こんにちは、SODAのSREチームのDucと申します。
GitHub Actionsのコストを削減しながらCIワークフローを高速化したの工夫をご紹介します。
背景
私たちのチームは、snkrdunk.comサイトとSNKRDUNKモバイルアプリの可用性とパフォーマンスの維持に注力しています。
それに加えて、クラウドインフラストラクチャやその他の監視・開発ツールのコスト管理も担当しています。
毎月、AWSやGitHubなどのインフラストラクチャとツールの請求書をチェックしています。
GitHubの請求額が非常に高いことに気づきました。特にGitHub Actionsの部分です。
参考までに、GitHub Actionの使用量とサーバーの本番ワークロード費用の比較をご紹介します。
- Fargate: Savings Plan適用で月額約$7,000。私たちのサービスは平均約5000リクエスト/秒のトラフィックがあります
- GitHub Actions: 予期しないコストを避けるため月額$9000で予算を上限設定していますが、定期的にこの閾値を超えるため、CICDパイプラインが完全に停止することを防ぐために予算を引き上げる必要があります。たまにはGitHubの請求額が$18,000に達することもありました。
GitHub Actions GitHub-hosted Runnerはそんなに高いのでしょうか?
GitHubは2種類のランナーを提供しています:GitHub-hosted Runner(Microsoftが2018年にGitHubを買収して以来Azureで動作)とself-hosted runnerです。
GitHub-hostedはUbuntuにプリインストールされたソフトウェアが付属しており、あらゆる種類のプログラミング言語で非常に使いやすく、しかしかなり単価が高いです。
| Specs | GitHub-hosted | EC2 On-demand | EC2 Spot |
|---|---|---|---|
| x86 2コア、8GBメモリ、75GBディスク、Public IP付き | $0.008 | $0.001818(-77%) | $0.000735(-90.8%) |
Note: EC2のは北バージニアリージョン、m7i-flex.largeタイプを使用する
では、どのように実現するのでしょうか?
オールインワンソリューション
Googleで簡単に検索したところ、2つのリポジトリが目に留まりました。
- Runs-onプロジェクト: https://github.com/runs-on
- Philips Labs AWS self-hosted runnerプロジェクト: https://github.com/github-aws-runners/terraform-aws-github-runner
どちらもオールインワンソリューションで、非常に良くドキュメント化されており、デプロイも簡単です。
私たちのIaCはTerraformなので、Phillips LabsのTerraformモジュールを選択しました。
注:Runs-onは商用目的で使用する場合、ライセンス料(年間$300)が必要です。
このモジュールのアーキテクチャは以下の通りです。

落とし穴
Terraformモジュールのパラメータを設定するだけで、簡単にできるはずですよね?
モジュールをセットアップし、terraform applyを実行し、Organization設定でGitHub Appを登録すると、ダミージョブが期待通りにピックアップされました。

self-hostedランナーが正常に起動できたのを確認できたので、次はすべてのテストワークフローをself-hosted runnerを使用するように変更しました。数日後、いくつかの問題発生しました。
- 試算の通りににコストが安くならなかった
- Docker Hubのレートリミット
- スポットインスタンスがAWSから回収されるため、self-hosted ランナーが強制的に停止られる
- ジョブのキュー時間がGitHub-hosted Runnerと比較してかなり長い
- 一部のジョブが「queued」状態で永遠に詰まる
試算の通りににコストが安くならなかった
数日後、請求書をチェックして、コストが非常に高いことに驚きました。
このプロジェクトに割り当てたタグでCost Explorerに日割りのコストを確認すると、90%はNAT Gatewayの費用でした。

