こんばんは、カスタマーエンジニアの Ax(あっくす)こと小野です。
この記事は、Google Cloud Japan Advent Calendar 2022 - 今からはじめる Google Cloud の 24 日目の記事になります。
クリスマスまであと少し!ということで、サンタさんに伝えたいことない?と毎日子供に聞いている今日このごろです(※)。
(※: 執筆開始した時点(2022/12/12)の話です。我が家に煙突はありませんがきっとプレゼントは無事に届くはずです)
TL;DR;
- Google Cloud では "バッチ ジョブ" をマネージド・サービスで実行することができる
- Batch と Cloud Run jobs が代表例となる
- Cloud Run 使いは制約を満たせるなら Cloud Run jobs がお勧め
- Google Compute Engine (以降、GCE)(※) からのお引越し or 実行時間が長い or GPU 利用などがある場合は Batch がお勧め
- 両方のプロダクトともに定時実行や定期実行するためには Cloud Scheduler や Workflows などを組み合わせて使う
※:GCE についてはこちらの記事を参照ください。
はじめに
この記事では Google Cloud をこれから使っていく / 使ってみたいユーザを対象にしたシリーズの一環として Google Cloud で "バッチジョブ" を実行する方法をお伝えします。
日本語の "バッチ"、"バッチ ジョブ"、"バッチ処理" という言葉はコンテキストによってイメージするものが違うこともあるかと思います(英語の “Batch”、”Batch Processing” とも少し意味が違う印象もあります)。
人によっては運用管理基盤のようなジョブ、ジョブネットのような概念が登場するものをイメージするかもしれませんし、人によっては ETL 基盤の一部の機能をイメージするかもしれません。
今回は ETL 基盤の話はしないので、どちらかというと前者をイメージしたユースケースにおける話に特化したいと思います。
具体的なイメージをもってもらうため、他のパターンもありそうですが今回はこんなユースケースを考えてみました。
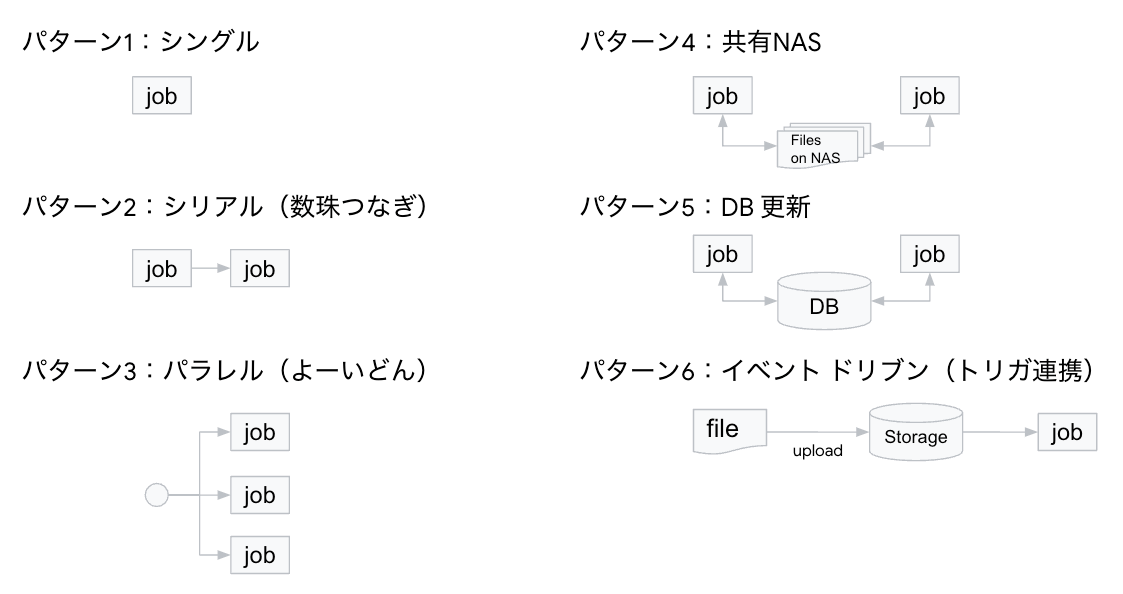
これらのユースケースを実現するプロダクトは何か...というテーマでミルクボーイさんのネタのような語り口で展開しようと思いましたが文字数の関係で(?)、辞めることにしました。
まずは代表的なプロダクトをご紹介したあと、2022年12月時点でどのユースケースでどのプロダクトを選ぶのがいいか...を一緒に考えたいと思います。
