\スニダンを開発しているSODA inc.の Advent Calendar 2024 1日目の記事です!!!/
どうも、ぎゅう(@gyu_outputs)です☺️
「どうすれば、CICDの実行時間を短縮できるの???」
こちらを解説していきます👍
面白かったら、いいね押してもらえると励みになります☺️
本記事で学べること
✅ ボトルネックの調査方法
- Github Actionsで調査する場合
- Datadogで調査する場合
✅ 実行時間を短縮するための4つの方法
- Github Actionsのrunnerをスケールアップ
- 並列実行
- キャッシュ
- スキップ
これらの結果、実行時間が28min→12minまで短縮することができました。
その方法を具体的に解説していきます
宣伝
優秀なメンバーが所属しているので、ぜひ採用ページも見てね☺️
背景
サービスも6年運用されて規模もずいぶん大きくなりました。ソースコードが莫大に増えたため、どうしてもCICDの実行時間が伸びてしまいます。
- 障害発生時に、CIの実行時間が長いと修正までに時間がかかる
- DEV環境の反映に時間がかかり、検証が遅れる
CI待ちなどのフラストレーションも生まれますし、DEV環境へのデプロイすることの抵抗感なども生まれてきます。
この課題を解決するために、CICDの実行時間の短縮を試みることになりました。
ボトルネックの調査
CICDの実行時間を短縮してほしいと言われて、「はて?何から始めようか?」となるかと思います。
結論としては、一番遅いPipelineやJOBの実行時間を短縮して、解決していきます。
そのため、ボトルネックの調査方法を知る必要があります。
ポイント
✅ ボトルネックを調査できるようになろう
Github Actionsで調査する場合
Github ActionsのSummaryからそれぞれの実行時間を確認して、特定することができる。

具体的なテスト名などは記載できませんが、赤枠の箇所がボトルネックだとわかります。
テストの種類としては、Integration Testです。
Unit Testは早いのですが、Integration TestはDBにデータをセットする必要があるため、実行時間はやはり長いです
今回はSummaryで確認しましたが、管理者と連携して実行時間のCSVをエクスポートして共有してもらうのも一つの方法です。
他にもGithub APIで分析する方法もあるようなので、そちらも検討しても良いかと思います
Datadogで調査する場合
sodaでは監視ツールにDatadogを利用しています。DatadogでCICDのボトルネックを特定していきます。Github Actionsでも特定は可能だが、目視で比較する作業が必要なため、作業効率は良くない。そこで、Datadogを活用して調査する。
パイプラインのボトルネックの調査
Software Delivery > CI Visibilityの Execurationsを開く

極端に実行時間が長い・短いログを除外する。
これは下記の2点の要因があるためです。
- Github ActionsのJOB Queueが溜まると、実行待ちになるため実行時間が極端に長くなることがある。また、何かしらGithub Acitonsの不具合で実行が進まないこともあるため。
- スキップされて実行時間が極端に短いものがある。

これらを無くすには、ステータスとDurationで実行時間を絞り込むと良い

また絞り込み条件のCI StatusからCancelとErrorを外し、Successだけで絞り込む
絞り込み条件が整ったら、Top Listタブを選択する

棒グラフ形式でわかりやすいですよね。
何より客観的な値が出ているので、見る側も納得しやすいです。
表示内容は下記のようにしています。
- 平均値の出力設定
- Duration(実行時間)
- Pipeline Name
- Top 10を表示
これでPipelineのボトルネックがわかります。
Pipeline名などは隠しておりますが、下記のPipelineを改善する必要があるとわかりました。
- デプロイ
- 直列のUnit Test
- Integration Test
- 並列のTest
Jobのボトルネックを特定する
Datadogで実行ログの詳細を開きます
すると、各JOBの実行時間が視覚的にわかります。

