Tポイント分析基盤の歴史とSnowflakeへ移行した話①
記事の目的
レガシーが多いシステムをモダンアーキテクチャに移管するのは非常に労力を伴いますが、どのように移行したかの具体事例や、特に途中の労苦を語ったものは少なく、皆様の参考になればと思い、恥ずかしい話もありますが勇気をもって投稿します!
TポイントからVポイントへ2024/4/22にブランド名が変わってますが、
当時の話なので、Tポイントで記載しています
分析基盤の歴史
私がTポイント事業にジョインしたのが2011年でその後の歴史を1枚絵にしたのが下の年表です。
現在、分析基盤はほぼSnowflake化されており、
徐々にモダンデータスタックには近づいてきたかな?と思っております。
早くSnowflakeの話しろよ!と思う人が多いかと思いますが
この基盤のコンセプトに関わる話なので、ご容赦ください(汗)
snowflakeの話だけ聞きたい方は②からどうぞ🙇
■分析基盤の歴史
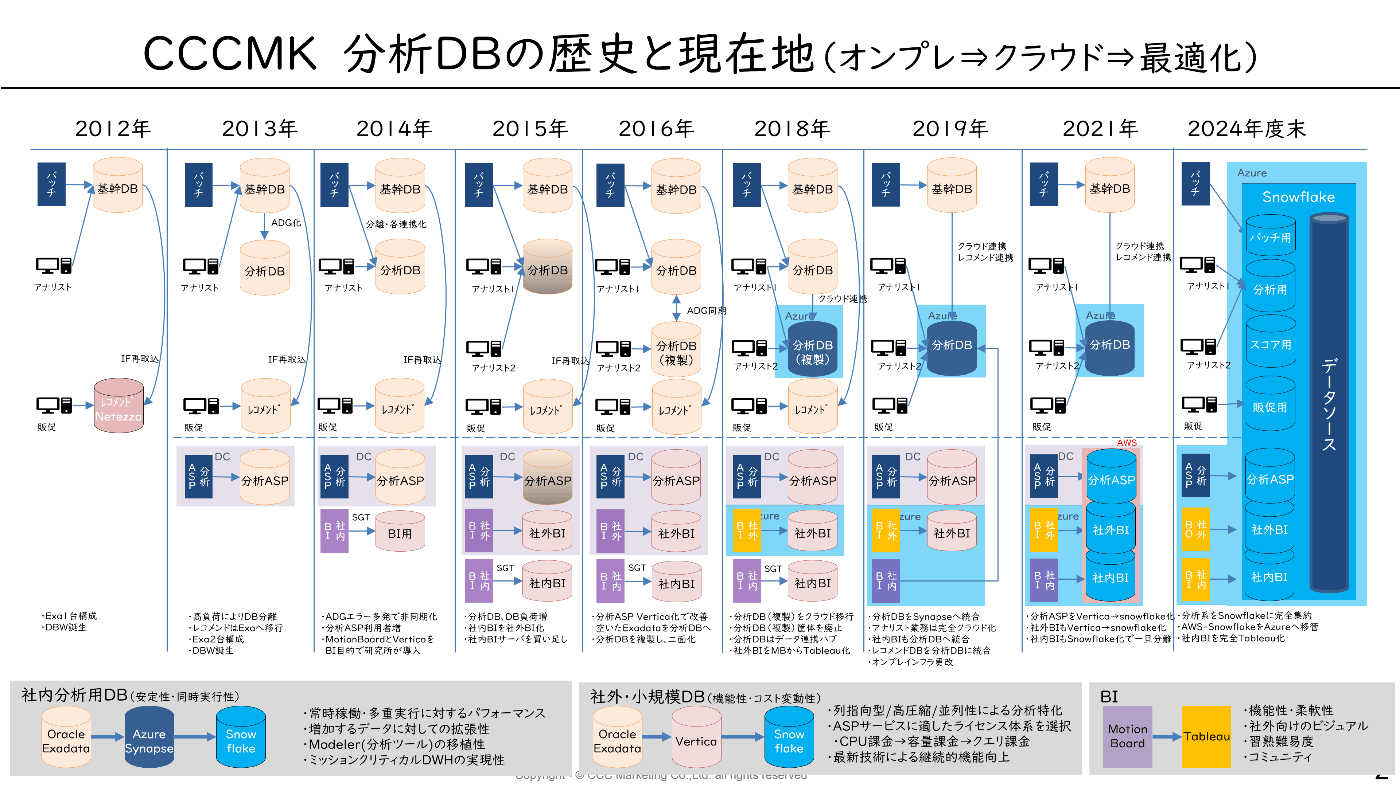
現在の状況(Snowflake完全統合に向けて最終工事中)
当時の私
さて、Tポイント事業にジョインした当時の私は、
”Tポイント提携先企業とのポイント導入担当”という、導入PJのプロジェクトマネジメント 兼 セールスエンジニア的な職種で、
我々が発注主でもなく、逆に下請けでもない関係性の中で、提携先企業のシステム部門、POSベンダー、本部ベンダーと協力して、提携先側のTポイント連携機能のシステム開発をしてもらうという、世の中でもなかなかない珍しい仕事で、とても楽しく面白かったのですが、とりあえずその話は横に置いときます(笑)
