強化学習未経験者がテトリスの AI を作ってみた話
はじめに

この度、強化学習によるテトリスの AI を作成してみました。想像以上にうまくいき、最終的には半永久的にラインを消してくれる AI に成長してくれたので、今回はその記録として AI を作成した過程をここに記していきます!
今回の AI の概要
今回作成したテトリス AI の概要は以下の通りです。
- 特定のゲームの状態から可能な行動パターンを全てシミュレーションする
- 行動後の状態を入力情報として Neural Network に今後の報酬の期待値を推測させる
- 今後の報酬の期待値が一番高くなる行動を実際の行動として選択して遷移する (貪欲方策)
- Game Over になるまで 1 ~ 3 を繰り返す

Tetris AI を可視化した図
何も知らない頃は『AI ってどうやって動いてるんだ?』と自分は思っていたんですが、動作原理は非常にシンプルです。強化学習とは、この今後の報酬の期待値を推測する Neural Network を作成する部分に値します。
テトリス環境の作成
テトリス環境の用意の仕方は主に以下の 3 種類で検討しました。
- テトリス環境を自作して Gym 化させる
- メリット:ルールや仕様を独自に変更できる
- デメリット:作成に少し時間がかかる
- 本家テトリスをキャプチャする
- メリット:本家準拠の本格的なAI作成が出来る
- デメリット:キャプチャする環境準備が大変
- 既存の Gymnasium のテトリス環境を使う
- メリット:楽
- デメリット:カスタマイズ性が少ない
Gym とは、機械学習の環境を提供するオープンソースのプラットフォームのことです。自分の作成した環境を Gym に準拠して作成することでより簡潔に機械学習が出来るようになります。
それぞれにメリット・デメリットがあると思いますが、『ルールや仕様を独自に変更できる』が決定打になり、今回は 自作のテトリス環境 を用意しました。ターミナルで動く単純なテトリスを作成した為、そこまで時間はかかりませんでした。また作るのがシンプルに面白かったので結果的に良かったです。テトリス環境の仕様は以下のように設定しました。
スコアリング
- ミノを設置する毎にスコアが
