25年に渡るデータマネジメント私史~あるエンジニアの取組み
はじめに
生成AIの登場により、改めて脚光を浴びているキーワードの一つにセマンティックレイヤーがあります。このセマンティックレイヤーの概念、実は非常に歴史は古く、1990年代まで遡ります。
セマンティックレイヤーとその歴史
セマンティックレイヤーの概念は、1991年に歴史あるBI製品である、SAP Business Objects(BO)によって提唱されました。当初はリレーショナルデータベースのアクセスやそのリレーショナルシップを効率良く管理するための機能でしたが、その後ビジネス情報と複雑なデータモデルとのギャップを埋める抽象化レイヤーとして位置付けられ、高度な業務知識なく、データにアクセスし、正確な分析が行えるためのモダンデータスタックにおける重要な機能へと進化を遂げました。
あるエンジニアのデータと向き合った四半世紀に渡る物語
私は2000年にBOと出会い、BIユーザーとしてその概念に触れ、またその後BI管理者としてその概念の実践にも携わりました。それらの経験を派生する形で、その後より上流の基幹系におけるデータディクショナリの整備や再びデータ基盤としてデータカタログの取組みを行ってきました。
そのような、実に25年以上の、つまり四半世紀に渡るそれぞれのフェーズで私が経験した事、学んだこと、また反省した事も含め、自身の今考えている事を言語化したいと考え、せっかくなので皆さんの何かの道標や参考になるかもと思いたち、記事にしてみました。
今回の記事では、データマネジメントに関する私の経験とその中で触れたセマンティックレイヤーなどのデータマネジメントの概念への取組みについてつらつらと書いておりますので、物語を読む気持ちでのんびり読んでいただければと思います。
プロローグ:新卒→転職→Business Objectsとの出会い
さて、データに関する話を始めるに辺り、その原体験の話を最初にしたいと思います。私は1999年に新卒で建築関係の会社に営業職で入社しました。当時はまだ電子計算機(電算)で見積書を作成する時代で、数台の端末に全員が並んで価格表を見ながらパチパチと打ち込みながら時間を掛けて見積を作っていました。まだ一人1台のパソコンもなく、パソコンは個人で調達する時代でした(今だと考えられない!)。
私は文系出身だったのですが、入社祝いに父親からお古のノートパソコンをもらい、Windows95の参考本などを買って使い方を独学で学んでいく中で、EXCELというツールが何となく目に留まり、その中でVLOOKUPという関数を用いて特定の行のある情報を抜き出すということが出来るということを知りました。
その時にあの毎日並んで見積を作る電算業務がEXCELで解決するので!?と閃き、しばらく仕事そっちのけで、数百個の商品マスタ(品番・名称・単価・原価)をシートに転記し、見積フォーマットを自作し、VLOOKUPの関数により、入力欄に品番を入れると名称、単価を商品マスタシートから取得し、それに対する台数と値引率を入れる事で見積書が出来るEXCELファイルを作りました。
いきなり話が逸れた上に、今となってはとてもレベルの低い内容ですが、私の中ではデータを用いて業務を向上させるというデータ活用の原体験になったと共に、テクノロジーを上手く使えば課題を大きく解決できるようになるという成功体験を持つ事が出来ました。
さて、その会社は見積を作った事以外は全く楽しくなく1年で辞めてしまい、大学時代の先輩の紹介で、今も在籍するCCCグループの子会社の1つに再び営業職として転職しました。
その会社では当時市場に出始めていた映像や音楽のDVDレンタルに関するコンサルティングや流通卸を行う事業をしており、その事業を伸ばすためにデータ活用に取り組んでおり、入社間もない私にもパソコン!とBIツールである、Business Objects(BO)が与えられました。
2000年当時に、BIツールを大々的に導入している企業は、日本でも限られており、当然ながら社内でも限られた人だけが使える状況でしたが、前職で見積書をEXCELで自作した経験が活き、テーブル=商品マスタのシート、このシートが複数あり、組み合わせて使うのか。という感覚で、EXCELの関数に似たBOの関数も覚え、1年ほどで、「レポート作成はこいつに頼めば良い」という、BIユーザーのエキスパート的な立ち位置になりました。