これでもわかりますが、Critical pathに✅を入れます。
これでボトルネック箇所だけが色がつきます。

優先的に対処すべき箇所が一目でわかりますね👍
めっちゃわかりやすいですよね!!
すごくないですか!?
はじめて知ったときは、衝撃でした。
今回のボトルネックは特定のディレクトリ(パッケージ)配下のテストでした
他の条件でも調べたい場合
絞り込み条件などを変更したい場合は、Infoタグを選択し、絞り込みたい項目ををFilter byすれば良い

今回はPipelineから調べていますが、実行ログの一覧をPipelineからjobに変更することもできます。

改善策
ボトルネックを特定したら、対象のJobを改善していきます。
改善方法は、大きく分けて4つの方法があります。
- スケールアップ
- 並列
- キャッシュ
- スキップ
1.Github Actionsのrunnerをスケールアップ
ボトルネックとなるJOBに対して、runnerのマシン性能を上げて、実行時間の短縮する。
料金は上がりますが、早期に解決できれば機能開発に戻れます。
経営陣としても早く開発に戻ってほしいので、まず最初に検討すべきでしょう。
※資金に余裕がないフェーズでは、得策ではない。
後述する他の施策で実行時間を短縮し、浮いたコストでrunnerをスケールアップするのが理想です。
結果
スケールアップすることで**30%**ほど実行時間の短縮できました
ボトルネックになった直列のUnit Testを2core→4coreに変更
具体的な部分はぼかしますが、下記のようなイメージです。
test(A領域):
- 25m -> 17.5m (-30%)
test(B領域):
- 22m -> 14m (-34%)
integration testは4core→8coreに変更
api:
- 24m -> 18m18s (-24%)
有用性がわかったところで、理解を深めていきましょう
large runnerの利用方法
runnerをスケールアップしたものをlarge runnerと呼ばれています。
このlarge runnerはrunner groupsを介して利用します。
流れ
- large runnerを利用したrunner groupsを作成
- 対象のJOBにrunner groupsを適用する
設定方法は下記がわかりやすいです。
GitHub Actions で 大規模ランナー(GitHub-hosted larger runners)が GA となりました | DevelopersIO
設定画面の変更等もあるので、一度公式ドキュメントを確認いただくと良いと思います
公式は図表もあるので、仕組みを理解するのに最適です
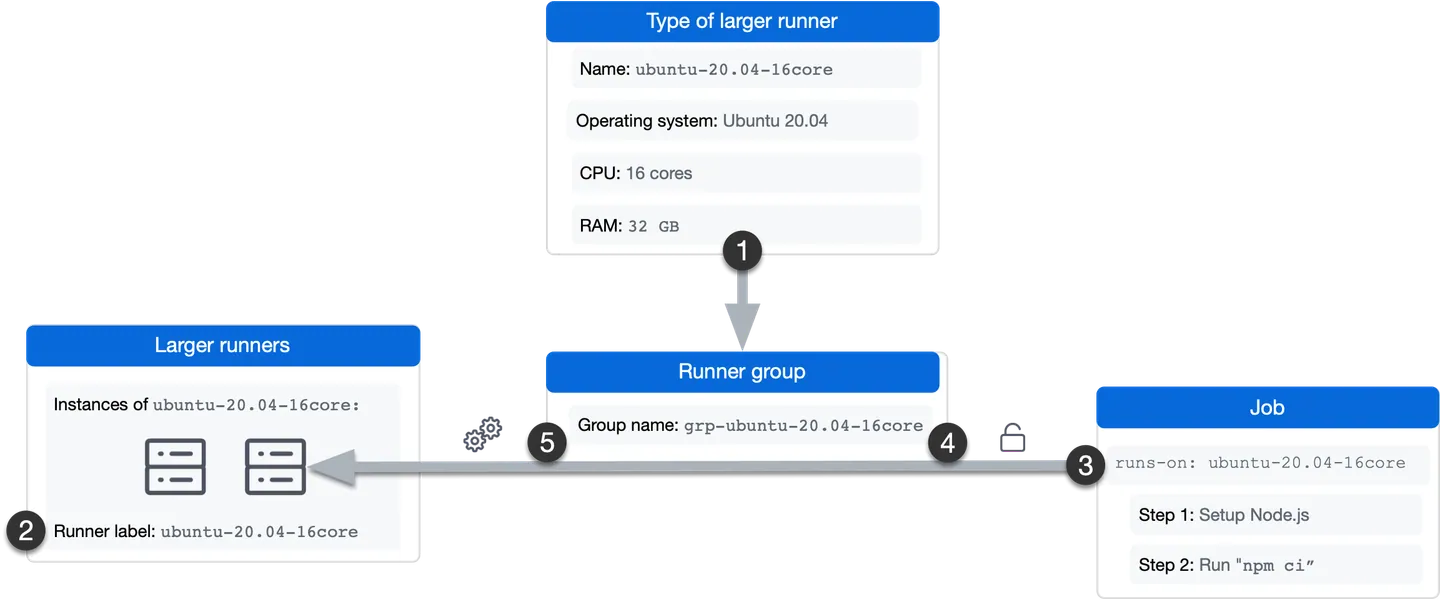
- このランナーのインスタンスは自動的に作成され、grp-ubuntu-20.04-16core というグループに追加されます。
- ランナーにはラベル ubuntu-20.04-16core が割り当てられています。
- ワークフロー ジョブは、runs-on キーの ubuntu-20.04-16core ラベルを使用して、ジョブの実行に必要なランナーの種類を示します。
- GitHub Actions は、ランナー グループをチェックして、リポジトリがランナーにジョブを送信する権限があるかどうかを確認します。
- このジョブは、ubuntu-20.04-16core ランナーの次に使用可能なインスタンスで実行されます。
対象のJOBにrunner groupsを割り当てる
runs-onでgroupを指定します。
// Before
jobs:
hoge:
runs-on: ubuntu-22.04
// After
jobs:
hoge:
runs-on:
group: grp-ubuntu-22.04-8core
見てわかる通り、特に難しいことはしていないです
簡単ですね!
ポイント
✅ runner groupsを作成して、JOBに割り当てる
runnnerの性能と料金体系を知る
プライベートリポジトリの標準runnerの性能は、公式ページに記載されています。

