Note: If you are limited by GPU memory and have less than 10GB of GPU RAM available, please make sure to load the StableDiffusionPipeline in float16 precision instead of the default float32 precision as done above. You can do so by telling diffusers to expect the weights to be in float16 precision:
「pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16, use_auth_token=True)」、試してみましたがVRAMが少ないと結局CUDA out of memoryが出るようです。
とは言え、本木々でご紹介いただいているoptimizedスクリプトでも落ちないものの緑色一色の画像が生成されるだけなので、私の環境がおかしいだけなのかもしれません。
Discussion
(2022/08/24 追記)
昨日私も理解が十分でなかったのですが、Hugging Faceで管理されているモデルは
.ckptファイルをダウンロードして使うもの https://huggingface.co/CompVis/stable-diffusion-v-1-4-original/discussions (この記事の方法はこちら)の2種類があり、後者にはfp16ブランチが存在しないようです。
従って、この記事に沿って進めていらっしゃる方はfp16よりメモリを節約できるフォークを使ったほうがトラブルが少なそうです。
fp16を使いたいんだと言う場合は、diffusersのStableDiffusionPipelineを使う公式READMEの方法がよいでしょう。
早速情報ありがとうございます!
VRAMが10GBない環境に関して、公式READMEでは次のように記載されています。
ここでオススメされている半精度(float16)のモデルは、Hugging Faceにおいては
fp16ブランチで公開されています。ローカルにダウンロードするやり方の場合、1. 最初からブランチを指定してクローンする(git clone https://huggingface.co/CompVis/stable-diffusion-v1-4 -b fp16)2. stable-diffusion-v1-4のリポジトリが既にあれば、その中でgit switch fp16でfloat16のモデルも取得するなどで半精度モデルを取得できないかな?と考えています。私もまだダウンロード中で最後まで試せてはおらず、速度を犠牲にするフォーク版とどちらがいいのか不明ですが、取り急ぎ情報です。kn1chtさん、ありがとうございます🙏
なるほど.. !ページの下のほうだったので、見逃していました..。
記事の本文も追記をしてみました!情報ありがとうございます!
なお,本記事のようにモデルを手動でgit cloneする方法以外に、diffusersというライブラリを使ってモデルを読み込む方法が公式READMEに紹介されています。そちらを使用する場合にVRAMのエラーを回避するには
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16, use_auth_token=True)のように書けばいいようです。別の方がTwitterで解説されているのは、diffusersを使う方の方法に当たると思います。本記事とは手順が違うだけで実行されるモデルは同じはずですので、混乱が出ないように書いておきます。
「pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16, use_auth_token=True)」、試してみましたがVRAMが少ないと結局CUDA out of memoryが出るようです。
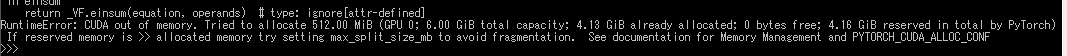
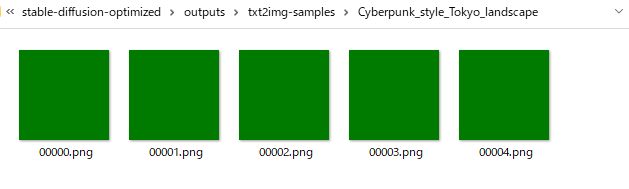
とは言え、本木々でご紹介いただいているoptimizedスクリプトでも落ちないものの緑色一色の画像が生成されるだけなので、私の環境がおかしいだけなのかもしれません。
とととさん、共有ありがとうございます!
出力画像が空になってしまう件ですが、ちょっと調べてみました。
--precision fullを引数に追加すると解決できたというコメントがissueにあり、試してみても良いかもしれません🤔GTX1660Ti環境でフォーク版のStable Diffusionを使って生成できました
↑で報告されている緑一色しか出力されない件に遭遇しましたが、--precision fullで回避できる模様です。
なおアスペクト比を--H 288 --W 512のような形に変えると以下のようにエラーが出ました
以下の記事によると「この問題は、ダウンサンプリング (エンコーダー) パスとアップサンプリング (デコーダー) パスの変数のサイズが一致しないために発生します。」とのことでした。
deep learning - PyTorch runtime error : invalid argument 0: Sizes of tensors must match except in dimension 1 - Stack Overflow
あまり良くわかってませんが、とにかく横長画像を生成してみたかったので、16:9の比率は一旦置いておいて、2:1で生成するテストしたところ以下のようになりました
--H 512 --W 1024|メモリーオーバー
--H 256 --W 512|画像生成が通りました
丁寧な記事ありがとうございました。ご報告までに……
コメントありがとうございます!
なるほど!よかったです!ありがとうございます!
こちらですが、おそらく、
HとWは2のべき乗64の倍数で指定してあげる必要があるかもしれません..!こちらも「--precision full」で回避できました!何をやっても動かず途方に暮れていたので助かりました~。
オリジナルのStableDiffusionもVRAM 8GB (GTX1080)で動作できました。
scripts/txt2img.py に以下修正を加えた上で、メモリ節約のためオプションに --n_samples 2 を指定する必要があります。
ありがとうございます!
自分も試してみました。※ VRAM 8GB (RTX2070)
python scripts/txt2img.py --prompt "a photograph of an astronaut riding a horse " --plms --H 256 --W 256 --n_samples 2でなんとか動作しました... 🙏--H 256 --W 256も指定しないと自分の環境だと厳しかったのですが、こちらっていかがでしたか?改めて試してみましたが、--n_samples 2 だとメモリ使用量がギリギリすぎて(7.8~7.9/8.0GB使用)、他のアプリの状況によっては不足するようです。--n_samples 1 にするとさらに3~400MBメモリ使用量が減るため、--H 512 --W 512 でも安定するかと思います
なるほど..理解しました。しかし、使用量結構厳しいですね。
ありがとうございます!
この記事を参考にしてAWSのEC2インスタンスで動かすことができたので、手順をまとめた記事を書きました。float16版ではなくオリジナル版を動かす手順となっています。VRAMが10GBあるグラボをお持ちでない方は試してみてください。
python optimizedSD/optimized_txt2img.py --prompt "Cyberpunk style Tokyo landscape" --H 512 --W 512 --seed 27 --n_iter 2 --n_samples 10 --ddim_steps 50
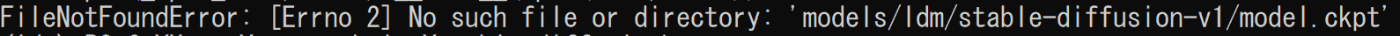
を実行すると画像の様な表示が出て止まってしまいます。どのように対策すればよいでしょうか。
モデルのデータがないか、ファイル名が間違っているよ、というエラーが出ていますね。
本文に記載の「学習モデル」をcloneし、フォルダ名とファイル名を変更する手順を再度ご確認してみるといかがでしょうか?
↓本文より
返信ありがとうございますm(__)m フォルダを手順通り確認してみたところstable-diffusion-v-1-4-originalのリネーム時に一文字だけタイプミスがあり、修正し実行したところ動きました。まさかの凄く初歩的なタイプミス... 無事生成する事が出来ました。ありがとうございました!