で、その業務を3年ぐらい担当した後、2014頃に分析基盤などのバックエンドを見て欲しいと言われ、
門外漢ながら分析基盤や販促系のシステムを担当する事になりました。
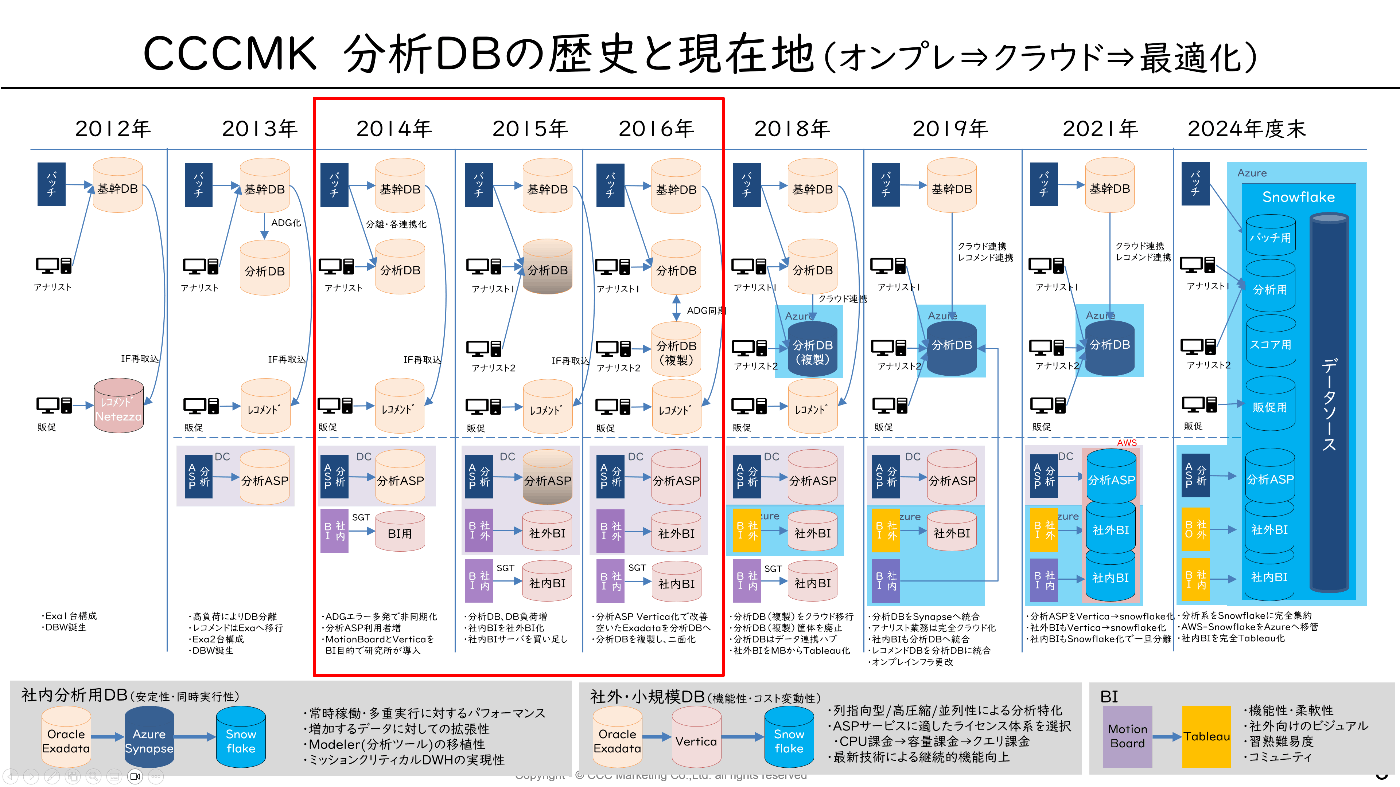
暗黒オンプレ時代(2014年‐2016年)
表題からして、既に終わってるの丸わかりですが、
ジョインしてしばらくすると激烈にヤバい状態だと認識しました。
分析DBの状態
・Tポイント会員は毎年10%以上増加する=ユーザー爆増
・提携先が毎年数十社増える=トラン爆増
・アナリストも毎年増員=クエリ数爆増
・分析するアウトプットも年々高度化、複雑化=クエリ負荷爆増
ユーザー↗×トラン↗×クエリ数↗×クエリ負荷↗ = 爆発(DB落ちる度にアナリスト部門よりお叱り)
社外に公開している分析ASP(DBW)の状態
こちらも分析基盤と同様
・Tポイント会員は毎年10%以上増加する=会員レコード数爆増
・提携企業数や各社の取引件数が増加=データ量爆増
・分析ASPの利用企業や利用者も毎年倍増=クエリ数増
・検索する条件が高度化、複雑化=クエリ負荷増
データ量↗×クエリ数↗×クエリ負荷↗ = ほぼ爆発(分析が終わらず、クライアントからお叱り多発)
といった状態で、ダブルで詰んでる状態。。
業務にならないアナリスト部門や顧客離脱の懸念がある分析ASPの事業部門との関係値も最悪というところも含めて、どうにかして欲しいという意図での異動だったと気付きました。
どうするよ、これ?
