Closed23
みんしゅみ 検索エンジンの実装ログ
引き継ぎ
検索エンジンは別個で作るとして、どう作るのがいいか。
Cloud Storageにインデックス保存、Cloud Runでインデックス登録・検索アプリを実装したいお気持ち
ストップワード一覧(便利)
GPTに聞いてみた
whooshめっちゃいい
whooshでのindexing
デフォルトだと完全一致のみになってしまうので、以下ではNGramで分割するよう設定済み
from whoosh.index import create_in, FileIndex
from whoosh.fields import *
import os, os.path as path
from whoosh import scoring
from whoosh.analysis import NgramAnalyzer, StopFilter
# setup index
def get_schema():
schema = Schema(
title=TEXT(
stored=True,
analyzer=NgramAnalyzer(minsize=1, maxsize=10),
),
path=ID(stored=True),
content=TEXT(analyzer=NgramAnalyzer(minsize=1, maxsize=10)),
)
return schema
def init_index(index_dir:str):
if not path.exists(index_dir):
os.mkdir(index_dir)
def get_index():
INDEX_DIR = "index_dir"
init_index(INDEX_DIR)
return create_in(INDEX_DIR, get_schema())
ix = get_index()
whooshのデータ追加
writerを用意してadd_document()でデータ追加、commit()で保存
def write_data(ix: FileIndex):
writer = ix.writer()
text = u"きめつのやばい" * 100
for i in range(len(text)):
writer.add_document( # writter.add_document()でデータ追加
title=text[0:i],
path=u"/b",
content=text[0:i]*3,
)
writer.commit()
write_data(ix)
whooshの検索
検索文字列をQueryParser()でパースしてsearcherにわたして
from whoosh.qparser import QueryParser
def search(query_text):
with ix.searcher(weighting=scoring.TF_IDF()) as searcher: # TF_IDFで重みづけしている
query = QueryParser("title", ix.schema).parse(query_text)
results = searcher.search(query, limit=20)
print("search result", len(results), results)
return results
全体のコードと実行結果
全体のコード
from whoosh.index import create_in, FileIndex
from whoosh.fields import *
import os, os.path as path
from whoosh import scoring
from whoosh.analysis import NgramAnalyzer, StopFilter
# setup index
def get_schema():
schema = Schema(
title=TEXT(
stored=True,
analyzer=NgramAnalyzer(minsize=1, maxsize=10),
),
path=ID(stored=True),
content=TEXT(analyzer=NgramAnalyzer(minsize=1, maxsize=10)),
)
return schema
def init_index(index_dir:str):