当初、すべてのランナーインスタンスをプライベートサブネットに配置していたため、インターネットと通信する際にNAT Gatewayを使用する必要がありました。
ジョブを実行する前に以下の手順を行う必要があります。
- GitHubワークフローを実行するために必要なソフトウェアをインストールする(curl, git, dockerなど)
- ランナーはGitHub Action runner binaryを取得する
さらにジョブを実行するの際に必ず下記のステップが繰り返します。
- git checkout
- Dockerイメージを取得する
AWSはネットワークに入るデータには課金しませんが、NAT Gatewayを使用する場合、方向に関係なく、NAT Gatewayを通過するデータに対して課金します。
ランナーインスタンスの再利用時に発生する奇妙なエラーを避けるため、エフェメラルランナーを使用しました。これは、すべてのジョブが新しいインスタンスを取得し、完了時にインスタンスが廃止されます。また、上記のすべてのステップが繰り返し実行されるので、NAT Gatewayを通過する大量のネットワークトラフィックが発生しました。
インターネット通信を可能な限り最小限に抑えるため、アーキテクチャにいくつかの変更を行いました。
- 何もないベースイメージからランナーを作る代わりに、カスタムAMIをビルドして使用します。これにより、ランナーがジョブが実行できる状態までの時間が短縮されます。AMI内で、ワークフローで使用するすべてのソフトウェア(我々の場合はCGO用のCライブラリ、Golangマイグレーションツールなど)とDocker image(Golang、MySQL、Redisなど)を準備します。
(Phillips Labsのモジュールは、カスタムAMIをビルドするためのPackerテンプレートのサンプルも提供しています) - Docker Hubからのイメージプル回数を減らし、彼らのレートリミットを避けるため、VPCエンドポイントでプルスルーキャッシュ設定のあるAWS Public ECRに切り替えました。
もう一つの選択肢は、プライベートサブネットの代わりにパブリックサブネットを使用することです。そうすると、各インスタンスに公開IPv4が付与され、独自にインターネットと通信できるため、NAT Gatewayは不要になります。しかし、これもまた、ランナーインスタンスがライフタイム中にインターネットに露出することを意味するため、最低限の通信のみの許可を設定しましょう。
結果として日額コストが$800から約$100に削減できました。

Docker Hubのレートリミット
私たちの1つのテストジョブにはい8つの公式のDockerイメージが必要です。
しかし、Docker Hubには未ログインユーザーに対して、1つのIPv4に対して6時間以内に100回までしかPullできません。

という意味すると、6時間に12ジョブしか実行できません。これは非常に厳しいレートリミットです。
(弊社ではDocker HubでTeam Planを購入しているため、Team Planのユーザーでログインすることでpull rateは無制限になりますがジョブにログインステップが増えてしまいますし、CI専用のアカウント管理の必要が新たに発生するため、Team Planのユーザーでログインすることは避けました)
GitHub-hostedでは問題ありません。すべてのジョブが新しいマシンと新しいIPv4を取得するためです。しかし、NAT Gatewayでは、すべてのインスタンスが限られたIPでDocker Hubと通信するため、Docker Hubから409エラーが発生する可能性が非常に高くなります。
そこで、ECR Public + プルスルーキャッシュ + AWS VPC Endpointに切り替えました。
ECR publicには、ほぼ有名なDockerリポジトリ(Golang、Redis、MySQLなど)があるため、必要なリポジトリを簡単に見つけることができるはずです。
但し、Docker HubのイメージとECRのイメージが異なることに少し懸念を持っています。そこでdocker scoutコマンドを使用して確認してみました。
docker scout compare --to golang:1.24.3-bullseye public.ecr.aws/docker/library/golang:1.24.3-bullseye
i New version 1.18.0 available (installed version is 1.17.0) at https://github.com/docker/scout-cli
! 'docker scout compare' is experimental and its behavior might change in the future
✓ SBOM obtained from attestation, 298 packages found
✓ Provenance obtained from attestation
✓ SBOM of image already cached, 298 packages indexed
## Overview
│ Analyzed Image │ Comparison Image
────────────────────┼───────────────────────────────────────────────────────────────────────────────────┼────────────────────────────────────────────────────────────────────────────────────
Target │ public.ecr.aws/docker/library/golang:1.24.3-bullseye │ golang:1.24.3-bullseye
digest │ cd43396a4113 │ cd43396a4113
tag │ 1.24.3-bullseye │ 1.24.3-bullseye
platform │ linux/arm64/v8 │ linux/arm64/v8
provenance │ https://github.com/docker-library/golang.git │ https://github.com/docker-library/golang.git
│ 6f5593131e9bccda9a4e83f858427d4d0d16b58d │ 6f5593131e9bccda9a4e83f858427d4d0d16b58d
vulnerabilities │ 0C 1H 3M 124L │ 0C 1H 3M 124L
│ │
size │ 280 MB │ 280 MB
packages │ 298 │ 298
│ │
Base image │ buildpack-deps:4724dfb3ebb274c6a19aee36c125858295ad91950e78a195b71f229228a6aaeb │ buildpack-deps:4724dfb3ebb274c6a19aee36c125858295ad91950e78a195b71f229228a6aaeb
tags │ also known as │ also known as
│ • bullseye-scm │ • bullseye-scm
│ • oldstable-scm │ • oldstable-scm
vulnerabilities │ 0C 1H 3M 63L │ 0C 1H 3M 63L
## Environment Variables
GOLANG_VERSION=1.24.3
GOPATH=/go
GOTOOLCHAIN=local
PATH=/go/bin:/usr/local/go/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
## Packages and Vulnerabilities
298 packages unchanged
ご覧の通り、出力された表のAnalyzed ImageとComparison ImageでTarget以外の行に差分がないことが確認できました。
スポットインスタンスがAWSから回収されるため、self-hosted ランナーが強制的に停止してしまう
コストを最適化するため、USリージョン(他のリージョンと比較して最も安価)でスポットインスタンスを活用しています。しかし、このスポットインスタンスタイプであるため、AWSが他の顧客のために必要とする場合はいつでも終了される可能性があります。
しかし、終了率を減らす手段があります。
デフォルトでは、EC2 Fleet APIはスポットインスタンスを取得の際にlowest price戦略を使用します。
- Lowest price -> デフォルト
- Diversified
- Capacity optimized -> 最低終了率
- Price capacity optimized -> 最良の価格-終了率
終了率はAZ間で同じではありません。より多くの容量を余裕を持って持つAZでは、終了率が低くなるはずです。モジュールのinstance_allocation_strategyパラメータで取得戦略を変更できます。

