\スニダンを開発しているSODA inc.の Advent Calendar 2024 2日目の記事です!!!/
どうも、ぎゅう(@gyu_outputs)です☺️
Batch処理のアーキテクチャを提案したので、こちらを解説していきます👍
ある日、それは起きた
ある日突然、これまで動いていた一部のCICDが動作しなくなった。
「なぜだ!?」
このままだと、本番反映できなくなってしまう。
調査すると下記のエラーによる原因だと判明した。
System.IO.IOException: No space left on device
「No space left on device」ということで、github actionsのrunnerの容量不足が原因だとわかった。
でも、なんで容量がパンパンになっているの??
肥大化した原因
batchビルド時にエラーになっていたため、ローカルでビルドして容量を確認する
/go/src/hoge # du -h /go/bin
6.3G /go/bin
「え、6.3GB!!多すぎる!!?」
どうして??
実は、各バッチをバイナリー出力していたため、容量が肥大化をしていた
同じRepositoryなどを利用しているので、無駄が多い状況でした
/go/src/hoge # du -h /go/bin/*
22.2M /go/bin/batch-hoge-a
22.2M /go/bin/batch-hoge-b
22.2M /go/bin/batch-hoge-c
22.2M /go/bin/batch-hoge-d
22.2M /go/bin/batch-hoge-e
22.2M /go/bin/batch-hoge-f
22.2M /go/bin/batch-hoge-g
...etc
ズラーーーーー...。
oh!無駄に容量を消費していますね
過去にも同様な問題があったが、その際はrunnerの不要なライブラリを削除して、容量を空けて解決していた。
同じ方法でさらに容量を空けるのは難しいため、runnnerのスケールアップすることで暫定対応することにした。
しかし、今後も同様な問題が生まれてしまうため、対応策を練る必要があった。
バッチ処理を追加すればする程、runnerをスケールアップさせる状況は脱したい!!
CDの実行時間にも影響していた
この個別にバイナリー生成する方法ですが、CDにも影響していました。
デプロイ時にBatch処理を個別にビルドするので、Batch処理のビルドがボトルネックになっていました。
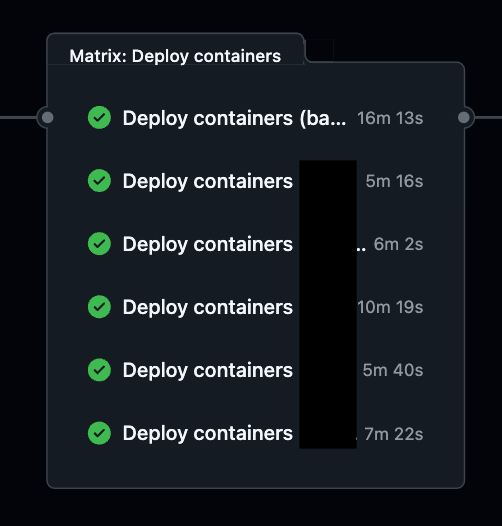
他は数分なのに、Batchのビルドだけ16minかかっています。
明らかに遅いです。これは各Batch処理をビルドしているためです。
「デプロイ時間をこれ以上伸ばさないためにも、バイナリー生成をやめなければ!!」
CICDの改善に関しては、下記の記事で解説をしています。よければ後で読んでみてください。
なぜ、このような状況に?
