流行りのテキストからのAI画像生成 (Midjourney, DALL-E 2, StableDiffusion, DiscoDiffusionなど) について、歴史、仕組みから試し方までまとめる
はじめに
9/10から開催の 技術書典13 で記事としてまとめるための、調査、素材置き場です。まず、日本語で界隈を概観するには以下記事がおすすめ。
(8/22)
もうすぐ来ると言われるStableDiffusionのモデル配布の衝撃について。
その根拠の一つである、Eman Mostaque氏 (Founder of Stability.ai) の、意味深なカウントダウンツイート。
(8/23)
公開されました。
Colaboratoryでの試し方をnpakaさんが公開しています。
さらにtuningが可能なColab notebookをpharmapsychoticさんが公開しています。
ローカルで動かす方法は、koyoarai_さんのZennより。
無償、英語・日本語で試せるWebアプリをshi3zさんほかが公開しています。
目次
試し方
最新のもの
Midjourney
Discordに参加し、すぐ使い始められる。
DALL-E 2
クローズドベータ。フォームから登録し、招待を待つ。
DiscoDiffusion
Colaboratoryノートブックとして提供されている。個々人で実行できる。 作成者は Maxwell Ingham (@Somnai_dreams)氏、今はMidjourneyで働いている。
アニメーションを作るためのツールなども、コミュニティで作られている。
Animation Preview
StableDiffusion
クローズドベータ。フォームから登録し、招待を待つ。
DreamStudioの有料ベータ提供が開始?
Tutorial
以下に日本語解説記事がある。
「オープンソースで誰でも自由に使えるAI」を目指してStability AIが開発しているものです。オープンソースの言語AIであるGPT-J-6BやGPT-NeoXなどで知られるEleutherAIも開発に協力しており、このStableDiffusionは既にgithubでソースが公開されています。
Latent Diffusion
ImageNetのクラス指定、自然言語文での指定で、それぞれColabノートブックで画像生成するチュートリアルがある。
Centipede Diffusion
Latent Diffusionの出力を、Disco Diffusionの入力に接続したもの。Colabノートブックで画像生成できる。
以前から存在するもの
DALL-E mini (craiyon)
以下からすぐ試せる。
プロンプトチューニング、プロンプトエンジニアリング
概要
画像生成の呪文Tips
