みんしゅみ レコメンドエンジンの実装ログ
Thompson Sampling
- 各スロットマシンが当たる確率を確率分布で推定する
- 各試行では、スロットマシン毎に確率分布から値をサンプルし、その値が最大となるスロットマシンの腕を引く
- 腕を引いた結果を使ってそのスロットマシンが当たる確率の確率分布を更新する
あらかじめ確率を用意→毎回確率を改善していく的な?
Clustered Thompson Sampling
上記だと
- 広告がクリックされる確率はユーザの属性によって異なる
- 広告がクリックされる確率は時間によって変化する
という問題点がある。そこでユーザをクラスタ(一定の属性ごとのグループ)に分割し、クラスタごとにThompson Sampling を行う。
↓↓↓
なんかよさげな雰囲気はあるものの、結果的にはあまりうまくいかなかった様子...
- 利用しているデータが過去3日分 → これを伸ばす? → 伸ばしすぎると逆効果なので適切な集計期間を見つけることが大切。
- クラスタリングの仕方を変える
1か月の内定者アルバイト....?!
レベル高すぎ
レコメンドエンジンの話じゃないけど。
最後のおまけの部分は本研究の真髄なのかもしれない
ユーザーが全文検索をする目的は「検索すること」ではなく「必要な情報を得ること」です。
ここのこと
信用のある人に紹介されたものが一番いい説が正しいと仮定すると、直近で(ポジティブな)コメントをくれたりいいねしてくれたりしてくれる人が仲良い人と判断できる。そう言う人たちがおすすめしてくれたものはよりいいおすすめなのでは?
他人が教えてくれたものより友達が教えてくれたものの方が信用しやすい的な説





TikTokのレコメンドのシステムは、「クリエイターのフォロワー数に限らず、優良なコンテンツを評価し、適切なユーザーに届ける」という理念のもとで設計されています。よって、たとえ駆け出しのクリエイターが投稿したコンテンツであっても、平等に一定量の初期アクセスが付与されます。そこから、コンテンツのいいね数、シェア数、視聴完了率、コメント率など、アクセスを配布した先のユーザーからの評価を見て、良ければさらに大きなアクセスを渡す……といった仕組みになっているのです。
全作品に平等に初期アクセスを付与するっていう理念は良さそう
分かち書きしてみる
GPTに聞くとこんな回答が返ってきた
nltk
自然言語処理するためのライブラリらしい。つかいやすそう。
import nltk
nltk.download('punkt') # 初回のみ必要
def split_into_sentences_nltk(text):
sentences = nltk.sent_tokenize(text)
return sentences
# テスト
text = "これはサンプルテキストです。これは別の文です。そして、最後の文です。"
sentences = split_into_sentences_nltk(text)
print(sentences)
spacy
こちらも自然言語処理をするためのライブラリ。使いやすそう
import spacy
nlp = spacy.load('ja_core_news_sm') # 日本語モデルを使用
def split_into_sentences_spacy(text):
doc = nlp(text)
sentences = [sent.text for sent in doc.sents]
return sentences
# テスト
text = "これはサンプルテキストです。これは別の文です。そして、最後の文です。"
sentences = split_into_sentences_spacy(text)
print(sentences)
つかいにくいmecabでごちゃごちゃする必要はなさそう
方針
- 登録時、
- 分かち書き
- 正規化
- 原形に
- すべて小文字に
- 単語リストを五十音順に並べ替え
- 保存
- レコメンド時に
- 正規化されたリストとレコメンド先ユーザの特徴をもとに検索
1~3
addArt({
tilte: "この素晴らしい世界に祝福を!",
tags: ["明るい", "ファンタジー"],
})
↓
関連ワードを摘出
↓
素晴らしい
世界
祝福
4
作品レコメンドインデックス
| word | 作品 |
|---|---|
| 素晴らしい | この素晴らしい世界に祝福を! |
| 世界 | この素晴らしい世界に祝福を! |
| 祝福 | この素晴らしい世界に祝福を! |
5~6 パターン1 明るいタグを設定しているユーザに向けてレコメンド
クエリのベクター = vectorize_text(好きな作品のベクター)
作品一覧のベクター = vectorize_text(作品一覧)
作品の関連度 = cosine_similarity(クエリのベクター, 作品一覧)
sorted_作品の関連度.argsort()[0][::-1]
大量のデータセットに対応するにはSparkとかを使うといいらしい。
Sparkについてはこれが一番わかりやすい。
vectorizer = TfidfVectorizer(ngram_range=(1, 1), analyzer='word')
X = vectorizer.fit_transform([
"私ね","もっと","ねえ","見届けて","ほしがり","でも",
"もっと","しぐさに","揺れて","抑えきれない","ほどに",
"あなたに","幾度も","触れたって","大体","ちょっとだけ","頓智",
])
print(vectorizer.get_feature_names_out())
print(X.toarray())
['あなたに' 'しぐさに' 'ちょっとだけ' 'でも' 'ねえ' 'ほしがり' 'ほどに' 'もっと' '大体' '幾度も' '抑えきれない'
'揺れて' '私ね' '見届けて' '触れたって' '頓智']
[[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0.]