+1 - ライン消去による追加スコア:
- 1ライン:
+100 - 2ライン:
+300 - 3ライン:
+500 - 4ライン(テトリス):
+800
- 1ライン:
行動集合
- 1 回の行動:「回転 → 横移動 → ハードドロップ」 または 「ホールド」
- 定義:
-
Action(a, b) y a b - 行動集合
A A = \{Action(x,y) \mid x \in [-2, 8], y \in [0, 3]\}
-
今回の自作環境では各ミノを行列で管理しており、Iミノの場合は
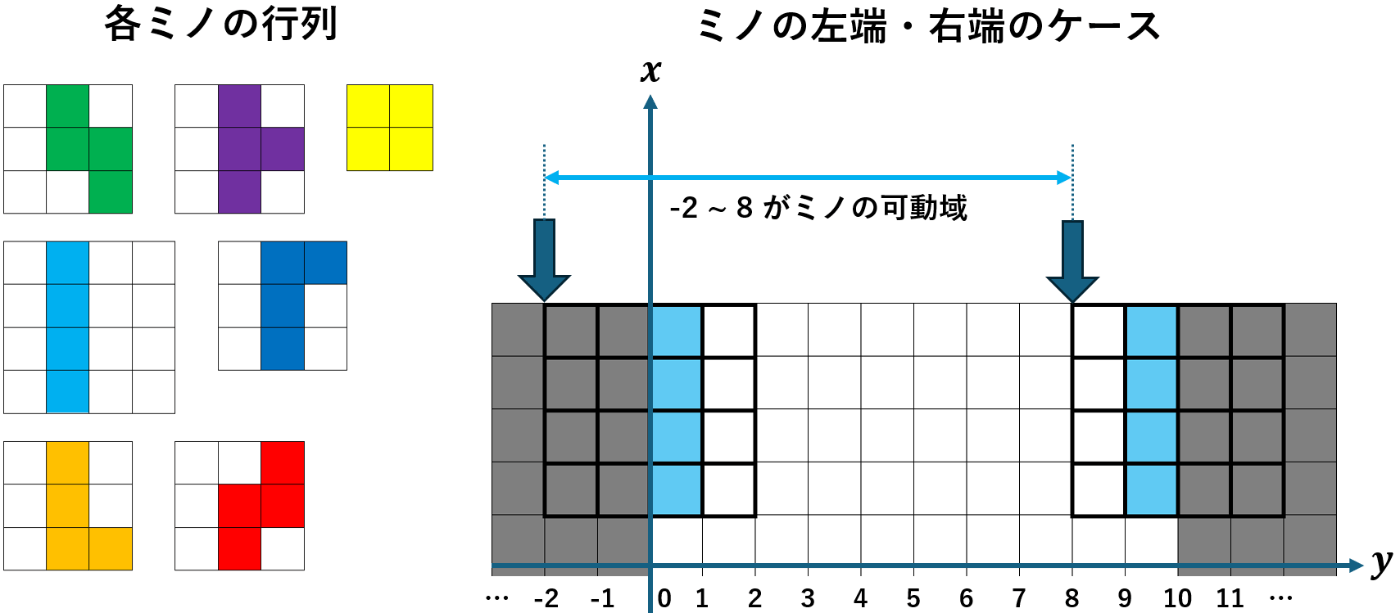
ミノの可動域の左端・右端のケース
実装初期は一般的なテトリスと同じく「回転」or 「横・下移動」 or 「ハードドロップ」 or 「ホールド」としていたのですが、これだと回転や左右移動による 無駄なループ が発生してしまうケースが多々あり、学習がなかなかうまく進みませんでした。その為、回転と横移動とハードドロップの 1 セットを 1 つの行動の候補としました。また今回の行動だと最後がハードドロップで終了する為 Spin 系統の技は入っていません。
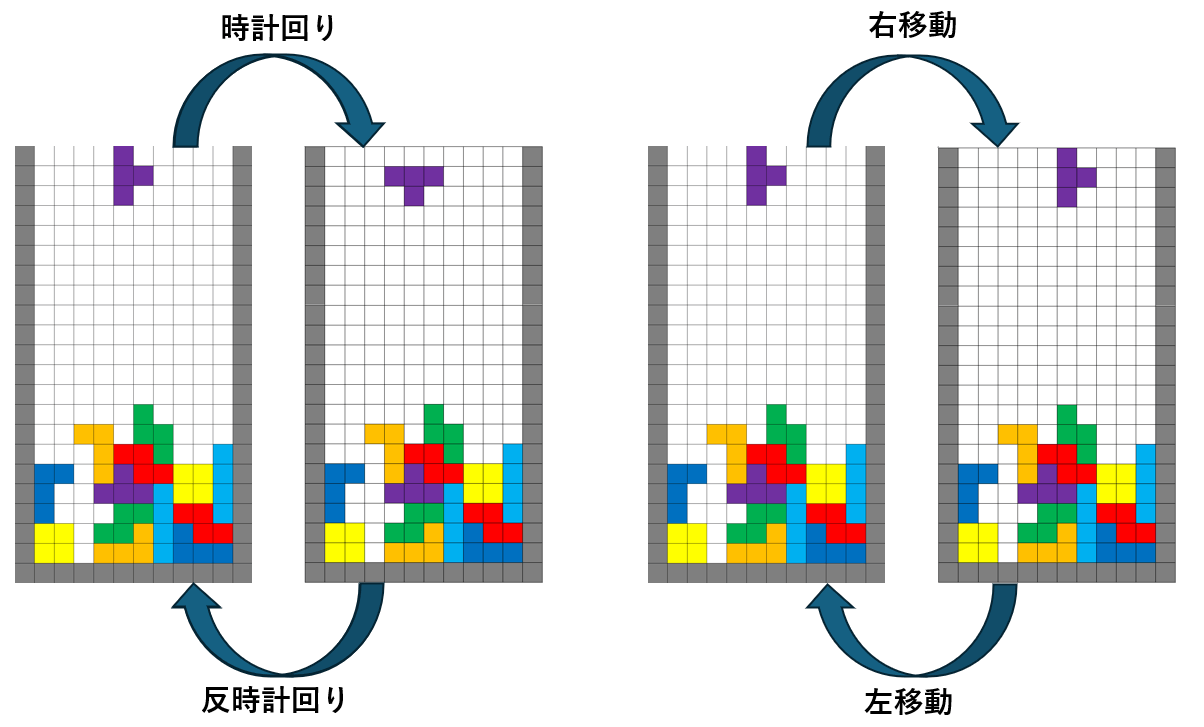
横移動や回転により起こってしまう無限ループ
よって(横移動)×(回転)×(ハードドロップ)+ ホールド が全行動パターンになり、今回の行動パターンとしては場面によって最大で
Neural Network の Model と学習
今回用いた Model の詳細は以下の通りになっています。
Input(13) \rightarrow Dense(64) \rightarrow Dense(128) \rightarrow Dense(64) \rightarrow Output(1) - 損失関数:Mean Squared Error (平均二乗誤差)
- 最適化アルゴリズム:Adam (学習率
lr = 0.001 - 割引率:
discount = 0.99 - 学習時の行動選択:
\epsilon - greedy \epsilon_{start} = 1.000 -
\epsilon \epsilon_{decay} = 0.995 -