思い通りの画像を生成するためのコツを書かれた記事が増えている。note記事などを中心にまとめる。
AI画像生成関連の歴史
Awesome-Text-to-Imageリポジトリがある。
Yutong Zhou氏が、他にも2つ関連のawesomeシリーズを更新中。
SOTAの遷移 (Paper with Code調べ)
簡単な経緯
- 生成モデルの代表手法には、GAN, VAE, Flowなどがある
- GANを使い、高精細な画像生成で話題となったBigGANは2018年
- 様々なデータセットに対し、ゼロショットで学習可能な自然言語を教師ラベルとする画像分類モデル CLIP が提案 (OpenAI; 2021)
- CLIPとBigGANを組み合わせたテキストからの画像生成に、Big Sleep、FuseDreamがある
- Big Sleepはあまり写実的な画像を生成できなかった
- FuseDreamは局所解に陥らないように工夫し、高精細化を一定実現した
- 一方Diffusion Modelは2015年発表の後、2020年頃からGANを凌ぐ高精細な画像生成で再度注目を浴びる
- Diffusion ModelはVAEの派生とも捉えることができる
- Diffusion Modelは当初計算量を必要としたが、Latent Diffusion Model等、計算量削減の手法が提案
- DDPM(2020)、ADM(2021)と進化
- CLIP特徴とDiffusion Modelを組み合わせたテキストからの画像生成に、GLIDE、unCLIP (DALL-E 2)がある
- さらにImagen (Google Brain; 2022)はCLIP特徴を使わず、大規模言語モデルを使用
cvpaper.challengeの基盤モデルのメタサーベイにも、Text-to-Imageの解説がある。
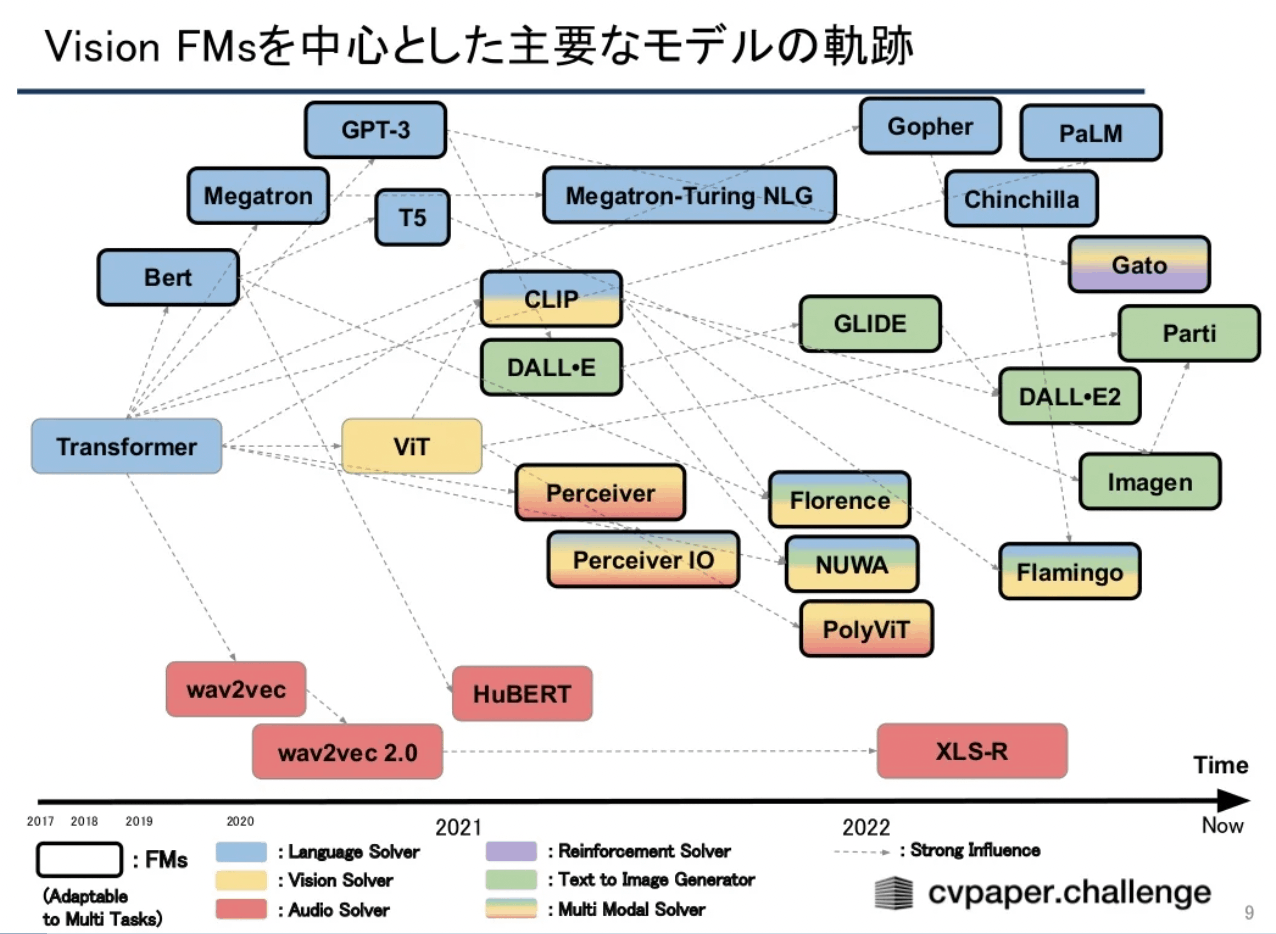
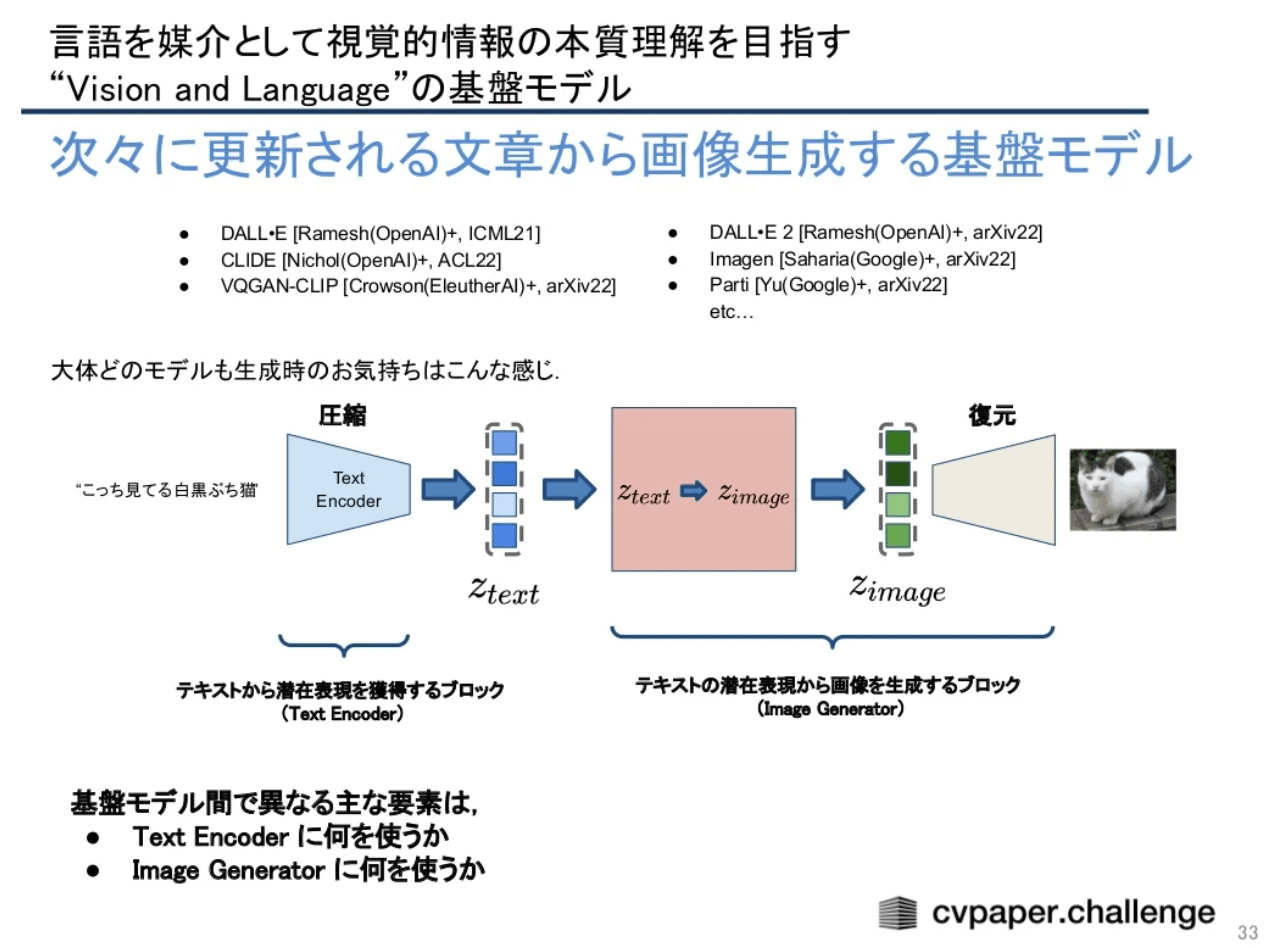
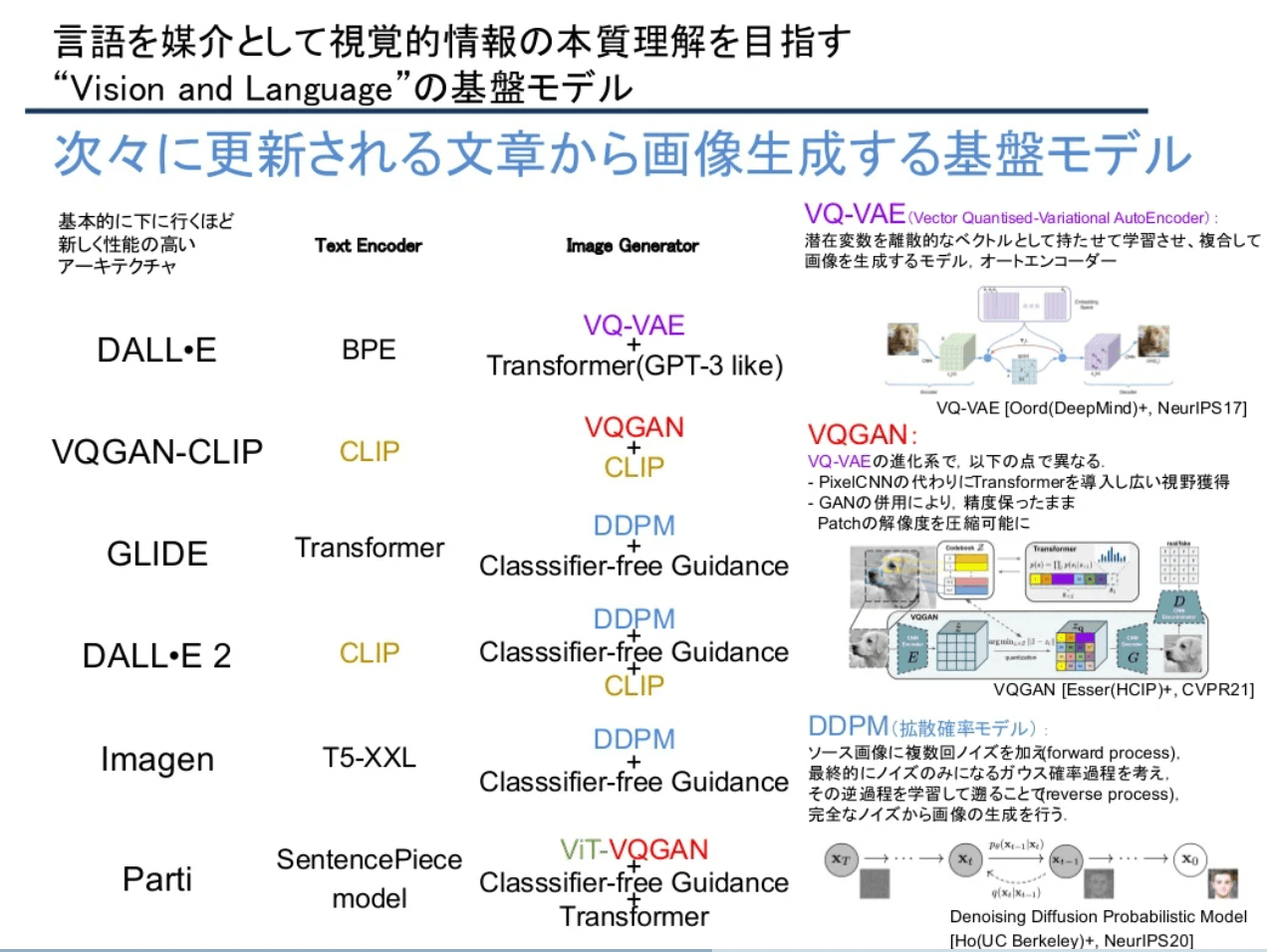
出典: 【メタサーベイ】基盤モデル / Foundation Models by cvpaper.challenge
画像生成、生成モデルのメタサーベイもある。
参考資料
解説系
日本語だと、SONY nnabla YouTubeチャンネルの情報量がとても多い。
- Diffusion Model
- CLIP解説 https://www.youtube.com/watch?v=7UsMRGzt9BI
- DALL-E 2までの道のり
- Imagen解説 https://www.youtube.com/watch?v=N6lJvkoku9s
