TAMPublicationへの投稿🎤WhisperとGoogle Colaboratoryで音声の文字起こしをやってみたKazuki Yonemoto2022/09/24に公開2022/09/2527件AIPythonGoogle Colaboratory音声認識WhispertechTAMPublicationお客さまと共に新しい価値を創る。パートナー型デジタル・エージェンシーTAMのテックブログです。 採用情報:wantedly.com/companies/tam/ DiscussionTakatsu2022/10/25とても有益な投稿で助かりました! すばらしい情報ありがとうございます! さっそく使用してみて恐縮ですが、最後のファイルにした際のテキストを、 文字列ごとに改行することは可能なのでしょうか? 現状、全てつながっている状況です。 プログラミング無知なためご教授いただけると幸いです。 Kazuki Yonemoto2022/10/26読んでいただきありがとうございます! 別記事で恐縮ですが、こちらで解説されてるような改行処理をやってみるのがいいかもですね。 https://self-development.info/【python】ai音声認識whisperを使ったsrt字幕ファイルの自動作/ Takatsu2022/10/26ありがとうございます! 早速試してみたいと思います。 返信を追加あみ2022/12/22に更新初めまして、非エンジニアですが、Whisperをどうしても使いたくて Google Colaboratoryに挑戦中です。 最終段階までできて、txtをダウンロードしてみたら、 画像のようになりました。 ▼ Transcription of test.MP3 スタッフの上に、スタッフの上に、スタッフの上に、…… 音声ファイルは会議で1時間以上のものです。 どうすればいいのか教えていただけないでしょうか? Kazuki Yonemoto2022/12/22に更新記事を読んでいただきありがとうござます。 記載いただいた要件ですと、以下記事を参考にしていただくのが良いかもしれません。同じワードがループしてしまう際の対処も少し紹介されています。 https://zenn.dev/ik/articles/f891d628e829ea あみ2022/12/22ありがとうございます。 読ませていただきます。 返信を追加あみ2022/12/22このページのサンプルをコピーさせていただいて、使用しております。 12 mel = whisper.log_mel_spectrogram(audio).to(model.device) の下に、 result = model.transcribe(audio, verbose=True, temperature=0.8, language=lang) を追加しました。 temperatureの数値を0.6~1.2ぐらいに変更してみましたが、 0.8が一番合っているような感じですが、やはり26秒ぐらいしか 文字起こしができませんでした。 しかも、日本語には見えますが、話している話題とはだいぶ違う感じでした。 句読点が入っているのがちょっとうれしいです。 やはりGoogle Colaboratoryでは、30秒ぐらいが限界ですか? Kazuki Yonemoto2022/12/22に更新文字起こしを以下のようにループ処理にしてみると、30秒以上の音声にも対応できるかもしれません。1時間の音声では試せていないですが、数分程度であれば書き出せました。 #@title 文字起こし import whisper fileName = "sample.m4a"#@param {type:"string"} lang = "ja"#@param ["ja", "en"] model_size = "medium"#@param ["tiny", "base", "small", "medium", "large"] model = whisper.load_model(model_size) # オーディオファイル読み込み audio = whisper.load_audio(f"content/{fileName}") outputTextsArr = [] while audio.size > 0: tirmedAudio = whisper.pad_or_trim(audio) startIdx = tirmedAudio.size audio = audio[startIdx:] mel = whisper.log_mel_spectrogram(tirmedAudio).to(model.device) options = whisper.DecodingOptions(language=lang, without_timestamps=True) result = whisper.decode(model, mel, options) outputTextsArr.append(result.text) outputTexts = ' '.join(outputTextsArr) print(outputTexts) # テキストファイル書込み with open(f'download/{fileName}.txt', 'w') as f: f.write(f'▼{fileName}の書き起こし\n') f.write(outputTexts) あみ2022/12/22に更新ビックリしました~そんなことまで簡単にできてしまうのですね。 私は、ファイルを30秒ごとに分割して・・・ なんてカメの思考でおりました。ぜひ、試してみます。 ところで、こんな記事があります。この方は14分ほど 起こしをされているようですね。 https://yasutakeyohei.com/blog/moji-okosi-whisper-surprised/ ChatGPTの案が役に立つとは思いませんでした(^^; 冗談かと思いました。。。 Kazuki Yonemoto2022/12/22厳密にいうと30秒毎に処理が切れてしまうので、途切れたタイミングで残りが0になるまで処理を繰り返しているイメージです。 