【LLM】LLaVA1.5について

用途
↑上からデモができる。画像をアップロードしつつ、チャットボットが利用可能。
商用利用は不可
論文は(下記の参考欄の)
・Improved Baselines with Visual Instruction Tuning
・Visual Instruction Tuning
をチェックすると良い。
LLaVA1.5の構成
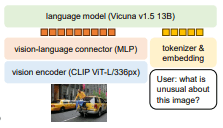
図 モデルの構成(https://arxiv.org/pdf/2310.03744.pdf より)
言語モデル(Vicuna v1.5 13B)と視覚エンコーダーの組み合わせで構成されている。
Vicuna-13B, an open-source chatbot trained by fine-tuning LLaMA on user-shared conversations collected from ShareGPT
VicunaはLLaMAをファインチューニングでトレーニングしたオープンソースチャットボット。
改善前の構成
LLaMA +visual encoder( CLIP ViT-L/14)の構成
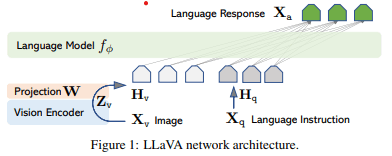
図(https://arxiv.org/pdf/2304.08485.pdf)
Vision encoder(CLIP ViT-L/336px)に関して
CLIP ☛ contrastive language-image pre-training
事前学習方法の一つ
ViT☛(Vision Transformer)
Transformerのエンコーダー部分を使用。
画像をパッチに分けて、パッチを単語のように扱う
trainingに関して
LLaVA training は二段階ある。
(1)feature alignment stage
(2)visual instruction tuning stage
Visual Instruction Tuning
※記載中
改善点
MLP cross-modal connectorの改善
☛linear projectionから2層のMLP(Multi Layer Perceptron)に変更した。
Visual instruction tuningの改善に関して
VQA (Visual Question Answering)での問題
Q: {Question} A: {Answer}.
上記の出力形式を明確に示していないプロンプトを使った場合、自然な視覚的な会話
でさえ、LLMが短い形式の応答をするような振る舞いにオーバーフィットしてしまうこと。
そこで出力形式を明確に指し示すようにした。
Answer the question <using a single word or phrase>.
学術的なタスク指向のデータの追加
OCRや領域レベルの認識に焦点を当てた4つのデータセットを追加
Additional scaling
視覚的知識リソースとしてのGQA datasetの追加
LLMを13B(Vicuna v1.5)に拡張していること。
ShareGPTのデータの追加
参照
Improved Baselines with Visual Instruction Tuning
Visual Instruction Tuning
Discussion