実装系
データセット
- LAION
https://laion.ai/
LAION 5B (50億枚)、400M (4億枚)、Aestheticsなどのデータセットがある。
https://rom1504.github.io/clip-retrieval/ でブラウズすることができる。
どのようにプロンプトと画像の相関があるかは、実際のText-to-Imageを繰り返すだけでなく、学習に使ったデータセットの具体画像とキャプションをブラウズすることで理解できる。
関連リポジトリ
- Disco Diffusion GitHub - alembics/disco-diffusion
- Stable Diffusion GitHub - CompVis/stable-diffusion
- Latent Diffusion
- Big Sleep GitHub - lucidrains/big-sleep: A simple command line tool for text to image generation, using OpenAI's CLIP and a BigGAN. Technique was originally created by https://twitter.com/advadnoun
- FuseDream GitHub - gnobitab/FuseDream
生成画像のギャラリー
以下のハッシュタグを見る。
#dalle2 https://twitter.com/hashtag/dalle2
#midjourney https://twitter.com/hashtag/midjourney
#stablediffusion https://twitter.com/hashtag/stablediffusion
#discodiffusion https://twitter.com/hashtag/discodiffusion
リストを作ってみた。
以下のsubredditを見る。
Midjourney https://www.reddit.com/r/midjourney/
DALL-E 2 https://www.reddit.com/r/dalle2/
DiscoDiffusion https://www.reddit.com/r/DiscoDiffusion/
StableDiffusion https://www.reddit.com/r/StableDiffusion/
2022/8/21時点で、以下の投稿数がある。
#midjourney 38.8万件
#dalle2 7.7万件
#discodiffusion 5.8万件
#stablediffusion 5000件以上
