多段ベクトル検索を使ってRAGの回答性能を向上させる
はじめに
今までは生成AIと初めてチャットを開始するときに、「背景」「状況」「場面」などの文脈をいちいち指示に含める必要がありました。
生成AIを使い慣れている人であれば、文脈を意識した指示が自然にできるかもしれませんが、そうでない人にとってはかなり難しいテクニックに感じることもあるかと思います。
しかし、それらの文脈をいちいち入力せずにChatGPTが過去の会話履歴から自然に文脈を推測するような機能が実装されました。
まだ一部のユーザしか利用できませんが、仕組みや動作デモなどがいくつか公開されています。
そこでOpenAIのAPIでも似たような機能が実装できそうなので、本記事では多段ベクトル検索を利用したRAGの実装方法とその仕組みについて解説したいと思います。
OpenAIのAssistant APIについて
はじめにOpenAIの会話のセッションを管理する単位であるThreadについて説明します。
以下の図は、OpenAIのAssistant APIを使用した会話の流れを示しています。以下は、図に表示されている各オブジェクトが何を表しているかの説明です。
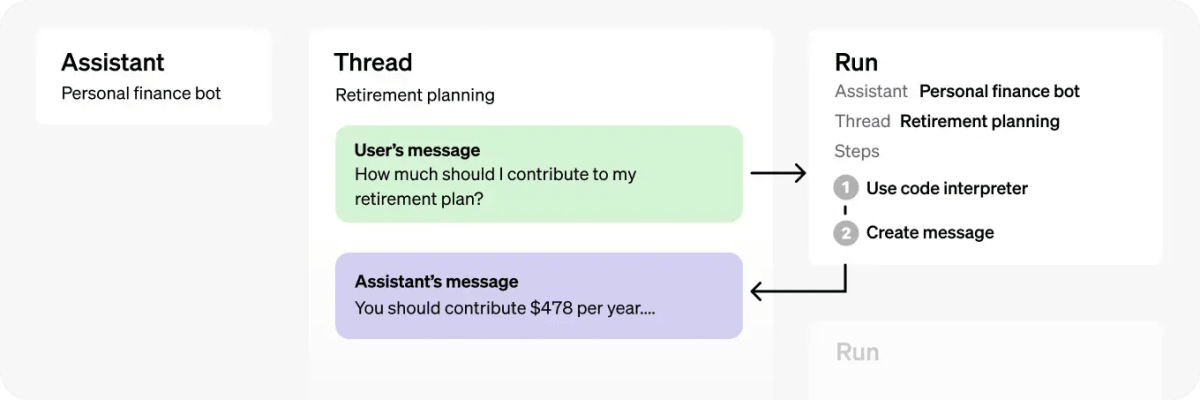
- Assistant: OpenAIのモデルを使用し、ツールを呼び出すために特別に構築されたAIです。
- Thread: Assistantとユーザー間の会話セッションです。Threadはメッセージを保存し、コンテンツをモデルのコンテキストに合わせて自動的に切り詰める処理を行います。
- Message: Assistantまたはユーザーによって作成されたメッセージです。メッセージにはテキスト、画像、その他のファイルを含めることができます。メッセージはThread上のリストとして保存されます。
- Run: Thread上でAssistantを呼び出すことです。Assistantは、その設定とThreadのメッセージを使用して、モデルやツールを呼び出しタスクを実行します。Runの一環として、AssistantはThreadにメッセージを追加します。
- Run Step: Runの一環としてAssistantが取った詳細なステップのリストです。Assistantは、実行中にツールを呼び出したり、メッセージを作成したりすることができます。Run Stepを調べることで、Assistantが最終結果に至る過程を内省することができます。
このThreadオブジェクトは会話を開始するときに新規作成されます。
ChatGPTだと以下のような画面でThreadオブジェクトのような物が作成されています。API経由での操作ではないので、実際にThreadオブジェクトを確認することはできません。

ChatGPTはチャット履歴から過去の会話を探して再開しない限り、常に新規で会話セッションが作成されるため文脈を一から入力する必要があります。
Assistants APIではこの会話セッション(Threadオブジェクト)を再利用することができるので、ユーザの質問内容に関連したThreadオブジェクトを探すことができれば過去の会話を継続する形で会話を開始することができるようになります。
OpenAIのスレッドをAPIで作成するにはplaygroundから作成することができます。
使い方はChatGPTに似ています。

API経由での会話セッションはこちらから確認することができます。(OpenAIアカウントのオーナー権限が必要です。)
このthread_から始まるIDがThreadオブジェクトを識別するためのIDです。

Pineconeを使ったベクトル検索について
Assistants APIにもベクトル検索を使ったRAGが実装されていますが、pineconeとOpenAIの埋め込みモデルを組み合わせることでRAGを構築することができます。
今回はOpenAI Embedding APIのtext-embedding-3-smallを使って解説します。

埋め込みとインデックス
- OpenAI Embedding APIを使用して、テキストデータのベクトル化します。
- これらのベクトルデータをPineconeにアップロードすると、数百万/数十億のベクトル埋め込みを保存してインデックス化し、超低レイテンシで検索できるようになります。
検索
- ユーザの質問内容をOpenAI Embedding APIに渡します。
- 結果のベクトルデータを取得し、Pineconeにクエリとして送信します。
- ベクトルデータに類似したドキュメント(メタデータ)を返します。
ベクトル検索を使った会話履歴の検索
それではユーザの質問内容に関連した過去の会話セッションを検索するコードを書いてみましょう。
こちらからpineconeアカウントを取得し、APIキーを取得します。
続いてOpenAIのAPIキーも取得します。
APIキーが取得できたら環境変数にAPIキーを設定します。
export PINECONE_API_KEY=xxxxxxxxxxxx
export OPENAI_API_KEY=xxxxxxxxxxxxx
APIキーが設定できたら以下のコードを実行して、スレッドの内容をベクトル化していきます。
import os
import time
from openai import OpenAI
from pinecone import Pinecone, PodSpec
