Docker Swarm in LXD
おはこんばんにちは
以前k8sをLXD上で試したのですが今回はSwarmを試してみたのでその備忘録
k8sの時の記事
準備
LXDで簡単にノードを追加削除出来るようにSwarmが動くLXD環境をまず1個作ってイメージを保存します。
LXDでswarmを動かせるようにするProfileを作成
$ lxc profile create swarm
Profile swarm created
$ wget -O - -q https://raw.githubusercontent.com/ubuntu/microk8s/master/tests/lxc/microk8s-zfs.profile | lxc profile edit swarm
Profileを適用してコンテナを起動
$ lxc launch -p default -p swarm ubuntu:20.04 manager
Dockerのインストール
$ lxc exec manager -- apt update
$ lxc exec manager -- apt install -y docker.io
ここまでの状態を使いまわしたいので保存
$ lxc stop manager
$ lxc publish manager --alias swarm
保存したイメージが適用するProfileにswarmを追加
最終行に- swarmを追記
$ lxc image edit swarm
確認
$ lxc image show swarm
auto_update: false
properties:
architecture: x86_64
description: Ubuntu 20.04 LTS server (20220308)
os: ubuntu
release: focal
public: false
expires_at: 0001-01-01T00:00:00Z
profiles:
- default
- swarm
swarmを起動
managerノードを1つworkerノードを2つで起動してみる
まずは最初に作ったコンテナが止まってるので起動してマネージャとして動かす
$ lxc start manager
$ lxc exec manager docker swarm init
workerノードを作成して参加する
まずはworkerとして参加するためのトークンを取得する
尚、この情報はinit時にも表示されている
$ lxc exec manager -- docker swarm join-token worker
To add a worker to this swarm, run the following command:
docker swarm join --token SWMTKN-1-3u72kjwwe38yxzlpx29km6a7l4gliagus00eb1ivx9jd5ocbhs-d5p7682dtv6998pz26vidhn39 10.129.61.177:2377
worker用コンテナを2つ作成してSwarmに参加する
1個目
$ lxc launch swarm worker1
$ lxc exec worker1 -- docker swarm join --token SWMTKN-1-3u72kjwwe38yxzlpx29km6a7l4gliagus00eb1ivx9jd5ocbhs-d5p7682dtv6998pz26vidhn39 10.129.61.177:2377
2個目
$ lxc launch swarm worker2
$ lxc exec worker2 -- docker swarm join --token SWMTKN-1-3u72kjwwe38yxzlpx29km6a7l4gliagus00eb1ivx9jd5ocbhs-d5p7682dtv6998pz26vidhn39 10.129.61.177:2377
参加出来たか確認
$ lxc exec manager -- docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
pwyisd5zyjgbpkep7isbka9m2 * manager Ready Active Leader 20.10.7
60t0m4m637tcyvg4v8bv6vmmu worker1 Ready Active 20.10.7
lcvgurxwu6lye0ulfl816enbn worker2 Ready Active 20.10.7
サービスを動かしてみる
DockerチュートリアルのこのイメージをビルドしてSwarmで実行してみる
gitコマンドが必要なので追加してDockerイメージをビルド
$ lxc exec manager -- apt install -y git
$ lxc exec manager -- git clone https://github.com/dockersamples/node-bulletin-board
$ lxc exec manager -- docker build --tag bulletinboard:1.0 node-bulletin-board/bulletin-board-app/
$ lxc exec manager -- docker images bulletinboard
REPOSITORY TAG IMAGE ID CREATED SIZE
bulletinboard 1.0 d371c334f1f3 About a minute ago 260MB