#midjourney https://www.pinterest.jp/search/pins/?q=midjourney
#dalle2 https://www.pinterest.jp/search/pins/?q=dalle2
#discodiffusion https://www.pinterest.jp/search/pins/?q=discodiffusion
#stablediffusion https://www.pinterest.jp/search/pins/?q=stablediffusion
Webサイト
実行可能なノートブック等
- DiscoDiffusion https://colab.research.google.com/github/alembics/disco-diffusion/blob/main/Disco_Diffusion.ipynb
- からあげさんから紹介してもらったlatent diffusion modelのcolab notebook
https://colab.research.google.com/drive/1mrCDUUvcfDAAYCWNsxXipsd6VQqeNjk-?usp=sharing
Disco Diffusion
使ってみる
以下チュートリアルを元にColabratory上で実行する。
ガイドやチートシート
派生ツール
AnimationPreview - アニメーション生成補助
DiscoArt - One linerでDisco Diffusion生成
作成経緯
-
Katherine Crowsonによるオリジナルノートブック(https://github.com/crowsonkb, https://twitter.com/RiversHaveWings)
- 以下いずれかのモデルを使用
- OpenAIの256x256のUnconditioned ImageNet
- Katherine CrowsonのFine-tuned 512x512の拡散モデル (https://github.com/openai/guided-diffusion)
- 以下いずれかのモデルを使用
-
CLIP (https://github.com/openai/CLIP) を使ったテキストプロンプトと画像を結びつけ
-
Daniel Russell (https://github.com/russelldc, https://twitter.com/danielrussruss) による以下修正
- 1000回ではなく15-100回のタイムステップで素早く生成するための最適なパラメータと、より堅牢なAugmentation
-
Dango233とnshepperdによる更なる改善
- 一般的に拡散の質が向上
- 特にこのノートブックが目指す短い実行時間での拡散の質が向上