Cloud Run jobs とは
概要
Cloud Run jobs は Cloud Run の機能の一つという位置づけになっており、執筆開始時(2022/12/12)は Preview というステータスです。
Cloud Run については 二日目の記事でも触れられていますが、公式ドキュメントを見ると「Google のスケーラブルなインフラストラクチャ上でコンテナを直接実行できるマネージド コンピューティング プラットフォーム」という説明になっています。
マネージド・サービスであるため、インフラの管理が不要でスケーリング設定に応じてよしなに動いてくれる便利なコンテナ実行環境と言えます。
そんな Cloud Run の一部である Cloud Run jobs もやはりコンテナとしてジョブを実行するプロダクトになります。
リソースモデルとしては以下(Cloud Run jobs は右側)のようになっており、ジョブという単位の中に複数のタスクをもっているように見えるので、1 つのジョブの中で複数のタスクを実行できそうに見えます。
そして、もともとあった Cloud Run のリソースモデルに非常によくにていることがわかります。

実際、Cloud Run jobs が登場するまでは、制約を受け入れた上で Cloud Run でリクエストを受けて、そのリクエストの中でバッチ処理を実行する使い方をされていたユーザも多かったのではないでしょうか。
このため Cloud Run と Cloud Run jobs のリソースモデルが似ているのは必然とも言えるかも知れません。
ここまで、まずは Cloud Run jobs の概要をお伝えしました。
Cloud Run jobs の細かい機能などについてはKazuu さんの記事がわかりやすいので参照ください。
使い方
はじめて Cloud Run jobs を使う際に見えてくることにフォーカスして説明します。
ジョブの定義
まずはジョブを作成するところから始まります。
Cloud Run の画面に少し前から「ジョブ」というタブが増えています。こちらを選択して「ジョブを作成」を押下します。
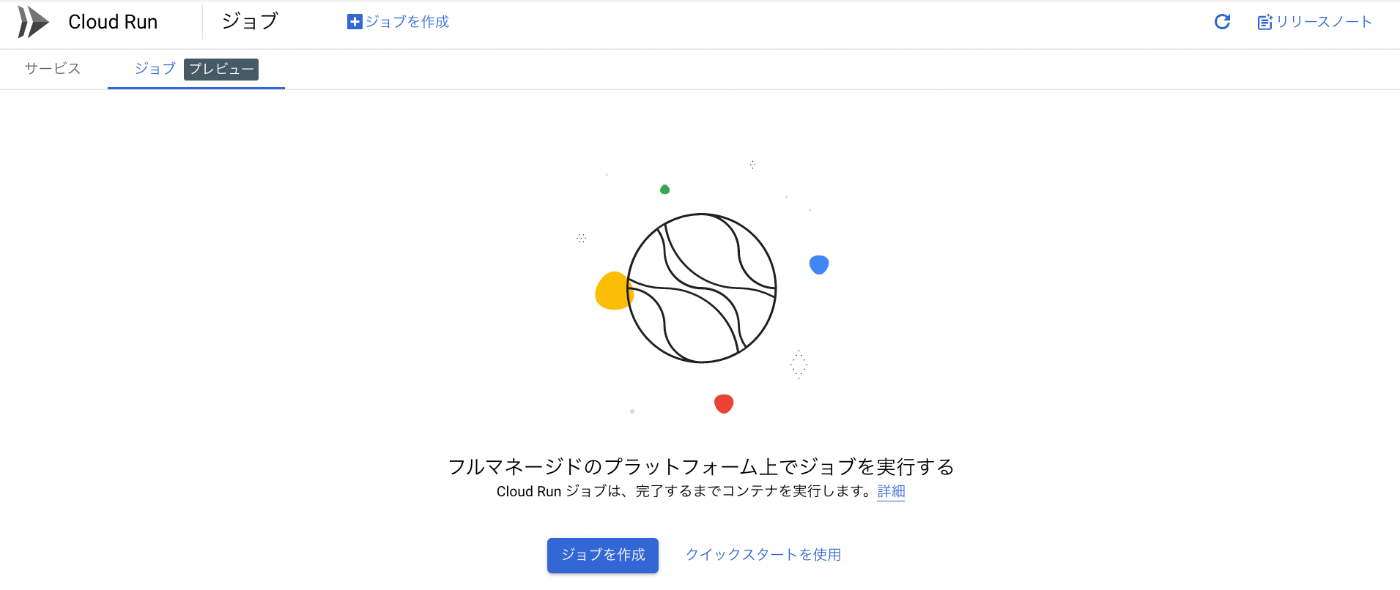
するとジョブで実行するコンテナイメージを指定する画面になるのですが、今回は「サンプル コンテナでテスト」を選択して、動きを確かめることにします。
このあたりは通常の使い方(「サービス」を定義する)と同じ感覚ですね。
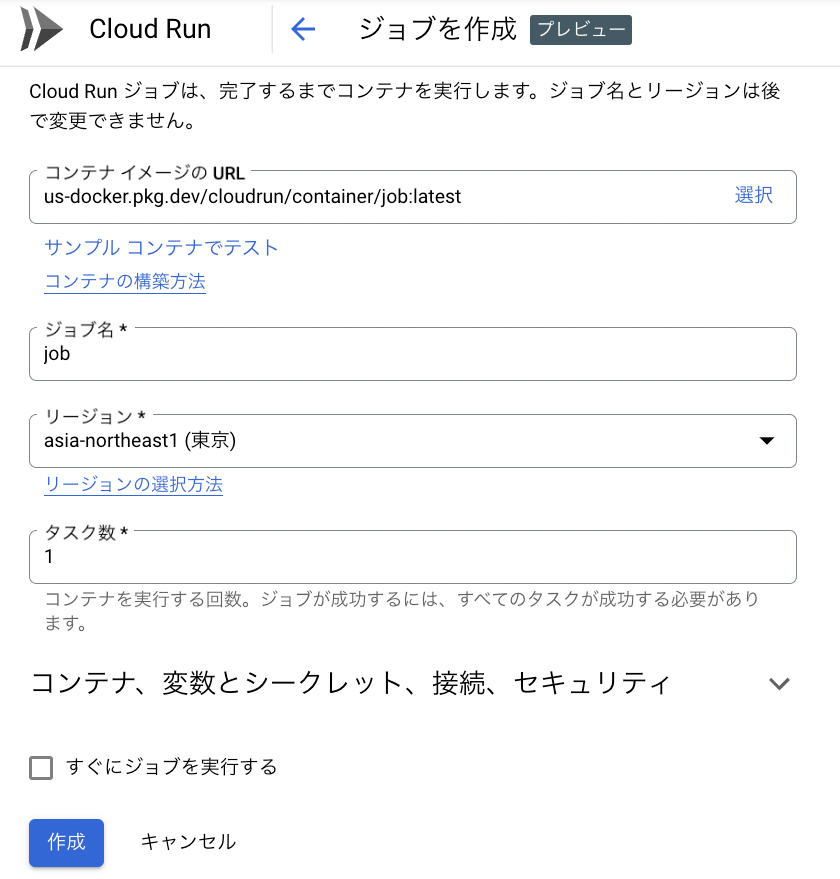
