緯度経度データの検索・処理をいつもやっている (情報検索・検索技術 Advent Calendar 2023)
本記事は情報検索・検索技術 Advent Calendar 2023の13日目の記事です。
最近Overtureのデータを触っていて、何回も同じ処理を書いていて頭がダメな感じなので、将来の自分のために処理をメモするために書いています。
特にライブラリをチョロっと使うだけの簡単な処理を書きました。
せっかくなので、これまでの細々とやっていた記事も宣伝しておきます。
設定
どこかから処理してきたCSVに格納されている位置情報データ (lat, lon, 他のデータ) を扱いたいです。
サンプルデータは この記事 で作ってきた 27 万行ぐらいのPlaceデータです。領域としては東京都(離島を除く)データなので、メモリに乗りそうです。
日本全域だとどうでしょうか(乗りそうな気がしています)。Overtureの世界単位だと、乗らなさそうなので、ディスクに置いたり index を計算したりすることになりそうです。
また pandas じゃないものがいいかもしれないです (polar とか)。
今回は pandas と GeoPandas くんでいきます。
データの雰囲気はこういうやつです (上の記事から引用しました。ファイル名 data/tokyo.csv です)。
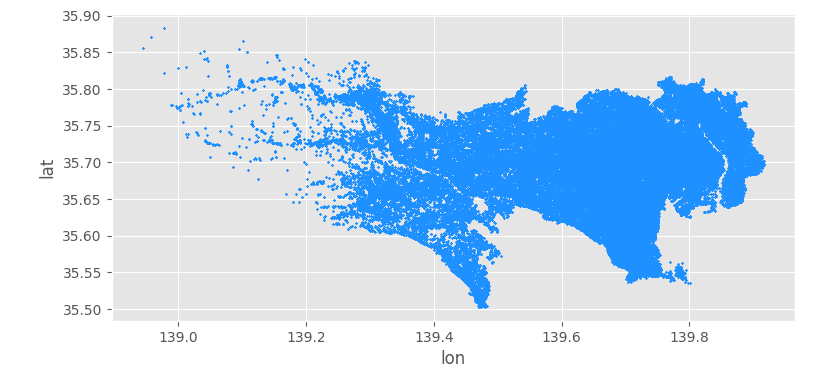
例
いろんな処理をやってみます。
例1: ある緯度経度の周辺を個数を指定して検索する
近傍処理です。
もちろん10万行単位ぐらいの DataFrame で普通に検索してもいいですが、scipy の KDTree はいろんな環境で使えるので良いです。 10万行ぐらいだと、pickle化しなくても毎回計算しても待てます(個人差があります)。現代でKDTreeなんて高次元に使うな!という怒られが発生しそうですが、3次元 (lat, lon, あと1つ) ぐらいまでなら特に気にしなくていいと信じています。
import random
import numpy as np
import pandas as pd
from scipy.spatial import KDTree
df = pd.read_csv("data/tokyo.csv", delimiter=",")
coords = df[["lon", "lat"]].to_numpy()
tree = KDTree(coords)
# ある点中心に10個取ってくる
sample_index = np.random.randint(0, df.shape[0])
random_row = df.iloc[sample_index]
random_query = np.array([random_row.lon, random_row.lat])
_, index = tree.query(random_query, k=10)
大変よく使う構文です。
注意点はKDTreeに与えるデータのサイズ The n data points of dimension m to be indexed. というぐらいでしょうか。
他のパラメータは ドキュメントを見て 設定したければすると良いでしょう。
使ってみた例の可視化です。上の全データのうち、一部だけ拡大しています。中央にある青い☓がランダムサンプルしたクエリした点で、周りの赤い点がクエリ点含めて10個出力されている様子です。
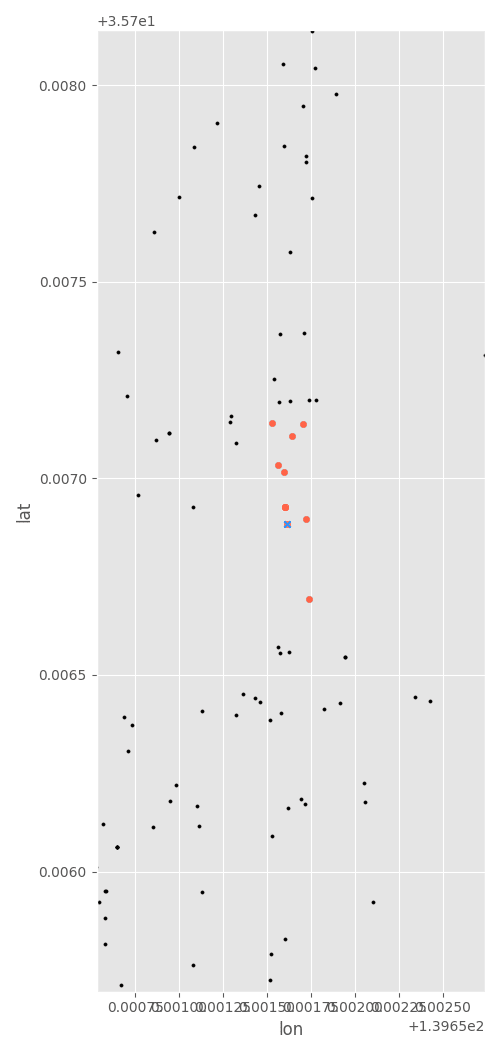
例2: ある緯度経度の周辺を距離を指定して検索する
例1の拡張版ですが、よく考えたら個数じゃなくて、ある地点からの距離で検索したい場合が多いですね。
ただし、持っている緯度経度は適当に射影座標なので、数値上の緯度経度で計算される距離と実世界距離の間には微妙な乖離があることに注意です。厳密な議論は難しいですが、要するに、個数ではなくボール型っぽくクエリするということです (普通のユークリッド距離をイメージ)。
# (上の続き)
sample_index = np.random.randint(0, df.shape[0])
random_row = df.iloc[sample_index]
random_query = np.array([random_row.lon, random_row.lat])
# r=0.0005を指定
index = tree.query_ball_point(random_query, r=0.0005)
これもよく使います。

円っぽく取れていることがわかります。