-
Vark は複数のCLIPモデルを一度にロードするコードを追加
- すべてのプロンプトがそれに対して評価されるようになり、精度が大幅に改善される可能性
-
最新のズーム、パン、回転、キーフレーム機能は、Chigozie Nri のVQGAN ズームノートブック (https://github.com/chigozienri, https://twitter.com/chigozienri)から引用
-
高度なDangoCutn Cutout法もDango223から
Disco:
-
Somnai (https://twitter.com/Somnai_dreams) Diffusion Animation のテクニック、QoLの改善、様々な技術やテクニックの実装を追加
- 主に以下のチェンジログに記載
-
Adam Letts (https://twitter.com/gandamu_ml) が Somnai と共同で 3D アニメーションの実装を追加しました。disco.pyの作成と継続的なメンテナンス
-
Chris Allen (https://twitter.com/zippy731) によるターボ機能
-
ローカルシステムでの実行機能、Windowsサポート、HostsServer (https://twitter.com/HostsServer) による依存性インストールの改善。
-
VRモード by Tom Mason (https://twitter.com/nin_artificial)
-
nshepperd による水平・垂直方向の対称性機能。Symmetry transformation_steps by huemin (https://twitter.com/huemin_art)。Disco Diffusion への Symmetry の統合 by Dmitrii Tochilkin (https://twitter.com/cut_pow).
-
Alex Spirin (https://twitter.com/devdef) によるワープとカスタムモデルのサポート
-
KaliYuga (https://twitter.com/KaliYuga_ai)によるPixel Art Diffusion、Watercolor Diffusion、Pulp SciFi Diffusionのモデル。KaliYugaのTwitterをフォローして、最新モデルや特殊な設定のあるノートブックを入手できます
-
Palmweaver / Chris Scalf (https://twitter.com/ChrisScalf11) による OpenCLIP モデルの統合と KaliYuga モデルの統合の開始
-