オプション設定らしき「コンテナ、変数とシークレット、接続、セキュリティ」について見てみます。
初見なので複数のタブがありますが現時点で全てを覚える必要はありません。
ざっくりとこんな時に使います。
- 全般:CPUやメモリといったコンテナの基本的な要求事項、タイムアウト値、リトライ設定や並列度を設定できます。
- 変数とシークレット:環境変数やパスワードなどのシークレットを設定できます(Secret Managerとの連携も可)。
- 接続:Cloud SQL との接続や VPC 上のリソースへの接続方法を設定できます。
- セキュリティ:どのサービスアカウントを使うかなどを設定できます。

ジョブの作成が終わるとこのような画面に遷移します。
また何も実行していないので「履歴」は空の状態です。
起動方法
実はジョブを定義する時にあった「すぐにジョブを実行する」を押せば即座に起動させることも出来たのですが、最初なのでまずは 1 ステップずつやっていきましょう。
ジョブの作成後の画面で「実行」を押下してもらうと、ジョブの実行が開始されます。

しばらくすると、実行が完了します。
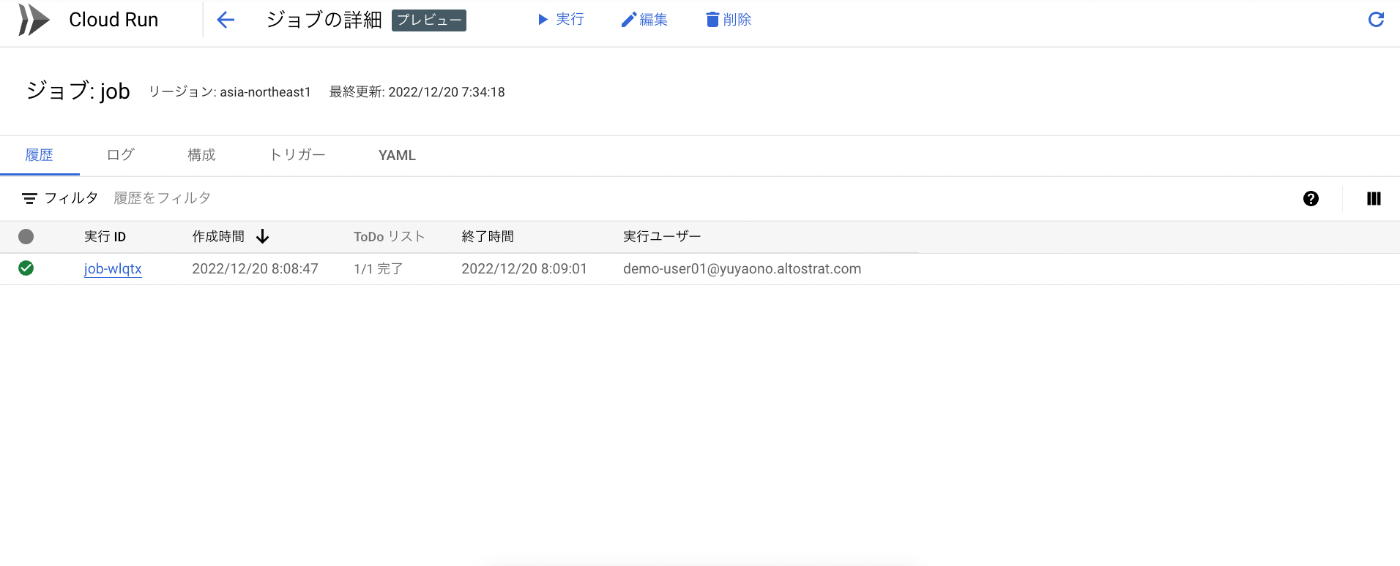
詳細画面をみてみると、ログも出力されていることがわかります。
実は Cloud Run と同じ仕組みで Cloud Logging にログが書き込まれているので、マネージド・サービスらしい恩恵にあずかることができます。

今回は GUI から起動しましたが、他の起動方法として大きく以下の 2 点があげられます。
実践的にはファイルのアップロードを契機に ジョブを実行したいようなケースもあると思います(私の中の辞書では「トリガ連携」と呼んでいます)。
このようなケースについては Eventarc、Workflows を組み合わせた方法がありますので、こちらを参照ください。
特徴
Cloud Run jobs の使い方をざっくりと説明しましたが、他にも便利な機能が沢山あります。
ご紹介した機能を含めて Cloud Run jobs の特徴として、まずはこのあたりをおさえていただくのが良さそうです。
- ジョブを予めコンテナ化することでジョブを実行できます
- 並列実行数の設定ができます(doc)
- 複数のタスクがある場合にシリアルに実行するか、並列に実行するかを指定できます。
- テーブルのカラムのバッチ更新など並列に実行できるものは処理の高速化が期待できます。
-
Google Cloud Storage (以降、GCS) のマウント設定ができます(doc)
- FUSE をつかって GCS を共有ディスクのように使うことができます