上記の画像からわかるように、capacity optimized戦略に切り替えた後、ランナーの終了率が大幅に改善されました。
(EC2での実行はGitHub-hostedよりも大幅に安価であるため、スポットでの少し高いコストは許容可能だと考えており、また、開発者がPRでジョブを再試行する必要が少なくなるため、より良い体験を提供します)
ジョブのキュー時間がGitHub-hosted Runnerと比較してかなり長い
これには2つの理由がありました。
- 準備ステップ(Dockerインストール、Action binaryセットアップ)は、ランナーが起動する際に少なくとも1分かかる必要があります。これは上記で説明したカスタムAMIを使用することで解決できます。
- EC2のクォータ。
通常、本番ワークロードには東京リージョンを使用しているため、他のリージョンのクォータ制限にあまり気にしておりません。
最初の理由については、ランナーは1分程度でジョブを実行する準備が整うはずですが、なぜかそれよりジョブが開始までの時間が長くかかりました。
スケールアップlambda関数のログを調べたところ、EC2 Fleet APIを呼び出す際にいくつかのエラーが見つかりました。それはMaxSpotInstanceCountExceededエラーでした。これは、AWSのクォータに達したためスポットリクエストが失敗したことを意味します。しかし、AWSコンソールでクォータをチェックしたところ、その時点まだ上限緩和申請はまだ指してなかったですが、制限はランダムな数字(648)でした。
スポットインスタンス制限クォータはのソフトリミットであることが判明しました。AWSは顧客の使用量を継続的に監視し、必要に応じて段階的に増加させます。しかし、私たちの場合、すべてのテストをself-hosted runnerを使用するように一気に切り替えたため使用量が突然増加し、このプロセスが追いつかず、制限エラーが発生しました。
妥当な制限をリクエストした後、キュー時間が大幅に短縮されました。

一部のジョブが「queued」状態で永遠に詰まる
時々、複数の並列ジョブを持つワークフロー内で、その一部のみがqueued状態に詰まります。GitHubコンソールは何も出力しないため、キューに入っているジョブがEC2に割り当てられているかどうか分かりませんでした。インスタンスIDがないため、どのインスタンスに問題があるかを特定できません。