swarmで動かすためのyamlを作成(stackファイルっていうらしい)します
$ lxc shell manager
root@manager:~# cat <<EOF > bb.yaml
version: '3.7'
services:
bb-app:
image: bulletinboard:1.0
ports:
- "80:8080"
EOF
root@manager:~# logout
Swarmに登録してみる
$ lxc exec manager -- docker stack deploy -c bb.yaml demo
これで実行されてるはずなので確認
$ lxc exec manager -- docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
jrfuvndpk5hs demo_bb-app replicated 1/1 bulletinboard:1.0 *:80->8080/tcp
REPLICASが起動してるコンテナ数でLXDコンテナの80ポートにアクセスするとDockerコンテナの8080ポートにアクセスするように起動されています。
続いてどのノードで動いているかを確認
$ lxc exec manager -- docker service ps demo_bb-app
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
u9dg3koqso2l demo_bb-app.1 bulletinboard:1.0 manager Running Running 2 minutes ago
managerノードで実行されているのがわかります
とりあえずブラウザで確認するためにLXDコンテナのIPを確認します
$ lxc list
+---------+---------+------------------------------+-----------------------------------------------+-----------+-----------+
| NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS |
+---------+---------+------------------------------+-----------------------------------------------+-----------+-----------+
| manager | RUNNING | 172.18.0.1 (docker_gwbridge) | fd42:6f2d:73e1:6009:216:3eff:fe40:5bda (eth0) | CONTAINER | 0 |
| | | 172.17.0.1 (docker0) | | | |
| | | 10.129.61.177 (eth0) | | | |
+---------+---------+------------------------------+-----------------------------------------------+-----------+-----------+
| worker1 | RUNNING | 172.18.0.1 (docker_gwbridge) | fd42:6f2d:73e1:6009:216:3eff:feb7:91c3 (eth0) | CONTAINER | 0 |
| | | 172.17.0.1 (docker0) | | | |
| | | 10.129.61.51 (eth0) | | | |
+---------+---------+------------------------------+-----------------------------------------------+-----------+-----------+
| worker2 | RUNNING | 172.18.0.1 (docker_gwbridge) | fd42:6f2d:73e1:6009:216:3eff:fe5b:2a16 (eth0) | CONTAINER | 0 |
| | | 172.17.0.1 (docker0) | | | |
| | | 10.129.61.144 (eth0) | | | |
+---------+---------+------------------------------+-----------------------------------------------+-----------+-----------+
そしてブラウザで確認
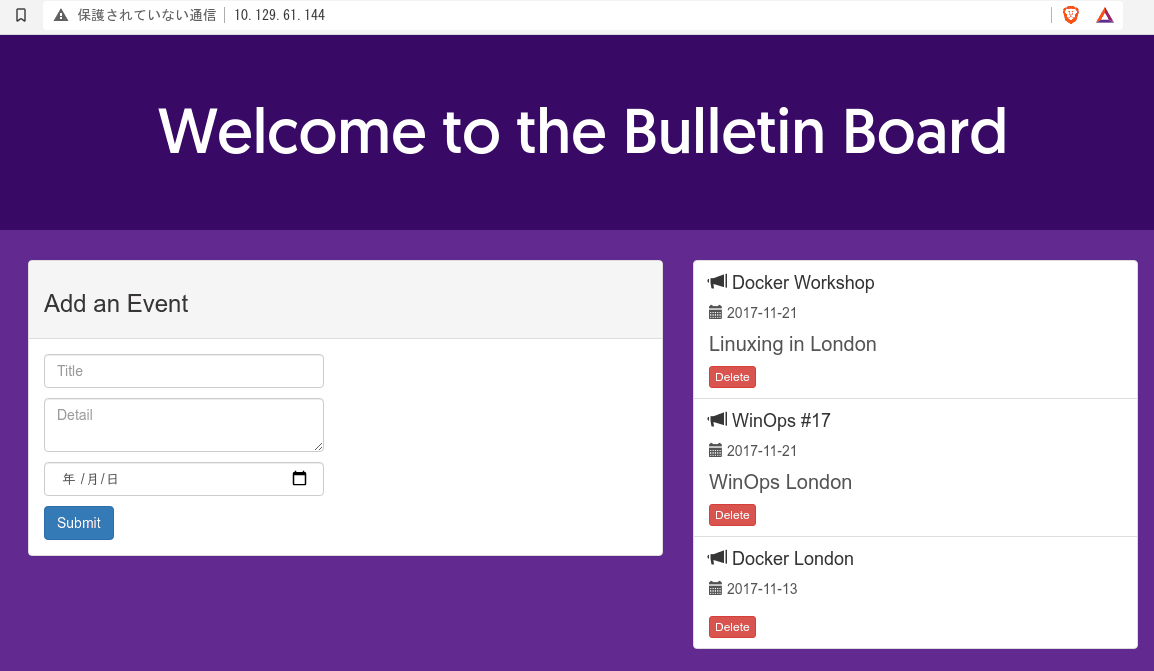
URLを見ればわかりますがアプリケーションはmanagerノードで実行されているのにworker2にアクセスしても画面が確認できます
これは内部でこんな感じでリクエストをルーティングしてくれているので参加してるノードのどこにリクエストを送っても動くようになっているからです
スケールアップしてみる
このWEBアプリを3つにスケールアップしてみます
$ lxc exec manager -- docker service scale demo_bb-app=3
$ lxc exec manager -- docker service ps demo_bb-app -f DESIRED-STATE=running
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