[0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]]
vertex ai search が優秀そう
レコメンドも検索もできる優れもの
ただし頻繁に発生する検索もお任せしちゃうと破産しちゃいそうなお気持ち

検索エンジンは別個で作るとして、どう作るのがいいか。
Cloud Storageにインデックス保存、Cloud Runでインデックス登録・検索アプリを実装したいお気持ち
検索エンジンの話は別スクラップにしよう
インデックス登録・検索アプリ、PostgreSQLで実装すればいいのでは?
vertex AI SearchでRecommendする方法
プログラムからレコメンドする
# This snippet has been automatically generated and should be regarded as a
# code template only.
# It will require modifications to work:
# - It may require correct/in-range values for request initialization.
# - It may require specifying regional endpoints when creating the service
# client as shown in:
# https://googleapis.dev/python/google-api-core/latest/client_options.html
from google.cloud import discoveryengine_v1beta
def sample_recommend():
# Create a client
client = discoveryengine_v1beta.RecommendationServiceClient()
# Initialize request argument(s)
user_event = discoveryengine_v1beta.UserEvent()
user_event.event_type = "event_type_value"
user_event.user_pseudo_id = "user_pseudo_id_value"
request = discoveryengine_v1beta.RecommendRequest(
serving_config="serving_config_value",
user_event=user_event,
)
# Make the request
response = client.recommend(request=request)
# Handle the response
print(response)
UserEventとは
UserEvent
UserEvent captures all metadata information Discovery Engine API needs to know about how end users interact with customers' website.ユーザーイベント
UserEventは、エンドユーザーが顧客のウェブサイトとどのようにやり取りするかについて、Discovery Engine APIが知る必要のあるすべてのメタデータ情報を取得します。
UserEvent.event_type
ユーザのどんな行動に対してレコメンドするかを指定するっぽい。
search , view-item , view-item-list , view-home-page , view-category-page , add-to-cart , purchase , media-play , media-play , media-complete の中から選ぶ。
string
Required. User event type. Allowed values are:
Generic values:
search: Search for Documents.
view-item: Detailed page view of a Document.
view-item-list: View of a panel or ordered list of Documents.
view-home-page: View of the home page.
view-category-page: View of a category page, e.g. Home > Men > Jeans
Retail-related values:add-to-cart: Add an item(s) to cart, e.g. in Retail online shopping
purchase: Purchase an item(s)
Media-related values:media-play: Start/resume watching a video, playing a song, etc.
media-complete: Finished or stopped midway through a video, song, etc.ストリング
必須。ユーザーイベントのタイプ。許可される値は以下のとおり:
一般的な値:
検索:ドキュメントの検索。
view-item:ドキュメントの詳細ページビュー。
view-item-list:ドキュメントのパネルまたは並べ替えリストの表示。
view-home-page:ホームページの表示。
view-category-page:例:ホーム > メンズ > ジーンズ小売関連の値:
カートに入れる:add-to-cart:商品をカートに入れる。
購入する:商品を購入するメディア関連の値:
メディア再生:ビデオの視聴、曲の再生などを開始/再開する。
メディア完了:ビデオや曲などの途中で終了または停止。
UserEvent.user_pseudo_id
要はいわゆるユーザIDっぽい。
string
Required. A unique identifier for tracking visitors.
For example, this could be implemented with an HTTP cookie, which should be able to uniquely identify a visitor on a single device. This unique identifier should not change if the visitor log in/out of the website.
Do not set the field to the same fixed ID for different users. This mixes the event history of those users > together, which results in degraded model quality.