Business Objects(BO)について
さて、ここで、Business Objects(BO) について説明させてください。
BOは1990年にフランスで創業したビジネスインテリジェンス(BI)製品の先駆的企業で、データ分析ツール業界の発展において大きな影響を与えた会社の1社です。
そして1991年にセマンティックレイヤーの概念を打ち出し、それに関する特許を取得しました。
つまり、昨今注目を集めているセマンティックレイヤーは、実は新しい概念ではなく、30年以上前に提唱されていた概念であるという事です。
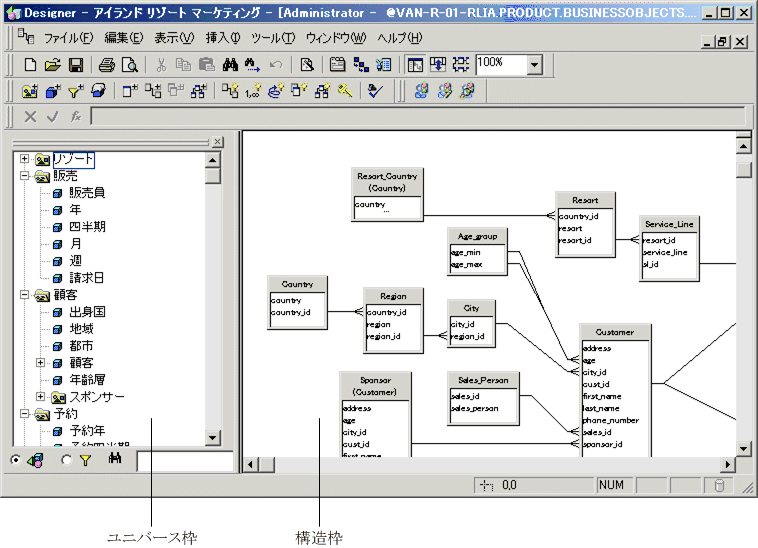
BOの機能要素の一つとして、ユニバースという機能があり、これはデータベース内のあるデータ群とそのリレーショナルの管理(結合キー)を行い、そのテーブルやカラムに対するビジネス用語やデータモデルを管理する機能を有しています。すなわち、セマンティックレイヤーを具現化した機能という事です。
ユニバースデザイナーのオブジェクト管理画面(テーブルなどの定義とリレーション定義)
ユニバースデザイナーのビジネスメタ情報管理
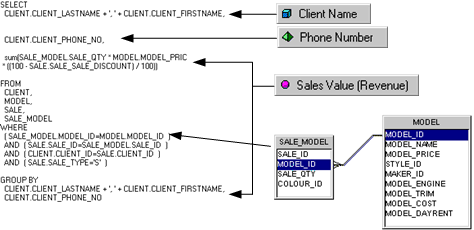
クエリの生成
20年以上前のUIなのでレガシーな雰囲気ですが、このような概念に触れていたことで、私自身はLookerが出た時に、(偉そうにも)それほど大きな衝撃を受ける事なく、BOと同じ仕組みがあるけど、よりエンジニア寄りでコーディングする感じだね。と思った記憶があります。
BOの詳細を知りたい方がいれば、こちらのGRANVALLEYさんのサイトを参照ください。
第1章:IT部門への異動とBI管理者へ(2002年)
さて、営業活動の傍ら、BIの依頼等をこなしていると、データの確認や質問を通じて、自然とIT部門と距離が近くなりました。
そんなある日、営業本部長から呼び出しがあり、「メンバー不足のIT部門へ異動して欲しい」と言われ、あんな忙しい部署に行くのか!と思いましたが、辞令には逆らえず、泣く泣くIT部門へ異動となりました。(結果的にキャリアチェンジは正解でした)
IT部門では、業務委託数人のシステム運用のリーダーとなり、システムが正常に稼働しているか、定常作業などが確実に実行されているかを監督しながら、全く分からないSQLやUnixについて、業務委託の皆さんに教えてもらったり、参考書を読んで勉強していました。
また社員が少ない事もあり、情報系システムのDBとBIシステムの管理者となり、保守運用も行う事になりました。
そしてこのBIシステムの管理者を通じて、私がいつも利用していた、あるBOのユニバースがどのような仕組みになっているのか? ということを知ることになりました。
取り組んだデータマネジメント
当時、怒涛のシステム開発期で、基幹系から新しいデータが連携されるたびにテーブル設計書を元に、ユニバースの既存オブジェクトの更新や新規登録を行いました。また一からユニバースを作成する場合は、使い方が分かるようにサンプルレポートを作成し、ユーザー部門に提供していました。
引き継いだ時点では、ユニバース内、ユニバース間でオブジェクトの名称や項目に不統一があったり、定義が異なるものも多く、それらを統一したり、より分かりやすい名称に置き換えていきました。また区分値に対する名称(1:受注済、2:入荷中など)や在庫数(入荷数-出荷数)などのカスタムオブジェクトの追加や手直しなど様々な整備を進めていきました。
ユーザー部門の立場でこういう風になっていると使いやすくなるはずという思いと生来の凝り性が合わさった結果、毎日深夜までユニバースの整理や項目名の統一などを行ったり、ドキュメントに纏めていくなかで、いつしかSQLもスラスラ書けるようになっていました。
「ユニバースをここまで整理しました!」と上長に報告しても「ふーん」ぐらいの感想しかもらえなくても、元同僚が多くいるユーザー部門から「分かりやすくなった!使いやすくなった!」と言われる事に喜びを感じて、ほぼ個人的なモチベーションで一つの作品のように作り込んでいきました。
