NVIDIA RTX3060(12GB)でLLMを試す:GPTQ量子化
手頃な価格のGPU(RTX3060)で、GPTQで量子化でしたLLM(ELYZA-japanese-Llama-2-7b-fast-instruct)を動かしたので、記事として残しておきます。
Update(2023/11/12): AutoGPTQ(GPTQConfig)のAPI変更を反映
Update(2024/01/14): GPTQConfigのdatasetに"c4"を指定すると動作しない理由を補足
PCの増強
AdobeCCやゲームを軽く遊ぶ程度なら十分なスペックでしたが、LLMでの利用に耐えられないので、小遣い程度で増強しました。
ベースシステム: ASUS TUF GAMING B550-PLUS + AMD Ryzen 9 5900X
12core/24threadsならCPUでLLMを処理できないかなぁ?と思ったのがきっかけで取り組み始めました
NVIDIA RTX3060(12GB)
お財布に余裕があれば24GB搭載したGPUが欲しかった!
GPU(PCIeデバイス)から直接CPUメモリをアクセスできるように、UEFI/BIOSでResize BARとAbove 4G Decodingを有効にしておきましたが効果は不明(未検証)
Windows 10 proにWSL2を導入
LLaMA2のライセンスを取得してダウンロードしようと思ったら、Shellスクリプト(download.sh)だったので、WSL2(ubuntu環境)を追加導入
CPU主記憶メモリ(32GB->96GB)増設
数10GBを超えるモデルも多いので32GBから96GBへ増設。DDR4メモリが安くなったので増設しやすい
PCIe4.0接続NVMe SSD(2TB)増設
LLMは数10GB~100GB超のモデル容量になるので、読み込み時間の短縮には、PCIe直結NVMeが効くはず
一般的なPCでLLMを動かそうと思ったら「メモリ(GPU)増強、メモリ(CPU主記憶)増強、メモリ(SSD)増強」ですね。
RTX3060(12GB)で試したいLLM
Metaが公開したLlama2をllama.cppで利用していましたが、株式会社ELYZAが日本語LLMを公開された(素晴らしい!)ので、そのfastモデルを非力なGPUで動かす、というのが今回の目標です。
LLMの実行環境を構築する
Windows上でも、WSL2(ubuntu)上でも、どちらでも良いので、PyTorch+CUDAの実行環境を構築します。
※ PyTorch環境の構築は他の方の記事もあるので、今回は省略(別途記事を書くかも)
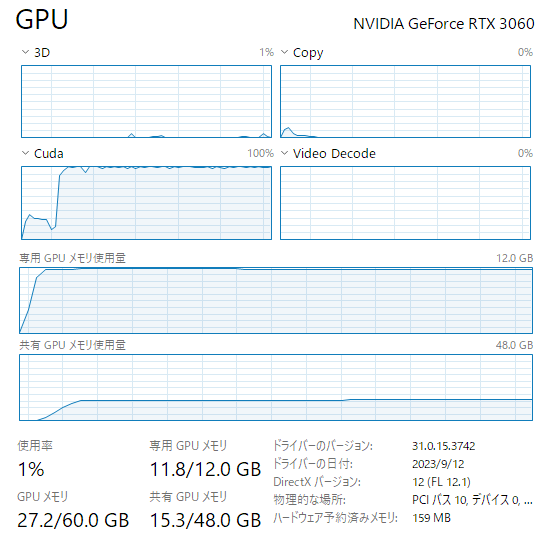
ちなみに、Hugging FaceのModel Cardに書いてあったコード("クマが海辺に行って...")をそのまま実行してみたら、モデルがVRAM12GBに入りきらなくてもCPUとGPUの共有メモリを使って動作するようです。我慢にも限界があるという遅さ! ですけど。
TIPS: WSL2を利用する場合はモデルなどを置く場所に注意
WSL2上に構築する際は、Windowsファイルシステム上に大きなファイル(Higging FaceのCacheやモデルファイル)を置かないようにしましょう。
当初、NVMe SSDに割り当てた/mnt/d/xxxなどにファイルを置いていたら、モデルの読み込みが遅くて悩みました。WSL2からWindowsファイルシステム(NTFS)へのアクセスは凄く遅いです。
大きなファイルでは特に遅さが際立ちますので、WSL2側の/home/xxxなどのext4ファイルシステム(実態はWindows上のCドライブにあるVHDファイル)に配置するようにしましょう。
詳細は省略しますが、WSL2用のVHDファイルを別のドライブに配置することも可能です。
AccelerateでCPU/GPUに分散配置してみる
Accelerateの導入についてはHigging Faceのドキュメントを参考にしてください。
⇒ https://huggingface.co/docs/accelerate/basic_tutorials/install
複数のGPUデバイスなどを使って分散処理するライブラリですが、GPU1台でも使えます。
AutoModelForCausalLM.from_pretrained()でdevice_map="auto"を指定すると、GPUメモリの空きをみて、モデルをCPUメモリとGPUメモリに分散配置してくれます。
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
# if torch.cuda.is_available():
# model = model.to("cuda")
最初の行で直接GPUメモリに読み込んでくれますので、明示的にmodel.to("CUDA")と指定しているコードはコメントアウトしてください。また、モデルの読み込み時間も短くなります。