音声ファイルを読み込み、30秒区画で書き起こして outputTextsArr の配列へ追加 音声ファイルがまだ続いている場合は途切れた箇所から 1. の処理を再開 最後まで処理が終わったらoutputTextsArr に格納されたの要素を全て連結 返信を追加あみ2022/12/22ChatGPTに聞いてみたらこんなお答えでした💦 あまり役には立たないかな? Kazuki Yonemoto2022/12/22に更新↑のスレッドで返信しています。 やった内容としては 1. の対応に近いですかね。🤔 あみ2022/12/23に更新ありがとうございます(^^)v 最初の部分で、図のようになりましたが、 そのあとだいぶ長いこと、文章化されました。 「medium」になってたので、全部ではない気がしますが、 どこまでできたか、明日検証します。 また、largeも試してみますね。 1日でできるとは思いませんでした。 おかげ様で、少しわかってきました。 ありがとうございます(o*。_。)oペコッ あみ2022/12/23に更新結果をお知らせします。 ・全体のデータは1:46:26 ①mp3アップロードに10分弱 ②文字起こしにMediumで11分、largeで16分でした。 ── 音質がいいとは言えない状況なので、結構、手直しは必要です。 ・largeの原稿をざっと見ましたが、句読点少な目で段落は入れてもらえませんが、 1:39:47の会議が終わるまで、文字起こしされていました。 ・会議が終わったあとの、ザワザワも多少拾っていました。 「お疲れ様」や「お腹が空いた」など。 ・会場が広く多少ガサガサしている部分もあり、音質は良いとは言えなかったのですが、少しマイクから遠い人の発言も精度はなかなか良かったです。(遠すぎる人はダメです) ※ 残る課題は、固有名詞や名前、地域、専門用語、使われている略語など、わかる範囲で登録できるといいなと思いました。あと、たまに飛んでいる部分があり、半角スペースが入っていた感じです。 ── 最終課題は、話者の活舌と録音状態ですね~ 今回は、録音状態あまり良くなかったので、飛ばされている箇所やマイクが遠く聞き取りミスも結構あったのですが、録音状態が良ければ、かなり使えると思います♪ 本当に、ありがとうございました。 最先端をお試しできてメチャクチャうれしいです! とりあえず、ご報告まで。 Kazuki Yonemoto2022/12/23おお!なんとか使えそうなところまで行けたようで良かったです🎉 バッジもありがとうございます!🙇🏻♂️ 返信を追加あみ2022/12/23今まで、複数の文字起こしツール試してみましたけど、これが一番早くて素晴らしいです。 今後が楽しみです~ 本当にありがとうございました。今後ともどうぞよろしくお願いします。 返信を追加あみ2022/12/26に更新こんにちは。段落をつけてみたくて、ChatGPTに相談して、ここまで作ったのですがうまくいきません。output.txtをダウンロードすることまでできましたが、何も変化がありません💦 【Windows 11+Google Colaboratoryです】 追伸 Wordにコピーしたら「\n」がそのまま転写されていたので、 f.write(paragraph + "\n") # 段落ごとに改行する 👇 f.write(paragraph + "^p") # 段落ごとに改行する にしたら、段落ができたものもありますが、できないものも結構あります。 また、行頭のスペースがありませんが、"^p"のあとに" " を追加しただけでは、ダメかな? お時間のあるときに、見ていただけますか? [共有リンク] https://colab.research.google.com/drive/1By-6ZWYIesSxdbmZO07W9tbWLfFREKfN?usp=sharing Kazuki Yonemoto2023/01/05もう見られてるかもですが、こちらの実装方法を参考にいただくのがいいかもしれません。 今あまり時間が取れる状況になく、詳細な回答は難しいです🙏 https://self-development.info/【python】ai音声認識whisperを使ったsrt字幕ファイルの自動作/ あみ2023/01/05ありがとうございます。まだ見ていなかったので参考にさせていただきます。 返信を追加みのりん2023/01/04に更新お世話になっております。非エンジニアなのですが、参考にさせていただき、文字起こしの仕組み構築にチャレンジしています。 以下のエラーになってしまうのですが、ご助言いただくことは可能でしょうか? 念のため、model_sizeをlargeとmediumの両方試したのですが、共にエラーになってしまいました。 音声ファイルは約15分の会議音声で153MBです。 PCのスペックは、以下になります。 ・Intel(R) Core(TM) i7-10510U CPU @ 1.80GHz 2.30 GHz ・実装 RAM 16.0 GB (15.8 GB 使用可能) ・システムの種類 64 ビット オペレーティング システム、x64 ベース プロセッサ ・エディション Windows 10 Enterprise Kazuki Yonemoto2023/01/05こちらの実装に変えていただくと、長時間ファイルの読み込みもいけるかもしれません。 コード部分をそのままコピペいただくのが確実かもです。 https://zenn.dev/link/comments/42c1c0a8da8a2f みのりん2023/01/05ありがとうございます! 一応、ご提示くださったリンク先からのコピペだったのですが、エラーになってしまうのですよね。”OutOfMemoryError”という文言があるので、PCのスペックは高い方だと思うのですが、足らないということなのでしょうかね(泣) Kazuki Yonemoto2023/01/06Colaboratoryはクラウド環境で動作するため、利用されているPCのスペック自体が影響することはないかと思います。 一度以下を試してみてください。 「ランタイム>ランタイムを接続解除して削除」をクリック 再度一からライブラリのインストール等を実行 みのりん2023/01/10できました! 本当にありがとうございました!!! 返信を追加ナルヘッソス2023/07/06記事を参考に文字起こしされたファイルを生成することができました。