より性能が高いlarge runnerの性能は、下記の公式ページに記載されています。
今回は、よく利用されているubuntuを見ていきましょう

CPU, メモリ, ストレージそれぞれが倍増されていくのがわかります。
では、それに対して料金はどれだけ上がるのか確認しましょう。
x64の場合、0.008ドルから倍増されていくのがわかります。

続いてARMを見ていきましょう

「あれ、安くない?」
そう、x64よりも破格なのです!!
0.005ドルから倍増されていくので、0.003ドルから節約できます。
初めて知ったときは、逆に安くなるのか!?と衝撃でした
x64の2コアとARMの4コアの金額差は0.003ドルです。この料金差なら許容できることも多いでしょう。
ARMの料金体験などは今後変更されるかもしれないので、一度確認しておくとよいでしょう
ポイント
✅ x64を利用しているなら、ARMに置き換える
見積もり
思った以上に料金は変わらないかもしれない。
とはいえ思わぬ請求は避けたいところですよね。
やってみた気づきとしては、下記の2点です
- 現状の金額をCSVエクスポートしてもらうなど、金額面の調査をした方が良い
- Datadogで1ヶ月の実行時間を調べるなどしても良かったかもしれない
リポジトリの責任者であれば、Github Actionsの請求金額を確認できます。
なので、CSVでjobの実行時間をエクスポートしてもらいましょう。
- Github Actionsの実行時間をCSVにエクスポートしてもらう
- 対象のJOBの月間の実行時間を集計する
- 料金を算出する
これがベストだと思います
CSVのエクスポート方法は下記を参考にしましょう
Datadogでも実行時間を確認することができます