アーキテクチャを考慮すると

以下のすべてのログをチェックしました。
- GitHub Apps
- API Gatewayアクセスログ
- Webhook Lambdaログ
- Scale-up Lambdaログ
スケールアップLambdaログに以下のようなログが含まれていることがわかりました。
{
"level": "INFO",
"message": "Created instance(s): i-06486eac2256681ca",
"timestamp": "2025-07-01T10:51:09.772Z",
"service": "runners-scale-up",
"sampling_rate": 0,
"xray_trace_id": "1-6863bd99-21c88f07e1a5a3e8328e7200",
"region": "us-east-1",
"environment": "gh-ci-x64-2core-cpu-optimized",
"module": "runners",
"aws-request-id": "cd33581c-5b7d-575e-b3c2-38c1e4a99eec",
"function-name": "gh-ci-x64-2core-cpu-optimized-scale-up",
"runner": {
"type": "Org",
"owner": "repo-owner",
"namePrefix": ""
},
"github": {
"event": "workflow_job",
"workflow_job_id": "45123342099"
}
}
GitHubコンソールを見ると、ジョブIDはURLの末尾の部分であることがわかります。
https://github.com/{org}/{repository}/actions/runs/{workflow_run_id}/job/{job_id}
ジョブIDがあれば、ジョブがどのインスタンスにも割り当てられているかどうかを確認できます。
しかし、ジョブが詰まった場合、ジョブIDで検索してみるとそのジョブのインスタンスが正常に作成され、正常に実行されていることが見えました!これは非常に不思議でした。
色々調べた結果、これはAction Runner binaryのバグであることが判明しました。
何らかの理由で、ランナーインスタンスはジョブを拾いましたが、GitHubにログをプッシュしてステータスを報告することができず、永遠にqueued状態に詰まります。このバグは現時点でもまだ解決されていないようです。
(AWSとAzureまたはGitHub間の接続問題に何らかの内部レート制限があると推測します)
進めないジョブについては、コンソールから手動でワークフローをキャンセルして再実行できます。しかし、ほぼ100近いのジョブをチェックして、本当に動かなかったのか、それとも実行順番を待っているだけなのかを確認するのは非常に面倒です。
最終的に、シンプルな対策を思いつきました。
GitHub-hosted runnerを使用して、15分ごとに実行されるスケジュールワークフローを実行し、15分以上キューに入っているジョブを含むワークフローがあるかどうかをチェックします。ある場合は、そのワークフローを強制的にキャンセルして再実行させます。
jobs:
retry-workflows:
runs-on: ubuntu-24.04
name: Retry Queued Workflows
steps:
- name: Check and retry queued workflows
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
run: |
QUEUED_RUNS=$(gh api --method GET /repos/{org}/{repository}/actions/runs -F status=queued --jq '.workflow_runs[] | .id')
CURRENT_TIME=$(date +%s)
for run_id in $QUEUED_RUNS; do
QUEUED_JOBS=$(gh api --method GET /repos/{org}/{repository}/actions/runs/"$run_id"/jobs --jq '.jobs[] | select(.status=="queued") | .id')
for job_id in $QUEUED_JOBS; do
# Get the created_at timestamp for the run
CREATED_AT=$(gh api --method GET /repos/{org}/{repository}/actions/jobs/"$job_id" --jq '.created_at')
CREATED_TIME=$(date -d "$CREATED_AT" +%s)
# Calculate how long the workflow has been queued (in minutes)
QUEUED_MINUTES=$(( ("$CURRENT_TIME" - "$CREATED_TIME") / 60 ))
echo "The job_id $job_id in the workflow $run_id has been queued for $QUEUED_MINUTES minutes"
# Only retry if queued time is between 15 and 120 minutes
if [ "$QUEUED_MINUTES" -ge 15 ] && [ "$QUEUED_MINUTES" -le 120 ] ; then
echo "Processing workflow run $run_id"
gh run cancel "$run_id"
sleep 5
for i in {1..5}; do
if gh run rerun "$run_id"; then
break
fi
echo "Retry $run_id attempt $i failed. Waiting 5 seconds before next attempt..."
sleep 5
done
break
fi
done
done
これにより、スタックしたジョブを手動でキャンセルして再試行する必要がなくなりました。
一時パーティションサイズ(tmpfs /tmp)が枯渇
カスタムAMIのベースイメージとしてAmazon Linux 2023を使用しています。しかし、このLinuxディストリビューションには注意点があります。
/tmpパーティションは、RAMの50%のサイズ制限と100万inodeの最大値を持つtmpfsファイルシステムです。
/tmpをキャッシュに使用する予定がある場合は、非常に速く枯渇になり、ワークフローが失敗する可能性があるため十分注意してください。
代替案として/var/tmp(EBS上)を使用できます。
CIワークフローを最適化
ジョブの仕様に基づくランナーインスタンスの適切なサイジング
EC2インスタンスを使用することでランナーの価格が大幅に削減されたため、ランタイムを最速化するためにインスタンスをスケールアップ余裕があります。
しかし、すべてのジョブがより多くのCPUコアとメモリを活用できるわけではありません。例えば、私たちのgo testはシリアルとパラレルに分かれており、パラレルジョブのみがより多くのCPUコアを持つインスタンスで高速に実行されます。
EC2利用のきっかけで、CloudWatchを使用してリソースメトリクスを収集し、必要に応じてインスタンスをスケールアップできます。
しかし、GitHub-hosted runnerを使用している場合でも、これは可能です。
このGitHub Actionは、ランナーがジョブを実行する際にすべてのメトリクスを収集し、結果をワークフローサマリーに投稿します。

Workflow Telemetryの結果をチェックした後、一部のジョブが多くのCPUコアを活用できることが分かりました。これは、mインスタンスタイプ(CPU-メモリ比が1:4)の代わりに、より良い価格/パフォーマンスのためにcインスタンスタイプ(CPU-メモリ比が1:2)を変更しました。
一方、GitHub-hostedは、CPU-メモリ比がEC2 mインスタンスタイプに等しい1種類の汎用インスタンスのみを提供します。