有意義な情報ありがとうございます。 2点質問があります。 もし分かればで良いので、お手すきの際にでも良いので教えていただけますと幸いです。 (1)なぜ無料なのか? ネットで検索した情報によりopen.ai のサイトで、有料登録を行い、apiキーを手に入れました。api経由で同様の処理を行った場合は従量課金されるようですが、このgoogle colabを用いた方法では、colabの環境上にインストールして処理を行うため無料ということなのでしょうか?apiへの課金が必要と思ってopen.aiのサイトにカード登録しましたが、この方法で文字起こしが無料で実行できるなら必要ないなと思っています。 (2)録音ファイルの扱い google colab 上にアップロードした音声ファイル自体は、あくまでcolab環境のみにストレージされるのみで、open.ai側には渡っていないと思っておいてよいでしょうか?colabに環境構築して実行しているのであくまでcolabのみに留まっている認識です。(試そうとしている音声ファイルがopen.ai 側にも渡ってもし万が一、流出したら嫌だなと思い・・・) Kazuki Yonemoto2023/07/07に更新(1)なぜ無料なのか? はい、こちら書いてもらってある通りです。モデルはMITライセンスでオープンソースで公開されているのと、本来はモデルがあったとしてもそれを動かした際、確実にコストはかかっているのですが、Googleさんが寛大にも無料である程度使えるようにしてくれているために実現できています。 このgoogle colabを用いた方法では、colabの環境上にインストールして処理を行うため無料ということなのでしょうか? https://github.com/openai/whisper https://colab.research.google.com/signup/pricing?utm_source=dialog&utm_medium=link&utm_campaign=settings_page&hl=ja (2)録音ファイルの扱い これもOpenAIのリソースは利用していないので、認識の通りです。 アップロードした音声ファイル自体は、あくまでcolab環境のみにストレージされるのみで、open.ai側には渡っていないと思っておいてよいでしょうか? 返信を追加ナルヘッソス2023/07/18当方の返事が遅くなり申し訳ありません。回答いただいた内容で疑問点が解消できました。 ご丁寧に回答くださりありがとうございました。感謝いたします。 返信を追加
Takatsu2022/10/25とても有益な投稿で助かりました! すばらしい情報ありがとうございます! さっそく使用してみて恐縮ですが、最後のファイルにした際のテキストを、 文字列ごとに改行することは可能なのでしょうか? 現状、全てつながっている状況です。 プログラミング無知なためご教授いただけると幸いです。 Kazuki Yonemoto2022/10/26読んでいただきありがとうございます! 別記事で恐縮ですが、こちらで解説されてるような改行処理をやってみるのがいいかもですね。 https://self-development.info/【python】ai音声認識whisperを使ったsrt字幕ファイルの自動作/ Takatsu2022/10/26ありがとうございます! 早速試してみたいと思います。 返信を追加
Kazuki Yonemoto2022/10/26読んでいただきありがとうございます! 別記事で恐縮ですが、こちらで解説されてるような改行処理をやってみるのがいいかもですね。 https://self-development.info/【python】ai音声認識whisperを使ったsrt字幕ファイルの自動作/
あみ2022/12/22に更新初めまして、非エンジニアですが、Whisperをどうしても使いたくて Google Colaboratoryに挑戦中です。 最終段階までできて、txtをダウンロードしてみたら、 画像のようになりました。 ▼ Transcription of test.MP3 スタッフの上に、スタッフの上に、スタッフの上に、…… 音声ファイルは会議で1時間以上のものです。 どうすればいいのか教えていただけないでしょうか? Kazuki Yonemoto2022/12/22に更新記事を読んでいただきありがとうござます。 記載いただいた要件ですと、以下記事を参考にしていただくのが良いかもしれません。同じワードがループしてしまう際の対処も少し紹介されています。 https://zenn.dev/ik/articles/f891d628e829ea あみ2022/12/22ありがとうございます。 読ませていただきます。 返信を追加
Kazuki Yonemoto2022/12/22に更新記事を読んでいただきありがとうござます。 記載いただいた要件ですと、以下記事を参考にしていただくのが良いかもしれません。同じワードがループしてしまう際の対処も少し紹介されています。 https://zenn.dev/ik/articles/f891d628e829ea
あみ2022/12/22このページのサンプルをコピーさせていただいて、使用しております。 12 mel = whisper.log_mel_spectrogram(audio).to(model.device) の下に、 result = model.transcribe(audio, verbose=True, temperature=0.8, language=lang) を追加しました。 temperatureの数値を0.6~1.2ぐらいに変更してみましたが、 0.8が一番合っているような感じですが、やはり26秒ぐらいしか 文字起こしができませんでした。 しかも、日本語には見えますが、話している話題とはだいぶ違う感じでした。 句読点が入っているのがちょっとうれしいです。 やはりGoogle Colaboratoryでは、30秒ぐらいが限界ですか? Kazuki Yonemoto2022/12/22に更新文字起こしを以下のようにループ処理にしてみると、30秒以上の音声にも対応できるかもしれません。1時間の音声では試せていないですが、数分程度であれば書き出せました。 #@title 文字起こし import whisper fileName = "sample.m4a"#@param {type:"string"} lang = "ja"#@param ["ja", "en"] model_size = "medium"#@param ["tiny", "base", "small", "medium", "large"] model = whisper.load_model(model_size) # オーディオファイル読み込み audio = whisper.load_audio(f"content/{fileName}") outputTextsArr = [] while audio.size > 0: tirmedAudio = whisper.pad_or_trim(audio) startIdx = tirmedAudio.size audio = audio[startIdx:] mel = whisper.log_mel_spectrogram(tirmedAudio).to(model.device) options = whisper.DecodingOptions(language=lang, without_timestamps=True) result = whisper.decode(model, mel, options) outputTextsArr.append(result.text) outputTexts = ' '.join(outputTextsArr) print(outputTexts) # テキストファイル書込み with open(f'download/{fileName}.txt', 'w') as f: f.write(f'▼{fileName}の書き起こし\n') f.write(outputTexts) あみ2022/12/22に更新ビックリしました~そんなことまで簡単にできてしまうのですね。 私は、ファイルを30秒ごとに分割して・・・ なんてカメの思考でおりました。ぜひ、試してみます。 ところで、こんな記事があります。この方は14分ほど 起こしをされているようですね。 https://yasutakeyohei.com/blog/moji-okosi-whisper-surprised/ ChatGPTの案が役に立つとは思いませんでした(^^; 冗談かと思いました。。。 Kazuki Yonemoto2022/12/22厳密にいうと30秒毎に処理が切れてしまうので、途切れたタイミングで残りが0になるまで処理を繰り返しているイメージです。 音声ファイルを読み込み、30秒区画で書き起こして outputTextsArr の配列へ追加 音声ファイルがまだ続いている場合は途切れた箇所から 1. の処理を再開 最後まで処理が終わったらoutputTextsArr に格納されたの要素を全て連結 返信を追加
Kazuki Yonemoto2022/12/22に更新文字起こしを以下のようにループ処理にしてみると、30秒以上の音声にも対応できるかもしれません。1時間の音声では試せていないですが、数分程度であれば書き出せました。 #@title 文字起こし import whisper fileName = "sample.m4a"#@param {type:"string"} lang = "ja"#@param ["ja", "en"] model_size = "medium"#@param ["tiny", "base", "small", "medium", "large"] model = whisper.load_model(model_size) # オーディオファイル読み込み audio = whisper.load_audio(f"content/{fileName}") outputTextsArr = [] while audio.size > 0: tirmedAudio = whisper.pad_or_trim(audio) startIdx = tirmedAudio.size audio = audio[startIdx:] mel = whisper.log_mel_spectrogram(tirmedAudio).to(model.device) options = whisper.DecodingOptions(language=lang, without_timestamps=True) result = whisper.decode(model, mel, options) outputTextsArr.append(result.text) outputTexts = ' '.join(outputTextsArr) print(outputTexts) # テキストファイル書込み with open(f'download/{fileName}.txt', 'w') as f: f.write(f'▼{fileName}の書き起こし\n') f.write(outputTexts)
あみ2022/12/22に更新ビックリしました~そんなことまで簡単にできてしまうのですね。 私は、ファイルを30秒ごとに分割して・・・ なんてカメの思考でおりました。ぜひ、試してみます。 ところで、こんな記事があります。この方は14分ほど 起こしをされているようですね。 https://yasutakeyohei.com/blog/moji-okosi-whisper-surprised/ ChatGPTの案が役に立つとは思いませんでした(^^; 冗談かと思いました。。。
Kazuki Yonemoto2022/12/22厳密にいうと30秒毎に処理が切れてしまうので、途切れたタイミングで残りが0になるまで処理を繰り返しているイメージです。 音声ファイルを読み込み、30秒区画で書き起こして outputTextsArr の配列へ追加 音声ファイルがまだ続いている場合は途切れた箇所から 1. の処理を再開 最後まで処理が終わったらoutputTextsArr に格納されたの要素を全て連結
