NVIDIA RTX3060(12GB)でLLMを試す:AWQ量子化
Hugging FaceのtransformersにAutoAWQが統合されていたので、VRAM12GBのGPU(RTX3060)で、LLM(ELYZA-japanese-Llama-2-7b-fast-instruct)のAWQ量子化を試してみました。
⇒ https://huggingface.co/docs/transformers/main_classes/quantization#awq-integration
最近のLLMは、Hugging Face Hubに量子化済のモデルが登録されていますので、この記事では、AWQ量子化に関するGPU(VRAM)の負荷/利用状況に着目して、記録に残しておきます。
AWQ量子化
他に解説記事もあるので詳細は省略しますが、NVIDIA GPUを前提として、4bit量子化などでGPUメモリー(VRAM)を効率良く利用して、高速に処理できるようになります。ただし、GPTQでは使えたPEFTライブラリ(QLoRA)が利用できませんので、量子化した状態で追加学習したい場合は、AWQではなくGPTQを利用する必要があるようです。
AWQで量子化してみる
試したモデルは、ELYZA-japanese-Llama-2-7b-fast-instructです。
AutoAWQは、利用するCUDAのVersionによってインストール方法が異なりますので、GitHubの記事に従ってインストールしてください。
⇒ https://github.com/casper-hansen/AutoAWQ#install
AutoAWQの前提PyTorchはversion:2.1.0
参考まで、今回(2023/11/12時点)のテストで利用したライブラリのバージョンも書いておきます。
accelerate 0.24.1
autoawq 0.1.6+cu118
torch 2.1.0+cu118
torchaudio 2.1.0+cu118
torchvision 0.16.0+cu118
tokenizers 0.14.1
transformers 4.35.0
safetensors 0.4.0
AWQ量子化(INT4 GEMV)のテストに使ったコード:
from transformers import AutoTokenizer, AwqConfig
from awq import AutoAWQForCausalLM
model_name = "elyza/ELYZA-japanese-Llama-2-7b-fast-instruct" # Hugging Face Model name
pretrained_model_dir = "./ELYZA-7B-fast-Inst-AWQ" # AWQ変換結果の格納ディレクトリ
awq_quant_config = { "zero_point": True, "q_group_size": 128, "w_bit": 4, "version": "GEMV" }
model = AutoAWQForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
# Quantize model
model.quantize(tokenizer, quant_config=awq_quant_config)
# model.configにquantization_configを埋め込む: 最近のAutoAWQは書き換え不要になっている
awq_quantization_config = AwqConfig(
bits=awq_quant_config["w_bit"],
group_size=awq_quant_config["q_group_size"],
zero_point=awq_quant_config["zero_point"],
version=awq_quant_config["version"].lower(),
).to_dict()
model.model.config.quantization_config = awq_quantization_config
# save quantized model
model.save_quantized(pretrained_model_dir)
tokenizer.save_pretrained(pretrained_model_dir)
AWQ量子化でデータセットを指定する必要があるようですが、今回はGPU利用率の確認が目的なので、何も指定せずにテストしました。
AWQ量子化時にデータセットを指定しなかった場合の動作
キュメントに記述が無かったのでAutoAWQのコードを追ってみましたが、何も指定しないとmit-han-lab/pile-val-backupというデータセットを用いているようです。このREADME.mdに書かれていたオリジナルへのリンクが切れていて、利用条件などが判りませんでしたので、テスト目的以外では、別途、データセットを用意した方が良さそうです。
AWQ量子化時のGPUリソース状況:
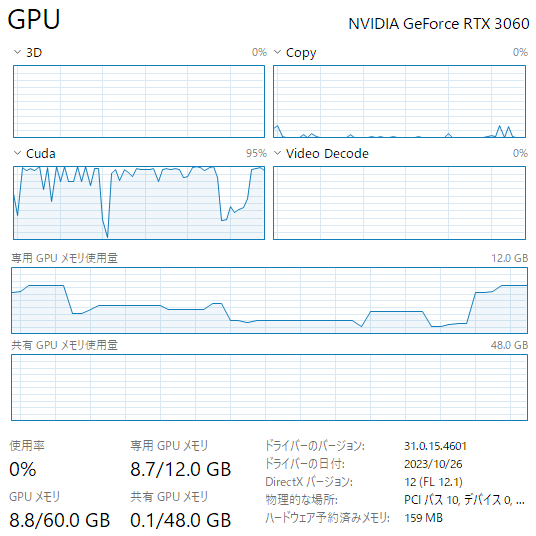
NVIDIA RTX3060で実行した結果、GPUメモリー(VRAM)も約9GB程度の利用に収まって、約30分で量子化が完了しました。同じNVIDIA RTX3060で、同じモデルのGPTQ量子化には、約6~8時間ほど掛かりましたので、AWQ量子化は凄く早いです!
⇒ 別記事 NVIDIA RTX3060(12GB)でLLMを試す:GPTQ量子化
AWQで量子化したモデルを動かす
GPTQと同様にAWQで量子化したモデルを使う時も、モデル名の代わりにローカルディレクトリのパスを指定するだけです。
pretrained_model_dir = "./ELYZA-7B-fast-inst-AWQ"
tokenizer = AutoTokenizer.from_pretrained(pretrained_model_dir)
model = AutoModelForCausalLM.from_pretrained(pretrained_model_dir, device_map=0)
:
# device_map=0でaccelerateがモデル全体をGPUにロードしてくれるのでmodel.to("cuda")などは不要
モデルが全てGPUに乗っていないと動作しませんので注意してください。device_mapで指定しない場合はAutoModelForCausalLM.from_pretrained(...).to("cuda")と書いても動きます。
比較の為、Hugging FaceのModel Cardに書いてあったコード("クマが海辺に行って...")をGPTQとAWQの両方で動かしてみました。

実行時間は、体感でも、上図のCUDAグラフでも、GPTQよりAWQの方が若干早く、GPUメモリー使用量は同等でした。
まとめ
AWQは、Hugging Faceのドキュメント整備もまだまだという印象ですが、非力なGPUを使う用途では、期待できそうな手法です。一方で、Turing世代(sm75)以降のNVIDIA GPUを前提にしていたり、PEFT(QLoRA)が利用できなかったり、といった利用条件は悩ましいところです。
最近は、GPTQ量子化済モデルが最初から公開(rinna/youri-7b-gptqなど)されるようになってきたので、AWQの進化を横目でみつつ、暫くは、GPTQ量子化済モデルを使っていく予定です。
ご参考まで。
Discussion