これらの整備を通じて、BI利用は進み、加盟店向けのレポートや営業数値もBIで集計して分析するなど社員の多くがBIを使うようになりました。
当時はセマンティックレイヤーという概念を知りませんでしたが、その世界観に触れ、このようなデータ基盤の整備がデータ活用にとって重要だという原体験になりました。
またこのBIの浸透に寄与しているという事が、営業からIT部門へ異動し、エンジニアスキルに自身がない私にとって、役に立っているという一つの自信にもつながりました。
データマネジメント人材の育成の難しさ
1~2年が過ぎ、セマンティックレイヤーである、ユニバースは数十を超え、社員200人のうち、利用者が100人以上、BIレポートも100を軽く超えてきたころ、システム運用と情報系以外のシステムも担当する事になり、また後輩やメンバーが増えた事もあり、私の業務を少しずつ渡して組織化したいと考えました。
ただ恥ずかしながらこの組織化は失敗に終わりました。その理由をお話したいと思います。
まず、ユニバースの設計や名称の登録などのプロセスには、業務知識やデータ理解、分析者の視点など様々な知識や観点が必要です。またユーザーからの問い合わせについてもそのレポートの目的やデータの意味を理解しないと質問に上手く答えられません。
私自身は営業から異動したため、ユーザー部門としてBIの目的や利活用のイメージがあり、事業的な理解や用語などのドメイン知識もある程度持っていました。
一方、ジョインしたてのメンバーがそれを身に着けるには時間が掛かりますし、そもそも若手メンバーの場合、エンジニアスキルを高めたり、目の前の業務を覚えるので精いっぱいで、事業理解や他部門理解をしながら通常業務をするというのは時間的にもスキル的にも難易度が高いです。
利用者の立場でこの整備の重要性を分かっている私とは異なり、ただ担当になったメンバーとの間ではこの業務の目的の理解度やモチベーションのGAPもあり、良く分からない作業を振られても・・という感じで、実質的に私一人でやっているのと変わらない状況でした。
データマネジメントにおいて、自身が使うよりも、誰かが使うための利他的な整備業務であることも多く、このモチベーションは、ある意味ユーザーからの感謝が重要となります。
振り返ると私自身が作り上げ、リーダーとして推進していた事もあり、ユーザーからの感謝は私に伝えられる事も多い一方で、そういう機会が少なかったメンバーにとっては自己効力感の低い業務でしかありませんでした。
この原因を気付いた時には、すでにメンバーのモチベーションは冷え切っており、私自身が引き続きユニバースの管理を行い、メンバーには一部の作業補助だけをお願いする関係になってしまいました。
当時27歳ぐらいでしたが、あの時の私にアドバイスするのであれば、私が100回意義を伝えるよりも、私が引継ぎたいメンバーたちに、その感謝のシャワーを浴びる機会を作ってあげた方が、何よりもやる意義を理解でき、その業務に対するモチベーションも上がるんだよ!と伝えてあげたいと思います。
教訓
- 温度差を理解する:私自身がなぜこの業務をやりたいと思うのか、モチベーションの源泉を明文化する事が重要
- モチベーションを作り出す:ユーザーから、組織として感謝をされる機会を多く作る
- 入力基準と必要知識の整備:メタデータを入力する事は作業で、その入力するためのドメイン知識、考え方、判断基準を整備する事の方が重要。つまりリーダー自身のアウトプットがとにかく重要
第2章:開発部門への異動(2007年~)
数年が経ち、システム運用、情報系以外に基幹系システムの開発にも携わるようになり、数十名の開発メンバー(大半が業務委託)と一緒に仕事をするようになりました。
そして今までは情報系の連携された範囲の数百テーブルしか知らなかったものが、基幹系の数千テーブルの存在を知りました。
そして開発案件の度に増えていくテーブルと、それらの不統一なカラム名や説明のないテーブル設計書などに憤りを感じるようになり、またエンジニアとも話す中で、テーブル設計のばらつきで結合キーの物理名をテーブルごとを確認しないといけないなど、多くの手間がかかっている事も分かってきました。