あみ2022/12/22ChatGPTに聞いてみたらこんなお答えでした💦 あまり役には立たないかな? Kazuki Yonemoto2022/12/22に更新↑のスレッドで返信しています。 やった内容としては 1. の対応に近いですかね。🤔 あみ2022/12/23に更新ありがとうございます(^^)v 最初の部分で、図のようになりましたが、 そのあとだいぶ長いこと、文章化されました。 「medium」になってたので、全部ではない気がしますが、 どこまでできたか、明日検証します。 また、largeも試してみますね。 1日でできるとは思いませんでした。 おかげ様で、少しわかってきました。 ありがとうございます(o*。_。)oペコッ あみ2022/12/23に更新結果をお知らせします。 ・全体のデータは1:46:26 ①mp3アップロードに10分弱 ②文字起こしにMediumで11分、largeで16分でした。 ── 音質がいいとは言えない状況なので、結構、手直しは必要です。 ・largeの原稿をざっと見ましたが、句読点少な目で段落は入れてもらえませんが、 1:39:47の会議が終わるまで、文字起こしされていました。 ・会議が終わったあとの、ザワザワも多少拾っていました。 「お疲れ様」や「お腹が空いた」など。 ・会場が広く多少ガサガサしている部分もあり、音質は良いとは言えなかったのですが、少しマイクから遠い人の発言も精度はなかなか良かったです。(遠すぎる人はダメです) ※ 残る課題は、固有名詞や名前、地域、専門用語、使われている略語など、わかる範囲で登録できるといいなと思いました。あと、たまに飛んでいる部分があり、半角スペースが入っていた感じです。 ── 最終課題は、話者の活舌と録音状態ですね~ 今回は、録音状態あまり良くなかったので、飛ばされている箇所やマイクが遠く聞き取りミスも結構あったのですが、録音状態が良ければ、かなり使えると思います♪ 本当に、ありがとうございました。 最先端をお試しできてメチャクチャうれしいです! とりあえず、ご報告まで。 Kazuki Yonemoto2022/12/23おお!なんとか使えそうなところまで行けたようで良かったです🎉 バッジもありがとうございます!🙇🏻♂️ 返信を追加
あみ2022/12/23に更新ありがとうございます(^^)v 最初の部分で、図のようになりましたが、 そのあとだいぶ長いこと、文章化されました。 「medium」になってたので、全部ではない気がしますが、 どこまでできたか、明日検証します。 また、largeも試してみますね。 1日でできるとは思いませんでした。 おかげ様で、少しわかってきました。 ありがとうございます(o*。_。)oペコッ
あみ2022/12/23に更新結果をお知らせします。 ・全体のデータは1:46:26 ①mp3アップロードに10分弱 ②文字起こしにMediumで11分、largeで16分でした。 ── 音質がいいとは言えない状況なので、結構、手直しは必要です。 ・largeの原稿をざっと見ましたが、句読点少な目で段落は入れてもらえませんが、 1:39:47の会議が終わるまで、文字起こしされていました。 ・会議が終わったあとの、ザワザワも多少拾っていました。 「お疲れ様」や「お腹が空いた」など。 ・会場が広く多少ガサガサしている部分もあり、音質は良いとは言えなかったのですが、少しマイクから遠い人の発言も精度はなかなか良かったです。(遠すぎる人はダメです) ※ 残る課題は、固有名詞や名前、地域、専門用語、使われている略語など、わかる範囲で登録できるといいなと思いました。あと、たまに飛んでいる部分があり、半角スペースが入っていた感じです。 ── 最終課題は、話者の活舌と録音状態ですね~ 今回は、録音状態あまり良くなかったので、飛ばされている箇所やマイクが遠く聞き取りミスも結構あったのですが、録音状態が良ければ、かなり使えると思います♪ 本当に、ありがとうございました。 最先端をお試しできてメチャクチャうれしいです! とりあえず、ご報告まで。
あみ2022/12/23今まで、複数の文字起こしツール試してみましたけど、これが一番早くて素晴らしいです。 今後が楽しみです~ 本当にありがとうございました。今後ともどうぞよろしくお願いします。 返信を追加
あみ2022/12/26に更新こんにちは。段落をつけてみたくて、ChatGPTに相談して、ここまで作ったのですがうまくいきません。output.txtをダウンロードすることまでできましたが、何も変化がありません💦 【Windows 11+Google Colaboratoryです】 追伸 Wordにコピーしたら「\n」がそのまま転写されていたので、 f.write(paragraph + "\n") # 段落ごとに改行する 👇 f.write(paragraph + "^p") # 段落ごとに改行する にしたら、段落ができたものもありますが、できないものも結構あります。 また、行頭のスペースがありませんが、"^p"のあとに" " を追加しただけでは、ダメかな? お時間のあるときに、見ていただけますか? [共有リンク] https://colab.research.google.com/drive/1By-6ZWYIesSxdbmZO07W9tbWLfFREKfN?usp=sharing Kazuki Yonemoto2023/01/05もう見られてるかもですが、こちらの実装方法を参考にいただくのがいいかもしれません。 今あまり時間が取れる状況になく、詳細な回答は難しいです🙏 https://self-development.info/【python】ai音声認識whisperを使ったsrt字幕ファイルの自動作/ あみ2023/01/05ありがとうございます。まだ見ていなかったので参考にさせていただきます。 返信を追加
Kazuki Yonemoto2023/01/05もう見られてるかもですが、こちらの実装方法を参考にいただくのがいいかもしれません。 今あまり時間が取れる状況になく、詳細な回答は難しいです🙏 https://self-development.info/【python】ai音声認識whisperを使ったsrt字幕ファイルの自動作/