とりあえず、重たいクエリをKillしたり、
ヘビークエリユーザー(をテロリストと呼称)にはDBスペシャリストが個別にクエリ指導したり、チューニングしてあげたり、ひとまず出来る事をしましたが、当然のごとく、焼石に水。
よーし、無理!と言いたいけれど、他に見る人もおらず、解決策を改めて考える事に。
当時は、オンプレのデータセンターでアプライアンス製品のOracleExadataで基盤を構築していたため、
インフラ拡張が出来ず、既存インフラの範囲でやれることはかなり限られていました。
また、そもそもOLTPルーツのデータベース製品での分析基盤にも限界だはないかと感じていましたが、インフラはホールディングスで一括調達している事もあり、個別最適・個別調達が難しく、なかなか動きづらい状態でした。
Verticaとの出会い
そんな中、社内の研究所(テックラボ)で導入したBIツールのベンダーから、Verticaを紹介してもらいました。
この手の事業部門からの紹介は、外れも多いのですが、
そういう先入観が視野を狭くする事もあるので、極力話を聞くようにしています。
最初は正直懐疑的な雰囲気で話を聞いていたのですが、
列指向型、高圧縮、超並列処理(MPP)の、Verticaのアーキテクチャは、当時としてはかなり先進的で分析用途に非常に特化していると感じました。
またライセンス体系がCPU課金であるOracleに比べ、データ容量課金というところも
分析ASPという”一定のデータセットを多くのユーザーに利用してもらうサービス”との相性が良いと考え、Verticaの導入が一つの解決策になると考えて、社内説得に動き出しました。
当時、グループ全体で共通インフラ基盤が事業部門に提供されているため、
個別の基盤を調達したい!というのは、なかなかネガティブな反応もありましたが、
・事業に迷惑をかけるだけではなく、分析業務が出来ないのは事業継続の危機であること
・OracleExadata自体を否定しないが、分析に特化したアーキテクチャではないこと
を伝え、また当時のCIOがベンチャー出身の方に変わったタイミングであったこともあり、新しい技術へのチャレンジを認めてもらうことが出来ました。(タイミング超大事)
まずはPoCの許可をもらい、その成果を以って最終判断となりましたが、
既存インフラの償却期間も後3年ぐらい残っており、二重コストは極力避けるべく、
全体として以下の構成を目標としました。
1.分析ASPのOracleExadataをVerticaへ移行する
2.分析ASPで利用していたOracleExcadataを分析DBへ転用する
OracleExadataをActiveDatagGardで2台構成にして、ユーザーを分割し、負荷分散させる
これなら既存のexadataを最大限活用しつつ、Verticaの導入コストの追加コストのみがP/Lインパクトとなり、売上が伸びている分析ASPの原価として吸収可能と判断しました。
分析ASPサービス(DBW)のVertica移行
上記の段取りを付けて、実際のPoCを開始する事になりましたが、
さすがにこの時点でハードウェアを調達するのは難しく、HP社の技術センターを借りて環境構築を行い、分析ASPのベンダーと性能評価や移植性の評価を実施しました。
様々な検証を行った結果、各分析メニューで7倍以上の性能向上が出来ると評価
また並列処理ではそれ以上の結果が出ていました。
上記で性能面では充分採用可能であったため、コスト試算も並行で進めました。
当時ASPのデータ容量は10TBほどで、これを元にライセンスやインフラスペックを選定し、コスト試算を行い、コスト面でもExadataを追加購入する事に比べれば、はるかに安価に構築できると判断しました。
この成果を元にITの投資精査会へ掛ける事になりました。
事業課題化していた性能問題について、技術で解決が可能であること、またインフラ全体のP/Lコストの影響なども許容内と判断し、CIOへの事前報告やIT基盤への協力依頼など多方面で調整の上、社内承認を取る事が出来ました。
PoCで実施していることもあり、サーバの発注などの物理的な時間が一番かかりましたが、
