時系列データ分析 論文解説③「 iTransformer 」
論文
前回記事 に引き続き、時系列データ分析のための論文紹介になります。
今回は、Transformer への入力を並べ替えたらうまくいった、という内容です。
タイトル
ITRANSFORMER: INVERTED TRANSFORMERS ARE EFFECTIVE FOR TIME SERIES FORECASTING
論文: https://arxiv.org/pdf/2310.06625
Github: https://github.com/thuml/iTransformer
概要
- iTransformer の提案。これは単純に「次元を反転させて」入力するものです
- iTransformer モデルは、難易度の高い実世界データセットにおいて最先端の成果を達成
モデル構造
モデル構造の理解は、公式Githubにある疑似コードがとても分かりやすいです。
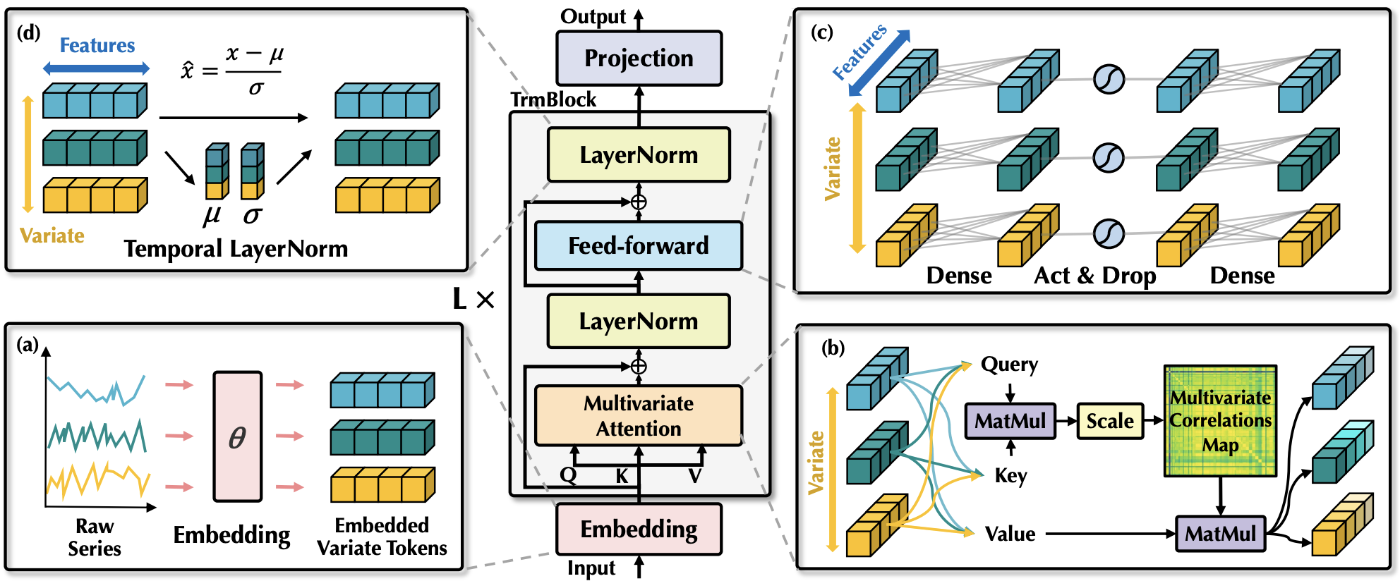

上述の疑似コードは Batch を考慮しておらず、1データの場合です。要は、時系列軸とChannel軸(通貨A価格, 通貨B価格, ... )を反転させて、入力しようという試みです。
Embedding ( MLP )
図にある Embedding というのは単なる MLP です。Channel 毎に重みが分けられている訳でもなく、T → D 次元に変換するための MLP です。
Position Encoding ( PE )
この仕組みは取り入れられていない様です。iTransformer における PE は、もしあるとするならば、時系列長ではなく Channel 軸に対する PE になるはずです(つまり通貨A, 通貨B, ... のようなどの通貨なのかを同定するために使われる Encoding )。
論文にも以下とあります。
the position embedding in the vanilla Transformer is no longer needed here.
Attention は通常時系列長に対しての位置を意識しない構造となりますが、今回の場合、Channel 軸は混ざり合わさっても問題ない、という事なのでしょう。
結果
いきなり結果ですが、本論文の iTransformer が良かったよ、という内容になります。

Invert して入力した時の結果

Transformer + Inverted が今回の iTransformer になります。入れ替えた方がどのモデルでも結果が良くなっています。
コンポーネントの入れ替えや除去別の結果

これちょっと説明が悪いと思うのですが、Variate -> Channel 方向、Temporal -> 時系列方向 という意味合いになります。つまり、Variate が Attention というのは、Channel軸のAttention 計算、という意味です(通常のTransformer は時系列軸に Attention を計算します)。そして、Temporal が FFN というのは、時系列方向にFFNしている、という事です。
Replace の二行目の、Variate: FFN, Temporal: Attention というのは、実質的に通常の Transformer になります(時系列軸に Attention, Channel 軸に FFN なので)。
w/o は without の意味で、そのコンポーネントを除去して検証した、という事になります。
FFN, FFN の組み合わせが思いのほか悪くないのが面白いですね。
考察
前回の PatchTST もそうですが、これらは Transformer の改造はしてなくて、入力を工夫した、という内容になります。なので、本質的にはあまり新規性はないです。
また、論文にも記載がありますが、時系列軸とChannel軸を入れ替えて Transformer Encoder に入力するため、これは「相関」のようなものを計算する事になります(通貨Aと通貨Aの相関, 通貨Aと通貨Bの相関, ...)。「~のような」とつけているのは、Attention で Query, Key, Value に分けて QK を計算するので、直接的な相関の計算にはなっていないからです。

Attention までの流れを簡易的に絵にすると上記のようになります。Channel 軸は 通貨A、通貨Bで表現しています。Attention の計算が、相関のような計算になっていることが分かると思います。
疑問点
ただ今回、前段のMLPや、Attention の計算の際に QKV に分ける MLP が、正しく理解していないとよくない操作になるのではないかと感じています。
というのも、通貨A、通貨B のように、似た種類の特徴量の場合は、MLPの重みがChannelに対しても共通で良いと思うのですが、例えば、時系列軸に対して「電流、電圧、電力、かかった料金」みたいな異なる種類の特徴量が Channel として並べられた場合、共通の重みとしての MLP は意味抽出に向かないんじゃないかな? という疑問です。
通常の Transformer の場合は、MLP に対する各ベクトルは、特徴量次元という意味で、時系列方向に渡って意味が共通しているので問題ないです。
ただ、時系列方向では共通した(i時間の情報, i+1時間の情報, ...)情報になっているので、問題ないのかな…。ちょっと、分からない点ではあります。
Discussion