結論、EC2運用時の名残です。
EC2運用時に、Batch処理を個別にバイナリー生成してcronで運用されていた。しかし、ECS移行時に既存のBatchをまとめた。その際に個別バイナリーから脱却するか議論されていたが、移行コストなどを考慮してそのままバイナリーを利用する方針となった。Batch処理が実装されるたびにバイナリーが生成され、結果的に6GBまで容量を圧迫してしまった。
要点
バッチ処理を個別にバイナリー化したことで、2つの課題が発生した。
✅ 容量の圧迫
✅ デプロイ時間が伸び続ける
これ以上の悪化を防ぐために、アーキテクチャを変更
個別にバイナリー生成するのが望ましくないとわかったので、別の実装方法を用意しなければなりません。そこで、HashMapでBatch処理を管理するように変更しました。
Before: batch管理のpkgとbatch関数のバイナリーで構成。
After: batch管理のpkgで定義された関数を実行し、一つのバイナリーで完結。
この実装方法であればバイナリー1つに処理をまとめられ、容量の肥大化とrunnerのスケールアップを避けられます
バッチ処理のInterfaceを定義
バッチ処理の共通Interfaceとして、CMDを定義する
package types
import "context"
type CMD interface {
Exec(ctx context.Context, flags Flags)
}
Flagsはmap[string]any型であり、Batch実行時のフラグで渡された値を管理する。フラグから値を取得する際は、冗長にならないように値を取得する関数を持つ
package types
import (
"errors"
"strconv"
)
type Flags map[string]any
func (f Flags) GetIntFlag(key string) (int, error) {
val, ok := f[key]
if !ok {
return 0, errors.New("key not found")
}
if intVal, ok := val.(int); ok {
return intVal, nil
}
strVal, ok := val.(string)
if !ok {
return 0, errors.New("value is not a string")
}
intVal, err := strconv.Atoi(strVal)
if err != nil {
return 0, errors.New("value is not a valid integer")
}
return intVal, nil
}
func (f Flags) GetStringFlag(key string) (string, error) {
val, ok := f[key]
if !ok {
return "", errors.New("key not found")
}
strVal, ok := val.(string)
if !ok {
return "", errors.New("value is not a string")
}
return strVal, nil
}
これらの関数を利用して値を取得する
exampleID, err := flags.GetIntFlag("exampleID")
Batch処理を実装する
このInterfaceを満たすBatch処理を実装する
package example_batch
import (
"context"
"fmt"
"batch/types"
)
const BatchName = "example_batch" // Batch名を定義し、Mapのkeyに利用する
type cmd struct{}
func NewCommand() types.CMD {
return &cmd{}
}
func (cmd *cmd) Exec(ctx context.Context, flags types.Flags) {
// バッチ処理を実装
}
MapでBatchを管理する
CMDInterfaceのMapであるcmdMap作成し、Batch処理を管理する。
// mapでBatch処理を管理する
var cmdMap = map[string]types.CMD{
example_batch.BatchName: example_batch.NewCommand(),
}
環境ごとにMapを分けたい場合は、prodCmdMapのように実行環境ごとにMapを用意します。
あとはmain()にて、mapを利用してBatchを実行させるだけです。
func main() {
...
batchName, batchPath, args := parseArgs(os.Args)
...
// Map内にBatch処理があれば、実行する
if cmd, exists := cmdMap[batchName]; exists {
flagMap := ParseFlags(args) // フラグから必要な値を取得する
cmd.Exec(ctx, flagMap) // Batch処理の実行
return
}
// existsでなければ、バイナリーを実行してBatch処理を実行する
...
}
ECS RunTask等でBatchを実行させたい場合
実行時は他と変わりありません。スケジュール実行させたり、ECS RunTaskで実行させます
// ECS RunTaskで実行させる場合、BatchNameを指定して実行する。
if err := usecase.worker.RunECSTask(ctx, example_batch.BatchName, args); err != nil {
logger.Error(ctx, err)
return err
}
やらなかったこと・今後の方針
すべてのBatchを移行しない
過去のBatch処理の移行も検討しましたが、移行コストとそのリターンを考えると、過去のBatch処理は移行しない方が得策だと考えました。MapでBatch関数を管理すれば、そうそうrunnerをスケールアップする必要もありませんし、エンジニアを動員するコストとrunnnerの費用を考えるとrunnerをそのまま利用した方が安いです。それなら、機能開発を優先した方が得策です。
今後の方針
今後の対応としては下記の3点を定めました。
- Batchの新規実装はMapで管理する
- Batchの改修時にMapへ移行する。
- 利用していないBatchは削除する
一気に移行せず、徐々に移行するようにしました。改修頻度が高いものからMapへ移行されるので、ビルド時間は将来的には短縮されていきます。
おわりに
この課題を通して、設計の理解度が高まりました。
SODAでは、優秀なメンバーでバシバシ機能開発を進めており、学びが多いです。
AIを積極的に利用しはじめていたり、AWSさんと連携して課題解決したりしています。
興味がある方はぜひリクルートページを見てみてください☺️

株式会社SODAの開発組織がお届けするZenn Publicationです。 是非Entrance Bookもご覧ください! → recruit.soda-inc.jp/engineer
Discussion