Overture Maps Foundationのデータを活用したい (2): Placesデータの抽出と可視化
はじめに
Overture Maps Foundationというものがあります。前回、位置データ (Placesデータ) をダウンロードし、中身を確認できたけど、うまくPandasのDataFrameに変換できなくて詰まっていました。
こちらの記事では、データの整形をやってみた結果をまとめます。
データの再確認
Schemeの再確認
前回の記事でも言及した通り、データの中身は Scheme のレポジトリに情報が書かれています。今回は位置データの名前やカテゴリ・位置(緯度経度)などに興味があるということで、データを頑張って読み込んでいきます。
再度、yamlファイルを確認してみます。
↑のyamlファイルに書かれたpropertiesを上から読んでいくと、以下のような情報が読めそうです。
- 名前:
properties -> namesstringが入っていそう - カテゴリ:
properties -> categoriesstringが入っていそう - 位置情報:
geometrygeojsonのPointで入っていそう (https://geojson.org/schema/Point.json)
具体的な値の確認
また、pyarrow を使ってデータを読み込んだ前回の例を思い出して列名を確認してみると、次のようなデータが読めそうなことがわかります。位置情報を見る際には、bounding box (bbox) も使えそうですね。
import pyarrow.parquet
# 20230725_... はダウンロードしたものの1つ
table = pyarrow.parquet.read_table("20230725_210643_00079_ayc64_01c760ca-02aa-4387-8b71-b2eaa6c7c700")
print(table.column_names)
# 実行結果
['id',
'updatetime',
'version',
'names',
'categories',
'confidence',
'websites',
'socials',
'emails',
'phones',
'brand',
'addresses',
'sources',
'bbox',
'geometry']
位置情報を確認するため、0行目のデータのgeometryとbboxを確認してみます。Python側で処理するときには、pyarrowのデータ型を通常のpythonのデータ型に戻すためにas_py()を使っています。
print(table["geometry"][0].as_py())
# 実行結果
b'\x01\x01\x00\x00\x00\x92!\xc7\xd63\xb4\x10\xc0d\xb1M*\x1a\x9bJ@'
print(table["bbox"][0].as_py())
# 実行結果
{'minx': -4.175979, 'maxx': -4.175979, 'miny': 53.211736, 'maxy': 53.211736}
ここまでの結果を見ると、geometry のデータは後処理が必要そうですが、bbox のデータはそのまま緯度経度 (bboxの情報を使うことにします。
東京データ (島含まない) の作成
ダウンロードしてきたデータをテーブルで読むとき、名前・カテゴリ・緯度経度などを取得できそうなことが分かりました。
元データを活用する例として、全データについて東京都内(島を含まない)の位置データを抽出してみようと思います。東京都内の判定には、以前作ったshpファイルを用いて、緯度経度が領域に含まれるかどうかを判定することにします。
全体処理は以下の3ステップで実装しました。
- 各 parquet ファイルから東京都内の位置データのインデクスを取得する
- 各 parquet ファイルの残ったインデクスからCSVファイルを作成する
- 全データのCSVファイルを結合する
それぞれ簡単に説明します。
処理1. 各 parquet ファイルから東京都内の位置データのインデクスを取得する
まずは以下の処理によって行番号 (index) を保存します。
- すべてのparquetファイルについて、各行の緯度経度を
bboxから取得する - 取得した点がshpファイルの内部に含まれていれば保存する
あるファイルを処理し、残った位置情報から散布図を打った例はこちらです。だいたい東京都内のデータが抽出できていることが分かります。

処理2. 各 parquet ファイルの残ったインデクスからCSVファイルを作成する
どの行が都内のデータかを先に処理して保存したので、後はCSVファイルを作れば良いです。読み込んだデータから名前を取得する部分が雑な実装になってしまっていますが、このような処理を動かして待っていればそのうち終わります。
# 名前などにカンマが入ったり区切りが難しそうなので、""と;で装飾する
# 緯度経度はbboxの(x, y)で代用する
with codecs.open(fn_table, "w", encoding="utf-8") as ff:
ff.write('"name";"cat";"lon";"lat"\n')
for i in tqdm(idx):
data_i = {}
for j in table.column_names:
data_i[j] = table[j][i].as_py()
name_i = data_i["names"][0][1][0][0][1]
cat_i = data_i["categories"]["main"]
lon_i = data_i["bbox"]["minx"]
lat_i = data_i["bbox"]["miny"]
ff.write(f'"{name_i}";"{cat_i}";"{lon_i}";"{lat_i}"\n')
変な処理を書いた原因ですが、データがこのようなものだったからです (このような入れ子構造があるので、pyarrowの処理でpandasに変換できなかったわけですね)。

このあたりのパースはまともに書く方法がある気もします (考えてないです)。
処理3. 全データのCSVファイルを結合する
これは処理2で作った個別のCSVをpandasでconcatし、CSVに出力するだけです。
作成したデータ
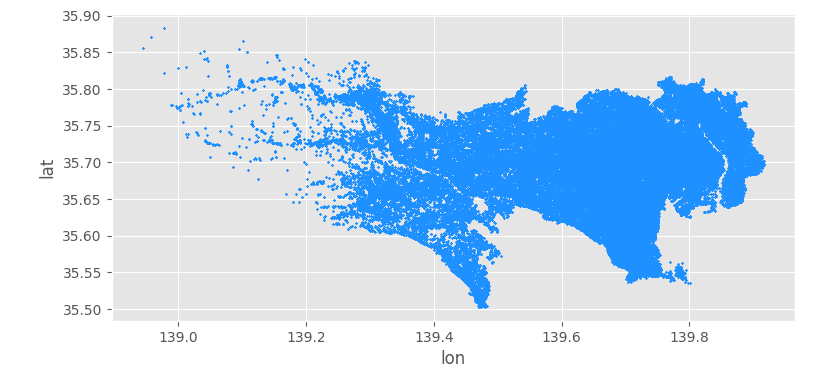
全データを処理した結果、276739 行のCSVファイルを作ることができました 💪 散布図を描くと、以下のようになりました。
ついでに、カテゴリの上位を棒グラフで見てみます。
import pandas as pd
import matplotlib.pyplot as plt
plt.style.use("ggplot")
# 作成したデータが tokyo.csv
df = pd.read_csv("tokyo.csv")
f = plt.figure()
a = f.gca()
df["cat"].value_counts().nlargest(30).plot(kind="bar", ax=a)
plt.tight_layout()
plt.show()
作成したグラフです。Noneも残ってしまっていますが、そこそこカテゴリがついているように見えますね。日本食レストラン・カフェ・バー・レストランなどが上位にあるみたいですね。

レポジトリ
今回の記事で使ったソースなどはこちらに置きました。
Discussion