真円にならない理由とか座標の話を真面目に知りたい場合は、こちらの本を読んでください。いい本でした(投げやり)。いずれにしても、厳密な円がどうしても必要な場合はともかく、POI検索などの用途では簡易的にはかなり使えます (多少円っぽくなくても気づかないので)。
例3: 近くにあるデータをまとめて取得する (pair, pair-tree)
これは今回のACのネタを考えているときに見つけました。地点間のペアについて指定した距離以下の組を取得することができます。例を見ると分かりやすいと思います。
ここでは、カテゴリがpubのデータに絞って使ってみます。
# importは省略
# KDtree構築
df = pd.read_csv("data/tokyo.csv", delimiter=",")
df = df[df.cat == "pub"]
coords = df[["lon", "lat"]].to_numpy()
tree = KDTree(coords)
# 距離 1e-3 (0.001) のペアを取得
pairs = tree.query_pairs(r=1e-3)
# 可視化 (一部)
## (W, H) の縮尺を散布図に揃える
W = 7
H = (
W
* (coords[:, 1].max() - coords[:, 1].min())
/ (coords[:, 0].max() - coords[:, 0].min())
)
f = plt.figure(figsize=(W, H))
a = f.gca()
# pubの位置と1e-3ペア
df.plot.scatter(x="lon", y="lat", ax=a, marker=".", color="k", s=20)
for i, j in pairs:
a.plot(coords[[i, j], 0], coords[[i, j], 1], "r-", lw=3)
このようになります。

赤くなっているところがペアとして得られた場所です。
matplotlibで拡大してみるとこのようになっています。pubが固まっている場所が見えるわけですね。
東京に地縁がある人だと、だいたいどの塊がどの駅になっているか分かるかもしれません。例えばpairが欲しいだけだと、queryを使って自分で辞書を作らなくても、pairを経由してお店のつながりを作れそうですね。

この query_pairs ですが、2つのKDtreeを受け取った場合にも使える面白い関数が query_ball_tree です。そのままの名前ですが…。
例えば bar カテゴリの木を tree1、japanese restaurant カテゴリの木が tree2 であったとします。すると、バーと日本食レストランのペアのうち距離が近いものを探してこれます。はしごするのに使えそうですね。
df = pd.read_csv("data/tokyo.csv", delimiter=",")
tree1 = build_tree_by_cat(df, "bar")
tree2 = build_tree_by_cat(df, "japanese_restaurant")
coords1 = tree1.data
coords2 = tree2.data
# bar と japanese_restaurant の木同士でペア計算
indexes = tree1.query_ball_tree(tree2, 1e-4)
# 可視化部分 (手抜き)
TOKYO_STATION_LAT = 35.681236
TOKYO_STATION_LON = 139.767125
EPS = 1e-3
W = 5
H = W
f = plt.figure(figsize=(W, H))
a = f.gca()
for i in range(len(indexes)):
for j in indexes[i]:
a.plot(
[coords1[i, 0], coords2[j, 0]],
[coords1[i, 1], coords2[j, 1]],
"k--",
lw=1,
alpha=0.25,
)
a.scatter(coords1[:, 0], coords1[:, 1], marker="x", color="k", s=30, alpha=1)
a.scatter(coords2[:, 0], coords2[:, 1], marker="o", color="tomato", s=30, alpha=1)
plt.tight_layout()
a.set_xlim(TOKYO_STATION_LON - EPS, TOKYO_STATION_LON + EPS)