u9dg3koqso2l demo_bb-app.1 bulletinboard:1.0 manager Running Running 48 minutes ago
a9700b189luq demo_bb-app.2 bulletinboard:1.0 manager Running Running 5 minutes ago
ox4gaxcogczm demo_bb-app.3 bulletinboard:1.0 manager Running Running 5 minutes ago
なんと全部managerで動いています。
これはmanagerでローカルビルドしたイメージを使っているためworkerから該当のイメージを見付けられないのが原因です
以下のコマンドでworkerで動かそうとして失敗した事がわかります
$ lxc exec manager -- docker service ps demo_bb-app -f DESIRED-STATE=shutdown
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
w7ljnpj4cl4d demo_bb-app.2 bulletinboard:1.0 worker1 Shutdown Rejected 7 minutes ago "No such image: bulletinboard:…"
t74j7r244u0b \_ demo_bb-app.2 bulletinboard:1.0 worker1 Shutdown Rejected 7 minutes ago "No such image: bulletinboard:…"
s5zs7vsmaeht \_ demo_bb-app.2 bulletinboard:1.0 worker1 Shutdown Rejected 7 minutes ago "No such image: bulletinboard:…"
1cn73nqm7ith \_ demo_bb-app.2 bulletinboard:1.0 worker2 Shutdown Rejected 7 minutes ago "No such image: bulletinboard:…"
ygc1u61rv6zn demo_bb-app.3 bulletinboard:1.0 worker2 Shutdown Rejected 7 minutes ago "No such image: bulletinboard:…"
ez3qde6jqu87 \_ demo_bb-app.3 bulletinboard:1.0 worker2 Shutdown Rejected 7 minutes ago "No such image: bulletinboard:…"
oikzsxrtx1dy \_ demo_bb-app.3 bulletinboard:1.0 worker2 Shutdown Rejected 7 minutes ago "No such image: bulletinboard:…"
o2k69ehwhfoe \_ demo_bb-app.3 bulletinboard:1.0 worker1 Shutdown Rejected 7 minutes ago "No such image: bulletinboard:…"
No such image: bulletinboard:…と出ていますね。
DockerHub等に上がってるイメージを使う場合は問題ないのですがローカルでビルドしたイメージを使う場合は各nodeに同じimageを入れるかどのノードからもアクセス出来るリポジトリ等にイメージを置く必要があります今回は各worker1,worker2にmanagerのイメージをコピーして対応してみます
$ lxc exec manager -- docker save bulletinboard | lxc exec worker1 -- docker load
Loaded image: bulletinboard:1.0
$ lxc exec manager -- docker save bulletinboard | lxc exec worker2 -- docker load
Loaded image: bulletinboard:1.0
$ lxc exec worker1 -- docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
bulletinboard 1.0 d371c334f1f3 About an hour ago 260MB
node current-slim e71ac23fcd7e 17 hours ago 241MB
$ lxc exec worker2 -- docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
bulletinboard 1.0 d371c334f1f3 About an hour ago 260MB
node current-slim e71ac23fcd7e 17 hours ago 241MB
さて再度スケールを変更してみましょう
まずはスケールを1にして元に戻してから
$ lxc exec manager -- docker service scale demo_bb-app=1
$ lxc exec manager -- docker service ps demo_bb-app -f DESIRED-STATE=Running
