Windowsで深層学習環境(Linux + Radeon)を構築する
はじめに
皆様〜お久しぶりです。
前回からずいぶん時間が経過してしまいました。この間資格取得や転職活動などバタバタしておりました。色々ネタは用意していたんですが、ここ最近のAIの進化スピードが異常なため執筆の機会を失ってしまい…。
と、言い訳はこの辺にしておき無事転職と参画案件も決まったためブログの執筆を再開していくことにしました。
間違いが出てくると思いますが、そこは優しく指摘してくださると今後の励みになります!
さて、ここから本題です。前回はOllamaを使ってdeepseek-r1を実際に使ってみましたが、今回から本格的に学習も含めてローカルLLMで遊んでみることになりました。なぜローカルでLLMを自作してみようかと思ったきっかけはこちらになります。
ローカルでどこまで出来るか挑戦してみる価値があると思い手を挙げました!さたけさんありがとうございます!
LLMを自作するWindows PCのスペックは以下となります。
- OS:Windows11 home
- version:24H2
- CPU:AMD Ryzen7 7800X3D 8-core
- RAM:32GB
- GPU:AMD Radeon RX 7800XT(16GB)
前回のブログでもご紹介しましたがゴリゴリのゲーミングPCです。本当はNVIDIAのグラボを使いたいのですが最近はデータセンター向けでがっぽり稼ごうという魂胆からゲーミング向けを疎かにしているんじゃないかと疑っておりますちょっとお高い傾向があるため、予算の関係から7800 XTを選びました。とはいえこれでも4070〜4070Tiぐらいの性能はあるので満足しております。
Linuxの導入
まずはLinuxのインストールから。LinuxのディストリビューションはUbuntu(24.02)を選択しました。これをWSL2を利用してWindows上で実行します。WSL2についてはMSの公式ドキュメントを参照してください。
ROCmについて
続いて、肝心の学習環境について。正直深層学習についてはどうしてもcuda縛りと言われるぐらいGeForce系が強いというかGeForce系でないと深層学習は不可能と思い込んでおりました。ですが、ちょっと調べれば出て来ますね先人達のありがたい教えが。こういった機会がなければしょーもない先入観で自分の可能性を潰してしまうところでした。改めて偉大な先人達に感謝いたします!
ROCmは簡単にいうとAMD版cudaです。こちらも詳細は公式のホームページを参照してください。
環境構築
環境構築の作業手順は以下を参照しました。
- AMD ROCm公式ドキュメント
https://rocm.docs.amd.com/projects/install-on-linux/en/latest/install/quick-start.html - LaR様
https://zenn.dev/lar/articles/7fa7e76cde3d72
ROCmからPyTorchのインストールまで上記を参考にすれば一気貫通で可能です。躓くことはないと思います。Ubuntu24.02にPython3がデフォでインストールされていることを知らず一からやり直したのは内緒です。
動作検証
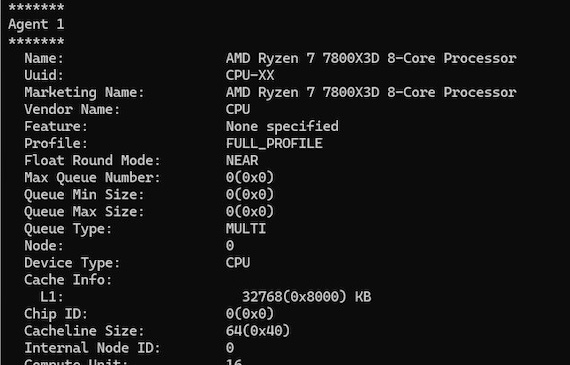
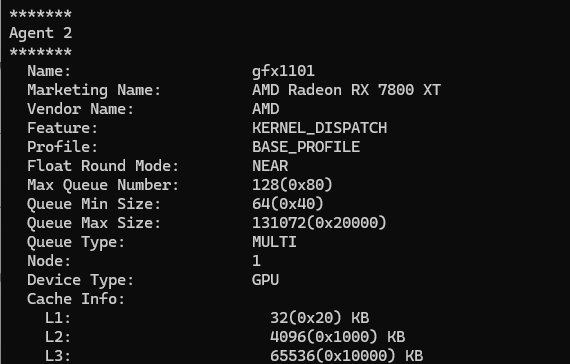
では実際に構築がうまく出来たか検証してみました。以下コマンドを入力。
rocminfo
無事デバイスが認識されていました!
PyTorchが使用出来るか確認してみます。
python3 -c 'import torch' 2> /dev/null && echo 'Success' || echo 'Failure'
Success
Successと返ってきたので問題なさそうですね。試しに簡単なスクリプトを書いて実行してみました。
import torch
x = torch.rand(5, 3)
print(x)
こちら5rows, 3columnsのテンソルをランダムで生成するスクリプトです。
tensor([[0.4026, 0.9260, 0.5777],
[0.2741, 0.7666, 0.3937],
[0.0074, 0.6882, 0.6361],
[0.6924, 0.3175, 0.0186],
[0.9877, 0.4112, 0.9017]])
ちゃんと出力されましたのでPyTochはインストールされてますね!
続いてGPUが使用出来るか確認してみます。
python3 -c 'import torch; print(torch.cuda.is_available())'
True
こちらもTrueが返ってきたのでGPUが使用できそうです。先ほどのスクリプトをちょちょいといじってGPUが使用出来るか試してみましょう。
import torch
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
x = torch.rand(5, 3, device=device)
print(x)
GPUが使用出来る場合Using device: cudaが主力されます。なぜrocmではないのかと思われますが、現状のPyTorchではそういう仕様(GPU関連の機能がtorch.cudaモジュールに集約されているため)だそうです。
Using device: cuda
tensor([[0.2009, 0.7434, 0.1094],
[0.3940, 0.1086, 0.5196],
[0.0984, 0.6546, 0.2834],
[0.2612, 0.5227, 0.2385],
[0.9329, 0.5524, 0.4900]], device='cuda:0')
いちおうGPUを使用出来ているようです。
無事深層学習環境は構築できたので、次回以降は実際に学習をして行こうと思います。まずはオープンソースのLLMを利用してファインチューニングから挑戦してみようと考えています。ではまた次回にお会いしましょう!
Discussion