みのりん2023/01/04に更新お世話になっております。非エンジニアなのですが、参考にさせていただき、文字起こしの仕組み構築にチャレンジしています。 以下のエラーになってしまうのですが、ご助言いただくことは可能でしょうか? 念のため、model_sizeをlargeとmediumの両方試したのですが、共にエラーになってしまいました。 音声ファイルは約15分の会議音声で153MBです。 PCのスペックは、以下になります。 ・Intel(R) Core(TM) i7-10510U CPU @ 1.80GHz 2.30 GHz ・実装 RAM 16.0 GB (15.8 GB 使用可能) ・システムの種類 64 ビット オペレーティング システム、x64 ベース プロセッサ ・エディション Windows 10 Enterprise Kazuki Yonemoto2023/01/05こちらの実装に変えていただくと、長時間ファイルの読み込みもいけるかもしれません。 コード部分をそのままコピペいただくのが確実かもです。 https://zenn.dev/link/comments/42c1c0a8da8a2f みのりん2023/01/05ありがとうございます! 一応、ご提示くださったリンク先からのコピペだったのですが、エラーになってしまうのですよね。”OutOfMemoryError”という文言があるので、PCのスペックは高い方だと思うのですが、足らないということなのでしょうかね(泣) Kazuki Yonemoto2023/01/06Colaboratoryはクラウド環境で動作するため、利用されているPCのスペック自体が影響することはないかと思います。 一度以下を試してみてください。 「ランタイム>ランタイムを接続解除して削除」をクリック 再度一からライブラリのインストール等を実行 みのりん2023/01/10できました! 本当にありがとうございました!!! 返信を追加
Kazuki Yonemoto2023/01/05こちらの実装に変えていただくと、長時間ファイルの読み込みもいけるかもしれません。 コード部分をそのままコピペいただくのが確実かもです。 https://zenn.dev/link/comments/42c1c0a8da8a2f
みのりん2023/01/05ありがとうございます! 一応、ご提示くださったリンク先からのコピペだったのですが、エラーになってしまうのですよね。”OutOfMemoryError”という文言があるので、PCのスペックは高い方だと思うのですが、足らないということなのでしょうかね(泣)
Kazuki Yonemoto2023/01/06Colaboratoryはクラウド環境で動作するため、利用されているPCのスペック自体が影響することはないかと思います。 一度以下を試してみてください。 「ランタイム>ランタイムを接続解除して削除」をクリック 再度一からライブラリのインストール等を実行
ナルヘッソス2023/07/06記事を参考に文字起こしされたファイルを生成することができました。有意義な情報ありがとうございます。 2点質問があります。 もし分かればで良いので、お手すきの際にでも良いので教えていただけますと幸いです。 (1)なぜ無料なのか? ネットで検索した情報によりopen.ai のサイトで、有料登録を行い、apiキーを手に入れました。api経由で同様の処理を行った場合は従量課金されるようですが、このgoogle colabを用いた方法では、colabの環境上にインストールして処理を行うため無料ということなのでしょうか?apiへの課金が必要と思ってopen.aiのサイトにカード登録しましたが、この方法で文字起こしが無料で実行できるなら必要ないなと思っています。 (2)録音ファイルの扱い google colab 上にアップロードした音声ファイル自体は、あくまでcolab環境のみにストレージされるのみで、open.ai側には渡っていないと思っておいてよいでしょうか?colabに環境構築して実行しているのであくまでcolabのみに留まっている認識です。(試そうとしている音声ファイルがopen.ai 側にも渡ってもし万が一、流出したら嫌だなと思い・・・) Kazuki Yonemoto2023/07/07に更新(1)なぜ無料なのか? はい、こちら書いてもらってある通りです。モデルはMITライセンスでオープンソースで公開されているのと、本来はモデルがあったとしてもそれを動かした際、確実にコストはかかっているのですが、Googleさんが寛大にも無料である程度使えるようにしてくれているために実現できています。 このgoogle colabを用いた方法では、colabの環境上にインストールして処理を行うため無料ということなのでしょうか? https://github.com/openai/whisper https://colab.research.google.com/signup/pricing?utm_source=dialog&utm_medium=link&utm_campaign=settings_page&hl=ja (2)録音ファイルの扱い これもOpenAIのリソースは利用していないので、認識の通りです。 アップロードした音声ファイル自体は、あくまでcolab環境のみにストレージされるのみで、open.ai側には渡っていないと思っておいてよいでしょうか? 返信を追加
Kazuki Yonemoto2023/07/07に更新(1)なぜ無料なのか? はい、こちら書いてもらってある通りです。モデルはMITライセンスでオープンソースで公開されているのと、本来はモデルがあったとしてもそれを動かした際、確実にコストはかかっているのですが、Googleさんが寛大にも無料である程度使えるようにしてくれているために実現できています。 このgoogle colabを用いた方法では、colabの環境上にインストールして処理を行うため無料ということなのでしょうか? https://github.com/openai/whisper https://colab.research.google.com/signup/pricing?utm_source=dialog&utm_medium=link&utm_campaign=settings_page&hl=ja (2)録音ファイルの扱い これもOpenAIのリソースは利用していないので、認識の通りです。 アップロードした音声ファイル自体は、あくまでcolab環境のみにストレージされるのみで、open.ai側には渡っていないと思っておいてよいでしょうか?