これは単純な例です。ワークフローが他のインスタンスタイプ(ネットワーク重視、メモリ重視、GPUインスタンスなど)を活用できる場合、自由にそれらに変更できます。
キャッシュバックエンドをGitHub cacheからS3に切り替え
GitHub Actionsには、ランタイムを短縮するためにジョブとワークフロー間でファイルをキャッシュバックエンドがあります。
しかし、どのプランでも各リポジトリは最大10GBのみです。私たちのリポジトリは少し複雑で、10GBでは不十分で、キャッシュファイルがGitHubによって頻繁に削除されていました。

EC2でself-hostedに移行したため、S3をキャッシュストレージとして使用する方が適切だと思います。利点としては
- 無制限の容量である
- S3 Gateway Endpointを使用するとスピードがすごく速い(実質300~400MB/sである。一方、GitHub Action Cacheは50~100MB/sだけ)
上記で話したruns-onプロジェクトは、actions/cacheactionの代わりのactionがあります。
AWS_REGION
RUNS_ON_S3_BUCKET_CACHE
上記の2つの環境変数を追加し、EC2ランナーがS3バケットに適切にアクセスする権限を持っていることを確認を取れれば、利用できます。
他のパラメータはactions/cacheと同じで、S3を使用できない場合は自動的にGitHub Action Cacheにフォールバックしてくれます。
ステップ間のキャッシュ問題を修正
これはself-hostedとはあまり関係ありませんが、最適化にの工夫を紹介させていただきます。
私たちのテストワークフローには以下のステップがあります
- 変更にテストを実行する必要があるファイル(
*.go、*.sqlなど)が含まれているかチェック - タグに基づいてテストをいくつかの並列ジョブに分割
- 各ジョブ内で
- ソースコードをチェックアウト
- docker composeでDockerコンテナを準備(go mod download、MySQL、Redisなど)
- マイグレーションを実行
- テストを実行する
テストワークフローはこのようになります。