- 実行時間などに制約があります(doc)
- 執筆時点(2022/12/12)ではタスクの実行時間は最大1時間になっています。
- また GPU などの Accelerator は利用できません。
Batch とは
概要
Batch は割と最近デビューしたプロダクトでしたが、早くも GA のステータスになっています。
ただし、執筆開始時点(2022/12/12)で東京リージョンではまだ利用できないため US リージョンなどの他のリージョンでご利用いただく必要があります。
(追記:2023/4/11 に東京リージョンでの提供が開始されています(doc))
公式ドキュメントの文言にたち返ってみると「Batch は、Compute Engine 仮想マシン(VM)インスタンスでバッチ処理ワークロードのスケジューリング、キューイング、実行を行えるフルマネージド サービスです」と定義されています。
この記載の通り Cloud Run jobs とは異なり GCE を使って実行されることがわかります。
一方でバッチ実行に必要なリソースについては自動でプロビジョニングされるため、素の GCE をつかって自分で Cron 設定などを行ったり、ジョブ実行基盤を導入するよりハードルは低そうです。
かつ、素で GCE を使った場合は自分で環境を構築するのも大変ですし、実行基盤としての GCE の起動停止を自分でコントロールする仕組みも必要になるので考えることは増えそうです。
実は Batch を使うと VM の起動しっぱなしによるコスト増への対策にもなるので、一石二鳥どころの騒ぎではないのですが地味といえば地味かもしれないというのが個人的な感想です。
使い方
ジョブの定義
ナビゲーション メニュー(通称:ハンバーガー メニュー)から Batch の画面にアクセスするとこのような画面になっています。「CREATE JOB」を押下してジョブの作成を開始します。
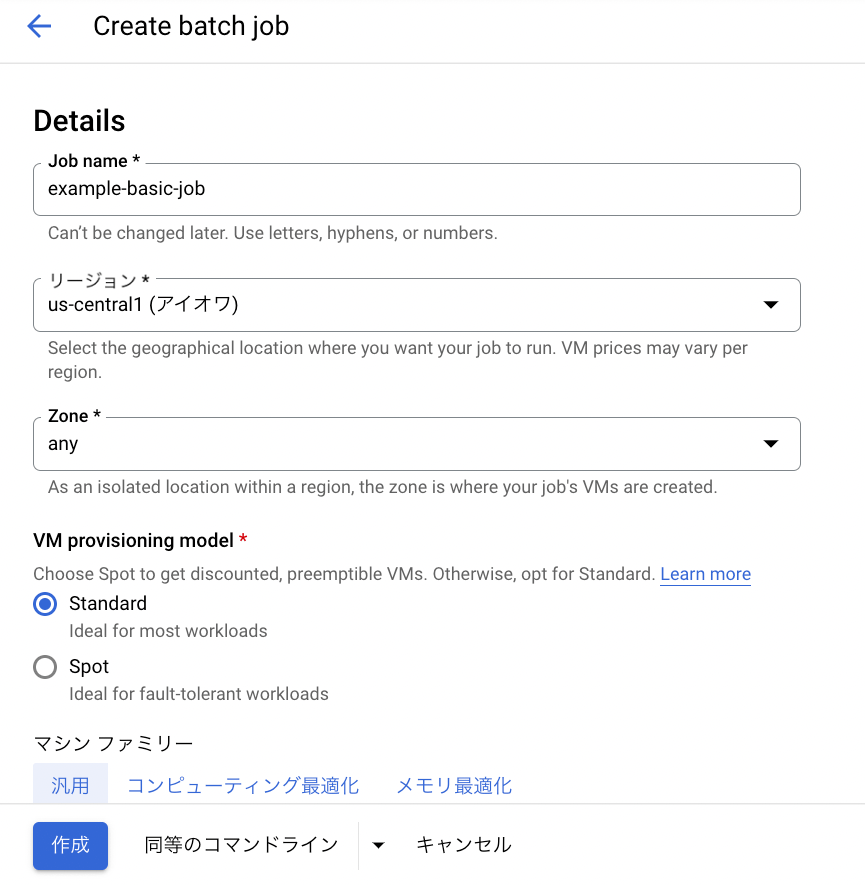
以下のようなジョブの定義を行う画面に遷移します。
ジョブ名の設定、リージョンの選択と GCE を裏で使っていることが実感できる Spot VMs を利用するかなど設定できることがわかります。
なお、Spot VMs を使う場合は処理の実行途中に削除(プリエンプト)する可能性があるため、ジョブ自体が冪等性の考慮を含め再実行できることを考慮した設計になっている必要があるので注意してください。
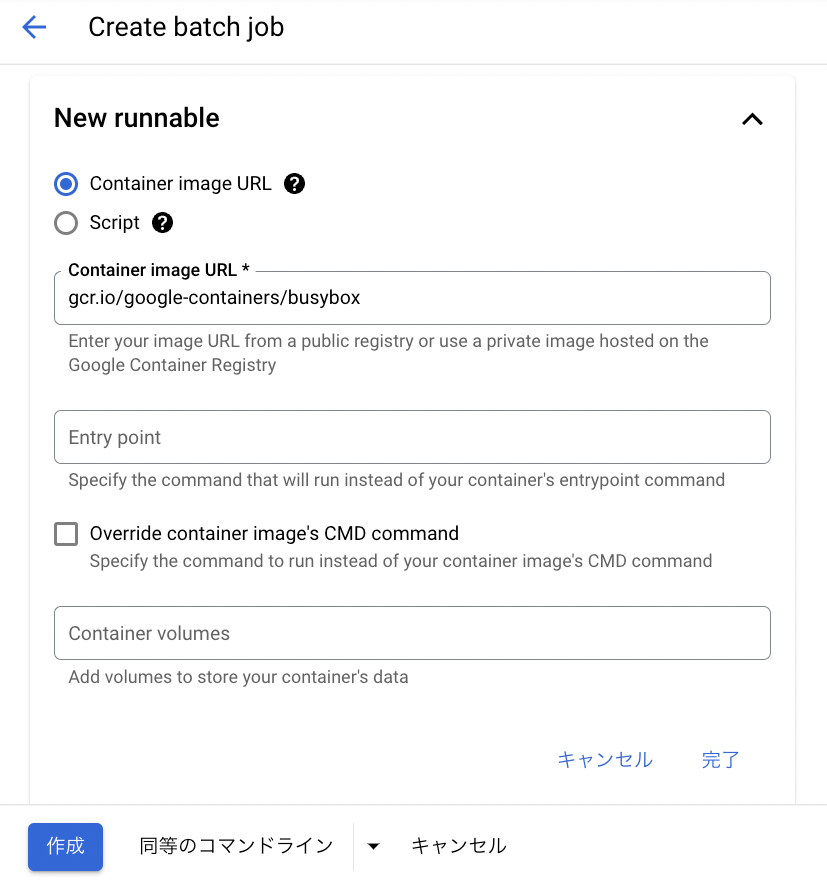
次はジョブの実行方法を選択する画面になります。