Discussion
とても有益な投稿で助かりました!
すばらしい情報ありがとうございます!
さっそく使用してみて恐縮ですが、最後のファイルにした際のテキストを、
文字列ごとに改行することは可能なのでしょうか?
現状、全てつながっている状況です。
プログラミング無知なためご教授いただけると幸いです。
読んでいただきありがとうございます!
別記事で恐縮ですが、こちらで解説されてるような改行処理をやってみるのがいいかもですね。
ありがとうございます!
早速試してみたいと思います。
初めまして、非エンジニアですが、Whisperをどうしても使いたくて
Google Colaboratoryに挑戦中です。
最終段階までできて、txtをダウンロードしてみたら、
画像のようになりました。
▼ Transcription of test.MP3
スタッフの上に、スタッフの上に、スタッフの上に、……
音声ファイルは会議で1時間以上のものです。
どうすればいいのか教えていただけないでしょうか?
記事を読んでいただきありがとうござます。
記載いただいた要件ですと、以下記事を参考にしていただくのが良いかもしれません。同じワードがループしてしまう際の対処も少し紹介されています。
ありがとうございます。
読ませていただきます。
このページのサンプルをコピーさせていただいて、使用しております。
12 mel = whisper.log_mel_spectrogram(audio).to(model.device)
の下に、
result = model.transcribe(audio, verbose=True, temperature=0.8, language=lang)
を追加しました。
temperatureの数値を0.6~1.2ぐらいに変更してみましたが、
0.8が一番合っているような感じですが、やはり26秒ぐらいしか
文字起こしができませんでした。
しかも、日本語には見えますが、話している話題とはだいぶ違う感じでした。
句読点が入っているのがちょっとうれしいです。
やはりGoogle Colaboratoryでは、30秒ぐらいが限界ですか?
文字起こしを以下のようにループ処理にしてみると、30秒以上の音声にも対応できるかもしれません。1時間の音声では試せていないですが、数分程度であれば書き出せました。
ビックリしました~そんなことまで簡単にできてしまうのですね。
私は、ファイルを30秒ごとに分割して・・・
なんてカメの思考でおりました。ぜひ、試してみます。
ところで、こんな記事があります。この方は14分ほど
起こしをされているようですね。
ChatGPTの案が役に立つとは思いませんでした(^^;
冗談かと思いました。。。
厳密にいうと30秒毎に処理が切れてしまうので、途切れたタイミングで残りが0になるまで処理を繰り返しているイメージです。
outputTextsArrの配列へ追加outputTextsArrに格納されたの要素を全て連結ChatGPTに聞いてみたらこんなお答えでした💦 あまり役には立たないかな?

↑のスレッドで返信しています。
やった内容としては 1. の対応に近いですかね。🤔
ありがとうございます(^^)v
最初の部分で、図のようになりましたが、
そのあとだいぶ長いこと、文章化されました。
「medium」になってたので、全部ではない気がしますが、
どこまでできたか、明日検証します。
また、largeも試してみますね。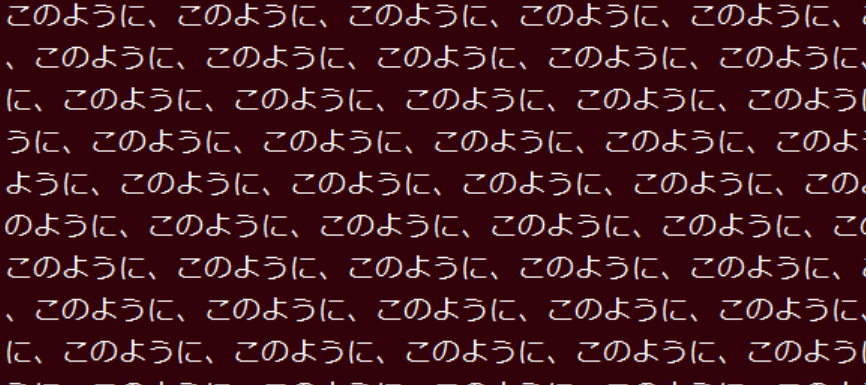
1日でできるとは思いませんでした。
おかげ様で、少しわかってきました。
ありがとうございます(o*。_。)oペコッ
結果をお知らせします。
・全体のデータは1:46:26
①mp3アップロードに10分弱
②文字起こしにMediumで11分、largeで16分でした。
── 音質がいいとは言えない状況なので、結構、手直しは必要です。
・largeの原稿をざっと見ましたが、句読点少な目で段落は入れてもらえませんが、
1:39:47の会議が終わるまで、文字起こしされていました。
・会議が終わったあとの、ザワザワも多少拾っていました。
「お疲れ様」や「お腹が空いた」など。
・会場が広く多少ガサガサしている部分もあり、音質は良いとは言えなかったのですが、少しマイクから遠い人の発言も精度はなかなか良かったです。(遠すぎる人はダメです)
※ 残る課題は、固有名詞や名前、地域、専門用語、使われている略語など、わかる範囲で登録できるといいなと思いました。あと、たまに飛んでいる部分があり、半角スペースが入っていた感じです。
── 最終課題は、話者の活舌と録音状態ですね~
今回は、録音状態あまり良くなかったので、飛ばされている箇所やマイクが遠く聞き取りミスも結構あったのですが、録音状態が良ければ、かなり使えると思います♪
本当に、ありがとうございました。
最先端をお試しできてメチャクチャうれしいです!