約8ヵ月で開発完了。
リリース直前でLinuxのバグ踏んで断腸の思いでリリース延期するなどアクシデントもありましたが、
最終的に無事リリース完了。
リリースは週末に実施し、社内で動作検証や性能確認を行い、問題なし。
週明けからが実際の本番稼働という流れで、やれることはやったという自信はありつつも実際のユーザー利用のパフォーマンスを見るまでは不安でしょうがなかったです。
週明け朝から稼働監視を行い、性能の速報は良好。
最終的な性能評価は、単純性能では7倍でしたが、同時実行性能としては前週までのExadataとの比較して実に21倍高速化されました。
移行後はクレームが全くなくなり、「めちゃくちゃ速くなったね!」とクライアントより事業部門が褒められて、事業責任者からも感謝されました。
また性能課題もあり、消極的になっていた新規契約も積極的に推進。
その後当時の企業数の何倍も利用するようになりましたが問題なく稼働出来、
かつインフラコストは削減と事業収益面でも大きな効果がありました。
分析ASPのVertica化で空いたExadataを分析DBに転用
さて、Vertica移行により空いたExadataですが、
こちらはCPUの増設などを行い、2台のExadataのスペックを揃えた上で、ActiveDataGardでの同期構成に変更
アナリストの業務部門単位で接続先を分散させることで、実質2倍に強化し、
システムダウンは発生しなくなり、レスポンスも一定レベル改善されるようになりました。
結果
・社外向けはVertica導入で性能改善し、クレーム解消+利用ユーザーもさらに増加
・分析基盤はOracleExadata 2台化で負荷半減により、分析業務も安定化(落ちない!)
またこのような取組みを通じて、各部門との関係性も改善されていき、
何か困った事があれば、僕に相談すれば良いといった認知をされるように。
とはいえ、オンプレではこれ以上の拡張は困難なため、2016年より次期基盤の検討を開始する事になりました
そして、気が付いたら分析基盤の責任者に(アレ?)。
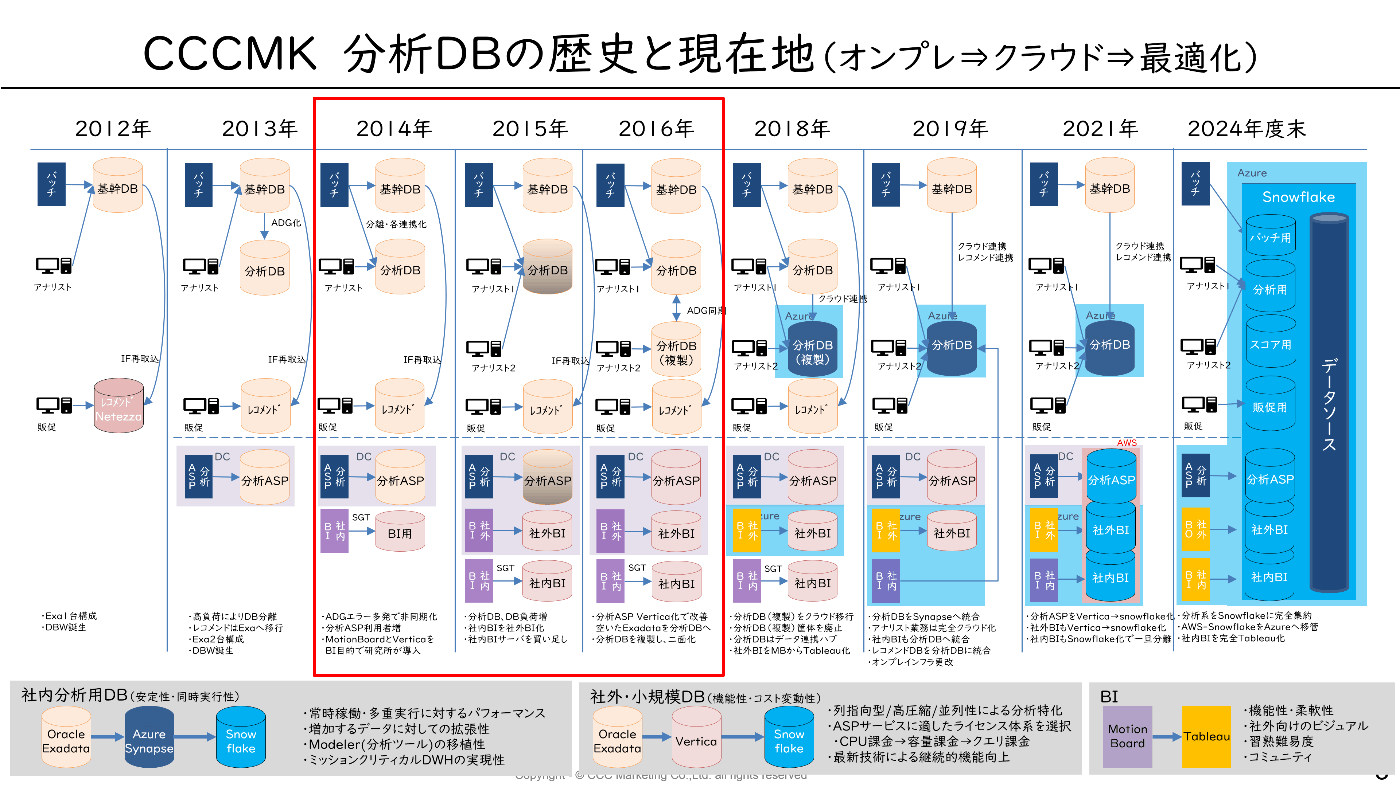
次期基盤に向けたクラウド導入の検討
EOLと迫りくるタイムリミット
現行OracleExadataのEOLが2019年のため、Exadataの最新バージョン機に入れ替えをする選択肢もありました。
ただ事業成長の基盤としてDWHの役割が一層高まる中で、現時点でも性能課題があるExadataの単純リプレイスは最新ハードによる高速化の可能性はありつつも、コストもさらに増加
またVarticaを通じて、分析に特化したアーキテクチャを選んでいく事が今後の事業成長に重要と考えていました。
一方で、2019年に迎えるExadataのEOLを考えると2018年には移管を完了しないといけない。
そのため、2017年には移行先を決め、開発に着手する必要がある。
つまり、2016年は、どのようなアーキテクチャにしていくべきか、既に様々な意思決定に向けて動き出すべきタイミングでした。
やっべ、全然余裕ないじゃん。
Verticaの評価
Verticaをさらに拡張する事も考えましたが、ハードウェアの調達など都度の構築作業があること、アナリスト部門で利用している統計分析ツールSPSS Modelerへの正式対応がなかなかされず、採択しづらい状況でした。
HP Vertica時代は、ソフト+ハードの一体販売かつ、弊社がアーリーアダプターで採用したこともあり、お値段などもかなり格安だったのですが、その後HPからMicroForcusに買収されたことや改めてのライセンス購入となると割高になることもあり、見送らざるを得ませんでした。
※今でもVerticaは良い製品だったのに惜しいなと思っています。
こうなるとクラウド上のDWHサービスの検討が現実的になってきました。
クラウド恐怖症
2016年当時、「クラウドって、なんか心配!!」というのが世の中の感覚で、
弊社も同様の状態でした。
法務・コンプラ、セキュリティ各方面からクラウド検討の相談もまずは門前払いをされ、