そして、各ジョブ内のステップはこのようになります

ご覧の通り、Setup backendsは約3分30秒がかかるし、すべての並列ジョブで同じく繰り返します。
5分または6分しか消費しないジョブにとって、これはランタイムの50%です!
そこで、ワークフロー全体を高速化するために以下のことを行いました。
MySQLコンテナをキャッシュする
MySQL公式イメージを使用していますが、データベースはテストを実行する前に日本語の設定が必要なため、実行前にビルドする必要があります。
#4 [mysql 1/2] FROM docker.io/library/mysql:8.0.36
#4 DONE 0.2s
#5 [mysql 2/2] RUN microdnf install -y glibc-locale-source && localedef -i en_US -c -f UTF-8 -A /usr/share/locale/locale.alias en_US.UTF-8
#5 1.177 Downloading metadata...
#5 16.20 Downloading metadata...
#5 28.49 Downloading metadata...
#5 29.00 Downloading metadata...
#5 32.86 Package Repository Size
#5 32.86 Installing:
#5 32.86 glibc-gconv-extra-2.28-251.0.3.el8_10.16.x86_64 ol8_baseos_latest 1.6 MB
#5 32.86 glibc-locale-source-2.28-251.0.3.el8_10.16.x86_64 ol8_baseos_latest 4.4 MB
#5 32.86 Upgrading:
#5 32.86 glibc-2.28-251.0.3.el8_10.16.x86_64 ol8_baseos_latest 2.3 MB
#5 32.86 replacing glibc-2.28-236.0.1.el8_9.12.x86_64
#5 32.86 glibc-common-2.28-251.0.3.el8_10.16.x86_64 ol8_baseos_latest 1.1 MB
#5 32.86 replacing glibc-common-2.28-236.0.1.el8_9.12.x86_64
#5 32.86 glibc-minimal-langpack-2.28-251.0.3.el8_10.16.x86_64 ol8_baseos_latest 76.5 kB
#5 32.86 replacing glibc-minimal-langpack-2.28-236.0.1.el8_9.12.x86_64
#5 32.86 Transaction Summary:
#5 32.86 Installing: 2 packages
#5 32.86 Reinstalling: 0 packages
#5 32.86 Upgrading: 3 packages
#5 32.86 Obsoleting: 0 packages
#5 32.86 Removing: 0 packages
#5 32.86 Downgrading: 0 packages
#5 32.86 Downloading packages...
#5 32.98 Running transaction test...
#5 33.33 Updating: glibc-common;2.28-251.0.3.el8_10.16;x86_64;ol8_baseos_latest
#5 33.49 Updating: glibc-minimal-langpack;2.28-251.0.3.el8_10.16;x86_64;ol8_baseos_latest
#5 33.50 Updating: glibc;2.28-251.0.3.el8_10.16;x86_64;ol8_baseos_latest
#5 33.75 Installing: glibc-gconv-extra;2.28-251.0.3.el8_10.16;x86_64;ol8_baseos_latest
#5 33.93 Installing: glibc-locale-source;2.28-251.0.3.el8_10.16;x86_64;ol8_baseos_latest
#5 34.31 Cleanup: glibc;2.28-236.0.1.el8_9.12;x86_64;installed
#5 34.32 Cleanup: glibc-minimal-langpack;2.28-236.0.1.el8_9.12;x86_64;installed
#5 34.33 Cleanup: glibc-common;2.28-236.0.1.el8_9.12;x86_64;installed
#5 34.52 Complete.
#5 DONE 36.3s
#6 [mysql] exporting to image
#6 exporting layers
#6 exporting layers 0.7s done
#6 writing image sha256:bc72bb57206fdb5aeee0e8bd8652e186861312b6abf67f42841c76142cb6fa64 done
#6 naming to docker.io/library/snkrdunkcom-mysql done
#6 DONE 0.7s
#7 [mysql] resolving provenance for metadata file
#7 DONE 0.0s
ビルドは約30秒かかります。しかし、MySQL設定はめったに変更されないため(MySQLバージョンアップぐらい)、すべてのジョブで繰り返しビルドする必要はありません。
そこで、すべてのテストを実行する前にMySQL Buildステップを追加しました。
- カスタムDockerfileとその他のMySQL設定ファイルを含む
etc/mysqlフォルダのハッシュをチェックを行う - ハッシュキーをキャッシュキーとして使用し、ビルドされたコンテナがキャッシュに存在するかどうかを確認する
- 存在しない場合、ビルドコマンドを実行する
- MySQLコンテナをディスクに保存し、ファイルをアーカイブしてキャッシュ(S3)にプッシュしする
mysql-build:
runs-on: self-hosted-linux-x64-4core-cpu-optimized
name: Building MySQL image
steps:
- name: Checkout
uses: actions/checkout@11bd71901bbe5b1630ceea73d27597364c9af683 # v4.2.2
with:
sparse-checkout: |
etc/docker/mysql
docker-compose.ci.yml
- name: Get mysql folder hash
run: echo "MYSQL_IMAGE_HASH=$(git ls-files -s etc/docker/mysql | git hash-object --stdin)" >> "$GITHUB_ENV"
- name: Check if cache exists
id: cache-hit-check
uses: runs-on/cache/restore@5a3ec84eff668545956fd18022155c47e93e2684 # v4.2.3
env:
RUNS_ON_S3_BUCKET_CACHE: dummy-bucket
with:
path: /tmp/docker-build/mysql
lookup-only: true
key: test-${{ runner.os }}-${{ runner.arch }}-snkrdunkcom-mysql-${{ env.MYSQL_IMAGE_HASH }}
- name: Build mysql image
if: ${{ steps.cache-hit-check.outputs.cache-hit != 'true' }}
run: |
cp etc/docker/.env.default etc/docker/.env
docker compose -f docker-compose.ci.yml build mysql
- name: Cache preparation
if: ${{ steps.cache-hit-check.outputs.cache-hit != 'true' }}
run: |
mkdir -p /tmp/docker-build/mysql
docker save -o /tmp/docker-build/mysql/snkrdunkcom-mysql.tar snkrdunkcom-mysql
- name: Saving mysql image
if: ${{ steps.cache-hit-check.outputs.cache-hit != 'true' }}
id: save-mysql-image
uses: runs-on/cache/save@5a3ec84eff668545956fd18022155c47e93e2684 # v4.2.3
env:
RUNS_ON_S3_BUCKET_CACHE: dummy-bucket
with:
path: /tmp/docker-build/mysql
key: test-${{ runner.os }}-${{ runner.arch }}-snkrdunkcom-mysql-${{ env.MYSQL_IMAGE_HASH }}
その後、各テストジョブで、S3からMySQLコンテナをダウンロードして、インポートします。
docker load < /tmp/docker-build/mysql/snkrdunkcom-mysql.tar
Docker composeファイル内の同じ名前で、MySQLコンテナは再びビルドされるべきではありません。
したがって、ランタイムに30秒かかるカスタムMySQLコンテナをビルドする代わりに、今ではS3からコンテナファイル(約350MB)をダウンロードするのに約1秒、インポートするのに約5秒しかかかりません。
マイグレーションされたデータベースのキャッシュ
テストを実行するには、スキーマを準備するためにマイグレーションコマンドを実行する必要があります。2018年に始まった私たちのサービスは、現在550以上のマイグレーションステップを実行する必要があります。