\epsilon \epsilon_{min} = 0.05
一般的な Deep-Q-Network との違い
深層強化学習と言えば、一番最初に出てくるのはおそらく Deep-Q-Network でしょう。(以降 DQN と呼びます。ドキュンではないです。)今回の NN は一般的な DQN とは違っていて以下の図のようになっています。一般的な DQN は現在の状態を入力として 全ての行動の行動価値 を求める為、その出力の中で行動価値が一番高い行動がそのモデルが示す最適な行動であると推測できます。
ただ今回の自分の NN は、ある状態から 今後の報酬の期待値 を求めるモデルになっています。そのため今の状態から可能な行動を列挙し、その行動後の各状態をモデルに通して今後の報酬の期待値を求めるということをします。そしてその中で期待値が一番高い行動がそのモデルが示す最適な行動ということになります。
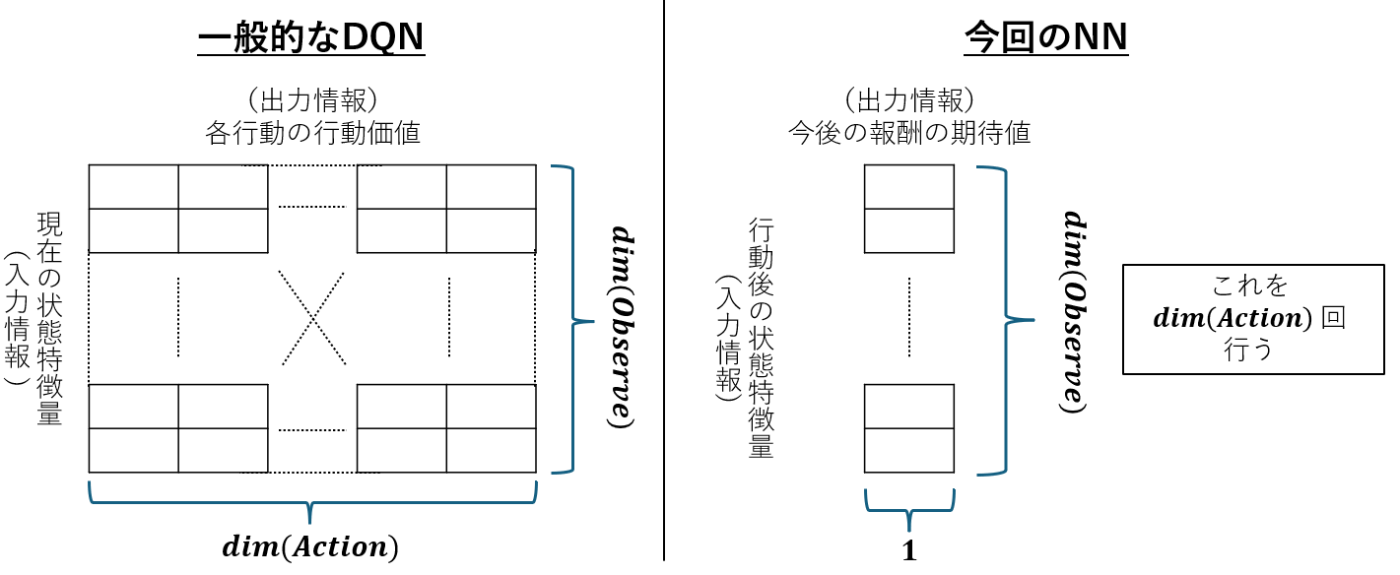
一般的な DQN と今回の NN の違い
当初は DQN を作成しようとしたのですが何故か上手くいきませんでした。(実装ミスなのかモデルが単純すぎたのか、はたまた行動集合の定義が良くなかったのか…)そのためモデルで求めるものを汎化して、「全ての行動の行動価値」ではなく「今後の報酬の期待値」として学習させてみたところうまくいったので、このモデルを採用しました。
ただし理論上 DQN はできるはずなので、今後も色々実験して試していこうと思っています。
層の深さの設定
初めは 128 ⇒ 64 の 2 層のネットワークを使用して学習をしていましたが、これだとラインを全然消してくれませんでした。そこで 64 ⇒ 64 ⇒ 32 の 3 層のネットワークに変更したところ、ラインを消してくれる AI まで成長してくれました。
この 2 つのネットワークを考えると、前者のネットワークが持つパラメータの数は
最終的には表現能力には多少の余裕を持たせた方がよいと考え、層を広くして 64 ⇒ 128 ⇒ 64 の 3 層にしています。
パラメータ更新(TD誤差)
パラメータの更新は TD 誤差を用いた更新式を用いています。今回類推する時刻
