未測定交絡の感度解析のためのE-valueとbounding factor (使用例編)


この記事ではE-valueをどんな感じで使うか、RのEValueパッケージも使いながら紹介します。参考文献は以下です。
- VanderWeele, T. J., & Ding, P. (2017). Sensitivity analysis in observational research: introducing the E-value. Annals of internal medicine, 167(4), 268-274. (URL)
- Ding, P., & VanderWeele, T. J. (2016). Sensitivity analysis without assumptions. Epidemiology, 27(3), 368-377. (URL)
- CRANのEValueパッケージのページ (URL)
E-valueとbounding factorの導出に興味がある人は導出編を参照してください。
導出編のまとめ
論文では、
| 変数 | 意味 |
|---|---|
| 処置 | |
| アウトカム | |
| 測定済み交絡因子 | |
| 未測定交絡因子 | |
|
|
|
|
|
|
| 観測された、 |
|
| whole populationにおける、 |
各変数の詳細な定義については導出編を参照してください。bounding factorを次で計算します。
bounding factorを使って次が成り立ちます。
(1)式から、
(2)式の右辺をE-valueと呼びます。
EValueパッケージのインストール
CRANからインストールします。論文の著者がパッケージ開発者に入っています。
install.packages("EValue")
使用例1
EValueパッケージのvignetteの1つのE-values for unmeasured confoundingから。
ある観察研究において、タバコを吸っている人と吸っていない人で肺がんになる確率の比が10.73、すなわち、タバコの肺がんに対する相対リスク(relative risk, RR)が10.73 (95% CI 8.02, 14.36)でした。相対リスクの点推定値が1になる、または相対リスクの信頼区間の下限が1になるには、未測定交絡の影響の大きさがどれぐらい必要でしょうか?これはE-valueを求めることで分かります。
library(EValue)
evalues.RR(est = 10.73, lo = 8.02, hi = 14.36)
結果は次です。
point lower upper
RR 10.73000 8.02000 14.36
E-values 20.94777 15.52336 NA
点推定のほうのE-valueは約21になります。つまり次の大きさが必要になります。
-
が約21倍 -
が約21倍
すなわち、
- タバコを吸っている群ではタバコを吸っていない群に比べて、
の人が約21倍多く存在する -
の人は の人に比べて、肺がんになる確率が約21倍高くなる
こういった未測定交絡因子
この境界線を保ったまま、bias_plot()を使います。
bias_plot(10.73, xmax = 40)
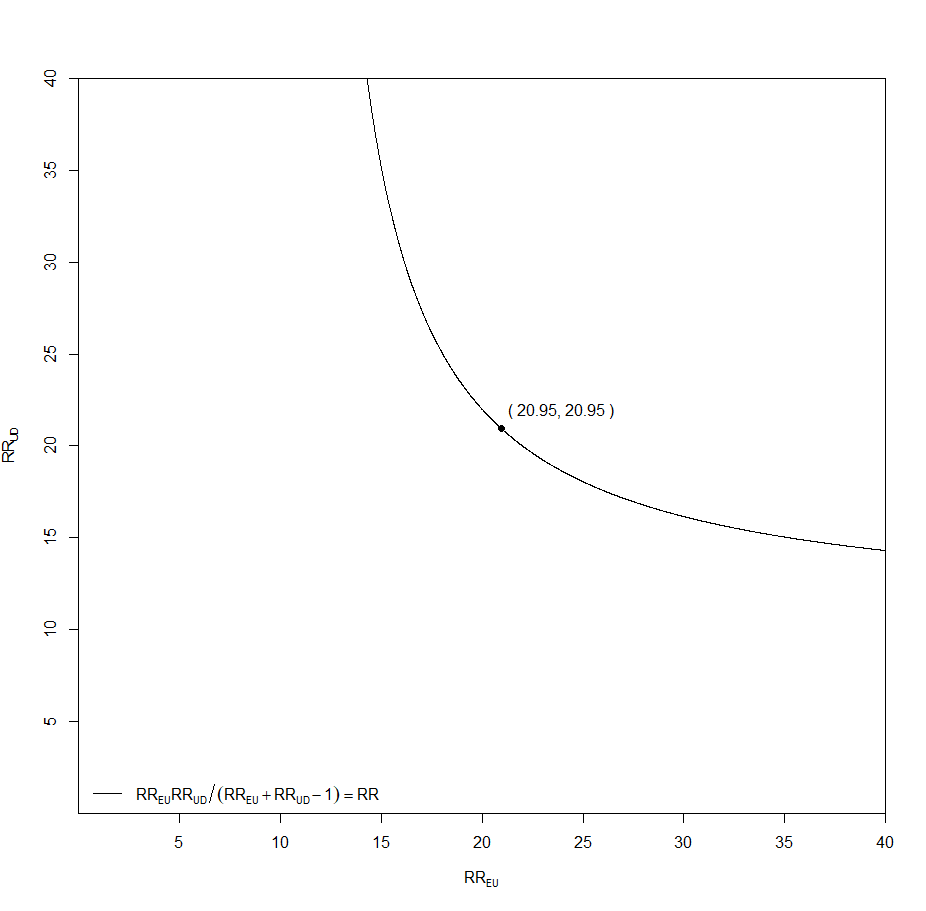
一方を15倍ぐらいに下げると、もう一方は35倍ぐらい必要そうなことが分かります。
使用例2
相対リスクが1より小さくなる方向を考えたい場合にも、そのままevalues.RR()を使えばOKです。
evalues.RR(est = 0.80, lo = 0.71, hi = 0.91)
point lower upper
RR 0.800000 0.71 0.910000
E-values 1.809017 NA 1.428571
相対リスク以外のアウトカムの場合
文献[1]のTable 2に近似の方法が書いてあります。ざっくりまとめますと次の表になります。Rの関数も用意されています。
| アウトカム | 近似方法 | 使用できるRの関数 |
|---|---|---|
| レアなオッズ比、ハザード比 | アウトカムの発生頻度がレア( |
evalues.OR(), evalues.HR()
|
| 連続値の比 | そのまま使う | |
| レアではないオッズ比 |
|
evalues.OR() |
| レアではないハザード比 |
|
evalues.HR() |
| 連続値の差 | 標準化された効果量を |
evalues.OLS() |
| リスクの差 |
|
evalues.RD() |
Enjoy!
Discussion