a.set_ylim(TOKYO_STATION_LAT - EPS, TOKYO_STATION_LAT + EPS)
東京駅周辺を拡大したときの結果です。◯と☓でペアができていますね。はしごしに行きましょう。

残念ながらそんなに高速ではないです。
例4: 矩形で処理したい (R木)
R木ですが、たぶんlibspatialindexに入っているやつのラッパーが使いやすいのかもしれません。ここではrtreelibを使ってみました。このrtreelibが存在することは、こちらのブログ記事で知りました (著者に感謝します)。まぁpure Pythonにこだわる必要はない気もしますが、pip installだけでインストールできるので場合によっては使えると思います。
まずは木を構築する方です。eps=1e-8 の適当な矩形に突っ込んでます (たぶん、isolationできているはず、考えてないですが…)。
import rtreelib
df = pd.read_csv("data/tokyo.csv", delimiter=",")
eps = 1e-8
root = RTree()
for idr, row in df.iterrows():
# min(x), min(y), max(x), max(y) の矩形を木の葉にして挿入
mbr = Rect(row.lon - eps, row.lat - eps, row.lon + eps, row.lat + eps)
root.insert(idr, mbr)
with open("example.index", "wb") as fp:
pickle.dump(root, fp)
次にクエリを投げるほうです。適当な矩形で検索してみます。
# example.index に pickle化したR木が入っているとする
def search_index(path: str = "example.index") -> None:
tree = pickle.load(open(path, "rb"))
print(tree)
# 東京タワーの1e-4あたりを探索
TT_LAT = 35.681236
TT_LON = 139.767125
EPS = 1e-3
TBOX = (
TT_LON - EPS,
TT_LAT - EPS,
TT_LON + EPS,
TT_LAT + EPS,
)
hits = tree.query(TBOX)
あとは中身を可視化する部分です。
# 可視化のために全データ
df = pd.read_csv("data/tokyo.csv", delimiter=",")
# クソすぎるfor文
plot_list_lon = []
plot_list_lat = []
for elem in hits:
plot_list_lon.append(df.iloc[elem.data].lon)
plot_list_lat.append(df.iloc[elem.data].lat)
f = plt.figure()
a = f.gca()
a.scatter(df.lon.to_numpy(), df.lat.to_numpy(), marker="o", alpha=0.5, c="k", s=10)
a.scatter(plot_list_lon, plot_list_lat, marker="o", s=20, color="tomato")
a.scatter([TT_LON], [TT_LAT], lw=2, marker="x", c="k", s=20)
# plot BB
a.plot([TT_LON - EPS, TT_LON + EPS], [TT_LAT - EPS, TT_LAT - EPS], c="k")
a.plot([TT_LON + EPS, TT_LON + EPS], [TT_LAT - EPS, TT_LAT + EPS], c="k")
a.plot([TT_LON - EPS, TT_LON + EPS], [TT_LAT + EPS, TT_LAT + EPS], c="k")
a.plot([TT_LON - EPS, TT_LON - EPS], [TT_LAT + EPS, TT_LAT - EPS], c="k")
a.set_xlim(TT_LON - 2 * EPS, TT_LON + 2 * EPS)
a.set_ylim(TT_LAT - 2 * EPS, TT_LAT + 2 * EPS)
plt.tight_layout()
plt.show()
plt.close()