TD 誤差を初めて聞いたという方は以下の記事が分かり易いので是非見てみてください。
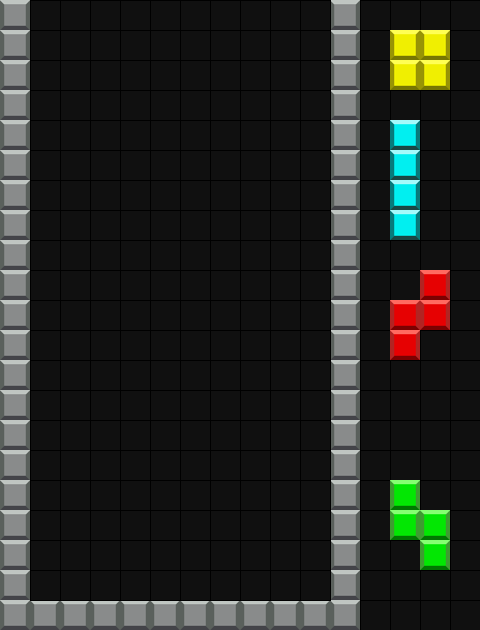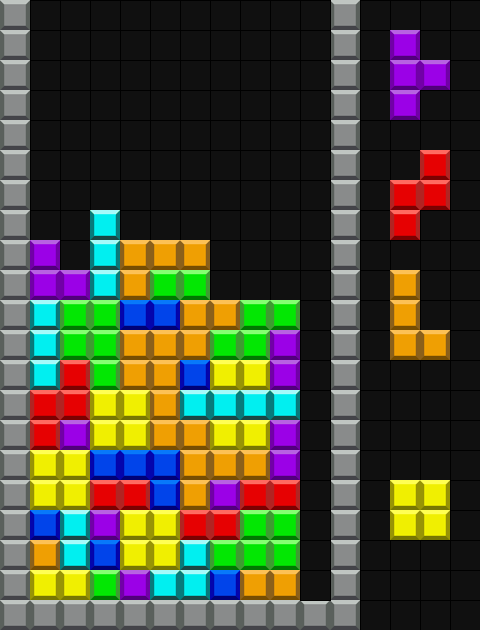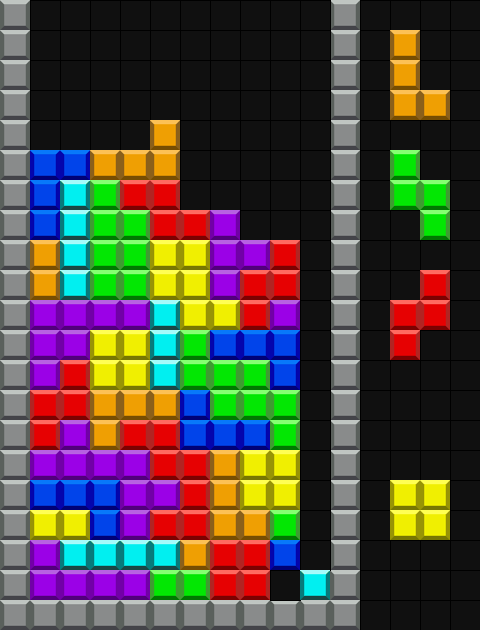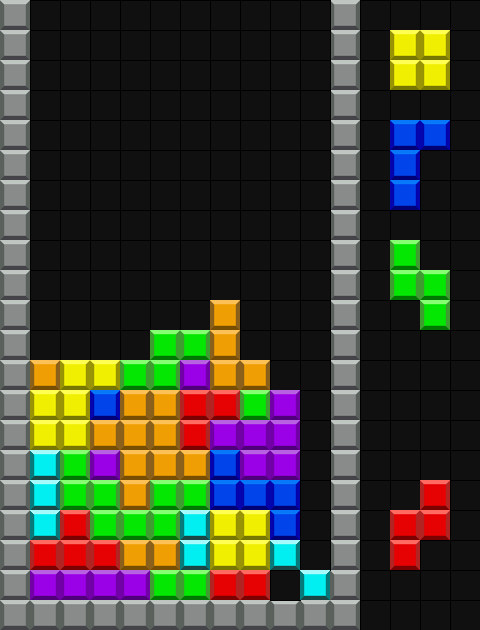
ここまでを実装し、盤面の各セルにあるミノとネクストミノ・ホールドミノの種類を入力として雑に学習するだけで、下記の様にラインを消してくれるようになってくれました。しかしまだまだ穴が多く見られ、上部に行ってしまうとすぐにゲームオーバーになってしまっていることが分かります。

上記のモデルで雑に学習させた AI のシミュレーション
より賢く学習をさせる
入力を盤面特徴量に変更
以前のモデルでは、盤面の情報(各セルに配置されたブロックの種類を示す配列を1次元化したもの)と、ネクストミノとホールドミノの種類を連結した配列を入力として使用していました。しかしこの入力情報だと現実的にはまず起こり得ない盤面の情報も考慮されており、冗長な部分が多く含まれています。よって学習の安定性を確保するために、入力情報は今後の報酬の期待値を適切に推定するのに必要な盤面の特徴量に絞って使用します。
今回の学習で用いた盤面の特徴量は以下の通りにしています。
- 各空マスにおける自身より上部にあるブロックの総和(hole_count)
- 直近でライン消しをしたミノの設置高さ(latest_clear_mino_heght)
- 横方向に空マスとブロックマスが隣合う箇所の総数(row_transitions)
- 縦方向に空マスとブロックマスが隣合う箇所の総数(column_transitions)
- 隣り合う列の最も高いブロックの差の総和(bumpiness)
- 左右が空マスのブロックマスが
k \sum{\frac{k(k+1)}{2}} - 中央 4 列のうちの最大の高さ(center_max_height)
- 各列の最も高いブロックの高さの総和(aggregate_height)