ホールディングスのIT基盤部門からも、「また個別基盤作ろうとしてるのか?」と言われ、
なかなかに詰んでる状態で頭を抱えていました。
各部門の懸念や課題は自分だけでは解決出来ない事が多く、導入検討対象のAmazon社とMicrosoft社にそれぞれ協力要請をしたところ、Micorsoft社がサポートや導入支援を手厚く実施してくれて、社内各部門の理解を後押ししてくれました。
クラウド恐怖症の払拭
当時は、クラウドに個人情報などを預ける事自体が法的にグレーな状態だったので、
まずは法務部門がしっかりクリアする事が重要と判断し、
かつ実際にクラウドにデータを預ける事における技術的な確認という2段階でクリアしていこうという事でそれぞれの部門に対し、アプローチを計画しました。
・リーガルセッションの実施
クラウドのセキュリティ規定や情報の取り扱いなどを明確にするためにMSと弊社法務部門で実施
かなり深くまで議論を行い、法務部門のクラウド理解が進み、これによりリーガル面を概ねクリア
・AzureDC見学ツアーの実施
コンプラ、セキュリティ、IT基盤部門としては、クラウドのセキュリティそのものをしっかりと確認したいという移行が強く、Microsoftがクラウドデータセンターの極秘ツアーを企画してもらいました。
メンバー一同、MS本社からバスに乗り、関東データセンターを訪問
詳細はしゃべっちゃダメなので内緒ですが、とあるデータセンター内にAzureの区画があり、
その中外で個別のセキュリティ強化策を実施している事など、様々な説明を受け、
データセンターのセキュリティや運用、コンプライアンスの徹底度合いに参加者一同は感銘
ツアー後に、とある本部長から「タロウくん、これはOK出していいよね?」と言ってもらいました。
これを機に、”理解出来た”、”安心出来るもの”になり、
各部門いずれもゆくゆくはクラウドも対応しなければと考えてはいたものの、得たいの知れないもの、リスクがあるのでは? という状態でありましたが、その後改めて協力をお願いしていく中で、社内はだんだんとクラウドに前向きな雰囲気へ変わっていきました。
またプロジェクトの方針も、子会社の我々が個別にクラウドを導入するのではなく、CCCグループとしてクラウドに対応しましょう。そのための最初の人柱は僕らがやります!という形で
ホールディングスの共通インフラ基盤にクラウドを追加するという位置付けにしたことで
いずれ対応しないといけないクラウドに対し、ホールディングスとしてもチャレンジできる良い機会という雰囲気になり、ホールディングスのIT基盤の協力も得られるようになってきました。
クラウドセキュリティ規定の策定
情報セキュリティ規定についても、クラウドを安全に使うためのクラウド規定を追加する事になり、IT基盤の有志とクラウド規定案を一緒に作成を開始しました。
さすがに一から作るのはツラすぎるので、ドコモ・クラウドパッケージのガイドラインを購入し、それをベースに有志で議論して規定案を作成し、ホールディングスのIT基盤部がまとめた規定案としてセキュリティ部門へ上程。
何度かの修正を経て正式なクラウド規定として、扱ってよい情報やルールなどが決まり、
上記と並行して、その実現性を証明するためのクラウドPoCを実施する事を決定してもらいました。
この辺りきっかけを作ったあとは、みんなが積極的に協力してくれて、スピーディに色々な意思決定が出来て行ったので、協力いただいた皆様には今でも感謝です。
クラウドPoCの実施
2017年頭にRedshiftとAzure Synapse Analytics(当時はAzure SQL DataWarehouse)で比較検討を開始しました。
MSに協力してもらっていた背景がありつつも、Redshiftが本命での心積もりでした。
が、しかし、当時のRedshiftではいくつか課題があり、最終的に要件を満たせたSynapseを採用する事に至りました。
この辺り、双方のPoCをやりつつ、どちらにするか自分自身でも揺れ動いていたので、
上司には、「タロウくんは浮気者だね」と言われました。。笑
①同時実行性能の差
・Redshiftは15多重ぐらいが限界(クラスター増やしたり、レプリすれば〇だけど、コスト合わん)