とりあえず、ご報告まで。
おお!なんとか使えそうなところまで行けたようで良かったです🎉
バッジもありがとうございます!🙇🏻♂️
今まで、複数の文字起こしツール試してみましたけど、これが一番早くて素晴らしいです。
今後が楽しみです~ 本当にありがとうございました。今後ともどうぞよろしくお願いします。
こんにちは。段落をつけてみたくて、ChatGPTに相談して、ここまで作ったのですがうまくいきません。output.txtをダウンロードすることまでできましたが、何も変化がありません💦
【Windows 11+Google Colaboratoryです】
追伸 Wordにコピーしたら「\n」がそのまま転写されていたので、
f.write(paragraph + "\n") # 段落ごとに改行する
👇
f.write(paragraph + "^p") # 段落ごとに改行する
にしたら、段落ができたものもありますが、できないものも結構あります。
また、行頭のスペースがありませんが、"^p"のあとに" " を追加しただけでは、ダメかな?
お時間のあるときに、見ていただけますか? [共有リンク]
もう見られてるかもですが、こちらの実装方法を参考にいただくのがいいかもしれません。
今あまり時間が取れる状況になく、詳細な回答は難しいです🙏
ありがとうございます。まだ見ていなかったので参考にさせていただきます。
お世話になっております。非エンジニアなのですが、参考にさせていただき、文字起こしの仕組み構築にチャレンジしています。
以下のエラーになってしまうのですが、ご助言いただくことは可能でしょうか?
念のため、model_sizeをlargeとmediumの両方試したのですが、共にエラーになってしまいました。
音声ファイルは約15分の会議音声で153MBです。
PCのスペックは、以下になります。
・Intel(R) Core(TM) i7-10510U CPU @ 1.80GHz 2.30 GHz
・実装 RAM 16.0 GB (15.8 GB 使用可能)
・システムの種類 64 ビット オペレーティング システム、x64 ベース プロセッサ
・エディション Windows 10 Enterprise
こちらの実装に変えていただくと、長時間ファイルの読み込みもいけるかもしれません。
コード部分をそのままコピペいただくのが確実かもです。
ありがとうございます!
一応、ご提示くださったリンク先からのコピペだったのですが、エラーになってしまうのですよね。”OutOfMemoryError”という文言があるので、PCのスペックは高い方だと思うのですが、足らないということなのでしょうかね(泣)
Colaboratoryはクラウド環境で動作するため、利用されているPCのスペック自体が影響することはないかと思います。
一度以下を試してみてください。
できました!
本当にありがとうございました!!!
記事を参考に文字起こしされたファイルを生成することができました。有意義な情報ありがとうございます。
2点質問があります。
もし分かればで良いので、お手すきの際にでも良いので教えていただけますと幸いです。
(1)なぜ無料なのか?
ネットで検索した情報によりopen.ai のサイトで、有料登録を行い、apiキーを手に入れました。api経由で同様の処理を行った場合は従量課金されるようですが、このgoogle colabを用いた方法では、colabの環境上にインストールして処理を行うため無料ということなのでしょうか?apiへの課金が必要と思ってopen.aiのサイトにカード登録しましたが、この方法で文字起こしが無料で実行できるなら必要ないなと思っています。
(2)録音ファイルの扱い
google colab 上にアップロードした音声ファイル自体は、あくまでcolab環境のみにストレージされるのみで、open.ai側には渡っていないと思っておいてよいでしょうか?colabに環境構築して実行しているのであくまでcolabのみに留まっている認識です。(試そうとしている音声ファイルがopen.ai 側にも渡ってもし万が一、流出したら嫌だなと思い・・・)
(1)なぜ無料なのか?
はい、こちら書いてもらってある通りです。モデルはMITライセンスでオープンソースで公開されているのと、本来はモデルがあったとしてもそれを動かした際、確実にコストはかかっているのですが、Googleさんが寛大にも無料である程度使えるようにしてくれているために実現できています。
(2)録音ファイルの扱い
これもOpenAIのリソースは利用していないので、認識の通りです。
当方の返事が遅くなり申し訳ありません。回答いただいた内容で疑問点が解消できました。
ご丁寧に回答くださりありがとうございました。感謝いたします。