そこで、これらに関する改善を行おうと決めました。
取り組んだデータマネジメント
まず最初に実施したのが、データ項目辞書を作る事でした。例えば店舗CDという項目も、各自がバラバラに作っていたため、STORE_NOやSTR_CD、TENPO_CDなど散在している状態でしたので、STORE_CDに統一すると取り決め、共通化しました。これはある意味ユニバースで取り組んだ項目の統一やビジネスロジックの明文化を物理層で行ったものになります。
とはいえ、すでに実装済のテーブルの変更は難しいため、テーブルのコメント情報に全て和名を入力することで和名ベースで集約できることを目的にしました。業務知識や情報系から見た世界観で設計したかったので私が中心となって実施し、分からない事はメンバーに聞いていきました。
数千テーブル×数十項目を2~3ヵ月かけて、項目名の入力→揺らぎの精査などをひたすら行い、またその過程で不要となったテーブル自体の削除やテーブル自体の命名規則も作って行きました。
またフラグや区分もテーブルを一つ一つ確認し、それらもコメントに入れていきました。
データマネジメントという概念は知らず、ほぼ体当りでしたが、こういう風に管理したいという思いで、以下のルールを決めていきました。
- テーブル作成文には必ずコメントを入れる(そのコメントを事前にチェックする)
- ワークテーブルはWK_、バックアップ_BK+日付などのルール
- フラグ(0,1)と区分(1,2,3,4,5)で名称定義を変える(業務名_FLG、_STATUSなど)
その他全部で10条ぐらいのルール
テーブルのコメントはこれもドメイン知識が必要でもあるため、項目辞書を作ることで、まずはそれを元にマッピング、新しい概念があればレビューにて決定するなど運用ルールを決めました。
今、振り返るとこれらの行為はデータカタログやデータディクショナリと呼ばれるデータマネジメントで、当時は私自身の役割のことをデータライブラリアン(データ司書) と勝手な造語で呼んでいました。
さて、このデータディクショナリを作った事については、非常に効果が大きく、業務委託メンバーが中心ゆえにバラバラになっていたテーブル設計は、統一ルールが出来た事で設計時の迷いや実装のばらつきを防げるようにもなり、これを機に様々な開発標準の取組みのきっかけとなりました。
BOのユニバースの時と同じように初期整備は私がやるものの、その時の反省を踏まえ、ドメイン知識というよりはその明文化やルール化の整備に注力としたことで、メンバーにとっても分かりやすく、設計や実装が楽になるなど直接的なメリットがありました。
結果としてルールを整備する事が生産性向上になるという成功体験となり、重要なルールは全員で議論するなど、データだけでなく、開発マネジメントにも広がっていきました。
教訓
- 具体的な価値の提示:ヒアリングを通じて納得感のある課題提起を行う
- 入力基準と必要知識の整備:項目辞書を整備することで、設計者が効率良く開発出来るようになった。その結果として、テーブル整備は進みました。ただテーブルの整備や整理をするのではなく、整備する仕掛け作りに注力することが大事
- 個人に依存しない作り:やる意義とルールが整備された事で組織的な運営が可能に
さてその後、2011年に急成長をし始めたTポイント事業へ異動となり、それまで所属していた子会社の開発からは離れる事になり、それを機に大阪から東京へ転勤となりました。
今と違い、リモート環境がない時期でしたので、ほとんどサポートは出来なくなることもあり、いくつかアドバイスやお願いはしましたが、BOのデータマネジメントは、その後、放置されるようになり、最終的に事業側の詳しい担当者にユニバースの管理を移管しましたが、問合せに応じるぐらいしか対応しない必要最低限のレベルに劣化してしまいました。
一方で基幹系のデータマネジメントは一定の品質で継続されていたようで、組織作りをする事が持続可能なデータマネジメントを生むという二つの対比事例として、苦い経験と共に私の中に深く刻まれました。
第3章:Tポイント分析基盤(2015年~)
Tポイントに異動してからしばらくは提携企業とのポイント連携などに従事していましたが、分析基盤の逼迫と共にその担当をする事になりました。