・Synapseは60多重ぐらいまで可能
当時Exadataでの実績としては、数十多重が当たり前という状態で多重度は重要な要素でした。
②クエリ性能
・単純な性能はDWHいずれもほぼ同等でした。
・一方で、アナリストが利用していた統計分析ツール(SPSS Modeler)で自動生成されるクエリについて、Redshiftはどうやっても速度が出ず、これには頭を抱えました。
生成されるクエリの癖か、当時のオプティマイザの精度の差なのか不明
上記の①がノックアウト条件の一つで、②で決定的となり、Synapseを採用する事を決断。
最終的に上司にも「Azureで行く」と宣言し、了承をもらいました。
後はコスト面ではまだまだ値段的には高い事や、Redshift側のノックアウトはありつつも、今後の機能アップデートで解消する可能性もある事も踏まえ、Microsoftとはかなりコスト交渉を実施
最終的に
性能 〇:現行DBよりもクエリ性能は向上
移植性 〇:Oracleからの互換性があり、非互換パターンも修正にて対応可能な範囲
コスト 〇:現行DBよりもコスト削減が可能
という状態で評価を完了する事が出来ました。
このDWH選定と並行して、策定済のクラウドセキュリティ規定に基づいた構築が行えるかの検証も基盤チームを中心にクリアし、最終的な価格交渉も踏まえ、Azureの採用およびSynapseへの移管をホールディングスのIT含め決議されました。
※2017年当時のRedshiftの評価です。その後様々なアップデートで解消されていると思います
ちなみにこの翌年にAWSも基盤として採用可能と承認されており、弊社も利用しています。
クラウド移行
分析系に含まれるDBは多数あるため、2019年に向けては分析DB2台の移管とレコメンドDBの移管を候補とし、性能課題が待ったなしの分析DBのクラウド移行から着手
基幹DBはOracleのPL/SQLやらシェルスクリプト、Perlとか色々レガシー抱え過ぎている一方、
チューニングも実施していたこともあり、今回のタイミングではDB更改はせず、Exadataのまま単コンを判断
分析DB正副のSynapseへの統合を視野にしつつ、まずは分析DB(副)を移行し、そこに分析DB(正)も統合することでExadata 2台をSynapse 1インスタンスにする事でインフラ・運用コスト削減をPhase1
その後にレコメンドDBのExadataも統合、それに合わせてSynapseも順次拡張というPhase2として最終的な計画を確定させました。
プロジェクト内容はクラウド全般の環境構築に加え、
システム開発としてExadataから日次でSynapseへ連携するパイプライン群を作成し、DC→Azure間は専用線、SFTPでファイル連携し、Synapse側でロードするというシンプルだけど膨大な数のパイプライン作成を行いました。
クラウド同士の移行だとストレージをデータレイクにしているので、ほとんど課題にならないですが、
オンプレ→クラウドはどうしても手間がかかる(悲)
そんな中、順調に環境構築や開発工程は完了し、データ移行や日次連携も開始
2017年秋から半年ほどの並行期間で、2018年春までにアナリストのストリーム移行を完了する予定でした。
が・・ここから大きく躓き、結果として約2年かかりました。
性能課題の勃発
発生した性能問題
①クエリ性能が思ったよりも出ず、全体的にDBが重い状態に。
②上記により、クエリ滞留により同時実行数の上限を超え、待ちが発生
③結果としてExadataよりも遅い事態に。
原因
これは今振り返っても反省しかないですが、単純にPoCでの評価不足でした。
弊社の分析は主に会員軸の分析と企業軸の分析に分かれます。
会員軸は会員をベースに各企業やサービスを横断した分析のため、広範囲なデータ量を取り扱い、ペルソナなど俯瞰的な分析を行います
企業軸は企業内のCRM分析や店舗軸での分析のため、データ範囲は狭く、商品や店舗単位での詳細な分析を行います