The field must be a UTF-8 encoded string with a length limit of 128 characters. Otherwise, an INVALID_ARGUMENT error is returned.
The field should not contain PII or user-data. We recommend to use Google Analytics Client ID for this field.
ストリング
必須。訪問者を追跡するための一意の識別子。
例えば、これはHTTPクッキーで実装することができ、1つのデバイス上で訪問者を一意に識別できる必要があります。この一意な識別子は、訪問者がウェブサイトにログイン/ログアウトしても変わらないようにする必要があります。
異なるユーザーに対して同じ固定IDをフィールドに設定しないでください。これは、それらのユーザーのイベント履歴を一緒に混ぜてしまい、モデルの品質を低下させる結果となります。
フィールドはUTF-8でエンコードされた文字列でなければならず、長さは128文字に制限される。そうでない場合、INVALID_ARGUMENTエラーが返される。
フィールドにはPIIやユーザーデータを含めるべきではありません。このフィールドにはGoogle AnalyticsクライアントIDを使用することをお勧めします。
RecommendRequestとは
まあその名の通りどんなふうにレコメンドしてほしいかを指定するオブジェクト。
RecommendRequest.serving_config
One default serving config is created along with your recommendation engine creation. The engine ID will be used as the ID of the default serving config. For example, for Engine projects//locations/global/collections//engines/my-engine, you can use projects//locations/global/collections//engines/my-engine/servingConfigs/my-engine for your [Recommend][] requests.
レコメンデーションエンジンの作成と同時に、デフォルトのサービングコンフィグが1つ作成されます。エンジンIDは、デフォルトのサービングコンフィグのIDとして使用されます。例えば、Engine projects//locations/global/collections//engines/my-engineの場合、[Recommend][]リクエストにはprojects//locations/global/collections//engines/my-engine/servingConfigs/my-engineを使うことができます。
よくわからないので追加で調べてみる。
About serving configs
Serving configs are referenced at serving time to determine what recommendations to generate.When any Vertex AI Search app is created, a default serving config is also automatically created. For search apps, the default serving config's ID is default_search. For recommendations apps, the serving config's ID is the same as the engine ID. The default serving config ID is specified when making recommend or search API calls.
However, search and generic recommendations apps don't allow you to modify serving configs or create additional serving configs. Only media recommendation apps have modifiable serving configs and allow multiple serving configs.
For any media recommendation app, you can create multiple serving configs with different settings for recommendations demotion and recommendations diversity. To get recommendations from a specific serving config with the demotion and diversity settings you need, specify that serving config's ID in the recommend request.
サービングコンフィグについて
サービングコンフィグはサービング時に参照され、どのようなレコメンデーションを生成するかを決定します。Vertex AI Searchアプリが作成されると、デフォルトのサービングコンフィグも自動的に作成されます。検索アプリの場合、デフォルトのサービングコンフィグのIDはdefault_searchです。レコメンデーション アプリの場合、サービング コンフィグの ID はエンジン ID と同じです。デフォルトのサービングコンフィグIDは、レコメンドや検索のAPIコールを行う際に指定します。
ただし、検索アプリや一般的なレコメンドアプリでは、サービングコンフィグを変更したり、追加のサービングコンフィグを作成したりすることはできません。サービングコンフィグを変更でき、複数のサービングコンフィグを使用できるのは、メディア推薦アプリだけです。
どのメディア推薦アプリでも、推薦の降格と推薦の多様性を異なる設定にして、複数のサービングコンフィグを作成できます。降格や多様性を設定した特定のサービングコンフィグからレコメンドを取得するには、レコメンドリクエストでそのサービングコンフィグのIDを指定します。
これ?