この分析基盤の取組みについては以下の記事にて詳しく書かせていただいています。
それと並行した取組みとして、データカタログの整備を行おうと考えました。
Tポイントの分析基盤は基幹システムのポイントデータや会員システムの匿名加工会員データ、多数のポイントアライアンスから連携されるID-POSデータや店舗マスタ、商品マスタなどを統合的に管理していました。それらは基幹系の設計書や、インタフェース仕様書などを元にしたメタ情報そのものは充実していましたが、EXCELやPDFなどに散在しており、これらの統合が必要な状況でした。
2015年頃からリクルートさんのメタデータ管理(METALOOKING)の事例が先進的な事例として知られるようになり、以前の子会社でやったようなデータディクショナリを昇華し、マネジメントシステムで運用するのが良いと考えようと思いました。
取り組んだデータマネジメント
メタデータ管理へ取り組むに辺り、悩みがありました。機能イメージややるべきアクションは分かっていましたが、当時はエンジニアが少なく、内製で作るのは難易度が高い状況でした。
そのため外部ツールを活用する事にしました。その調査の中で、Lookerを知るようになり、それと合わせてセマンティックレイヤーの概念を知る事となり、昔BOで使ったユニバースがまさにそれだったのだと知る事となりました。ただLookerは当時GCP専用ツールに近く、採用には至りませんでした。
なかなか良い製品がなく、最終的にInfomatica社のデータカタログツールを導入し、時流に合わせ、データディクショナリからメタデータと呼び方を変え、メタデータの充実を進めていきました。
今回の取組みでは、同じ課題感を持つアナリストメンバーがいたこともあり、私自身は同じ目線で一緒にやる相手がいる事の心強さ、一人で進める事のリスクも前職で痛いほど分かっていましたので、非常に嬉しく業務に取り組んでいました。
彼を中心に分散したドキュメントの情報の整理とメタデータへの統合・拡充は進んでいきましたが、この製品自体は思っていた以上に品質や操作性が良くなく、利用率が上がらず、費用が高い事もネックとなっていました。
ちょうどエンジニアが増えたこともあり、ローコードツールにより内製化を決断し、メタデータ情報を内製ツールに移管しました。この頃から利用者も徐々に増えてきましたが、一方でメタデータカタログ画面を見ながら、別のBIやSQLインタフェースでデータ抽出を行うというのはあまり効率が良くなく、やはり利用は限定的に留まりました。
そのような課題感がある中、Snowflakeへの分析基盤の統合が完了したこともあり、かつてOracleのテーブル定義でデータディクショナリを運用していたことを元に、Snowflakeのテーブル定義にメタデータ管理を移行する事にしました。Snowsightにユニバーサル検索が実装され、メタ情報の検索や確認もそのUIにまとめる事で使い勝手も良くなるのでは?と思った次第です。
このようなツールの変遷はありつつも、Tポイントの分析基盤メンバーはテーブルの追加を検知や設計変更などを元にメタデータの更新作業を行ってくれました。
メタデータの整備を維持し続けてくれたことで、ツールが変更になろうとも、そのツールで管理していたメタデータを抽出し、次のツールやSnowflakeへ変換し、移行を完了し、業務を継続してくれていました。
最終的にSnowsight上でメタデータを見つつ、そのままSQLが書ける環境が出来たことで、SQL体験が向上しました。またアナリストはメタデータを探索することでSnowflake上で自己完結するようになり、エンジニアの問い合わせも減り、私も徐々に現場を離れたこともあり、テーブル等で分からない事が増えてきましたが、Snowflake内でメタ情報を検索することで自己完結できるようになりました。
メタデータ管理の変遷
| 年度 | 取り組み | 課題 |
|---|---|---|
| 2021 | Informatica導入 | コスト高でUIが使いづらく、低利用率 |
| 2023 | 内製カタログ構築 | 内製化でコスト減も、カタログとクエリ画面の2画面は利用伸び悩み |