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
u9dg3koqso2l demo_bb-app.1 bulletinboard:1.0 manager Running Running about an hour ago
再度3にしてみると
$ lxc exec manager -- docker service scale demo_bb-app=3
$ lxc exec manager -- docker service ps demo_bb-app -f DESIRED-STATE=Running
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
u9dg3koqso2l demo_bb-app.1 bulletinboard:1.0 manager Running Running about an hour ago
m3mytsmtchi0 demo_bb-app.2 bulletinboard:1.0 worker1 Running Running 16 seconds ago
367ghy7ujl7y demo_bb-app.3 bulletinboard:1.0 worker2 Running Running 16 seconds ago
今度は正常に各ノードに振り分けられました
ではログをtailします
$ lxc exec manager -- docker service logs -n0 -f demo_bb-app
この状態でブラウザで再度画面を開くと
demo_bb-app.2.m3mytsmtchi0@worker1 | GET / 304 0.403 ms - -
demo_bb-app.1.u9dg3koqso2l@manager | GET /node_modules/vue/dist/vue.min.js 304 0.549 ms - -
demo_bb-app.3.367ghy7ujl7y@worker2 | GET /site.css 304 0.601 ms - -
demo_bb-app.3.367ghy7ujl7y@worker2 | GET /app.js 304 0.693 ms - -
demo_bb-app.2.m3mytsmtchi0@worker1 | GET /node_modules/bootstrap/dist/css/bootstrap.min.css 304 0.734 ms - -
demo_bb-app.2.m3mytsmtchi0@worker1 | GET /node_modules/vue-resource/dist/vue-resource.min.js 304 2.830 ms - -
demo_bb-app.2.m3mytsmtchi0@worker1 | GET /api/events 304 0.639 ms - -
demo_bb-app.2.m3mytsmtchi0@worker1 | GET /fonts/geomanist/hinted-Geomanist-Book.woff2 304 0.375 ms - -
demo_bb-app.2.m3mytsmtchi0@worker1 | GET /null 404 0.514 ms - 143
demo_bb-app.3.367ghy7ujl7y@worker2 | GET /node_modules/bootstrap/dist/fonts/glyphicons-halflings-regular.woff2 304 0.524 ms - -
こんな感じでリクエストが各ノードに分散して実行されているのがわかりますね
managerの追加による耐障害性の確保
ドキュメントによると
Nつのmanagerクラスタは、最大で (N-1)/2 manager の障害に耐えます
とのことで耐障害性の確保には最低でも3つはmanagerノードが必要になるようなのでmanagerノードを2つ追加してみます
$ lxc launch swarm manager2
$ lxc launch swarm manager3
manager用のトークンでswarmに参加します
$ lxc exec manager -- docker swarm join-token manager
To add a manager to this swarm, run the following command:
docker swarm join --token SWMTKN-1-3u72kjwwe38yxzlpx29km6a7l4gliagus00eb1ivx9jd5ocbhs-7y5i7tpuv3qpqkzx2qpomp1e0 10.129.61.177:2377
$ lxc exec manager2 -- docker swarm join --token SWMTKN-1-3u72kjwwe38yxzlpx29km6a7l4gliagus00eb1ivx9jd5ocbhs-7y5i7tpuv3qpqkzx2qpomp1e0 10.129.61.177:2377
This node joined a swarm as a manager.
$ lxc exec manager3 -- docker swarm join --token SWMTKN-1-3u72kjwwe38yxzlpx29km6a7l4gliagus00eb1ivx9jd5ocbhs-7y5i7tpuv3qpqkzx2qpomp1e0 10.129.61.177:2377
This node joined a swarm as a manager.