Accelerateでモデルがどう配置されたかを知りたい時は、print(model.hf_device_map)で表示できます。この出力はdevice_map形式になっていますので、.from_pretrained()に渡すdevice_mapパラメータを調整したい時にも役立ちます。
★ ただし、モデルのメモリー配置を変えてもVRAM12G程度では殆ど速くなりません ★
そこで、4bit程度に量子化したら、12GB程度のGPUでも軽快に動くのではないか?と思って、やってみました。
量子化(Quantization)
量子化(Quantization)についてはHugging Faceの記事が参考になります。
⇒ https://huggingface.co/blog/overview-quantization-transformers
今回は、Hugging FaceのTransformerをそのまま使えるGPTQ形式の4bit Quantizationに取り組みました。
Update補足: 最近Transformerに統合されたAWQ形式の方がGPUの利用効率が高いようです。
⇒ 別記事 NVIDIA RTX3060(12GB)でLLMを試す:AWQ量子化
他にもllama.cppでLLMを動かす方法などがあります (Update:13B-Fastモデルに関する補足追加)
elyza/ELYZA-japanese-Llama-2-7b-fast-instructにはtokenizer.modelファイルが無いので、llama.cppで上手く扱う方法が判らず、GPTQの量子化に取り組みました。
最新のelyza/ELYZA-japanese-Llama-2-13b-fastなどでは、SentencePiece モデル(tokenizer.modelを含む)が追加されており、llama.cppで簡単に取り扱うことが出来ます。
※ llama.cppは他の方の記事もあるので、今回は省略(別途記事を書くかも)
GPTQで量子化する
試したモデルは、ELYZA-japanese-Llama-2-7b-fast-instructです。
Accelerateを使っても、GPTQ量子化処理で、モデルの倍くらいのGPUメモリを消費するようで、CPU/GPU共有メモリをたくさん使ってしまい、非力なGPUでは時間がかかりました。そこで、auto-gptqとoptimumライブラリで試行錯誤して、上手くいった結果を書いておきます。
使用するライブラリ: auto-gptq optimum accelerate
詳しい導入方法などはHugging Faceのドキュメントを参考にしてください。
⇒ https://huggingface.co/docs/optimum/llm_quantization/usage_guides/quantization
今回利用したPyTorchはversion:2.1.0+cu118 (2.0.1からUpdate)
参考まで、今回(2023/9/29 2023/11/12時点)の試行で利用したライブラリのバージョンも書いておきます。
頻繁にアップデートされているので、最新版にupgradeしながら使った方が良いと思います。
accelerate 0.23.0 0.24.1
auto-gptq 0.4.2 0.5.1+cu118
optimum 1.13.2 1.14.0
torch 2.0.1+cu118 2.1.0+cu118
torchaudio 2.0.2+cu118 2.1.0+cu118
torchvision 0.15.2+cu118 0.16.0+cu118
transformers 4.33.3 4.35.0
safetensors 0.4.0
GPTQ量子化に使ったコード (Update Version):
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, GPTQConfig
model_name = "elyza/ELYZA-japanese-Llama-2-7b-fast-instruct"
pretrained_model_dir = "ELYZA-7B-fast-inst-GPTQ" # GPTQ量子化結果の格納ディレクトリ
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 4bit GPTQ設定、exllamaはモデルが全てGPUに乗らないとエラーになるのでdisableにする
gptq_config = GPTQConfig(
bits=4, dataset="c4", tokenizer=tokenizer,
use_exllama=False, cache_examples_on_gpu=False, use_cuda_fp16=True )