# クライアントの初期化
pc = Pinecone(api_key=os.getenv("PINECONE_API_KEY"))
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
embedding_model = "text-embedding-3-small"
index_name = "semantic-search-openai"
thread_id = "thread_から始まるID"
# Pineconeのインデックスを確認する
if index_name not in pc.list_indexes().names():
# インデックスがなければ作成する
pc.create_index(
index_name,
dimension=1536, # dimensionality of text-embed-3-small
metric="dotproduct",
spec=PodSpec(environment="gcp-starter"),
)
# インデックスが初期化されるまで待つ
while not pc.describe_index(index_name).status["ready"]:
time.sleep(1)
# インデックスに接続
index = pc.Index(index_name)
# OpenAI API
client = OpenAI(timeout=20.0, max_retries=3)
# スレッドのメッセージを取得
messages = client.beta.threads.messages.list(
thread_id=thread_id,
order="asc",
).data
# 会話のテキストを時系列で抽出する
thread_data = ""
thread = client.beta.threads.retrieve(thread_id=thread_id)
for message in messages:
for content in message.content:
if content.type == "text":
thread_data += f"- [{message.role}]: {content.text.value}\n"
# 会話のテキストをベクトル化
res = client.embeddings.create(
input=[thread_data],
model=embedding_model,
)
embed = (
client.embeddings.create(input=thread_data, model=embedding_model).data[0].embedding
)
# ベクトルデータのみをPineconeに保存する。
# ベクトル検索でマッチした場合に該当スレッドを特定するために、thread_idをpineconeのidとして保存します。
# assistants apiでthreadが更新された場合はこのidを使ってベクトルデータを更新することができます。
# 最新の情報で回答したい場合もあるかもしれないので、メタデータにはスレッドの作成時間も保存しておきます。
res = index.upsert(
vectors=[
{
"id": thread_id,
"values": embed,
"metadata": {"created_at": thread.created_at},
}
],
)
pineconeの管理画面から以下のようなデータが登録できていることが確認できます。

赤枠がOpenAIのthreadオブジェクトのIDで、青枠がtext-embedding-3-smallによってベクトル化されたデータです。
以下の文字列がtext-embedding-3-smallによってベクトル化されています。
- [user]: ChatGPT メモリについて説明してください。
- [assistant]: ChatGPTのメモリは、特定の情報やコンテキストを記憶し、会話の中でそれを使用して議論を進めることができます。ChatGPTのメモリは使用するほど向上し、時間が経つにつれて改善されていきます。具体的な例としては、会議の議事録やブレインストーミングなどの場面での活用が挙げられます。
また、ChatGPTはユーザーの好みや情報を覚えており、それに基づいて適切な提案や返答を行います。例えば、会話の中で子供が好きなものや好みが言及された場合、それを覚えておいて後続の会話や提案に反映させることが可能です。これにより、よりパーソナライズされた会話やサポートが提供されることが期待されます。
続いて上記の質問に似たような質問から該当するthreadオブジェクトのIDが特定できるかどうか試してみます。
import os
from openai import OpenAI
from pinecone import Pinecone
pc = Pinecone(api_key=os.getenv("PINECONE_API_KEY"))
client = OpenAI()
index_name = "semantic-search-openai"
embedding_model = "text-embedding-3-small"
# 質問内容
query = "ChatGPTがユーザーの好みや情報を取得することはできますか?"