Synapseのアーキテクチャとして、分散キーにより、データを60分割してストレージ配置する仕組みがあります。分散キーが揃っていると同一ストレージ内で集計処理が行えるため、良く使われる結合条件で分散キーを設定する事で効率良く集計が行われます。
弊社がTポイントサービスをしているため、当然のごとく分散キーは会員IDのハッシュ値で実施しています。
そのため、会員軸の分析の場合、同じストレージ内で会員の属性や履歴を会員番号で集計できるため、
非常に高速な集計が行えます。
逆にキーが異なるデータは他のストレージに取得するため、shufflemoveが発生し、性能が大幅に悪化します。
皆さんは薄々お気づきと思いますが、
PoCの際は、当時取り扱うデータ量が多い事でクエリが重く、業務にならないと頻繁に言われていた会員軸の分析を中心に実施をしていました。
またアナリスト部門が繁忙期であったこともあり、
アナリスト部門からクエリ等を受領し、それをシステム部門で性能検証をしていたこともあり、
固定的なパターンでの評価となっていた事、その間にも大手提携先を中心に企業軸分析の複雑度を一層増していた事を把握出来ておらず、結果的にパターンや負荷の評価が足りていませんでした。
動かないクラウド
会員軸の分析は単発ではPoCの通り、明らかに速かったのですが、
企業軸の分析はむしろ従来よりも劣化しており、それによるクエリ滞留からの同時実行の上限を超え、待ちが発生。
結果として会員軸の分析も芋づる式で遅くなっていました。
この見誤りは影響大きく、簡単な解決策は期待できない状態でした。
リリース延期の判断
アナリスト部門からも「業務にならない」と言われ、一方でオンプレの廃止を辞めるのであれば、Exadataを買い直すかどうかの判断時期も迫っていました。
上司や関係者にも状況の報告をするも、
「で、どうするの?オンプレに戻すの?その後はどうするの?」
と言われてもその代替案すら言えないという事で、この時期は毎日吐きそうになっていました。
目先の対応として、長時間クエリをkillしたり、個別のチューニングなどを実施しましたが、
焼石に水の状態で、お先真っ暗とはこのことかという状態でした。
ただクラウドへチャレンジした事の意義を理解して、アナリスト部門も応援してくれたり、
研究所がクラウド環境を使って、新たなライフスタイル分析を行った報告をしてくれたり、
一緒にプロジェクトをやってくれたメンバーが根気よくアナリストのサポートをしてくれていたことで、
諦めそうになる気持ちを踏みとどまり、何か解決策はないかと日々リソースやクエリ解析をしながら調査をしていました。
再チャレンジに向けて
Microsftの営業やエンジニアとはかなり深いところまで調査や支援をいただき、その中で、SynapseのGen2(ジェネレーション2)の計画とプライベートプレビューのオファーをもらいました。
Gen2の性能
本国のエンジニアからのレポートより、Gen2でインフラやアーキテクチャが大きく見直しされることで、クエリ性能が2~4倍程早くなる事が分かりました。
・内部のハードウェアのCPU自体が最新化かつスペックアップ
・またローカルSSDにデータキャッシュを格納する事でディスクI/Oが減る
今起きている性能課題の原因やこれらのアップデート情報をはめ合わせると、
性能の大幅な改善が現実的に可能となる判断し、移行の再計画を検討し始めました。
(苦しい時期だったので、ほんとにそうか?藁にもすがってないか?と自問自答しながら)
またクエリ解析を続ける中で、tempdbの利用削減に寄与するテーブルの見直し要素が見つかり、
Gen2を待たず、その対策を順次実施する事になりました。
テーブルのカラム正規化
テーブルの結合キーの文字型のばらつき(Varchar、Nvarchar、Char)があると
クエリ結合時に型を揃えるための型変換が発生し、tempdbの利用が増加する事が分かりました。
Oracleでは型変換をDBが柔軟に吸収していたが、Synapseでは厳密に判定する事でこの事象が各クエリで頻繁に発生し、それらが結果的に慢性的なクエリ遅延やDB負荷の要因となっていました。
上記を実施後、クエリ全般で一定効果がみられてきましたが、