構造化メディアデータをいれるデータストアのの構造について記載があるので見といたほうがよさそう
ドキュメント(みんしゅみにおける作品)のデータ型
JSONスキーマ
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"type": "object",
"properties": {
"title": {
"type": "string",
},
"description": {
"type": "string",
},
"language_code": {
"type": "string",
},
"categories": {
"type": "array",
"items": {
"type": "string",
}
},
"uri": {
"type": "string",
},
"images": {
"type": "array",
"items": {
"type": "object",
"properties": {
"uri": {
"type": "string",
},
"name": {
"type": "string",
}
},
}
},
"media_type": {
"type": "string",
},
"in_languages": {
"type": "array",
"items": {
"type": "string",
}
},
"country_of_origin": {
"type": "string",
},
"content_index": {
"type": "integer",
},
"persons": {
"type": "array",
"items": {
"type": "object",
"properties": {
"name": {
"type": "string",
},
"role": {
"type": "string",
},
"custom_role": {
"type": "string",
},
"rank": {
"type": "integer",
},
"uri": {
"type": "string",
}
},
"required": ["name", "role"],
}
},
"organizations": {
"type": "array",
"items": {
"type": "object",
"properties": {
"name": {
"type": "string",
},
"role": {
"type": "string",
},
"custom_role": {
"type": "string",
},
"rank": {
"type": "integer",
},
"uri": {
"type": "string",
}
},
"required": ["name", "role"],
}
},
"hash_tags": {
"type": "array",
"items": {
"type": "string",
}
},
"filter_tags": {
"type": "array",
"items": {
"type": "string",
}
},
"duration": {
"type": "string",
},
"content_rating": {
"type": "array",
"items": {
"type": "string",
}
},
"aggregate_ratings": {
"type": "array",
"items": {
"type": "object",
"properties": {
"rating_source": {
"type": "string",
},
"rating_score": {
"type": "number",
},
"rating_count": {
"type": "integer",
}
},
"required": ["rating_source"],
}
},
"available_time": {
"type": "string",
},
"expire_time": {
"type": "string",
},
"production_year": {
"type": "integer",
}
},
"required": ["title", "uri", "available_time"],
}
サンプル
{
"title": "Test document title",
"description": "Test document description",
"language_code": "en-US",
"categories": [
"sports > clip",
"sports > highlight"
],
"uri": "http://www.example.com",
"images": [
{
"uri": "http://example.com/img1",
"name": "image_1"
}
],
"media_type": "sports-game",
"in_languages": [
"en-US"
],
"country_of_origin": "US",
"content_index": 0,
"persons": [
{
"name": "sports person",
"role": "player",
"rank": 0,
"uri": "http://example.com/person"
},
],
"organizations": [
{
"name": "sports team",
"role": "team",
"rank": 0,
"uri": "http://example.com/team"
},
],
"hash_tags": [
"tag1"
],
"filter_tags": [