if not path.exists(index_dir):
os.mkdir(index_dir)
def get_index():
INDEX_DIR = "index_dir"
init_index(INDEX_DIR)
return create_in(INDEX_DIR, get_schema())
ix = get_index()
def write_data(ix: FileIndex):
writer = ix.writer()
text = u"あいうえお" * 3
for i in range(len(text)):
writer.add_document(
title=text[0:i],
path=u"/b",
content=text[0:i]*3,
)
writer.commit()
write_data(ix)
# search
from whoosh.qparser import QueryParser
from time import time
with ix.searcher(weighting=scoring.TF_IDF()) as searcher:
query_text = input("検索ワードを入力:")
start = time()
query = QueryParser("title", ix.schema).parse(query_text)
results = searcher.search(query, limit=20)
result_time = time() - start
print("search result", len(results), results, "in", result_time)
for i, result in enumerate(results):
print(" ", i,":", result)
実行結果
$ py test.py
検索ワードを入力:あいうえおあ
search result 9 <Top 9 Results for Term('title', 'あいうえおあ') runtime=0.0008547999896109104> in 0.0050067901611328125
0 : <Hit {'path': '/b', 'title': 'あいうえおあいうえおあ'}>
1 : <Hit {'path': '/b', 'title': 'あいうえおあいうえおあい'}>
2 : <Hit {'path': '/b', 'title': 'あいうえおあいうえおあいう'}>
3 : <Hit {'path': '/b', 'title': 'あいうえおあいうえおあいうえ'}>
4 : <Hit {'path': '/b', 'title': 'あいうえおあ'}>
5 : <Hit {'path': '/b', 'title': 'あいうえおあい'}>
6 : <Hit {'path': '/b', 'title': 'あいうえおあいう'}>
7 : <Hit {'path': '/b', 'title': 'あいうえおあいうえ'}>
8 : <Hit {'path': '/b', 'title': 'あいうえおあいうえお'}>
データ数ある程度多くても大丈夫そう
スキーマ定義についてはもうちょっと深堀りたい。

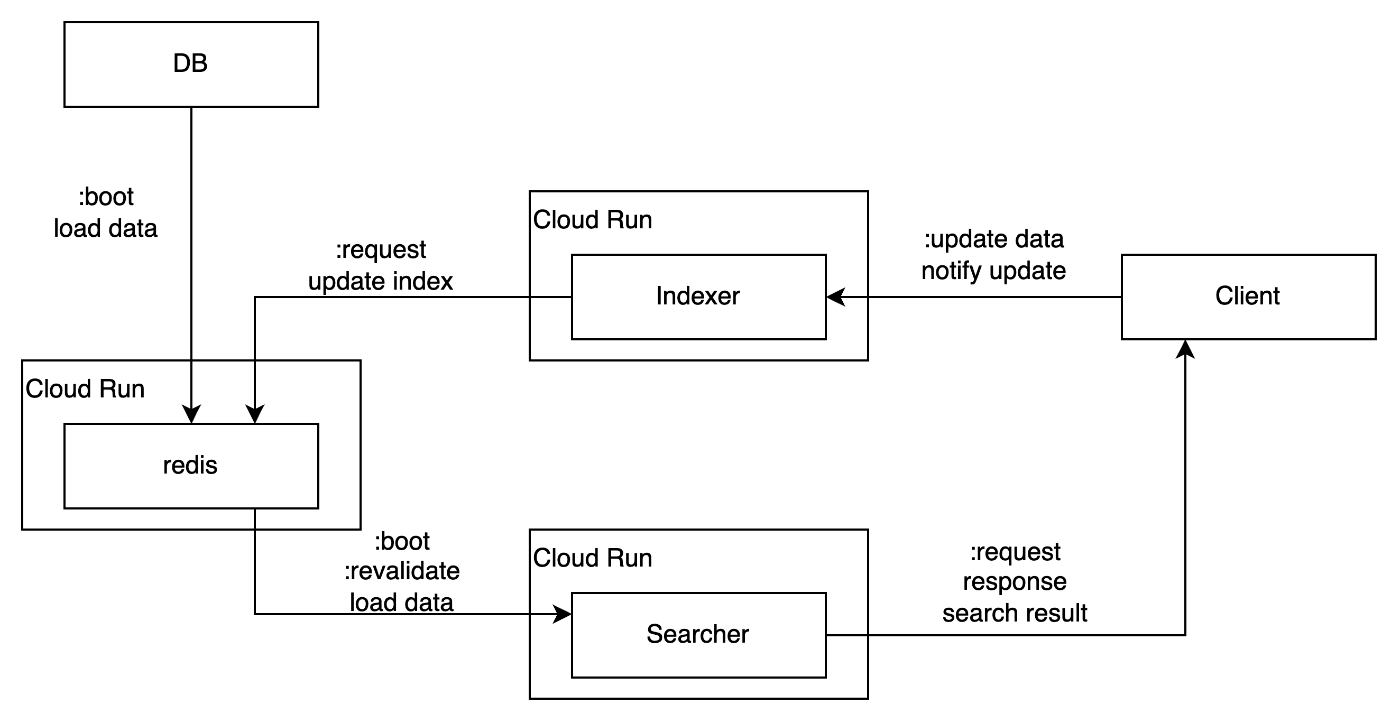
こんな感じの構成になりそう
index更新の排他制御むずそう
cloud tasks とかで何とかする
スキーマの stored には検索結果の中に含めるかを指定する(含める場合Indexとは別に元データも保存(store)しておく必要があるので指定しないといけないっぽい)
webサーバはfastapiさわってみよう
Dockerfileもシンプル
FROM python:3.11.7-alpine
WORKDIR /app
COPY . .
RUN pip install --no-cache-dir --upgrade -r ./requirements.txt
CMD ["uvicorn", "app:app", "--host", "0.0.0.0", "--port", "8000"]
Cloud Runにデプロイできたー!
Cloud Storage のメタデータ使うの賢い
GCSのディレクトリダウンロード
このスクラップは2024/02/25にクローズされました