この 8 つの特徴量に加えて、現在のミノ + ネクストミノ 3 つ + ホールドミノの種類の番号の計 13 個の情報を入力として学習を行いました。
経験再生 (Experience Replay)
経験再生とは、過去のシミュレーションデータを経験バッファ(Experience Buffer)に蓄積しておき、このデータからいくつかのデータを抽出してモデルを学習する手法です。経験再生は方策オフ(off-policy)の学習手法であり、この性質によって以下のような利点が生まれます。
方策オフ学習の利点
方策オフ学習では、エージェントの行動ポリシー(方策)と収集されたデータの関連性がなく、シミュレーションとは独立して学習が行われます。この性質により、経験再生では次のような利点があります。
- 過去のデータの再利用:方策オフの性質により、経験再生では過去の経験をメモリに蓄積し、効率的に再利用することができます。これにより、データの再利用率が高まり、学習効率が向上します。
- データの時系列要素の低減:シミュレーションデータをバッファに蓄積してランダムにサンプリングするため、経験再生では時系列な要素が低減されます。このことが過学習のリスクを減少させ、学習の安定性を向上させます。
経験再生を導入して学習させると、以下のような動きをするモデルができました。
ここまでを実装した時の AI のシミュレーション
ラインはよく消してくれるものの、見て分かる通り画面上部でラインを消していることが多いです。これは下部でラインを消していくことを学習するより前に、上部だけでも十分にラインを消せることを学習してまっています。自ら上段だけを使うという縛りプレイをする AI が出来てしまいました。
そして上部だけで解決できるようになるとバッファに溜まる学習データも上部のものが増えてきて、一気に過学習が進んでしまいます。
このような学習データが学習進度によって偏ってしまう現象を防ぐべく、経験バッファを 画面上部・下部の二つ で持って、上部と下部から同じ数だけデータをランダムサンプリングして、それらを合わせたデータを 1 つのバッチとしてバッチ学習をさせました。すると画面下部と上部がうまく連結され、安定してラインを消してくれる AI が作成出来ました。gif ではそもそも高く積まれることが少ないですが、実際に高く積まれたときでも安定して画面下部まで戻ってくることが可能です。