"filter_tag"
],
"duration": "100s",
"production_year": 1900,
"content_rating": [
"PG-13"
],
"aggregate_ratings": [
{
"rating_source": "imdb",
"rating_score": 4.5,
"rating_count": 1250
}
],
"available_time": "2022-08-26T23:00:17Z"
}
必須なのは title , categories , uri , available_time が必須っぽい
title ... 作品のタイトル。1000文字まで
categories ... カテゴリ。 "sports > highlight" みたいな感じに階層的に指定できる。
uri ... ドキュメントのURI。みんしゅみの作品ページのURLでよさそう。
RESTが一番説明が丁寧っぽい(エンジンIDの取得方法とかも教えてくれている)
Preview with allowlist だからなのかドキュメントの追加ができない...?
エラーも出ないから不安すぎる。
一旦はメディアじゃない方でやってみることにする。

検証した時のコードはこんな感じ(プロジェクト固有の情報はマスクしてあります)
from google.cloud import discoveryengine_v1beta
client = discoveryengine_v1beta.DocumentServiceClient()
parent = "projects/xxx/locations/global/collections/default_collection/dataStores/xxx/branches/0"
req = discoveryengine_v1beta.ImportDocumentsRequest({
"parent": parent,
"inline_source": {
"documents": [
discoveryengine_v1beta.Document({
"id": "test-1",
"schema_id": "default_schema",
"json_data": str({
"title": "test-1",
"uri": "https://minshumi.app/art/test-art-1",
"available_time": "2022-08-26T23:00:17Z",
}),
}),
discoveryengine_v1beta.Document({
"id": "test-1",
"schema_id": "default_schema",
"json_data": str({
"title": "test-1",
"uri": "https://minshumi.app/art/test-art-1",
"available_time": "2022-08-26T23:00:17Z",
}),
}),
],
},
})
res = client.import_documents(req)
print(res, res.done())
res = client.list_documents(discoveryengine_v1beta.ListDocumentsRequest({
"parent": parent,
}))
print("documents", res)
for page in res.pages:
print(page.documents)
<google.api_core.operation.Operation object at 0x1068c3450> True
documents ListDocumentsPager<>
[]
1日くらいおいてもそのままだったので多分できてないのかと思われる
よくない雰囲気



データストア作成のタイミングでAPIからimportするように指定しないといかんっぽい
その場合はREST APIで作成する必要があるみたい
と言うことで作ってみた
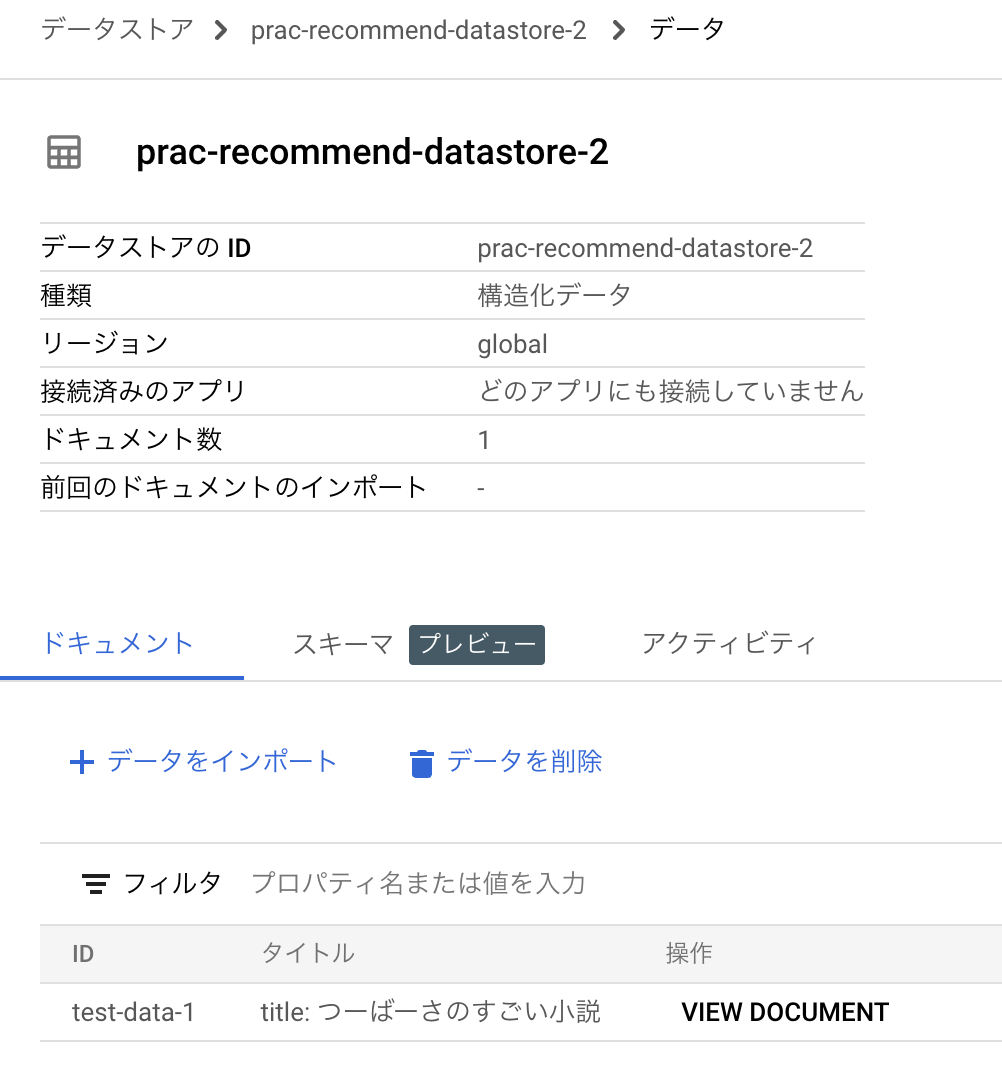
コマンド
データストアの作成
PROJECT_ID=xxx
DATA_STORE_ID=xxx
DISPLAY_NAME=$DATA_STORE_ID
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
-H "X-Goog-User-Project: $PROJECT_ID" \
"https://discoveryengine.googleapis.com/v1alpha/projects/$PROJECT_ID/locations/global/collections/default_collection/dataStores?dataStoreId=$DATA_STORE_ID" \
-d "{
'displayName': '$DISPLAY_NAME',
'industryVertical': 'GENERIC',
'solutionTypes': ['SOLUTION_TYPE_SEARCH'],
"solutionTypes": ['SOLUTION_TYPE_RECOMMENDATION']
}"
# output
# {
# "name": "projects/xxx/locations/global/collections/default_collection/operations/create-data-store-11726871623769991452",
# "done": true
# }
データのインポート
PROJECT_ID=xxx
DATA_STORE_ID=xxx
DISPLAY_NAME=$DATA_STORE_ID