確認
$ lxc exec manager -- docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
pwyisd5zyjgbpkep7isbka9m2 * manager Ready Active Leader 20.10.7
h9vyiz86y4cvpl2zkzln1a64u manager2 Ready Active Reachable 20.10.7
zlsym5cfjavdt2gs5qhqmejnq manager3 Ready Active Reachable 20.10.7
60t0m4m637tcyvg4v8bv6vmmu worker1 Ready Active 20.10.7
lcvgurxwu6lye0ulfl816enbn worker2 Ready Active 20.10.7
折角なのでアプリも全部に配置
$ lxc exec manager -- docker save bulletinboard | lxc exec manager2 -- docker load
$ lxc exec manager -- docker save bulletinboard | lxc exec manager3 -- docker load
$ lxc exec manager -- docker service scale demo_bb-app=5
$ lxc exec manager -- docker service ps demo_bb-app -f DESIRED-STATE=running
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
u9dg3koqso2l demo_bb-app.1 bulletinboard:1.0 manager Running Running 2 hours ago
m3mytsmtchi0 demo_bb-app.2 bulletinboard:1.0 worker1 Running Running about an hour ago
367ghy7ujl7y demo_bb-app.3 bulletinboard:1.0 worker2 Running Running about an hour ago
09kkoprfbpz9 demo_bb-app.4 bulletinboard:1.0 manager2 Running Running 12 seconds ago
zhrcudp3895f demo_bb-app.5 bulletinboard:1.0 manager3 Running Running 13 seconds ago
この状態でLeaderであるmanagerを停止してみる
$ lxc stop manager
するとmanager3がLeaderに選出されて居ることがわかる
$ lxc exec manager2 -- docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
pwyisd5zyjgbpkep7isbka9m2 manager Unknown Active Unreachable 20.10.7
h9vyiz86y4cvpl2zkzln1a64u * manager2 Ready Active Reachable 20.10.7
zlsym5cfjavdt2gs5qhqmejnq manager3 Ready Active Leader 20.10.7
60t0m4m637tcyvg4v8bv6vmmu worker1 Ready Active 20.10.7
lcvgurxwu6lye0ulfl816enbn worker2 Ready Active 20.10.7
この状態でサービスを確認するとmanagerで動作していたサービスはworker1に引き継がれて正常にスケールされていた
$ lxc exec manager2 -- docker service ps demo_bb-app -f DESIRED-STATE=running
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
hg8qarxfsjoc demo_bb-app.1 bulletinboard:1.0 worker1 Running Running 2 minutes ago
m3mytsmtchi0 demo_bb-app.2 bulletinboard:1.0 worker1 Running Running 2 minutes ago
367ghy7ujl7y demo_bb-app.3 bulletinboard:1.0 worker2 Running Running 2 minutes ago
09kkoprfbpz9 demo_bb-app.4 bulletinboard:1.0 manager2 Running Running 2 minutes ago
zhrcudp3895f demo_bb-app.5 bulletinboard:1.0 manager3 Running Running 2 minutes ago
managerを起動し直すだけでSwarmクラスタに再度組み込まれることを確認
$ lxc start manager
$ lxc exec manager2 -- docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
pwyisd5zyjgbpkep7isbka9m2 manager Ready Active Reachable 20.10.7
h9vyiz86y4cvpl2zkzln1a64u * manager2 Ready Active Reachable 20.10.7
zlsym5cfjavdt2gs5qhqmejnq manager3 Ready Active Leader 20.10.7
60t0m4m637tcyvg4v8bv6vmmu worker1 Ready Active 20.10.7
lcvgurxwu6lye0ulfl816enbn worker2 Ready Active 20.10.7
サービスのアップデート
microbotという実行中ホストの確認とアップデートの確認をするためのコンテナがあるのでそれで確認してみる
まずは今あるサービスを削除
$ lxc exec manager2 -- docker service rm demo_bb-app
