🥃
OpenAI Whisperに音声データを全文書き起こしさせる【Google Colaboratory】
OpenAIの「Whisper」を試してみていたのですが、Pythonで音声データを全文書き起こしする方法があまり情報がなかったため、備忘録です。
(手軽に試せるデモだと30秒程度までしか認識してくれません)
Whisper
「Whisper」は、OpenAIが開発した、会話音声をテキストに変換する深層学習モデルです。
多様な音声の大規模データセットで学習され、音声翻訳や言語識別だけでなく、多言語音声認識を行うことができるマルチタスクモデルでもあります。
(細かくは調べていないですが、音声を元にしてTransformerなどの自然言語処理技術で文章を生成する、という認識の方が近いかもしれません)
Colabでの実行
Colabでの実行の、基本的な実装は以下を参照してください。
この中の文字起こし処理部分の実装を変更します。
全文書き起こしを行う
Whisperの内部関数として、書き起こし用の関数model.transcribeが実は用意されています。
これをColabで実行することで、全文書き起こしが行なえます。
最終結果はdict型で返ってくるため、必要な情報を加工して保存します。
(自分で実験している最中に、同じ単語を繰り返して崩壊する現象が起きてしまったため、temperatureの値を0.8に変更していますが、音声によって適宜変更してください)
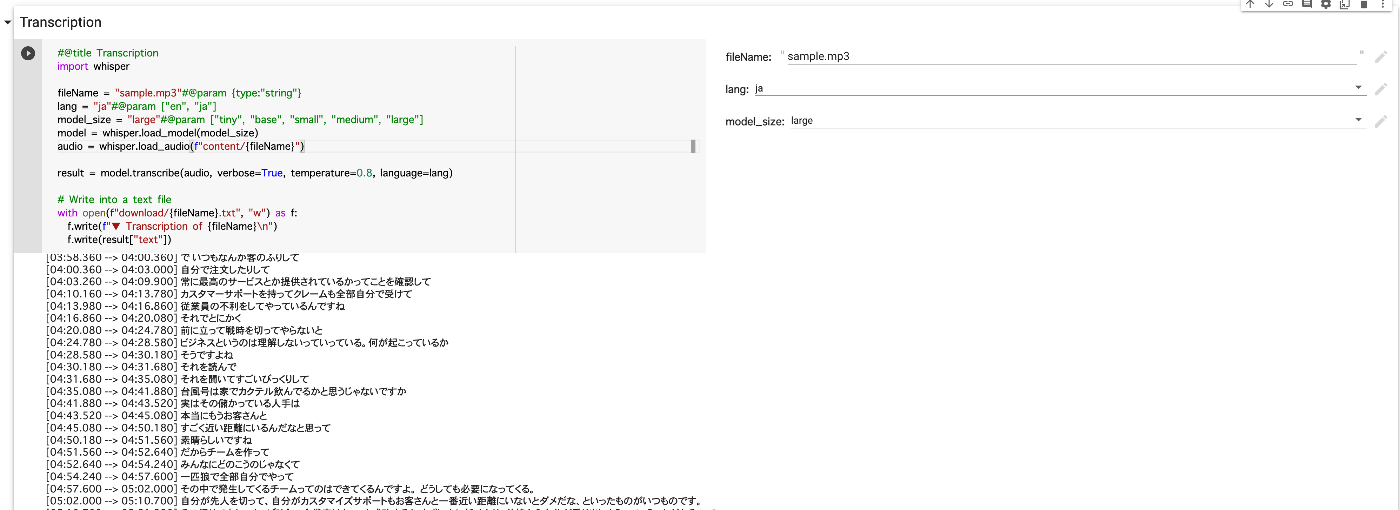