# 質問内容をベクトル化
xq = client.embeddings.create(input=query, model=embedding_model).data[0].embedding
index = pc.Index(index_name)
# 質問内容に関連した上位3件の類似した内容のスレッドを検索します
res = index.query(vector=[xq], top_k=3, include_metadata=True)
for match in res["matches"]:
print(f"score: {match['score']:.2f}, thread_id {match['id']}, meta:{match['metadata']}")
上記のコードを実行すると以下のようになります。該当するThread IDのスコアが高くなっていることがわかります。
score: 0.57, thread_id thread_Ghg1jY0NUG6tW8LNVEKqTltM, meta:{'created_at': 1711272161.0}
score: 0.32, thread_id thread_XEnpu5oqviy2YaBvoRgPVufX, meta:{'created_at': 1711162412.0}
score: 0.28, thread_id thread_vL9M7v7byTfuxQSM6ubBaknh, meta:{'created_at': 1711270137.0}
上記の結果を踏まえて以下のようなコードを作成して実行してみましょう
import os
from openai import OpenAI
from pinecone import Pinecone
from typing_extensions import override
from openai import AssistantEventHandler, OpenAI
from openai.types.beta.threads import Text, TextDelta
from openai.types.beta.threads.runs import ToolCall, ToolCallDelta
class EventHandler(AssistantEventHandler):
@override
def on_text_created(self, text: Text) -> None:
print(f"\nassistant > ", end="", flush=True)
@override
def on_text_delta(self, delta: TextDelta, snapshot: Text):
print(delta.value, end="", flush=True)
def on_tool_call_created(self, tool_call: ToolCall):
print(f"\nassistant > {tool_call.type}\n", flush=True)
def on_tool_call_delta(self, delta: ToolCallDelta, snapshot: ToolCall):
if delta.type == "code_interpreter":
if delta.code_interpreter.input:
print(delta.code_interpreter.input, end="", flush=True)
if delta.code_interpreter.outputs:
print(f"\n\noutput >", flush=True)
for output in delta.code_interpreter.outputs:
if output.type == "logs":
print(f"\n{output.logs}", flush=True)
pc = Pinecone(api_key=os.getenv("PINECONE_API_KEY"))
client = OpenAI()
index_name = "semantic-search-openai"
embedding_model = "text-embedding-3-small"
# 質問内容
query = "ChatGPTがユーザーの好みや情報を取得することはできますか?"