| 2025 | Snowflakeをデータディクショナリ化 | ユニバーサル検索などノンストップでデータ探索 |
教訓
- 継続し続ける事の重要性:ツールの変遷は手段の変更であり、継続してメンテし続けたことが重要
- 組織的体制の構築:組織の運用として定着したことで一定の品質で運用
- カタログ充実による問合せ削減:自己完結化が進み、エンジニアへの問い合わせも減少
メタデータの充実により、項目レベルの問い合わせは減りましたが、一方で「こういう分析を行うにはどうしたらよいか?」「このテーブルを組み合わせるとこの分析は出来ますか?」などたくさんのテーブルの中から目的に合わせて、テーブル群とどのように組み合わせるのか、それらの利用方法の問い合わせが目立つようになりました。
そして、ビジネス情報のとりまとめや目的別にまとまったデータセットの提供の必要性、すなわちセマンティックレイヤーの整備の必要性を再び考えるようになりました。
第4章:AI時代におけるセマンティックレイヤーの充実
AI時代においてデータマネジメントは重要です。そのような前提においてメタデータを管理しており、Snowflakeのユニバーサル検索でデータ探索をする事は可能となりましたが、生成AIとメタデータだけでは生成AIのアウトプットの品質は安定しません。
特に売上の定義や区分値の取得などは、メタデータだけでは揺らぎが大きく、生成AI任せでは精度が担保が難しい事も分かってきました。
その精度を上げるためには、予め定義されたデータ群、それらに対するビジネスロジックの定義、それらを内包したセマンティックレイヤーが生成AIの精度を大きく左右すると考えられています。
現在、データ関連の生成AIの多くでは、セマンティックモデルが採用され、YAML形式で、ジョインキーの定義や、売上の計算定義や分かりやすい表現などが設定され、それらを元にモデルを作り、AIの回答精度を大きく引き上げる事が出来ます。
あの頃、BOのユニバースを用いて、BIユーザーが利用しやすいように、目的の範囲で必要なテーブルだけを登録して結合キーを定義し、売上を定義したカスタムオブジェクトを定義したり、名称を統一するなど営みの本質は変わらないなと感じています。
(BOのユニバース経験者からすると感覚的に理解出来る、あのGUIが欲しいなと思います)
そして生成AIの、特にAIエージェントについては、このような5層構造になっていくと考えています。
- AI向けのデータセット(BIに向けたGold層からAIに向けたGold層を新たに整備)
- 目的別の多数のセマンティックモデル
- それを利用する機能別AIエージェント
- それを取りまとめる調整役AIエージェント
- 最終的なユーザーインタフェース
このような中で、1,2のデータの整備は最終的なAIの精度や成否を大きく左右します。AIの時代と言われ、データエンジニアの存在が相対的に下がるような見方もありますが、むしろ今まで以上にデータマネジメントやデータエンジニアリングの重要性は増していくと考えています。
3以降のAIエージェント機能は各データプラットフォーマーは提供し始めています。そして1~5が垂直に出来るような高い開発生産性を持つ機能群の各社が積極的にリリースしている状況です。それらにより開発自体はしやすくなる一方で、1,2のデータ品質がAIプロジェクトを確実に左右するようになります。
それはある意味、自らのデータマネジメントレベルを客観的に評価される機会となります。
このような生成AIの波の中で、多くの企業が自社のデータマネジメントの更なるレベルアップを図る事になり、データマネジメント組織の重要性もさらに上がるため、我々も現状に甘んじる事なく、より強化をしていくべきだと考えています。
第5章:データマネジメント組織についての私見
データマネジメントの組織運営については、様々な議論がされています。そのような中で私見を述べるのはなかなか勇気が要りますが、私自身は中央集権が良いという思いが非常に強かったです。
これは自身の成功体験から来るものであるのは間違いないのですが、ではなぜ中央集権型だと上手くいったと思うのかについて上手く説明出来ない事があり、その理由を突き詰めようと思いました。
それがこの記事を書こうと思ったきっかけとなり、その結論としては私自身のキャリアによると考えています。