今回は Cloud Run jobs と粒度を合わせるため、コンテナをつかったジョブの実行を選択しましょう。
簡単のためその他の設定はそのままにして、「作成」ボタンを押下します。
すると、ジョブ定義が反映されます。

起動方法
Cloud Run jobs のときとは違い、実はジョブを作成したタイミングで実行にむけてスケジューリングされています。
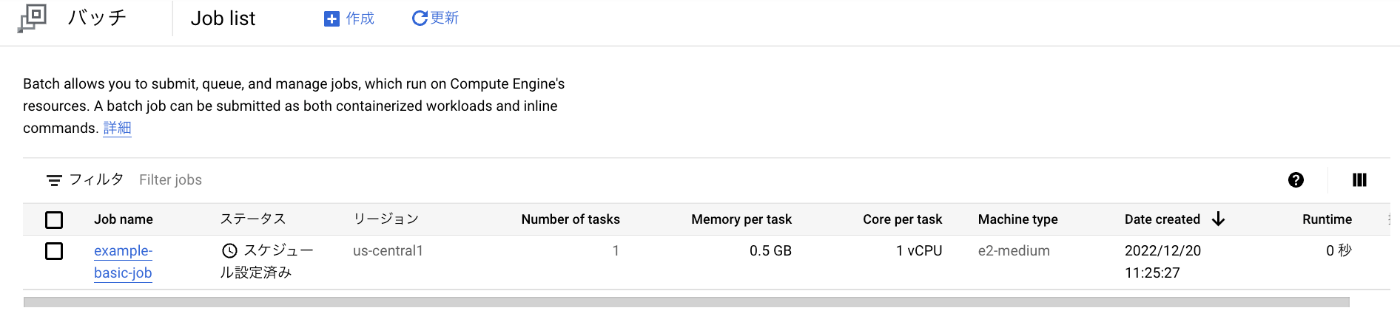
その裏で実はこのように GCE のインスタンスが稼働しています。
そして、ジョブが終了するとGCE のインスタンスは自動で削除されます。
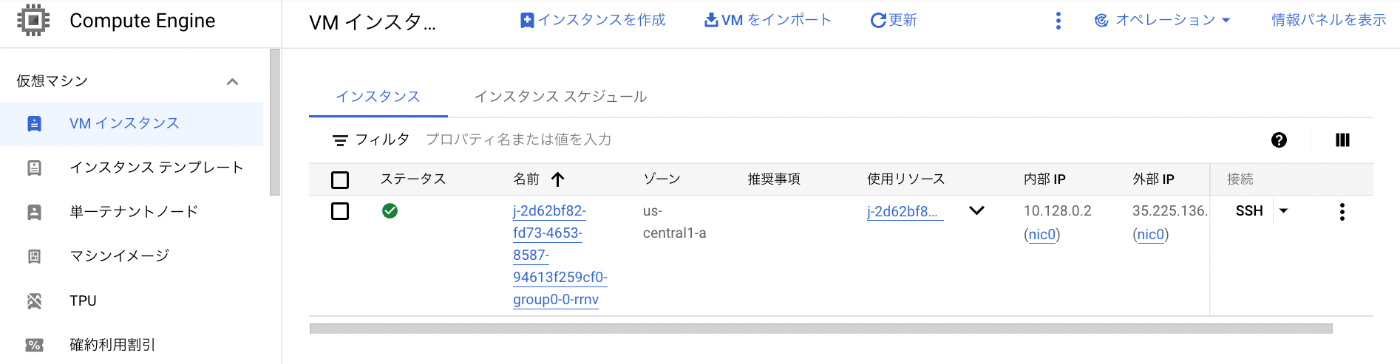
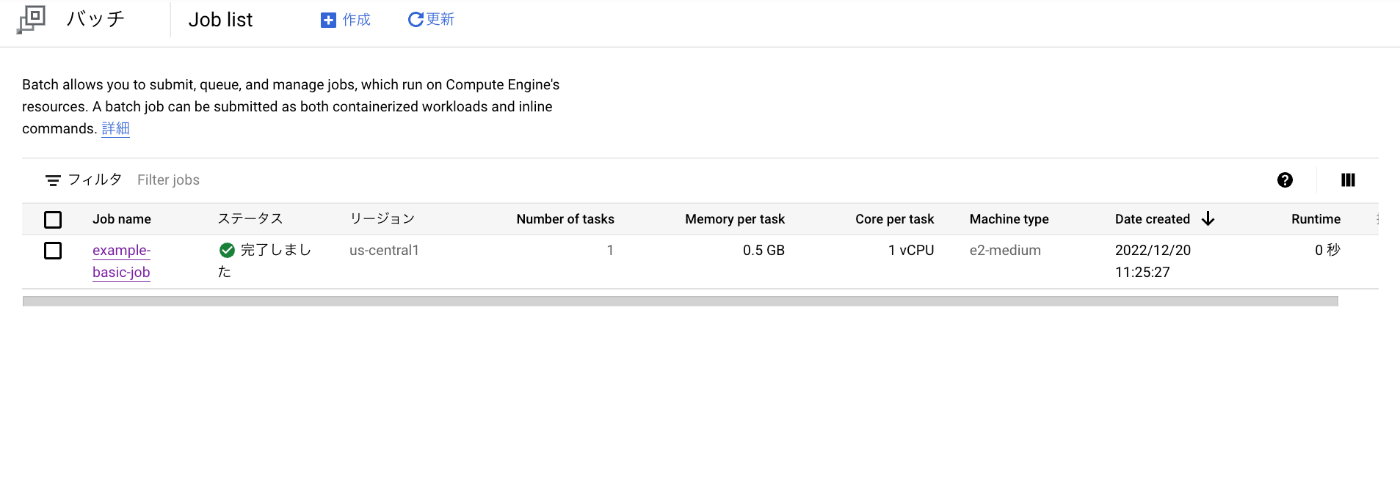
ジョブの実行が完了すると Batch の画面でもステータスが「完了しました」になっていることがわかります。
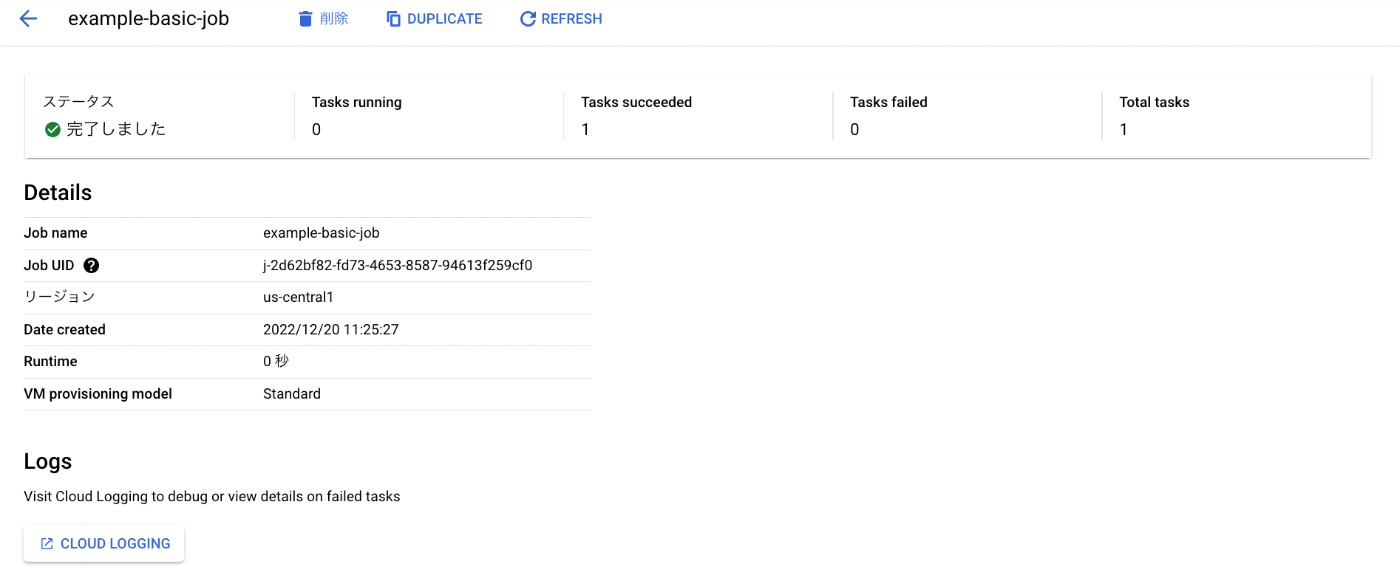
ジョブ名を押下して詳細画面をみると、Cloud Logging へのリンクがあります。
やはりマネージド・サービスらしく Cloud Logging にログが自動で集約されます(doc
)。
今回は GUI から起動しましたが、他の起動方法として大きく以下の 2 点があげられます。
現状はジョブの作成と同時に実行されるのでその点は注意が必要です。
ただし、Cloud Run jobs と同様に定時実行など意識して Cloud Scheduler や Workflows などを組み合わせることを考えると違いは意識しなくて良さそうです。
Batch と Workflows を組み合わせる方法はこちらを参照いただければと思います。
特徴
- コンテナまたはスクリプトを指定してジョブを実行できます
- Cloud Run jobs とちがい、簡単なスクリプトであれば、gcloud コマンドの引数やジョブ定義の JSON に直接書くことも可能です。
- 並列度の設定ができます。
- Cloud Run jobs と同様に並列度の設定をおこなうことで、柔軟なジョブ構成を作れます。
- 外部ディスクの選択肢が豊富
- GCE の Persistent Disk、local SSD を利用できます
- FUSE をつかった Cloud Storage も利用できます
- Filestore も利用できます
- GPU を利用することができます
- AI/ML、HPC などの分野に対応することができます
どっちのプロダクトで Show