# 質問内容をベクトル化
xq = client.embeddings.create(input=query, model=embedding_model).data[0].embedding
index = pc.Index(index_name)
# 質問内容に関連した上位3件の類似した内容のスレッドを検索します
res = index.query(vector=[xq], top_k=3, include_metadata=True)
for match in res["matches"]:
# 閾値以上のスレッドを割り当てて回答する
if match["score"] > 0.5:
thread_id = match["id"]
try:
# アシスタントを作成する
assistant = client.beta.assistants.create(
name="Test Assistant",
tools=[{"type": "code_interpreter"}],
model="gpt-4-1106-preview",
)
# 取得したスレッドにメッセージを追加
client.beta.threads.messages.create(
thread_id=thread_id,
role="user",
content=query,
)
# runオブジェクトを生成して回答を生成する
with client.beta.threads.runs.create_and_stream(
thread_id=thread_id,
assistant_id=assistant.id,
event_handler=EventHandler(),
) as stream:
stream.until_done()
finally:
client.beta.assistants.delete(assistant.id)
break
実行結果
assistant > ChatGPTは、会話中にユーザーが共有する情報を理解し、その情報を会話のコンテキストの一部として扱います。たとえば、ユーザーが好きな映画や興味を持っている主題について話すとき、ChatGPTはそれを会話の進行で考慮し、関連する内容に基づいた反応や提案をすることができます。
ただし、OpenAIの方針により、ChatGPTはユーザーの個人情報を保存したり、追跡したりすることはしません。セッション間で情報が維持されることはなく、プライバシーの保護とデータセキュリティが重要視されています。ユーザーが共有する情報はその会話の中でのみ一時的に利用され、ユーザーの同意なく情報を保存したり使用することはありません。
プラットフォームやツールによっては、よりパーソナライズされた経験を提供するために、ユーザーからデータを収集し、それを使い続ける機能を持つものもありますが、プライバシーに配慮した設計とユーザーのコントロールが必要です。この点は、法規制や個々のサービスのプライバシーポリシーによって規定されることが一般的です。OpenAIでは、ChatGPTを使って作業や交流を行う際にも、プライバシーを尊重し、個人データの使用に関する明確なガイドラインを設けています。
threadの内容を確認すると、以前のスレッドの続きから会話が始まっていることがわかります。

ここまでに説明した構成を図にすると以下のようになります。
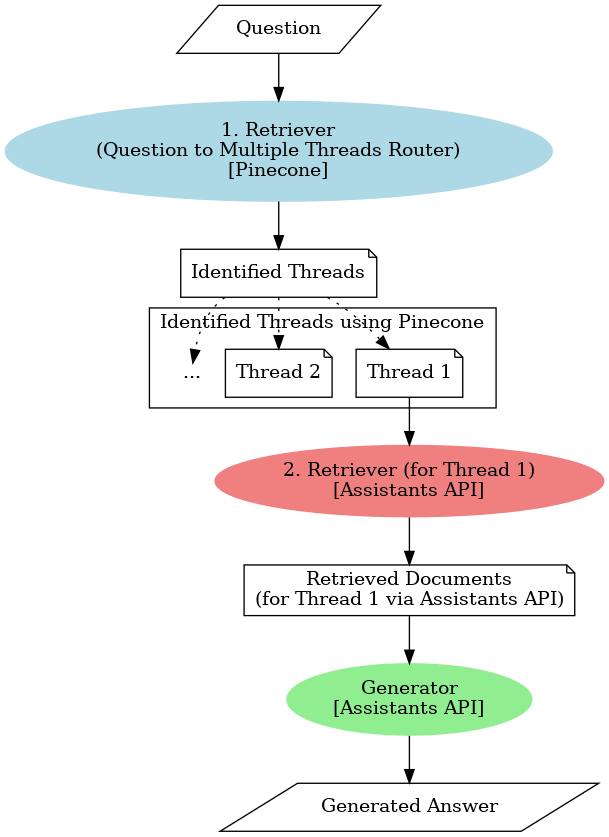
今回の検証ではThreadオブジェクトの内のトークン数が少なくてシンプルですが、質問内容から関連したスレッドをベクトル検索した後にスレッド内でmemory.txtというファイルの内容を回答できることが確認できました。このように多段でベクトル検索を実行することによって「ChatGPTがユーザーの好みや情報を取得することはできますか?」のように文脈が欠如した質問に対して意図した回答を生成することができるようになりました。
検証に利用したスレッド数は少ないため意図した回答を生成することができましたが、複数人で利用するようなチャットボットとして利用する場合は、以下に紹介されているようなリランキングのテクニック等を使ってさらに精度を上げていく必要がありそうです。
まとめ
この記事では、多段ベクトル検索を利用してRAGの回答性能を向上させる方法について解説しました。
OpenAIのAssistant APIを使用して、ユーザーの質問内容に関連した過去の会話セッションを検索し、過去の会話を継続する形で文脈が欠如しているような質問への回答を生成しました。
今後はこちらにも多段ベクトル検索の機能を実装して公開したいと考えています。
最後まで読んでいただきありがとうございました。
参考
Discussion