このステップは各ジョブで合計150秒以上かかります!
しかし、すべての変更にデータベースマイグレーションが含まれているわけではありません。
そこで、すべてのテストジョブの前に、データマイグレーションステップを実行するだけのジョブを追加しました。
-
/migrationsフォルダのハッシュをチェックする - ハッシュキーをキャッシュキーとして使用し、マイグレーションされたデータベースファイルがキャッシュに存在するかどうかを確認する
- 存在しない場合、MySQLコンテナを起動し、マイグレーションコマンドを実行する
- MySQLコンテナを停止し、データベースファイルをアーカイブしてキャッシュ(S3)に保存する
db-migrate:
runs-on: self-hosted-linux-x64-4core-cpu-optimized
name: Database migration
steps:
- name: Checkout
uses: actions/checkout@11bd71901bbe5b1630ceea73d27597364c9af683 # v4.2.2
- name: Get migration hash
run: echo "MIGRATION_HASH=$(git ls-files -s migrations | git hash-object --stdin)" >> "$GITHUB_ENV"
- name: Check if migration cache exists
id: cache-hit-check
uses: runs-on/cache/restore@5a3ec84eff668545956fd18022155c47e93e2684 # v4.2.3
env:
RUNS_ON_S3_BUCKET_CACHE: dummy-bucket
with:
path: /var/tmp/db_data
lookup-only: true
key: test-${{ runner.os }}-${{ runner.arch }}-db-migration-${{ env.MIGRATION_HASH }}
- name: Setup db
if: ${{ steps.cache-hit-check.outputs.cache-hit != 'true' }}
run: |
cp etc/docker/.env.default etc/docker/.env
docker compose -f docker-compose.ci.yml up -d mysql
docker run --network snkrdunkcom_default jwilder/dockerize:v0.9.3 -wait tcp://mysql:3306 -timeout 3m
docker compose exec mysql mysql -uroot -psnkrdunk -e 'SET GLOBAL default_collation_for_utf8mb4=utf8mb4_general_ci'
make migrate-up DB_NAME=snkrdunk_test
- name: Cache preparation
if: ${{ steps.cache-hit-check.outputs.cache-hit != 'true' }}
run: |
docker compose -f docker-compose.ci.yml down
sudo chmod -R 775 /var/tmp/db_data/
- name: Saving DB migrated data for test
if: ${{ steps.cache-hit-check.outputs.cache-hit != 'true' }}
id: save-migrated-db-data
uses: runs-on/cache/save@5a3ec84eff668545956fd18022155c47e93e2684 # v4.2.3
env:
RUNS_ON_S3_BUCKET_CACHE: dummy-bucket
with:
path: /var/tmp/db_data
key: test-${{ runner.os }}-${{ runner.arch }}-db-migration-${{ env.MIGRATION_HASH }}
マイグレーションされたデータがすでにデータベースに読み込まれているため、各ジョブで毎回150秒かかるマイグレーションコマンドを実行する代わりに、今ではMySQLデータファイル(約31MB)をダウンロードするのに1秒未満しかかかりません。
go mod downloadのキャッシュ
これはテストジョブの前にgo mod downloadを実行し、Golangコンテナがそれを再実行しないように変更しました。
結果
結局、私たちのワークフローは
から