# 量子化前のモデルは極力GPUを使わないようにdevice_mapを定義
my_device_map = {'model.embed_tokens': 'cpu', 'model.layers': 'cpu', 'model.norm': 'cpu', 'lm_head': 'cpu'}
# Auto-GPTQがGPTQConfigの設定に従ってモデルを読み込んでくれる
quantized_model = AutoModelForCausalLM.from_pretrained(model_name, device_map=my_device_map,
torch_dtype=torch.float16, quantization_config=gptq_config)
# Auto-GPTQで量子化されたモデルをsafetensors形式でローカルディレクトリに格納
quantized_model.to("cpu")
quantized_model.save_pretrained(pretrained_model_dir, safe_serialization=True)
tokenizer.save_pretrained(pretrained_model_dir)
【注意】2024/01/14現在、optimum(~1.16.1)では、上記コードの"c4"指定がエラーになります。
HuggingFace allenai/c4データセットのCommunityに記載がありますが、optimumのdata.pyコードにあるload_dataset()の引数が現在のデータセット仕様に対応できていないことが原因です。
⇒ https://huggingface.co/datasets/allenai/c4/discussions/7
optimumのアップデートを待つか、別のdatasetを利用するなどを検討する必要がありそうです。
Update: 最新のAPIではdisable_exllama=Trueがuse_exllama=Falseに変更されており、追加パラメータcache_examples_on_gpu=FalseでVRAM消費量を低減できるようです。
このコードの中でdisable_exllama=Trueuse_exllama=Falseは非力なGPUで特に重要です。このパラメータが無いと8~10時間かけてGPTQ量子化が終わった直後に"全てのモデルがGPUメモリに入っていないのでexllamaが動けない"という悲しい例外が発生して、せっかく量子化した結果が失われます。
私の環境(Ryzen 5900X+RTX3060)で実行したら約8時間ほどかかりました。
ちなみに、device_map="auto"にしたら約11時間かかりましたので、量子化処理前のモデルをGPU(VRAM)にロードしないdevice_map指定は、何らかの効果がありそうです。
ただ、device_mapを指定してもGPTQ処理中は無条件にGPU(VRAM)を使うようで、溢れた分は共有GPUメモリまで使って処理しているようです。この辺の挙動を解析できれば、もう少し時間短縮ができるかもしれません。(llama.cppの量子化処理はとても速いので、工夫の余地はありそう)
GPTQで量子化したモデルを動かす
先ほどのGPTQで量子化したモデルを使う時は、モデル名の代わりにローカルディレクトリのパスを指定するだけです。
pretrained_model_dir = "ELYZA-7B-fast-inst-GPTQ"
tokenizer = AutoTokenizer.from_pretrained(pretrained_model_dir)
model = AutoModelForCausalLM.from_pretrained(pretrained_model_dir, device_map=0)
:
# device_map=0でaccelerateがモデル全体をGPUにロードしてくれるのでmodel.to("cuda")などは不要
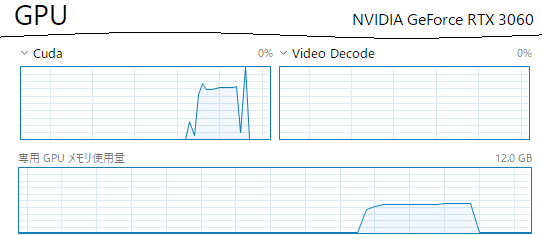
ちなみに、4bit量子化した影響まで検証したわけではないですが、先ほどと同じModel Cardに書いてあったコード("クマが海辺に行って...")をGPTQ(4bit)量子化済モデルで動かすと、下図のように12GBのGPUでも余裕でサクサク動きます。
まとめ
VRAM 12GB程度のGPUでも、GPTQで量子化したLLMを動かせることを確認できました。
llama.cppがサポートしていないモデルでも量子化して動かせますし、Hugging FaceのTransformerを使ったコードがそのまま動くのは、用途によっては使い勝手がよさそうです。
以上、参考まで。
Update補足: 本記事はNVIDIA RTX3060でAutoGPTQを動かすことに主眼を置いており、日本語対応モデルのGPTQ変換で用いるデータセット(現状は"c4"指定)の妥当性などは検討できておりません。
Discussion