DOCUMENT_ID=test-data-1
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
"https://discoveryengine.googleapis.com/v1beta/projects/$PROJECT_ID/locations/global/collections/default_collection/dataStores/$DATA_STORE_ID/branches/0/documents?documentId=$DOCUMENT_ID" \
-d '{
"jsonData": "{\"persons\": [{\"role\": \"author\", \"name\": \"つーばーさ\"}], \"country_of_origin\": \"JP\", \"cotent_index\": 0, \"in_languages\": [\"ja-JP\"], \"uri\": \"https://minshumi.app/art/test-art-1\", \"title\": \"つーばーさのすごい小説\", \"available_time\": \"2023-12-01 18:41:02\", \"media_type\": \"novel\", \"language_code\": \"ja-JP\", \"has_tags\": [\"コメディ\", \"感動\", \"ファンタジー\"]}"
}'
ちょっと扱いずらかったので修正
import json
data = {
"persons": [
{
"role": "author",
"name": "つーばーさ"
}
],
"country_of_origin": "JP",
"cotent_index": 0,
"in_languages": [
"ja-JP"
],
"uri": "https://minshumi.app/art/test-art-1",
"title": "つーばーさのすごい小説",
"available_time": "2023-12-01 18:41:02",
"media_type": "novel",
"language_code": "ja-JP",
"has_tags": [
"コメディ",
"感動",
"ファンタジー"
]
}
output = {"jsonData": str(data)}
print(json.dumps(output, ensure_ascii=False))
PROJECT_ID=xxx
DATA_STORE_ID=xxx
DISPLAY_NAME=$DATA_STORE_ID
DOCUMENT_ID=test-data-2
DOCUMENT_DATA="$(python test-data-2.py)"
echo $DOCUMENT_ID
echo $DOCUMENT_DATA
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
"https://discoveryengine.googleapis.com/v1beta/projects/$PROJECT_ID/locations/global/collections/default_collection/dataStores/$DATA_STORE_ID/branches/0/documents?documentId=$DOCUMENT_ID" \
-d "$DOCUMENT_DATA"
# -d "{
# 'jsonData': '{\"persons\": [{\"role\": \"author\", \"name\": \"つーばーさ\"}], \"country_of_origin\": \"JP\", \"cotent_index\": 0, \"in_languages\": [\"ja-JP\"], \"uri\": \"https://minshumi.app/art/test-art-1\", \"title\": \"つーばーさのすごい小説\", \"available_time\": \"2023-12-01 18:41:02\", \"media_type\": \"novel\", \"language_code\": \"ja-JP\", \"has_tags\": [\"コメディ\", \"感動\", \"ファンタジー\"]}'
# }"
# output
# {
# "name": "projects/xxx/locations/global/collections/default_collection/dataStores/xxx/branches/0/documents/test-data-1",
# "id": "test-data-1",
# "schemaId": "default_schema",
# "jsonData": "{\"language_code\":\"ja-JP\",\"country_of_origin\":\"JP\",\"has_tags\":[\"コメディ\",\"感動\",\"ファンタジー\"],\"in_languages\":[\"ja-JP\"],\"title\":\"つーばーさのすごい小説\",\"cotent_index\":0,\"persons\":[{\"role\":\"author\",\"name\":\"つーばーさ\"}],\"available_time\":\"2023-12-01 18:41:02\",\"media_type\":\"novel\",\"uri\":\"https://minshumi.app/art/test-art-1\"}",
# "parentDocumentId": "test-data-1"
# }
新年早々、大トラップひいた
いや、IDおかしいよって言われるな...