に変わりました
結果として、DataDogのCI Pipeline Visibilityで確認したところ
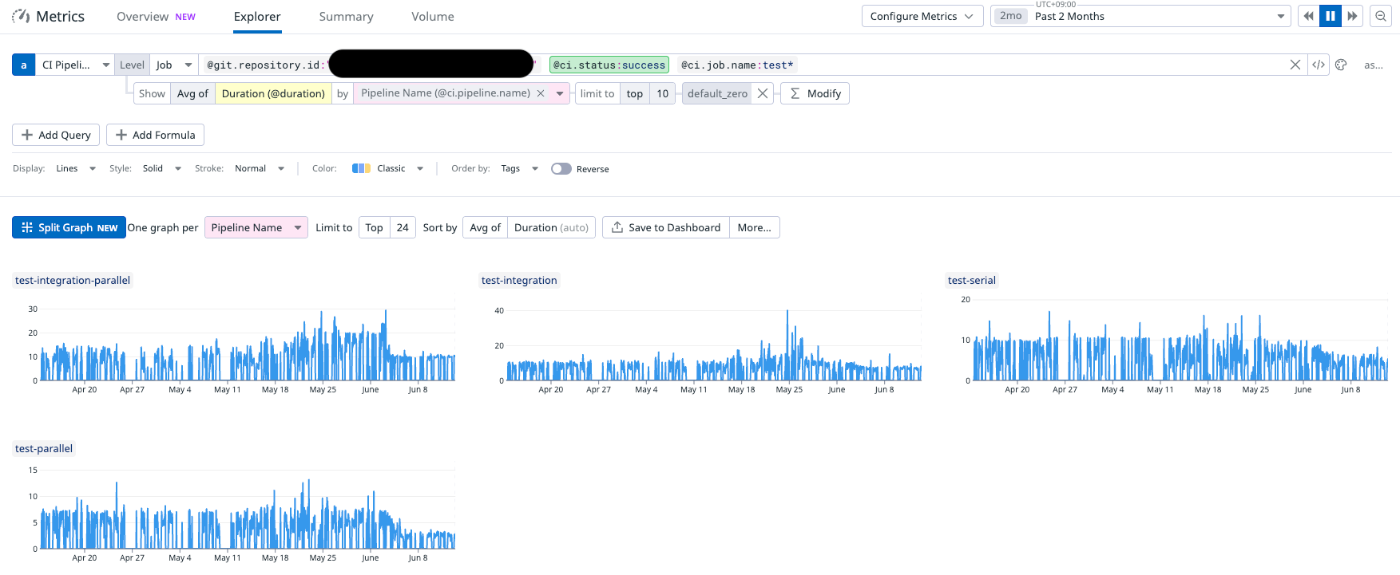
CIランタイムが大幅に短縮されのが見えています🎉
GitHub Action Performance Metricsの数値からみると、私たちのジョブは以前より平均 20% 高速になり、最良のシナリオでは最大 54% 速くなりました。


| Test Workflow | Old (sec) | New (sec) | Change |
|---|---|---|---|
| Test Workflow 1 | 394.4 | 279.7 | 29.1% |
| Test Workflow 2 | 311.3 | 233.1 | 25.1% |
| Test Workflow 3 | 443.4 | 374.4 | 15% |
| Test Workflow 4 | 495.3 | 548 | -10% |
※ Workflow中の各ジョブ平均実行時間で計算しました。
削減できたコストについては、毎月ワークロードが変わるので、移行前と移行後の請求書を比較するのはできないため、移行後実際利用量(分数)をGitHub Usage Metricsからを取って、GitHub-hostedを利用する場合、いくらかかるべきのか計算しました。
| Machine Type | Total minutes | Price per min | Total Cost (USD) |
|---|---|---|---|
| linux-x64-2core | 4845 | 0.008 | 38.76 |
| linux-x64-4core | 622319 | 0.016 | 9957.104 |
| linux-x64-8core | 416835 | 0.032 | 13338.72 |
| linux-arm64-2core | 145365 | 0.005 | 726.825 |
| linux-arm64-4core | 1400 | 0.01 | 14 |
| linux-arm64-8core | 116 | 0.02 | 2.32 |
| Total cost in case of GitHub-Hosted | 24077.729 |
ご覧の通り使用量はGitHub-hostedで $24,000 かかるべきでしたが、self-hostedに移行した後ただ $3000 だけかかりました💸
これは 87.5% のコスト削減です!

結論
- Self-hostedは、オンデマンドインスタンスでもGitHub-hostedよりはるかに安いです。
- スポットインスタンスを使用する場合、より良い終了率のためにデフォルトのインスタンス取得戦略を変更することを忘れないでください。
- CICDパイプラインを最適化するためにランナーを積極的にカスタマイズできます。
- CI監視は非常に便利です。DataDog CI Pipeline Visibilityについては弊社別のブログ記事もあります:https://zenn.dev/team_soda/articles/b10194a91dbd34
- 永遠に詰まる「Queued」ジョブに十分注意してください。原因は色々があるかと思います。
最後に
Self-hostedに移行してから2ヶ月経ちました。最初想定できなかったシナリオが多かったですが、少しづつ潰して、現在だいぶ安定になりました。
運用コストがちょっと増えてきましたが、コストとカスタマイズのメリットはすごく大きい感じました。
ぜひやってみてください!
また、メンバーを常に募集しているので、ぜひ採用ページだけでも覗いてみてね☺️

株式会社SODAの開発組織がお届けするZenn Publicationです。 是非Entrance Bookもご覧ください! → recruit.soda-inc.jp/engineer
Discussion