ただこれはBillable timeではないので、見積もりという観点ではあまり利用できない。
なので、CSVで確認するのがベストかと思います
ポイント
✅ 見積もりはCSVをエクスポートして確認しよう
2.並列実行
- JOBの実行順を見直す
- golintの並列実行
- ビルドタグを利用した並列実行
2-1.実行順を見直す
例えばBuildしてデプロイする際に、Batch処理がボトルネックなら、早い段階にビルドを進めてしまいます。
結果的に5minの短縮することができました。

workflowの流れとしては下記の順になっています。
- assetのアップロード
- assetのアップロード後に、コンテナのビルドしてデプロイ
- デプロイ
この処理の中でBatch処理のビルドがけ時間が15minと長いです。

Datadogで確認すれば、一眼でボトルネックだとわかります

このBatchのビルドが長い問題は次回解決していきます。
(これ以上の悪化を防ぐために、アーキテクチャの見直しもしています。)
ひとまず、工数をかけずに解決をしたい。
そこでbatchコンテナのビルドを早い段階で実現できないか模索します。
今回の場合だとビルドの前にassetのアップロードを行っているので、assetのアップロードと並列で行えか模索します。assetはフロントエンドで利用するものが含まれています。batchは画面表示などするわけでもないので、assetが不要です。
なので、assetアップロードと同時にbatchのビルドも進めてしまいます
- assetのアップロード、各コンテナのビルドを同時に進める
- batch処理はビルド完了後、即座にデプロイする
- assetが必要なコンテナは、assetのアップロード後にデプロイを実行
workflowは下記のようになります

画像でわかる通り、batch処理ではassetのupload完了まで待機していません。
このようにworkflowの処理をスライドすることで、スライドした実行時間の5分を短縮できました
JOBの実行順を見直し、スライドすることが可能であれば、スライドして実行時間を短縮させましょう
結果
こちらもrunnerのスケールアップと併用することで
平均値が29min → 18minまで短縮することができました

ポイント
✅ JOBを分割して、スライドしよう
2-2.golintの並列実行
他のボトルネックを削っていったとしも、go-lintの実行時間が遅ければ、それ以上早くはできない。

そのため、go-lintの実行時間を短縮して、実行時間の下限をさらに下げます。
golangci-lint-actionでconcurrency=0を指定することで並列実行します。
なぜconcurrencyに0を指定するかはドキュメントに説明が書かれています
翻訳したものですが、下記のように記載されています
golangci-lint を同時に実行できるオペレーティングシステムのスレッド (
GOMAXPROCS) の数。
もし明示的に 0 に設定されている場合(つまりデフォルトではない場合)、golangci-lint は Linux コンテナの CPU quota に合うように自動的に値を設定します。
Default:マシンの論理CPU数
値を0で設定した場合、LinuxコンテナのCPU quotaに合うように、同時に実行できるオペレーティングシステムのスレッドが自動的に値が設定されます。
それでは
- name: golangci-lint
uses: golangci/golangci-lint-action@v3.7.0
with:
args: --timeout 20m
args: --timeout 20m --concurrency=0 // concurrencyを0にして並列実行
.golangci.ymlは下記のように書くこともできる。
run:
concurrency: 0
timeout: "20m"
これにより16minほどかかっていたgolangci-lintが8minほどに抑えられています。