Felipe3DArtist (https://twitter.com/Felipe3DArtist)によるportrait_generator_v001の統合
比較記事
Disco Diffusion vs DALL-E 2
DALL-E 2 vs Midjourney vs StableDiffusion
未整理のリソース
Emad, CEO of Stability.ai
Stable Diffusion, Explained
Visions of Chaos
History
Majesty Diffusion by Dango223
Morphing
img2img
StableDiffusionのファインチューニング、Latent spacesの操作
txt2imgのプロンプトを探す
Lexica
プロンプトと、それに対応する生成動画を検索できる。
img2prompt
画像からプロンプト例を生成できる。
元となったcolabはpharmapsychotic氏による以下のもの。
pharmapsychotic氏の公開するtoolsリストはこちら。
Stable Diffusionの動作原理
Hugging FaceのDiffusersは、複数のVision、Audioなどマルチモーダルな学習済み拡散生成モデルに加え、学習や推論のためのツールキットを提供してくれる。
そのColabから、拡散生成モデルに入門できる。

- Stable Diffusionは、Latent Diffusionベースのため、Pixel-basedなDALL-E 2やImagenに比べ軽量
Latent Diffusion https://arxiv.org/abs/2112.10752
- Pixelベースの場合、 (3, 512, 512) のベクトルを扱うが、Lantent Spaceだと (3, 64, 64) の大きさのベクトルのみ扱うので、1/8 x 1/8 = 1/64の大きさのベクトルを扱えば済む
- VAEで、(3, 512, 512) の画像から、 (3, 64, 64) の特徴を取り出し、そこへのnoise / denoiseを行う
- U-NetはResNetブロックを使ったもの
- Imagenにヒントを得て、テキストから埋め込みベクトルを得るTransformerベースのtext encoderは、学習は行わず、学習済みのCLIPTextModelをそのまま使っている
- U-Netによるdenoisingは繰り返し行われるが、schedulerアルゴリズムは選択できる
Schedulerアルゴリズムの詳細は https://arxiv.org/abs/2206.00364
- diffusersを使って自分で推論パイプラインを書くことができる
Stable Diffusionの考察