最終的なテトリス AI のシミュレーション(冒頭の gif と同じ)
番外編(火力の高い AI を作る)
番外編として、生き延びる AI とは別で火力の高い(スコア効率の良い)AI も作ってみたいなと思ったので作ってみました。ここまでで作成した AI もそこそこスコア効率が良いですが、もう少し工夫して 3・4 Line 消しの頻度が増えるようにしてみました。まだまだ改善途中なのですが、やったことはざっくりいうと下記になります。
- 3・4 Line 消しの学習データを経験バッファに長居させる
- 積み込みが綺麗であるほど追加報酬を入れて Fine-Turning
- 3・4 Line 消しが出来る場合は優先的に行う
1, 2 つ目は3・4 Line 消しの頻度を高めるべく、積み込みがうまくいくようにするために設定しています。また 3 つ目は生存率を高めるためにやっています。火力の高い AI は一度に多くのラインを消す都合上、ミノを溜め込んでしまう傾向があります。積み込みは凄く綺麗にできても積みすぎてゲームオーバーになってしまう悲しい AI になってしまうのを防ぐべく、適度に 3・4 Line 消しを消費することで事故を起きにくくしています。
(※ 下記の gif は積み込みがある方が映えるため 3・4 Line 消しの頻度を少な目にしています)
ただ、ミノの来る順番によってはかみ合わずに、積み込みがうまくいかずにゲームオーバーになってしまうことがそこそこあります。生存の長さとしては、先ほどの半永久的にラインを消してくれる AI は 100,000 ラインは優に超えてきますが、この AI は現状だと平均 30,000 Line ほどでゲームオーバーになってしまうため、まだ改良は必要そうです。
火力の高い AI のシミュレーション(見た目はすごく良い)
終わりに
今回の学習の経過を X(旧Twitter)に乗せていたのですが、改めてみるとしっかり成長している過程が見えてとても良いです。今回記事を書いてる際に、情報が整理できて改善点や今後やりたいことが続々出てきたので、時間がある時にやってみようかなと思っています。(うまくいったら記事を更新するかも?)