これでMAXで8minまで短縮することができます。
2-3.ビルドタグを利用した並列実行
integration testがボトルネックになっています。
この原因は、各テストでDBをリセットし、肥大化した共通テストデータが読み込むためでした。共通テストデータを分解し、テストに必要な最小限のテストデータのみを取り組むことで根本解決されます。しかし、テストの量が多いため時間がかかります。また、すでにmatrixでテストを並列実行していることもあり、別の対策が必要でした。
そこで、取得処理のテストと書き込み系のテストを分けることにしました。
GET処理のみでまとめてしまえば、テストデータは最初のセットアップの一度で済みます。また、テストの並列実行ができれば、さらに時間短縮が望めます。
そこで、ビルドタグを分割して、書き込み系のテスト・取得系のテストに分けることにしました。
タグ名としてはtest-integration-getのようなイメージです。
- 既存のテストのワークフローを複製し、
test-integration-getビルドタグを指定する - 並列可能なテストで
test-integration-getを指定し、テストデータのセットアップは行わない。並列可能なテストであれば、t.Parallel()をつけます。
各テストをビルドタグを指定するだけなので、3日ほどでテストの移行が完了しました。
大きく実行時間が下がるだろうと考えていました。
しかし、結果は次の通りでした。

テストを移行すると共に緩やかに減少し、19~18minほどに落ち着きましたが、正直なところ期待していたほど短縮はできませんでした。
理由は下記の2つの理由により、並列でテストができなかったためです。
- RedisにAPIの値がRedisでキャッシュされており、実行順によって結果が異なる。
- 実行時間を指定したテストがあり、その時刻で他のテストを行うと失敗する。
3日ほどで完了できた点は良かったですが、課題が残る結果になりました。
ポイント
✅ テストを並列で実行しよう
✅ integrationの場合、キャッシュや実行時の時間などの考慮が必要
3.キャッシュ
Goのキャッシュを再利用します。
詳細に関しては、Advent Calendar 2024 の10日目に公開予定です☺️
ビルドキャッシュを再利用することで、goのビルド時間がグッと減ります。

ビルドキャッシュによりビルド時間が7minほど短縮。
短期間でグッと数値が減少して、平均値が17min以下まで下がりました。
ただし、キャッシュは10GBの上限に達すると、古いキャッシュは削除されるので注意しましょう
リポジトリには最大 10 GB のキャッシュを含めることができます。10 GB の制限に達すると、キャッシュが最後にアクセスされた日時に基づいて古いキャッシュが削除されます。過去 1 週間にアクセスされていないキャッシュも削除されます。
Githubのキャッシュについては、下記でも説明されています。サンプルなども用意されているので一度確認してみると良いでしょう。
- uses: actions/cache@v1
with:
path: ~/go/pkg/mod
key: ${{ runner.os }}-go-${{ hashFiles('**/go.sum') }}
restore-keys: |
${{ runner.os }}-go-
- name: Get npm cache directory
id: npm-cache
run: |
echo "::set-output name=dir::$(npm config get cache)"
- uses: actions/cache@v1
with:
path: ${{ steps.npm-cache.outputs.dir }}
key: ${{ runner.os }}-node-${{ hashFiles('**/package-lock.json') }}
restore-keys: |
${{ runner.os }}-node-
ポイント
✅ キャッシュを再利用して、実行時間を短縮させる
追記ですが、DBのキャッシュなどは下記の記事で改善されたので、一度確認してみると良いでしょう
4.スキップ
最後にスキップの観点です。
影響箇所のみを実行して他はスキップし、ごそっと時間を削ります。
4-1.変更ファイルに合わせてJOBを実行する
例えば、サーバーサイドの修正のみの場合、フロントエンド周りのCIは実行させたくありません。
tj-actions/changed-filesを利用して、対象ファイルがある場合のみ実行する。変更対象のファイルがあるかで判別し、なければスキップさせてしまいます。
name: Set skip-front-test
outputs:
skip-front-test:
description: skip-front-test flag variable
value: ${{ steps.set.outputs.skip-front-test }}
runs:
using: composite
steps:
- id: changed-files
name: 変更ファイルを取得
uses: tj-actions/changed-files@v44 // all_changed_filesがoutputsに含まれる
- id: set
name: 変更ファイルからフラグの値を制御する
env:
ALL_CHANGED_FILES: ${{ steps.changed-files.outputs.all_changed_files }}
shell: bash
run: |
skip_front_test=true
for file in ${ALL_CHANGED_FILES}; do
if [[ $file == src/* ]]; then
skip_front_test=false
break
fi
done
echo "skip-front-test=$skip_front_test" >> ${GITHUB_OUTPUT}
あとは、下記のようにif文でフラグの値を元にスキップさせます。
job-name:
needs: is-skip-front-test
if: ${{ needs.is-skip-front-test.outputs.skip-front-test != 'true' }}
こちらのデメリットとしては、それぞのワークフローでtj-actions/changed-filesを実行する点です。(ただ、そこまで費用はかからないので気にするほどでもありません。)
やらなかったこと:ワークフローの共通化
この対策として、ワークフローを共通化し、はじめに変更ファイルを取得し、それを各ワークフローに渡す方法を試してみました。