このようになります。東京タワーを中心に、矩形処理できていますね (R木の説明は放棄していますが…)。

KD木とR木について真面目に知りたい人はインターネットサーフィンしてください…。
例5: シェープファイル (shp) で処理したい
矩形とか円でフィルタする場合は pandas とデータ構造だけでなんとかなりますが、今のところ、都道府県ポリゴンなどの shp ファイルなどから読めるポリゴンを使ったフィルタを簡単にかけられるか、よくわかりません。
というか簡単には思いつきませんでした。これまでどうやって処理してたかというと、実は普通に for 文でやって、寝ている間に処理してもらっていました。ただOverture データのサイズで for 文すると時間がかかってNGです。
ちょっと調べたら GeoPandas の空間ジョイン (sjoin) で簡単に実装できたので、今度はこれを使おうと思っています。とりあえず実装だけを紹介します。ただ、上の座標系の話と関連しますが、厳密に座標のズレが気になる場合には、ちゃんと注意して使いましょう。今回は例題のために、東京都のシェープファイルのgeojsonファイルから文京区を使っています。
ちょっと試した限り、2点に気をつけたら最低限のフィルタは適用できそうです。
- 両方の入力を GeoDataFrame にする
- 両方の CRS を揃える
import pandas as pd
import geopandas as gpd
from geopandas.tools import sjoin
# 文京区の GeoDataFrame を作成 (geojsonはどこからかダウンロードしてきて…)
gdf_shape = gpd.read_file("./data/N03-21_13_210101.geojson")
gbunkyo = gdf_shape[gdf_shape["N03_004"] == "文京区"]
# 文京区の GeoDataFrame のCRSに合わせて東京のPlaceデータを変換
# 変換するときに、DataFrameの (lon, lat) をgeometryデータに付与
df = pd.read_csv("./data/tokyo.csv")
gdf = gpd.GeoDataFrame(
df, geometry=gpd.points_from_xy(df.lon, df.lat), crs="epsg:6668"
)
# 空間ジョイン (ついでに一緒につく余計な列は消しておく)
res = sjoin(gdf, gbunkyo)
res = res[gdf.columns]
# 可視化
f = plt.figure()
a = f.gca()
gbunkyo.plot(ax=a, color="k", alpha=0.25)
a.scatter(res.lon, res.lat, marker="x", c="k", s=5)
a.xaxis.set_major_formatter(FormatStrFormatter("%.3f"))
a.yaxis.set_major_formatter(FormatStrFormatter("%.3f"))
結果はこのように、区のポリゴンに合わせたデータが抽出できました。
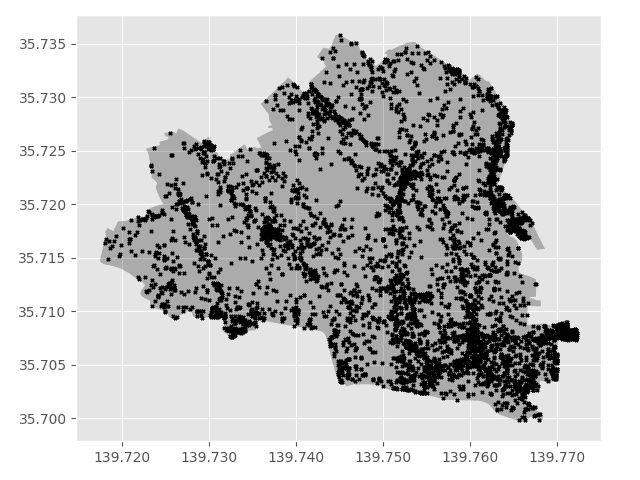
KD木のpairとかに比べるとかなり高速で使える気持ちだったので、10万単位のデータだと気軽に使って良さそうです。インターネットサーフィンをしていると、ギリ 1M までは使えそうです。
ヨーロッパ全土の処理、とかだとムズいかも…。
例6: bounding boxの処理
これは最近学んだのでオマケで書いておきます。
地図情報処理していてメッシュとかgeometryのエンコードとかはよく使って世の中に記事があるのでいいですが、もっと雑に「あるbounding box (west-south-east-northの箱) 周辺をイテレーションしたい」みたいなのがたまにあります。自分で書くのも微妙かなーと思っていたら、pythonのmercantileというライブラリがあって便利だったので使用例を紹介します。
Mercantile is a module of utilities for working with XYZ style spherical mercator tiles (as in Google Maps, OSM, Mapbox, etc.) and includes a set of command line programs built on these utilities.