- 設置個所を全探索して行動パターンを生成することで Spin にも対応する
- DQN や SAC のような他のアルゴリズムでも AI を作成してみる
- 使用する特徴量の相関分析をして入力の質を高める
- 1 操作当たりの時間制限を用いてヒューリスティック的な手法で AI を作成して比較してみる
- フィールドの大きさ・形・出現ミノ等を変更したり、対戦ルールに発展させたりする
今回の開発は松尾研主催の RL Spring Seminer 2024 の課題として、友人 2 人含め 3 人 (@through__TH__, @sor4chi, @solehamugoiyo3)で開発をしました。
ずっと手を出せていなかった機械学習に手を出せた良い機会になったので楽しかったです。テトリス AI はゲーム AI の題材として扱いやすいと感じたので、みなさんも是非作ってみてください!
Discussion
こんにちは、記事を拝見させていただきました。
現在私も強化学習未経験でテトリスのAIを作成しようとしているのですが、調べても分からない点がいくつかあったのでご質問させてください。
まず1点目に、Input(14)の14という値がどこから来たのかが分からないです。盤面の特徴量とnext,holdミノが入っているのかと思ったのですが、それだと数が足りないので他に何を入力値として入れているのかを教えていただきたいです。
次に、私はjsでTensorFlowを使って作成しようとしているのですが、chatGPTに聞いたところinputDataのほかにもtargetDataというエージェントが達成しようとする目標や、望ましい行動の情報が不足していると言われました。このデータについてthroughさんのtetris-projectのコードを確認したのですが、私の勉強不足でどこにそのデータが入っているのかが分かりませんでした。テトリスのラインを消した数などが入るという認識で合っているのでしょうか?もしよければ、コードのどの部分で実装されているのかを教えていただきたいです。
以上、長文になってしまいましたがよろしくお願いいたします。
コメントありがとうございます。
返信が遅れてしまい申し訳ありません。
これはこちらのミスでした。
正しくは、盤面の特徴量(8個)+ 現在のミノの種類 + ホールドミノの種類 + ネクストミノの種類(3個)の計 13 個を入力として持っていることになるので Input(13) になります。(記事の方は修正しておきました。ご指摘ありがとうございます。)
なお今回用いている特徴量に関するプログラムは以下の部分になります。
今後 AI の改良があった場合、現在のリポジトリとここの記事に書かれている特徴量やモデルに差異が出る事があると思うので、記事は参考程度で見て頂けると幸いです!
認識が違うような気がします。
ここでいう「targetData」は、おそらく「実際にテトリスを動かして得られたデータ」の事を言っているのかなと思います。今回のプログラムで言うと以下の部分になります。
また「望ましい行動」というのは、下記の get_action 関数のことを言っているのではないかと思います。これは今の盤面からどういった行動をすべきかを返す関数になっています。これは本番フェーズと学習フェーズで異なります。
本番フェーズの get_action 関数は Greedy 法 という「常にNN が推測する最高の行動を選択する」手法になります。プログラムは以下に該当します。
一方、学習フェーズの get_action 関数は ε-Greedy 法 という「一定の確率でランダムで動いて、それ以外の確率で今の NN が推測する最高の行動を選択する」手法になります。プログラムは以下に該当します。
今回の NN を大まかに説明すると、
という感じになります。
よって、本来 NN があるべき姿として必要になるのが「targetData」であり、またシミュレーションを遂行するうえで必要になるのが「望ましい行動」であるという認識が正しいと思います。