ここまでプロダクトの説明に終始してきたので、実際のユースケースだとどっちが良いんだよ!という疑問が残っています。冒頭で予告したようにパターン/ユースケースごとにどちらのプロダクトを採用するのかを一緒に考えたいと思います。
Batch の方は執筆時点(2022/12/12)では東京リージョンでの提供がないため、 仮に US リージョンで使うならという前提とします。
(追記:2023/4/11 に東京リージョンでの提供が開始されています(doc))
パターン1: シングル

粒度の違いはありますが 1 ジョブを動かすだけなら、Cloud Run jobs も Batch も問題なく使えそうです。
焦点になるのは実行時間と、GPU 利用の有無になると思います。
Cloud Run jobs の場合は最大 1 時間の制約と GPU 利用不可となりますので、その場合は Batch を選択するのが正しそうです。
(この考え方は自体は他のパターンにも当てはまることを留意してください)
パターン2: シリアル(数珠つなぎ)

シリアルに処理を行うという意味だと 1 ジョブの中で論理的に行うことも出来ますが 1 ジョブに複数の機能をもたせると作りによってはリトライができないなどでトラブルフォローが難しくなることを考慮して、1 ジョブ 1 機能のイメージでパターン 1 の粒度でジョブをつなげていくことを前提とします。
Cloud Run jobs の場合、2 パターン目はユースケースが限られそうですが
- 複数の Cloud Run jobs を Workflows などで数珠つなぎにする
- 並列度を 1 に設定しつつ、1 つのジョブ定義の中で環境変数等で動きを変える
といったことが考えられます。
このパターンでは、個々のジョブ単位では1時間の制限がありますが、処理を複数のジョブの数珠つなぎとすることで全体としてより長い時間を必要とする処理も実行が可能となるため Cloud Run jobs の最大 1 時間の実行時間制約の対策にもなっています。
このため Cloud Run + Workflows という真のサーバレス構成を適用できる可能性があがります。
Batch の場合はジョブの定義のなかで複数の Runnable(Cloud Run jobs の Task のようなもの)を定義できるのでもう少しシンプルになります。
- runnable を複数定義して実行する
実は Cloud Workflows と組み合わせて Cloud Run jobs と同じ事もできるのですが、Batch の方は 1 つのジョブに複数のコンテナを指定して順次実行できるのでプロダクト単体で似たようなことが実現できます。
パターン3: パラレル(よーいどん)