- 営業からIT部門へ異動、BIユーザー→BI管理者→情報系→基幹系→分析基盤責任者→IT責任者
このような様々な職種やスキルを跨いだキャリアを通じた結果として、(とても偉そうな表現かもしれませんが、)私自身がクロスファンクショナルな人材になっていたと考えています。
そのため、無意識を含め、複眼的な視点や観点を持つ傾向があり、その複数のキャリアを通じた事業や業務に関するドメイン知識の範囲や深さにより、中央集権的な意思決定による一定精度以上のスピーディな推進がその成功体験の源泉ではないかと考えられます。
一方で自身のキャリアの否定になりますが、私のようなクロスファンクショナルな人材に依存するのは成果の早期化では有効かもしれませんが、組織として持続性は低くなるリスクが上がります。
なぜなら事業が一定規模を超えると必ず分業制となり、キャリアやスキル、ドメイン知識を複数持つ人材は減っていきます。私のような経歴はイレギュラーな存在であり、組織の持続性においては分業制における明確な役割とロールによって、どのように協創して運用するかが重要と考えています。
アフリカの諺である、”早く行きたければ一人で行け、遠くへ行きたければみんなで行け”
この有名な言葉を元に改めて、持続可能なデータマネジメント組織を考えると中央集権ではなく、それぞれの領域を分担し、相互に連携した緩やかな統治を目指したデータマネジメント組織が理想的と考えています。
つまり個人にクロスファンクショナルなスキルや経験を求めるのではなく、組織でクロスファンクショナルな動きが出来るような協創体制を目指すべきと考えています。
また、そのような中で私のような存在をどのような位置づけにするか?も考えるようになりました。
これからは私自身の経験と私見に基づく意見になりますが、それはやはり文化を残すことだと思っています。一時の流行ではなく、永続的な文化、その分かれ目に来ているなと感じています。
私がかつてBO時代にメンバーへ伝えられなかったビジネス知識やドメイン知識を文書化。基幹開発時代にメンバーとやったデータディクショナリの運用、ポイント分析基盤でやったデータカタログ。それぞれの成功や反省の体験を抽象化し、組織として再現できるようにしていくことだと考えています。
ではそれにはどのようなものを残すべきか、今思う要素をまとめてみました。
1. データマネジメントの継続的な向上や維持のための取組み
- データマネジメントやデータリテラシーを上げる研修
- データマネジメントそのものの手法でなく、その意義や今の成果の可視化
- データ基盤の歴史やその変遷を理解し、今どうつないでいくのかを考える機会
- 可視化された成果以外も含め、それを運営してくれているメンバーへの適切な賞賛の機会
いずれにせよ、メンバー自身がモチベーションを持ち、自走してくれることが重要で、それを1人ではなく、複数のメンバーで進むことが重要です。
そしてこれに限らずですが、リモート中心の現代において定期的な交流や勉強会、成果報告などお互いをリスペクトする関係作りや機会の創出が何よりも大切だと考えています。
2. 目的と役割の明文化
- なぜやるのかなぜ必要なのかの共通認識を持つための鑑を作る
- クロスファンクショナルな責任者に依存しない、組織としてのドメイン知識と技術理解の整備
- 各部門の役割や権限、責務に関する合意事項(これはもしかすると組織規程かもしれません)
上記の組織役割に参加する人は、傍観者や利用者ではなく、合議し、決定する責任者の一人としての意識を持ってもらう事が重要だと考えています。
3. クロスファンクショナルな組織運営とその成長を促す適切なストレッチ
- アナリスト、データエンジニア、データサイエンティスト、AIエンジニア、ビジネスユーザーの合議制(間接的な関係者も当事者に)
- 上記2つに加え、そのモニタリングの客観的評価やより上を目指すための視点や観点
- それらを明文化するADRの追加や更新プロセス
- 特にAI領域やビジネス活用の部門は、意見や要望だけでなく、成果に対するコミットや共有が重要です