結果的に、この方法は利用しませんでした。
ワークフローを共通り用すると、@mainブランチやリリースタグを指定する必要があるため、変更しづらいデメリットがあったためです。
name: ci
on:
pull_request:
push:
branches:
- main
jobs:
call-go-lint:
needs: [check-chenged-files]
if: ${{ github.ref == 'refs/heads/main' || needs.check-chenged-files.outputs.go_files != '' }}
uses: xxx/hoge/.github/workflows/golangci.yml@main // mainブランチを指定
call-actionlint:
needs: [check-chenged-files]
if: ${{ github.ref == 'refs/heads/main' || needs.check-chenged-files.outputs.actions_files != '' }}
uses: xxx/hoge/.github/workflows/actionlint.yml@main
結局ワークフローでの共通化はやめて、そのままusesで変更ファイルを取得するようにしています。料金もそこまで変わらないので、デメリットは気にしなくても良いなという結論になりました
ポイント
✅ 変更ファイルの種類に応じて、実行するCIを切り分ける
4-2.依存関係のあるファイルのみをテストする
再帰的に依存関係を辿っていくことで、必要なテストのみを実行する。
詳細は次の記事で記載しています☺️
アーキテクチャの構成によって実施方法が異なるのですが、ci上でgoファイルを実行し、依存関係を辿っていきます。
その依存関係を元に、テスト実行対象のpackageを絞るという感じです。
結果的に下記のように大きく減少しました
total duration: 26min11秒 → 2min 10s
Bilable: 2h18min → 13min
ごそっと実行時間が短縮されていることがわかります。
アーキテクチャによって実現の難易度が上がるため、依存関係を追いやすいCIも考慮したアーキテクチャにすると良いという学びを得ました。
ポイント
✅ 依存関係のテストのみを実行する
✅ 再起的に依存関係が追えるアーキテクチャ構造にするのが望ましい
その他
Xで良い意見や質問があったので、追記していかもしれないです☺️
今回Front周りは記載していませんが、めちゃくちゃ大切なので記載しました☺️
Frontend側の短縮も行おうとしていて、その際はビルド方法の見直しなどを検討していました。
ただ、そこまでパフォーマンスが向上しなかったので、今回のプロジェクトには適用しなかったです。
このあたりはFrontの構築方法で変わる印象でした。
(きっと良い方法はあるはず...!!)
最後に
これらの取り組みを行なった結果、チーム外からも下記のような声が出てきました☺️
- 「めっちゃ早くにデプロイできる!!」
- 「CIめっちゃ早くなっていてビックリした!!」
嬉しい声ですねぇ☺️
いかがだったでしょうか?
何か参考になる点がありましたか?
- 「知らなかった!!」
- 「参考になった!!」
- 「勉強になりました!!」
え、ホントですか!?
それは良かったです👍
トレンドを目指しているので、よければいいねを押してもらえると嬉しいです
お願いいたします🙏
また、メンバーを常に募集しているので、ぜひ採用ページだけでも覗いてみてね☺️

株式会社SODAの開発組織がお届けするZenn Publicationです。 是非Entrance Bookもご覧ください! → recruit.soda-inc.jp/engineer
Discussion