まだ確実な解消とは言えない状況でGen2の稼働に向けた準備を進めました。
またリザーブドインスタンスの契約パターンが追加される計画も知り、
この点も考慮した上で、事業部門への負担も最小化するため、以下のステップで実施しました。
再移行計画
①会員軸分析の部門のみをSynapseの3000DWUで先行稼働し、企業軸分析はオンプレの利用に一旦戻す。確実に効果があるものだけを移行。
②Gen2へのバージョンアップ後に企業軸分析の移行を開始する。
④企業軸分析の稼働を見つつ、6000DWUへ上げる(Gen2による性能向上×リソース2倍)
マシンパワーで乗り切る
④最終的に3年リザーブドを適用し、性能UPとコストDownを両立させる
・DB性能:Gen2 2倍×DWU2倍
・コスト:DWU2倍×リザーブド33%=コスト66%
コストの適正化
長いトンネルを抜けてクラウド化の完了
18年3月:移行計画の①に基づき、確実の性能が上がっていた会員軸分析メンバー約30名を先行移行完了
18年5月:②のGen2化を実施、以降Gen2の安定稼働を監視(プレビュー段階で色々トラブるが対策前進)
またテーブルのメンテナンスによるTenmpdb負荷の軽減
18年9月:③の企業軸分析メンバー約60名の移行に合わせ、DWU6000への増強を実施
Release T43でShuffleMoveやオプティマイザが改善され、クエリ性能が全般的に向上
またSynapse化以降に開始したデータマート化のリリースによりDB負荷の削減も徐々に進行
19年6月:④リザーブド課金がリリースされ、3年リザーブド購入を行い、コスト66%オフ化
最終的に企業軸の分析もパフォーマンスは改善し、安定して稼働出来るようになりました。
またリザーブドインスタンスにより、スペックは2倍にしつつもコストは66%となり、
性能アップとコストダウンを実現と共にアナリスト部門の移行が2019年にほぼ完了
また本件の目途を立てつつ、並行してセグメント配信用のExadataの移行にも着手しており、
19年12月:セグメントDBを廃止し、Synapseへ移行完了、併せてDWUを10000に増強。
オンプレのExadataの電源を順次落としていきました。
これにより、クラウド移行を完了し、オンプレの基盤は大幅に縮小され、
以降、AzureSynapseで分析業務や配信業務は実行されるようになりました。
クラウド移行の成果
最終的に4台のExadataのうち、Exadata3台を廃止し、Synapseへの移行が完了しました。
・分析DB(副)とレコメンドDBはSynapseへ移管し、それぞれのExadataは廃止
・各分析DBやレコメンドDBnの一部機能を基幹DBのExadataへ移植
コスト的にはリザーブド化の効果もあり、相当なコストダウン
かつオンプレの基盤更改のタイミングに合わせた事で重複コストもある程度抑える事が出来ましたが、移行の遅延で並行稼働分の重複コストを発生させた事も事実で、ここは手放しには喜べませんでした。
クラウド化の実現でコストダウンと性能向上を何とか成し遂げましたが、
振り返っても、PoCの目算誤りで綱渡りのプロジェクトとなり、
アナリスト部門や上司や関係者には迷惑かけまくったにも関わらず、完遂まで協力いただけたことには感謝です。
またPh2として実施したレコメンドDBの移行も、
先行する分析基盤移行が遅滞する中、信じてプロジェクトを進めてくれたメンバーにも感謝。
苦労ばかりでしたが、この時にコンプラや法務、IT基盤、アナリスト部門、データサイエンス部門など
色んな部署と取り組んだことで、新しい事へのチャレンジをする人でありながら、全体のバランスを取れる人と認知されるようになったようで、今まで距離の遠かった部署や非協力的だと感じた部署とも戦友のような関係性が出来ました。
戦いの後、次の戦いでは仲間になる的な? By男塾

暗黒オンプレからクラウド移行時代(2017年-2019年)
さて、そんなこんなのクラウド移行を完了するかどうかの2019年11月にsnowflakeで出会うのですが、
それは次の記事で。(もう、お腹いっぱい??)
Discussion