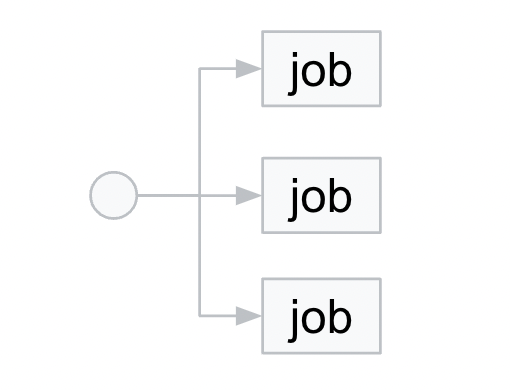
このパターンについては Cloud Run jobs も、Batch も並列度を設定できるので、どちらでも良さそうです。
実は細かい話をすると Cloud Run jobs については CPU の数での上限が決まる(doc)ので、注意が必要です。
ジョブあたりの並列タスクも執筆時点(2022/12/12)では Batch が 1,000 と高い多重度を実現できます。
パターン4: 共有NAS
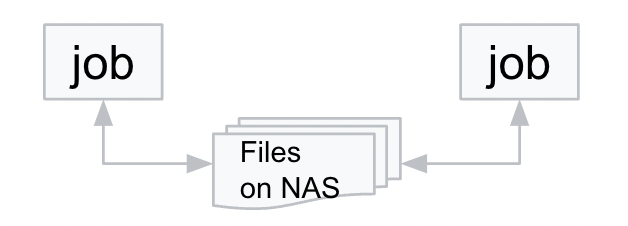
このパターンについても Cloud Run jobs と Batch の双方で GCS、Filestore などを共有 NAS 的に利用できるので問題ありません。
Cloud Run jobs の方は Cloud Run 自体が VPC の外にいるので、Filestore と組み合わせるときはこちらのドキュメントにあるように Serverless VPC Access の設定が必要である点だけ注意が必要です。
GCS と組み合わせるときは FUSE を使うだけなので、こちらのドキュメントの通り Serverless VPC Access の設定は不要です。
パターン5: DB 更新
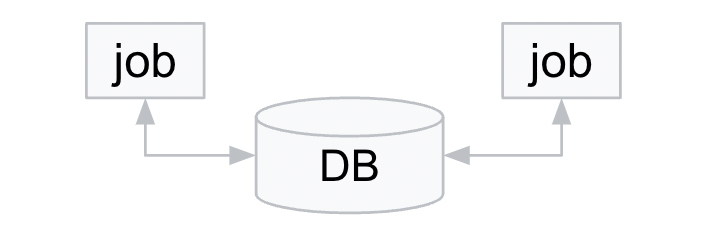
このパターンについても Cloud Run jobs と Batch の双方で対象の DB への接続方法が確立できれば問題ありません。
Cloud Run の場合はパターン 4 と同様に、Cloud SQL で Private IP 利用などを考える場合は、Serverless VPC Access の設定が必要になるのが注意点でしょうか。
(因みに Cloud SQL の Public IP や Privarte IP の話はこちらの記事を hanotsu さんが書いてくれているので、気になる方はあわせて参照ください)
パターン6: イベント ドリブン(トリガ連携)

このパターンについては厳密には Cloud Run jobs と Batch の機能を使ってると言い切れないですが起動方法の話でふれた通り、各種プロダクトの組み合わせにて簡単に実現できます。
ある意味、Executor としての Cloud Run jobs と Batch という見方ができるので、他のプロダクトとの組み合わせは容易です。
各パターンからの学び
いかがでしたでしょうか?
それぞれのユースケースでどちらのプロダクトが利用可能かをみてきました。