microbotをデプロイ
$ lxc exec manager2 -- \
docker service create --replicas 5 \
--name microbot \
--publish 80:80 \
dontrebootme/microbot:v1
画面確認

v1からv2にイメージをアップデート
$ lxc exec manager -- docker service update --image dontrebootme/microbot:v2 microbot
ブラウザを適当に更新し続けていると画面が切り替わる

プロセス確認
$ lxc exec manager -- docker service ps microbot
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
av0cpmgaq70s microbot.1 dontrebootme/microbot:v2 manager Running Running 2 minutes ago
w3r6fuob4y4u \_ microbot.1 dontrebootme/microbot:v1 manager Shutdown Shutdown 2 minutes ago
jolnqtaiy7mo microbot.2 dontrebootme/microbot:v2 manager3 Running Running 3 minutes ago
qmlwwytr2c9j \_ microbot.2 dontrebootme/microbot:v1 manager3 Shutdown Shutdown 3 minutes ago
wm91vtjq45ny microbot.3 dontrebootme/microbot:v2 worker1 Running Running 2 minutes ago
x7nb1cjxbgfc \_ microbot.3 dontrebootme/microbot:v1 worker1 Shutdown Shutdown 2 minutes ago
51rojcmq1iy6 microbot.4 dontrebootme/microbot:v2 manager2 Running Running 3 minutes ago
ucfa641q8ywg \_ microbot.4 dontrebootme/microbot:v1 manager2 Shutdown Shutdown 3 minutes ago
p4u64ktzti2z microbot.5 dontrebootme/microbot:v2 worker2 Running Running 2 minutes ago
vxqeaxswe3fv \_ microbot.5 dontrebootme/microbot:v1 worker2 Shutdown Shutdown 2 minutes ago
各ノードでv1が停止されてv2が起動していることがわかる
一旦全てが立ち上がりきるまでは旧アプリが表示され続けるので全てが正常に起動し切るまでは新には切り替わらないようだ
また新旧が切り替わるまでの間に一瞬アクセスできなくなったので更新時は注意したほうが良さそう
--update-parallelism引数でに並行で何個更新かけるかを決められる0指定で全部一気に更新できる
HAProxyでLBしてみる
今現在は適当に選んだノードのIPに対してリクエストを送信して動作確認しているが実際には前段にそれらをまとめるLBをおいてそいつがリクエストを捌くことが多いのでHAProxyを置いてみる
とりあえずHAProxyを動作させるLXDコンテナを作成Dockerを使うのでSwarm用のイメージを流用します
$ lxc launch swarm HAProxy
今のLXDコンテナ一覧を確認
$ lxc list
+----------+---------+------------------------------+-----------------------------------------------+-----------+-----------+
| NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS |
+----------+---------+------------------------------+-----------------------------------------------+-----------+-----------+
| HAProxy | RUNNING | 172.17.0.1 (docker0) | fd42:6f2d:73e1:6009:216:3eff:fec8:5939 (eth0) | CONTAINER | 0 |
| | | 10.129.61.154 (eth0) | | | |
+----------+---------+------------------------------+-----------------------------------------------+-----------+-----------+
| manager | RUNNING | 172.18.0.1 (docker_gwbridge) | fd42:6f2d:73e1:6009:216:3eff:fe40:5bda (eth0) | CONTAINER | 0 |
| | | 172.17.0.1 (docker0) | | | |
| | | 10.129.61.177 (eth0) | | | |
+----------+---------+------------------------------+-----------------------------------------------+-----------+-----------+
| manager2 | RUNNING | 172.18.0.1 (docker_gwbridge) | fd42:6f2d:73e1:6009:216:3eff:fe61:77cb (eth0) | CONTAINER | 0 |
| | | 172.17.0.1 (docker0) | | | |
| | | 10.129.61.55 (eth0) | | | |