メルカトルとタイルのシャレなのかなと思っているのですが、真実は知りません。
コードサンプルはチュートリアルからもってきました。あるbounding box (赤色) を包むタイル (黒色) をイテレーションできるようになります。
import mercantile
import matplotlib.pyplot as plt
plt.style.use("ggplot")
# 対象のBB
east, south, west, north = [-79.546171, 8.948970, -79.528040, 8.956771]
Z = 16
all_box = mercantile.LngLatBbox(west, south, east, north)
tiles = list(mercantile.tiles(east, south, west, north, Z))
bbox_list = [mercantile.bounds(tile.x, tile.y, tile.z) for tile in tiles]
def plot_box(a, bbox, c: str = "k", txt: str = "", lw: int = 1) -> None:
# bbox: [east, south, west, north]
e, s, w, n = bbox.east, bbox.south, bbox.west, bbox.north
a.plot([e, e], [s, n], lw=lw, c=c)
a.plot([e, w], [n, n], lw=lw, c=c)
a.plot([w, w], [s, n], lw=lw, c=c)
a.plot([e, w], [s, s], lw=lw, c=c)
if len(txt) > 0:
a.text((e + w) / 2, (s + n) / 2, txt, ha="center", va="center")
f = plt.figure()
a = f.gca()
plot_box(a, all_box, c="r", lw=3)
for ib, bbox in enumerate(bbox_list):
plot_box(a, bbox, txt=f"{ib}")
このように全体タイルを包む解像度(Z)のタイルでイテレーションできます。
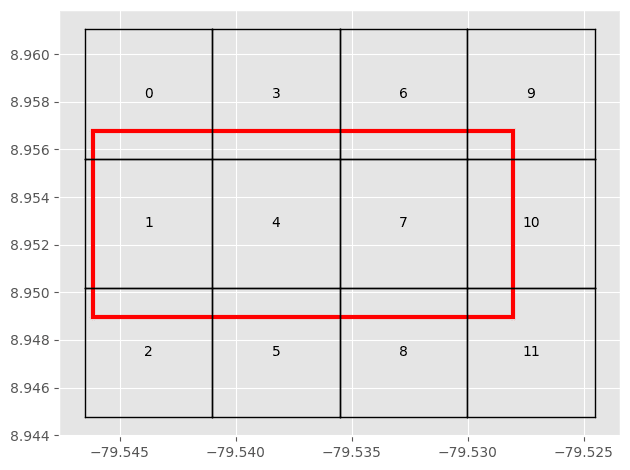
いろいろ面白い関数もあって、たとえばある箱 (e.g., 4) を更に分割した子領域を見る、みたいなこともできます。
# 4番目の箱の部分で子を見る
for ib, bbox in enumerate(bbox_list):
plot_box(a, bbox, txt=f"{ib}")
if ib == 4:
# bbox の子供タイルの計算
center_w = (bbox.east + bbox.west) / 2
center_h = (bbox.south + bbox.north) / 2
tile = mercantile.tile(center_w, center_h, Z)
bbox_list = [
mercantile.bounds(tile.x, tile.y, tile.z)
for tile in mercantile.children(tile)
]
for icb, cb in enumerate(bbox_list):
plot_box(a, cb, txt=f"{ib}-{icb}", c="b")

再帰処理が簡単にできそうですね!
まとめ
毎回調べて書くのさすがにダメなので、自分のために書きました。地味にmatplotlibとかも毎回調べるので、いい加減毎回調べるのやめたいと思っています。
- Q. 今まで (著者が) O(N) で for回してたのがおかしいのでは?
- A.
はいまぁ 0.1M ぐらいのサイズだとすぐ終わるので…。- あと、どうせ処理再開・中断をサポートするために、適当にpickleしたり中間データ書き出したりするので…
- Q. どうせ100Mとかになったらメモリ乗らないのでは…?
- A. どっちにしろ分割しないとメモリに乗らないので…
- Q. データベースとかは使わないの?
- A. 知らん (使えない)
- (自問自答が続く)
ソースコードはそのうち整理しておきます (来年まで…)。
Discussion