時間置いたらできるようになった
最終的なコマンド
curl -v -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://discoveryengine.googleapis.com/v1beta/projects/PROJECT_ID/locations/global/collections/default_collection/dataStores/DATASTORE_ID/servingConfigs/SERVICE_CONFIG:recommend \
-d '{ "userEvent": { "eventType":"view-item", "userPseudoId":"USER_ID", "documents":[{"id":"DOCUMENT_ID"}]}}'
参考:
アプリの統合タブから見れる
注: Vertex AI Search and Conversation は現在、パーソナライゼーション機能に仮名化 ID を利用していませんが、Vertex AI Search and Conversation の将来の実装のために今すぐこの値を含めることを強くお勧めします。
userPseudoIdは今は使われてないらしい
ユーザイベントも扱ってみたい
ユーザイベントの種類
- view-category-page
- view-item
- view-home-page
- media-play
- media-complete
みんしゅみだと、
- view-category-page
- view-item
- view-home-page
あたりが収集できそう。
いいねとかも収集したいなってお気持ち。
P.S.
searchとかもあるらしい
イベントにカスタム属性をつけることもできるらしい。
レコメンドが改善されるらしいお。
(「メディアの推奨事項を使用するときに、ユーザーに対する推奨事項が改善され」って書いてあるからあんま意味ないのかもしれないけど)
// カスタム属性の例
attributes: {
user_age: {text: ["teen", "young adult"]},
user_location: {text: ["CA"]},
user_zip: {numbers: [90210]}
}
分書 → gensimでベクトル算出 → voyagerで近似検索で行く
gensimでベクトル算出するところ
import time
from os import path
import gensim
from settings import DIMENSIONS
sentences = [
["ファンキー", "な", "直感", "で", "今日", "の", "歌", "だって", "変わってく", "なら"] * 10,
["もっと", "仕草", "に", "揺れて", "抑え", "きれない", "ほど", "に"] * 10,
]
FAST_TEXT_MODEL_PATH = "models/fast_text.model"
WORD2VEC_MODEL_PATH = "models/word2vec.model"
def init_fast_text_model():
fast_text_model = gensim.models.FastText(
sentences=sentences,
vector_size=DIMENSIONS,
window=5,
min_count=1,
workers=4,
)
fast_text_model.save(FAST_TEXT_MODEL_PATH)
fast_text_model.train(
sentences,
total_examples=2,
epochs=1,
)
return fast_text_model
def init_word2vec_model():
word2vec_model = gensim.models.Word2Vec(
sentences=sentences,
vector_size=DIMENSIONS,
window=5,
min_count=1,
workers=4,
)
word2vec_model.save(WORD2VEC_MODEL_PATH)
word2vec_model.train(
sentences,
total_examples=2,
epochs=1,
)
return word2vec_model
def load_fast_text_model():
if not path.exists(FAST_TEXT_MODEL_PATH):
return init_fast_text_model()
return gensim.models.FastText.load(FAST_TEXT_MODEL_PATH)
def load_word2vec_model():
if not path.exists(WORD2VEC_MODEL_PATH):
return init_word2vec_model()
return gensim.models.Word2Vec.load(WORD2VEC_MODEL_PATH)
def to_vec_by_model(text: str, model):
if model is None:
raise NotImplementedError("please init_model")
if text not in model.wv:
return None
vector = model.wv[text]
return vector
word2vec_model = None
fast_text_model = None
def init_models():
global word2vec_model
global fast_text_model
word2vec_model = init_word2vec_model()
fast_text_model = init_fast_text_model()
return word2vec_model, fast_text_model
def to_vec(text: str):
vec_word2vec = to_vec_by_model(text, word2vec_model)
if vec_word2vec is None:
vec_fast_text = to_vec_by_model(text, fast_text_model)
return vec_fast_text, "fast_text"
return vec_word2vec, "word2vec"
if __name__ == "__main__":
def test_word(word: str):
print("test:", word)
t1 = time.time()
vec = to_vec(word)
t2 = time.time()
print(" vec", vec)
print(" time", int((t2-t1)*1_000_000) / 1_000, "ms")
t1 = time.time()
init_models()
t2 = time.time()
print("init models", t2-t1)
test_word("な")
test_word("ファンキー")
test_word("仕草")
test_word("NewWord")
- Modelを用意 + 基本データセットを学習
- Model.wv[検索ワード] で検索ワードのベクトル算出
の流れ
分書も簡単にできた
pip install mecab-python3
pip install unidic-lite
import MeCab
wakati = MeCab.Tagger("-Owakati")
def split_text(text: str):
return wakati.parse(text).split()
良さげ
APIにするぞ