#@title Transcription
import whisper
fileName = "sample.mp3"#@param {type:"string"}
lang = "ja"#@param ["en", "ja"]
model_size = "large"#@param ["tiny", "base", "small", "medium", "large"]
model = whisper.load_model(model_size)
audio = whisper.load_audio(f"content/{fileName}")
result = model.transcribe(audio, verbose=True, temperature=0.8, language=lang)
# Write into a text file
with open(f"download/{fileName}.txt", "w") as f:
f.write(f"▼ Transcription of {fileName}\n")
f.write(result["text"])
Discussion
こういうエラーが出てしまうのですが、どうすればいいでしょうか?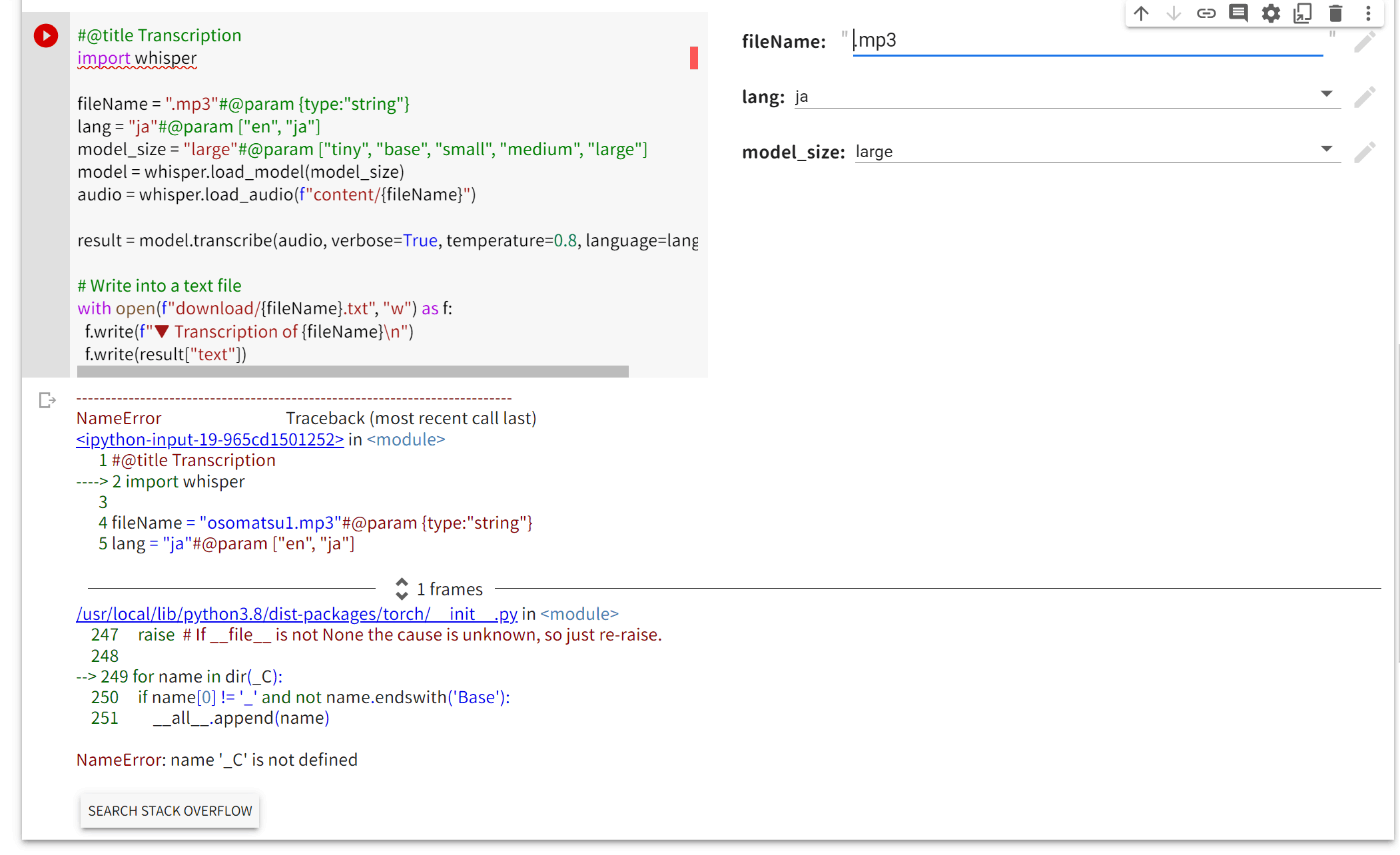
回答として合っているかはわからないのですが、このエラーはCythonがインストールされていない時によく見るエラーな気がしてます。
!pip install Cythonを実行してもらうと解決するかもしれません。