感覚的には各部門2名の10名ぐらいが良いかもしれません。1名に部門のすべての判断を委ねるよりも部門ごとに複数の視点を持つ事が必要です。そしてこのデータマネジメント組織が他の業務とのバランスを取りながら、より高度化し、適切に運営していくための半期に1度ぐらいのアドバイスや促しぐらいが私の仕事かもしれません。常時参加すると毎回意見言っちゃいそうなので・・
世の多くのデータマネジメントは最初から計画されて立ち上がる事は少なく、事業の成長や業務の増加と共に一部メンバーの想いから始まるのではないかと思います。またしっかりとした準備や計画に基づき、データマネジメントの持続的な運営を成功させた組織もあると思います。
私自身は先頭を切って、中央集権スタイルでやっていく事が多かったですが、この約25年のいくつかの経験を踏まえ、どのように、緩やかな統治としてデータマネジメントを持続的な運営にし、かつレベルアップさせていくのか?未だ模索をする日々ですが、今見えている景色から上記3つを一つずつやっていく事が一つの答えになるのではないかと考えています。
エピローグ:25年間の技術進化と不変の本質
2000年から約25年、ツールも手法も大きく変わりました。しかし、データ活用において重要な要素の一つとしての 「ビジネスとデータをつなぐ共通語彙の構築」 という目的は変わらないと感じています。
私が偶然出会ったBOのユニバースを通じて触れていたセマンティックレイヤーという概念は、今やデータマネジメントにおけるデータ×AI活用のキーファクターという共通認識になってきました。
あの時のユニバースの整備を通じて得た、データ活用をドライブさせているという達成感や効力感を、生成AI時代のセマンティックレイヤーの整備を通じて、私だけではなく、次の世代や仲間たちと、より大きな達成感と効力感を得られるようにサポートしていきたいと考えています。
私自身は同じCCCグループの中で、キャリアチェンジやステップアップ、事業チェンジなどを経験し、ある意味ゼネラリストとしての経験が多く、エンジニアとしては今もなお引け目を感じる事が多かったです。
一方で、それぞれの職種や役割をまたいだ経験があるからこそ、どのように共通言語化するのか、同じ課題感を持つのか、そのための最初の一歩を踏み出すということの経験は多く積んだような気がしています。
それゆえの苦労がある一方で、それを成しえた時に自己効力感もより多く感じることが出来ました。それは逆に一人で突っ走ることにもつながるため、自分の役職と共にこれを組織としての再現性かつ持続性に移行するための模索を始めています。
個人から組織へとこの取組みが変わっていく中で、引き継ぐメンバー達ともこの 「ビジネスとデータをつなぐ共通語彙の構築」 そのものをお互いの共通言語化していくことにチャレンジしていきたいと思います。
経験こそが人間の本質
生成AIによって一般的な、標準的な概念や考察は簡単に手に入るようになり、多くの問いには確からしい答えを得られるようになりました。
一方で人間の営みは多くの矛盾をはらみ、教科書通りに行かない事も多々あります。
そのような不確かな人間の営みの中で、成功も失敗も含め、本人が経験したことは、その時、その場所でその人だけが得た、AIには導けない独自の知的資産です。
この記事は、何か標準的なフレームワークを再現したものでも、独自のアイデアを創出するものでもなく、ただただ私の約25年に渡る、それぞれの時期にデータと向き合い、取り組んだことの経験をまとめ、その振り返りを元に今後それをどうしていきたいと思っているのか?という私見をまとめたものになります。
もしかすると何かの理論と全く逆の意見を述べていたり、どなたかの取組みや考え方と大きく異なるものもあるかもしれませんが、その矛盾や違いも含め、読んでいただいた皆様の何等かの参考になれば幸いです。
失敗も成功もまたその悩みもその人だけの財産であり、その経験とそこから生まれる問いだけが人間らしさの証明だと思いますし、私の経験と悩みや問いもまたその一つだと思います。
このような財産を人間同士がシェアしていくことが、AIには出来ない、人間だけの営みだと考えています。
データに限らず、同じような悩み、違う悩みをお持ちの方がいれば、是非どこかで人間らしくお互いの経験したことや悩みを語り合いましょう!
Discussion