;
hamming->match(des1, des2, match);
// 特徴量マッチングの距離を、算術平均でまとめる
double result = 0;
if(match.size() > 0){
for(auto m : match){
result += m.distance;
}
result /= match.size();
}else{
result = 100000000.0;
}
return result;
}
3. 性能と余談
100試合分のキャプチャ画像でこのアプリケーションの精度を測定しました。
その結果、推定の正答率はおおよそ 95% 程度でした。
面白かった推定ミス例を下図に示します。
1~3 の例だと、色合いと姿勢が似てる別のポケモンを推定してしまっています。
また、4 水ロトムの場合、比較的小さいポケモンなので、背景を完全には除去できず、黄色い別のポケモンに推定してしまっています。

Discussion
ポケモンを五体未満選出した場合、ポケモンを選択しなかった画面の領域から背景画像のみが切り抜けるはずです。
その背景画像とキャプチャから差分ピクセルを取れば綺麗にポケモンが切り抜けると思いました。
それを利用すれば精度向上出来るのではないでしょうか?
ご助言ありがとうございます。
ポケモン対戦をしてくださるフレンドや2台目以降の Switch を所持しておらず、推定精度向上に活かせるような対戦相手画面を取得することを全く考えていませんでした。
機会があれば、ポケモンを選択しなかった画面等を取得して、改良を試みようと思います。