+----------+---------+------------------------------+-----------------------------------------------+-----------+-----------+
| manager3 | RUNNING | 172.18.0.1 (docker_gwbridge) | fd42:6f2d:73e1:6009:216:3eff:fe3c:ad7 (eth0) | CONTAINER | 0 |
| | | 172.17.0.1 (docker0) | | | |
| | | 10.129.61.242 (eth0) | | | |
+----------+---------+------------------------------+-----------------------------------------------+-----------+-----------+
| worker1 | RUNNING | 172.18.0.1 (docker_gwbridge) | fd42:6f2d:73e1:6009:216:3eff:feb7:91c3 (eth0) | CONTAINER | 0 |
| | | 172.17.0.1 (docker0) | | | |
| | | 10.129.61.51 (eth0) | | | |
+----------+---------+------------------------------+-----------------------------------------------+-----------+-----------+
| worker2 | RUNNING | 172.18.0.1 (docker_gwbridge) | fd42:6f2d:73e1:6009:216:3eff:fe5b:2a16 (eth0) | CONTAINER | 0 |
| | | 172.17.0.1 (docker0) | | | |
| | | 10.129.61.144 (eth0) | | | |
+----------+---------+------------------------------+-----------------------------------------------+-----------+-----------+
各コンテナのeth0のIPをベースに設定ファイル作成
cat <<EOF > /tmp/haproxy.cfg
frontend web_proxy
default_backend test
bind *:80
backend test
option redispatch
retries 3
server manager 10.129.61.177:80 weight 1
server manager2 10.129.61.55:80 weight 1
server manager3 10.129.61.242:80 weight 1
server worker1 10.129.61.51:80 weight 1
server worker2 10.129.61.144:80 weight 1
EOF
HAProxyコンテナにコピー
$ lxc file push /tmp/haproxy.cfg HAProxy/haproxy.cfg
HAProxyを起動
$ lxc exec HAProxy -- docker run -d -p 80:80 -v /haproxy.cfg:/usr/local/etc/haproxy/haproxy.cfg --name web haproxy
起動確認
$ lxc exec HAProxy -- docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
87abe54b9256 haproxy "docker-entrypoint.s…" 27 seconds ago Up 19 seconds 0.0.0.0:80->80/tcp, :::80->80/tcp web
HAProxyにブラウザでアクセスしてみるとSwarmに登録したサービスの画像が表示されているのがわかる
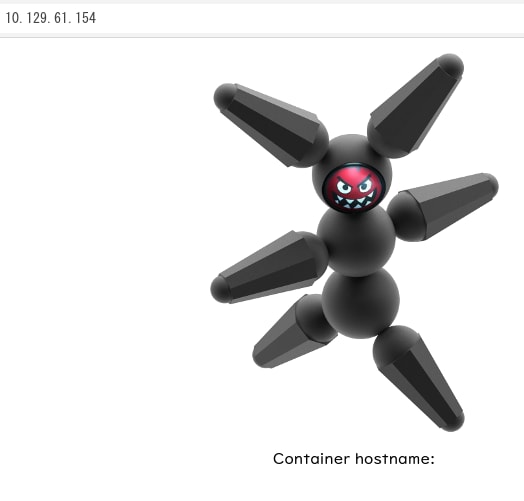
manager,worker1,worker2ノードを止めてみる
$ lxc stop manager worker1 worker2
$ lxc exec manager2 -- docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
pwyisd5zyjgbpkep7isbka9m2 manager Down Active Unreachable 20.10.7
h9vyiz86y4cvpl2zkzln1a64u * manager2 Ready Active Reachable 20.10.7
zlsym5cfjavdt2gs5qhqmejnq manager3 Ready Active Leader 20.10.7
60t0m4m637tcyvg4v8bv6vmmu worker1 Down Active 20.10.7
lcvgurxwu6lye0ulfl816enbn worker2 Down Active 20.10.7
半分以上のノードが停止している状態だがHAProxy経由なら正常なノードに繋がる
まとめ
長くなってきたので一旦ここらへんで締める
まだ色々触ってみたいものがあるので都度追記するか別記事にするかは後で考えるとして
サクッと触ってみた感じK8sの時より簡単だった、dockerコマンドにある程度慣れてたらその延長線上で使えるからだと思う
産廃PC寄せ集めてDockerクラスタ組めみたいな無茶振りされたらこれ使うと思う
後で追記しようと思うがConfigとかSecretが便利そうなのでスタンドアローンでもSwarm有効化して使っていきたいなと思う
P.S.
世間では半導体不足が騒がれて久しいですね
アプリ側なんで自分には関係ない話だと思ってたらまさかの実害が出てきました
レガシーな現場なんでオンプレのサーバが一杯あるわけなんですが保守切れの古くなったやつは新しいのに置き換える必要があるわけですね
で、サーバ置き換える際に確保した予算にはアプリの機能追加分の予算とかも積まれてるわけですよ。。。
そこに半導体不足が直撃してサーバの納期が未定になりました😇
その結果。。。。
巻き込まれてアプリの対応も無期延期に!🤣
さてこの状態いつまで続くのか。。。
Discussion