お気づきの方もいらっしゃるかもしれませんが、パターン 1−3 はジョブの構成について、パターン 4−6 は処理の方式/内容にフォーカスした分類を意識していました。
何れのパターンについても Cloud Run jobs、Batch ともに対応が可能であることがわかりました。
ここまであまり触れていませんが、”ジョブ” の単位については Cloud Run jobs と Batch でそれぞれ意識していただきたい粒度の違いがあるとは言え、なんとも悩ましいですね?
今年最後の煩悩を生みそうです。
執筆時点(2022/12/12)は東京リージョンの前提であれば Cloud Run jobs の一択になるのですが、Batch が将来的に東京リージョンで利用可能となった場合に何を基準に選べばよいのでしょうか?
(追記:2023/4/11 に東京リージョンでの提供が開始されています(doc)。)
色々な観点はあると思いますが、こういった観点での選択するのはいかがでしょうか?
- Cloud Run jobs を選択する理由
- Cloud Run だけを利用することで学習コストを抑えたい
- ジョブの実行時間は 1 時間以内である
- Batch を選択する理由
- ジョブの実行時間が 1 時間を超えてしまう
- 既存がシンプルなスクリプトのみなので、コンテナを用意するのも Too Much
- 既存が VM ベースのバッチの仕組みで似たような構成にしたい
- 現状 GCE を使っていて、バッチ実行のために起動しっぱなしでコストが課題になっている
- GPU 利用、HPC なユースケースに該当する
そもそも運用性観点でのジョブの再ランまわりの機能やログの見え方、セキュリティ観点など他にも沢山考えることはあると思いますが、まずは取っ掛かりとして参考にしていただければと思います。
まとめ
この記事では Google Cloud で "バッチジョブ" を実行する方法をお伝えしました。
代表的なプロダクトとして、Cloud Run jobs と Batch といったマネージド・サービスに分類されるプロダクトをご紹介しました。
両プロダクトともに様々なユースケースに対応できますので、年末はゆっくり休んでもらって年始あたりから活用を検討いただければ幸いです。
私の記事は以上で終了となります。ここまで読んでくださった方、ありがとうございました。
次回の「Google Cloud Japan Advent Calendar 2022 - 今からはじめる Google Cloud」 は、今年の Next で登場したあのプロダクトが登場する「Cloud Shell & Workstation」に関する記事になります。

Discussion